はじめに
Unsloth Studioは、ローカルでLLMのファインチューニング・推論・データセット作成ができるGUIツール。Google Colabなしでローカル完結できるのが売り。 本記事では**M1 MacBook Pro(メモリ8GB)**という最低スペック環境で、Unsloth Studioがどこまで使えるかを検証した。 結論:1.7Bモデルなら約43 tok/sで推論可能。Data Recipes(データセット作成)もMac版で利用可能になった。ただし4B+Visionはメモリ不足でOS強制再起動。Training/ExportはMac版では無効(MLX Training対応は「coming soon」)。
環境
| 項目 | スペック |
|---|---|
| マシン | M1 MacBook Pro |
| メモリ | 8GB(統合メモリ) |
| OS | macOS Sequoia |
| Unsloth Studio | v0.1.25-beta(2026-03-27リリース) |
| 推論エンジン | llama.cpp b8508(llama-server) |
インストール
curl -fsSL https://unsloth.ai/install.sh | sh
unsloth studio -H 0.0.0.0 -p 8888所要時間:約2分。公式スクリプトがuv仮想環境の作成、依存関係のインストール、llama.cppプリコンパイルバイナリの配置まで自動で行う。初回起動時にパスワード設定を求められる。 ポイント:
- Python 3.11以上が必要(公式スクリプトがuvで自動管理)
- M1 Macでは
device_type: "mac",chat_only: trueとして検出される - Chat(GGUF推論)とData Recipes(データセット作成)が利用可能
- Studio(Training)/ Export はMac版では無効(Chatにリダイレクト)
検証1: Qwen3.5-4B-GGUF + Vision(2.7GB)→ OS強制再起動
やったこと
- モデル選択で
unsloth/Qwen3.5-4B-GGUFのUD-Q4_K_XL(2.7GB)を選択 - Vision用mmproj(BF16)も自動ダウンロード開始
サーバーログから分かったこと
GGUF metadata: context_length=262144
GGUF metadata: model supports reasoning (enable_thinking)
GGUF metadata: model supports tool calling
GGUF size: 2.7 GB, GPUs free: [], selected: None, fit: True
Starting llama-server ... --flash-attn on --fit on --mmproj ...
- コンテキスト長262Kトークン
- Reasoning(thinking)/ Tool calling / Vision 対応
- llama-serverでCPU推論、flash-attn有効
結果
llama-server health check timed out after 120.0s
Error loading model: llama-server failed to start.
120秒のヘルスチェックでタイムアウト → その後OSが強制再起動(メモリ不足によるカーネルパニック) 2.7GBモデル + mmproj Vision + llama-server + Unsloth Studio本体 + OS + ブラウザ = 8GBでは収まらなかった。
検証2: SmolLM2-1.7B-Instruct(1GB)→ 成功(ただしUI経由は失敗)
モデル選択
| 量子化 | サイズ | 備考 |
|---|---|---|
| Q4_K_M | 1007 MB | recommended、採用 |
| Q5_K_M | 1.1 GB | |
| Q6_K | 1.3 GB | |
| Q8_0 | 1.7 GB | |
| F16 | 3.2 GB |
Unsloth Studio UIでのロード → 失敗
llama-server exited with code -11 (SIGSEGV)
ggml_metal_init: the device does not have a precompil...
Unsloth Studioは --flash-attn on オプションを付けてllama-serverを起動するが、M1のMetal GPUではflash-attnがクラッシュ(セグフォ)する。これはBeta版のバグ。
llama-server直接起動 → 成功
~/.unsloth/llama.cpp/build/bin/llama-server \
-m SmolLM2-1.7B-Instruct-Q4_K_M.gguf \
--port 58888 -c 4096 --parallel 1 --jinja-flash-attnを外して起動すると問題なく動作。
推論結果
テスト1: 日本語の簡単な質問
- 質問:「日本の首都はどこですか?一文で答えてください。」
- 回答:「日本の首都は、東京です。」 ✅ 正確
- プロンプト処理:149 tok/s
- 生成速度:42.7 tok/s
- レイテンシ:約0.5秒 テスト2: コード生成
- 質問:「Pythonでフィボナッチ数列を再帰で実装してください」
- 回答:動くコードを出力したが「再帰」ではなくループで実装(指示に従えていない。1.7Bモデルの限界)
- プロンプト処理:195 tok/s
- 生成速度:45.9 tok/s(200トークン)
- レイテンシ:約4.4秒
補足: Beta初期版(3/17)では35 tok/s前後だったが、v0.1.25(3/27)のllama.cpp更新で20-30%高速化された。公式によると、以前は起動時間を推論速度に誤算入していた問題も修正されている。
メモリ使用量
| プロセス | RSS |
|---|---|
| llama-server | 1.8 GB |
| Unsloth Studio(Python) | 約300 MB |
| 合計(OS・ブラウザ除く) | 約2.1 GB |
M1 8GBの統合メモリのうち約26%を使用。OS・ブラウザ分を考えると余裕はあまりない。
Mac版の機能制限まとめ
| タブ | 利用可否 | 備考 |
|---|---|---|
| Chat | ⭕ 利用可 | GGUF推論。flash-attnバグあり(手動起動で回避可) |
| Recipes(Data Recipes) | ⭕ 利用可 | v0.1.2-beta(3/25)で有効化。PDF/DOCX/TXT/MDアップロード対応 |
| Studio(Training) | ❌ 無効 | Chatにリダイレクト。MLX Training対応は「coming soon」 |
| Export | ❌ 無効 | Chatにリダイレクト |
API /api/health では chat_only: true が返されるが、実際にはData Recipesも利用可能。
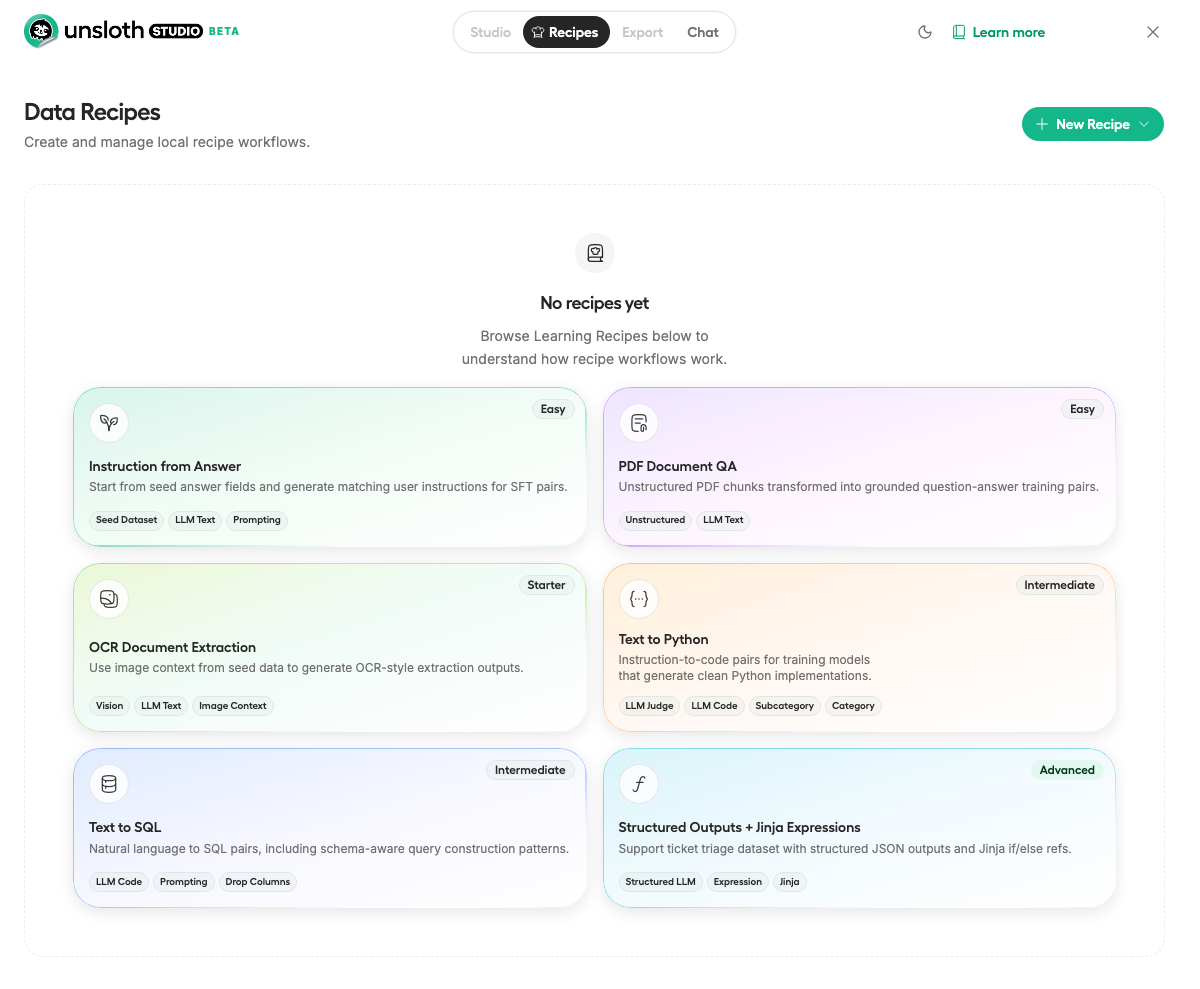
Data Recipesで使えるテンプレート(6種)
| テンプレート | 難易度 | 用途 |
|---|---|---|
| Instruction from Answer | Easy | 回答からSFT用の指示文を自動生成 |
| PDF Document QA | Easy | PDFからQAペアを生成 |
| OCR Document Extraction | Starter | 画像からOCR抽出データを生成 |
| Text to Python | Intermediate | 自然言語→Pythonコードのペア生成 |
| Text to SQL | Intermediate | 自然言語→SQLクエリのペア生成 |
| Structured Outputs + Jinja | Advanced | 構造化JSON出力+Jinjaテンプレート |
GPU環境でのTrainingは不可だが、ファインチューニング用データセットの準備はMac単体で完結できる。作成したデータセットをGoogle ColabやGPUマシンに持ち込んでTrainingする運用が可能。
M1 8GBでのモデルサイズ目安
| モデル | サイズ | 結果 |
|---|---|---|
| Qwen3.5-4B + Vision (Q4) | 2.7GB + mmproj | ❌ OS再起動 |
| SmolLM2-1.7B (Q4_K_M) | 1.0GB | ✅ 43 tok/s |
| SmolLM2-360M | ~300MB | 未検証(さらに軽量) |
目安:M1 8GBではモデルサイズ1.5GB以下が安全圏。2GB超はリスクあり。
発見したバグ・注意点
- flash-attn M1クラッシュ: Unsloth Studio UIが
-flash-attn onでllama-serverを起動するが、M1ではSIGSEGV。回避策:llama-serverを手動起動(-flash-attnなし)。v0.1.25時点でも未修正 - 4B+Visionでカーネルパニック: メモリ不足でOS強制再起動。事前警告なし
- chat_only APIの不整合:
/api/healthはchat_only: trueを返すが、実際にはData Recipesも利用可能。APIレスポンスが実態と合っていない
まとめ
| 観点 | 評価 |
|---|---|
| インストール容易性 | ⭕ 公式スクリプト一発、約2分で起動 |
| 1.7Bモデルの推論 | ⭕ 約43 tok/s、実用レベル |
| 4Bモデルの推論 | ❌ メモリ不足でOS再起動 |
| Data Recipes | ⭕ Mac対応済。6種のテンプレートで学習データ作成可能 |
| Training | ❌ Mac未対応(MLX対応 coming soon) |
| M1での安定性 | △ flash-attnバグあり(手動起動で回避可能) |
Unsloth StudioをM1 8GBで使うなら、1-2Bクラスの小モデルでChat推論 + Data Recipesでデータセット作成が現実的な活用法。Trainingは素直にGoogle Colab(またはGPU搭載マシン)で行い、データ準備だけMacで完結させるワークフローが組める。 「M1 Macで手軽にローカルLLM推論だけしたい」なら、LM StudioやOllamaの方が安定している(flash-attnバグもない)。ただしData Recipesによるファインチューニング用データセット作成はUnsloth Studio固有の強みであり、この機能のためにインストールする価値はある。MLX Training対応が実装されれば、Mac完結のファインチューニング環境としてさらに化ける可能性がある。
