はじめに
月末の請求書処理では、PDFを開いて会社名をコピーし、スプレッドシートに貼り付け、合計金額を確認してまた貼り付ける、という作業が発生しがちです。
PDFはシステムにとって「画像」や「テキストの塊」にすぎず、人間が手作業で構造化データ(JSON)に変換しているケースが多いのではないでしょうか。
本記事では、PDFをアップロードするだけで欲しい情報を抽出するツールを、n8nで構築します。以前Difyで実装したPDF要約ワークフローの n8n版です。
作るもの
専用のURLにアクセスしてPDFをアップロードすると、数秒で「会社名」「請求番号」「合計金額」など、あらかじめ指定したデータが整理されて画面に表示されるシンプルなWebアプリです。
作業環境
| 項目 | バージョン / 種別 |
|---|---|
| n8n | 2.14.2(クラウド版、またはセルフホスト版) |
| LLM API | Google Gemini API(OpenAIなど他のLLMでも可) |
n8nとは?
複数のアプリやAPIを繋いで業務を自動化する、ノーコード・ローコードツールです。ZapierやMake(旧Integromat)と同じカテゴリのツールです。
強みは自由度の高さとデータ処理のしやすさにあります。DifyなどのAI特化プラットフォームでも似たツールは作れますが、n8nなら「画面の作成(フォーム)」から「バイナリデータ(PDF自体)の処理」、そして「他SaaSへのデータ送信」まで、一つのキャンバス上で完結できます。
完成イメージ
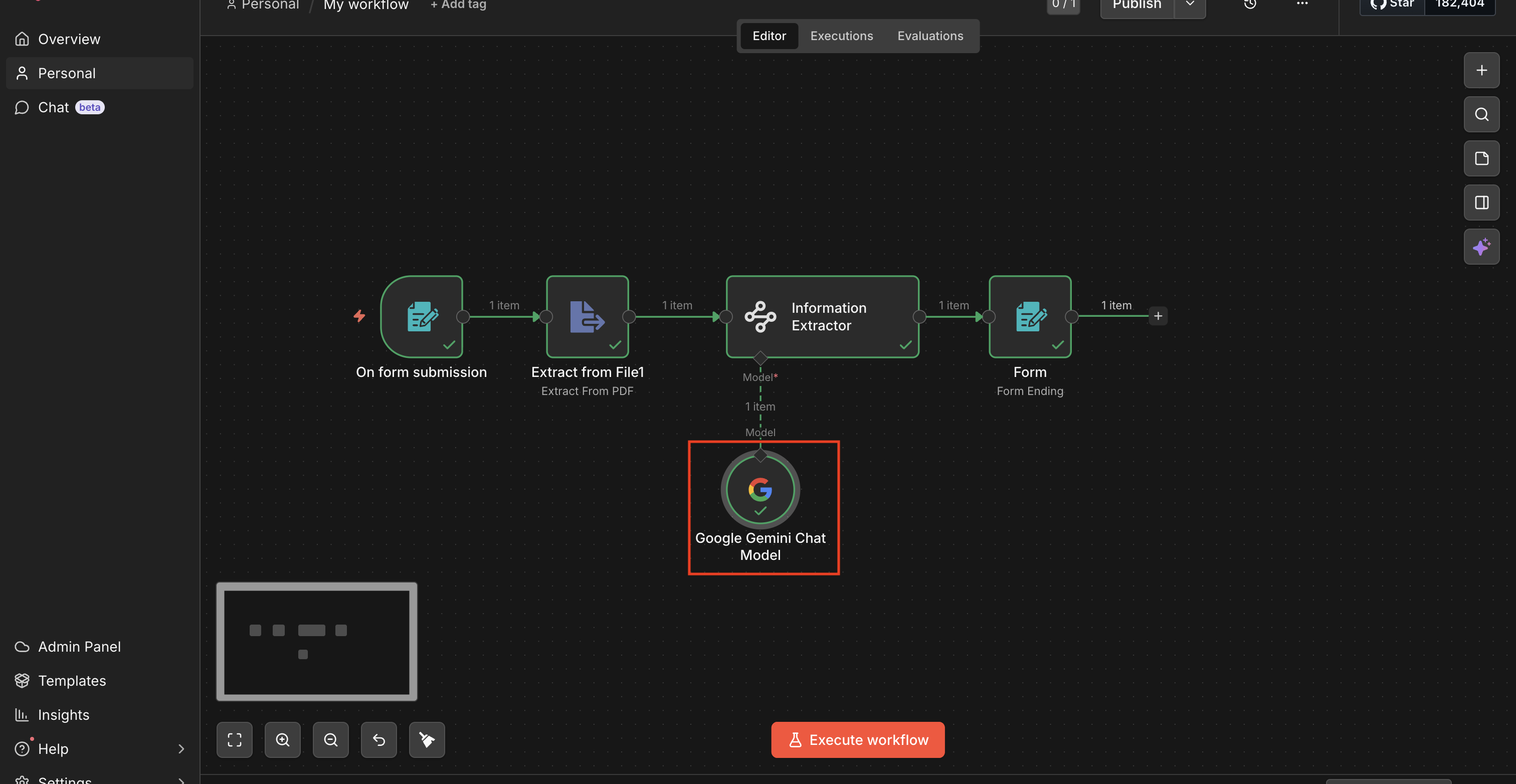
ワークフローの全体像
今回組むノードは4つです。
作業手順
事前準備:APIキーの取得
まずはLLMのAPIキーを用意します。今回はGoogleのGeminiを使用します。 Google AI Studio(aistudio.google.com)にアクセスし、「Get API key」から新しいキーを発行してコピーしておいてください。
ワークフローの新規作成
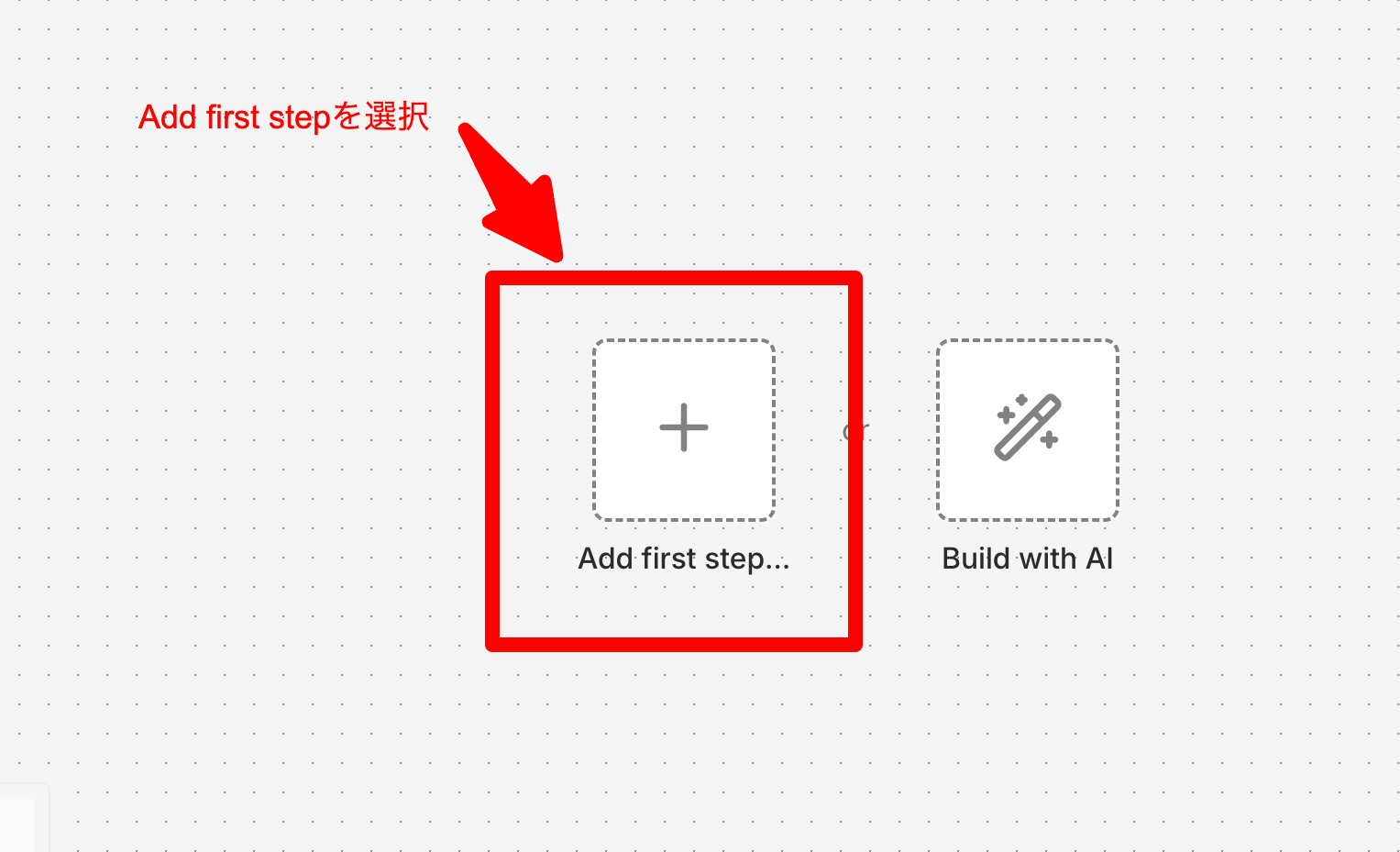
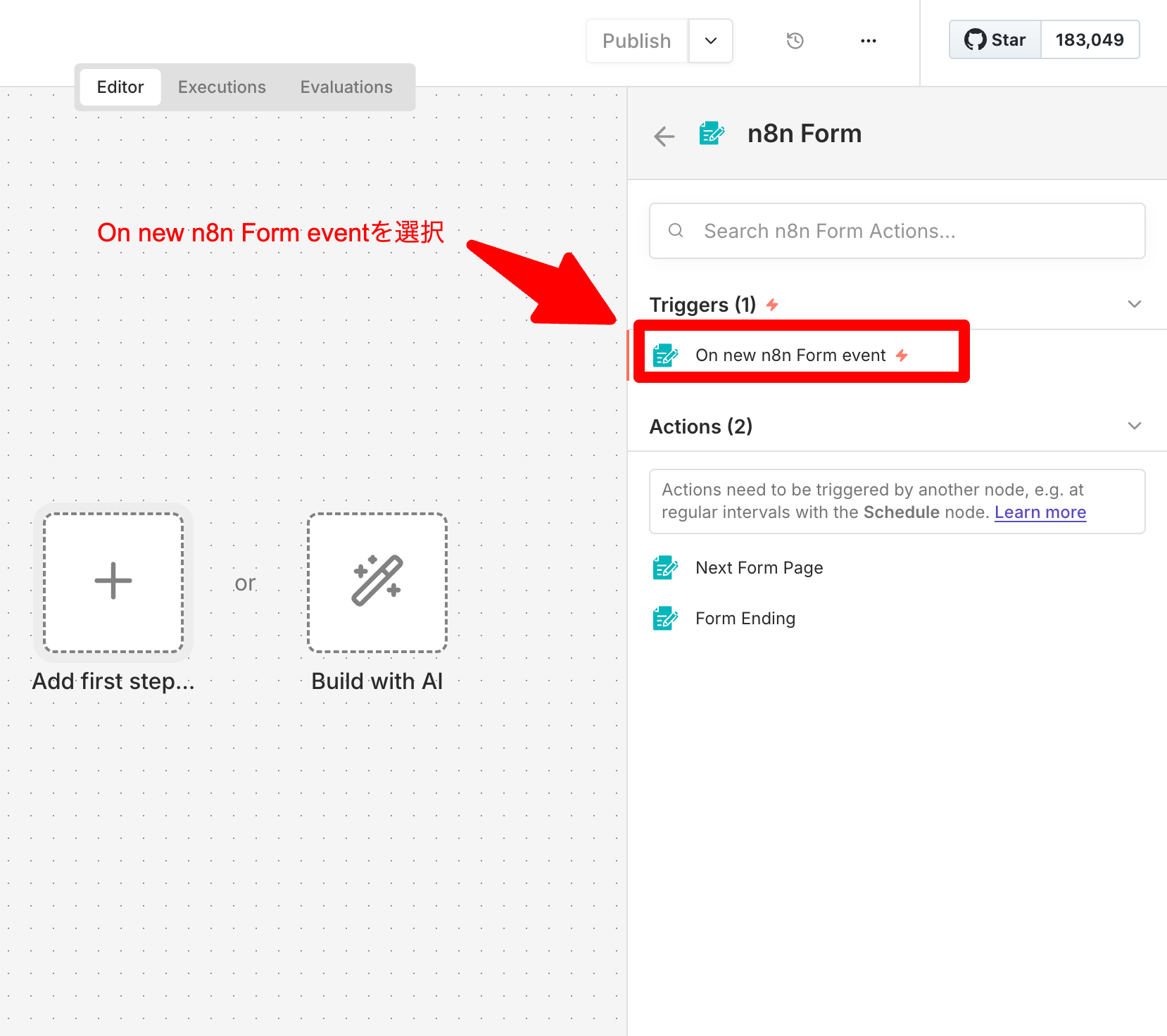
n8nの画面を開き、新しくワークフローを作成します。 最初のスタート地点(トリガー)として、On new n8n Form event をキャンバスに配置してください。
- add first stepをクリック
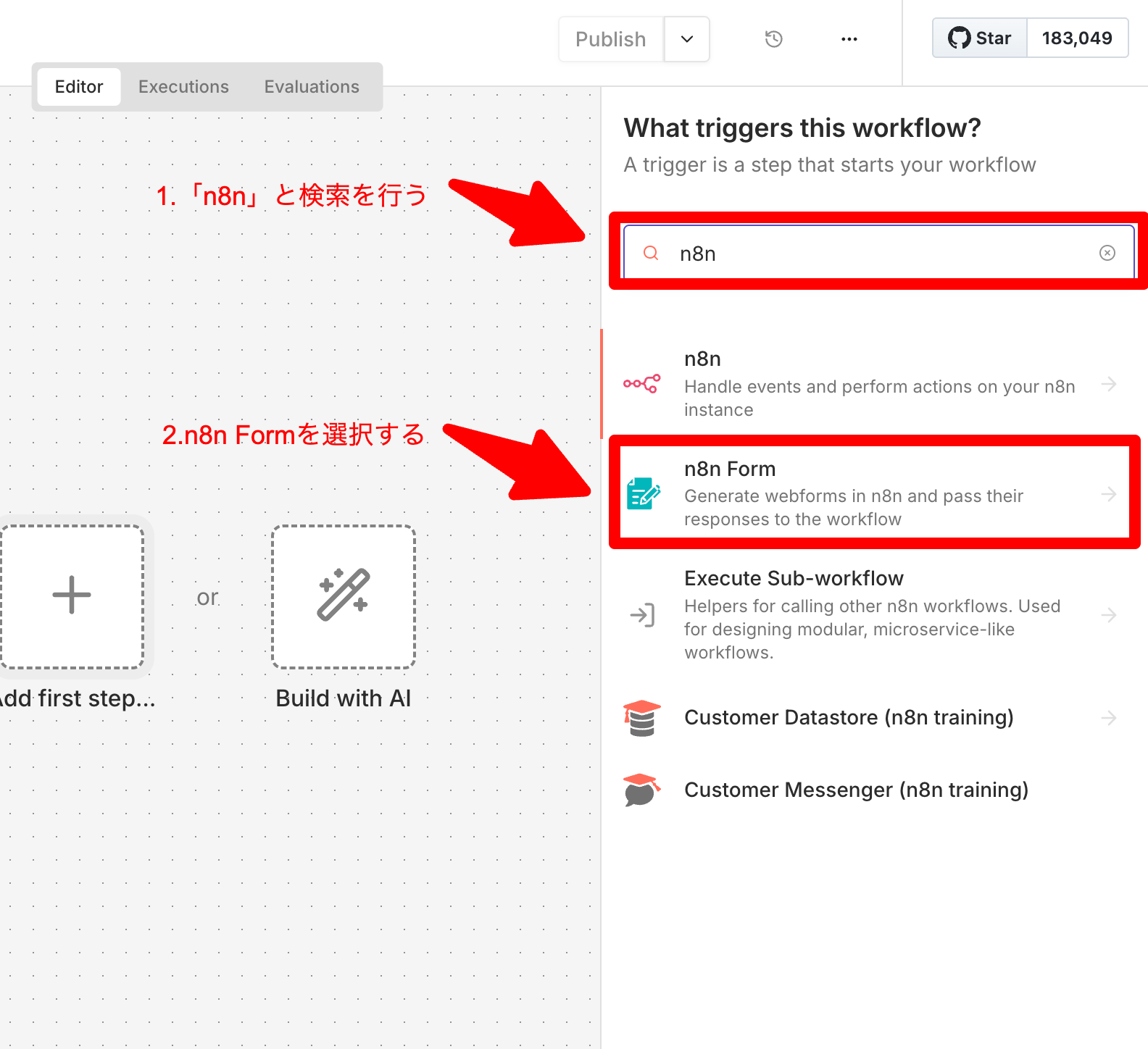
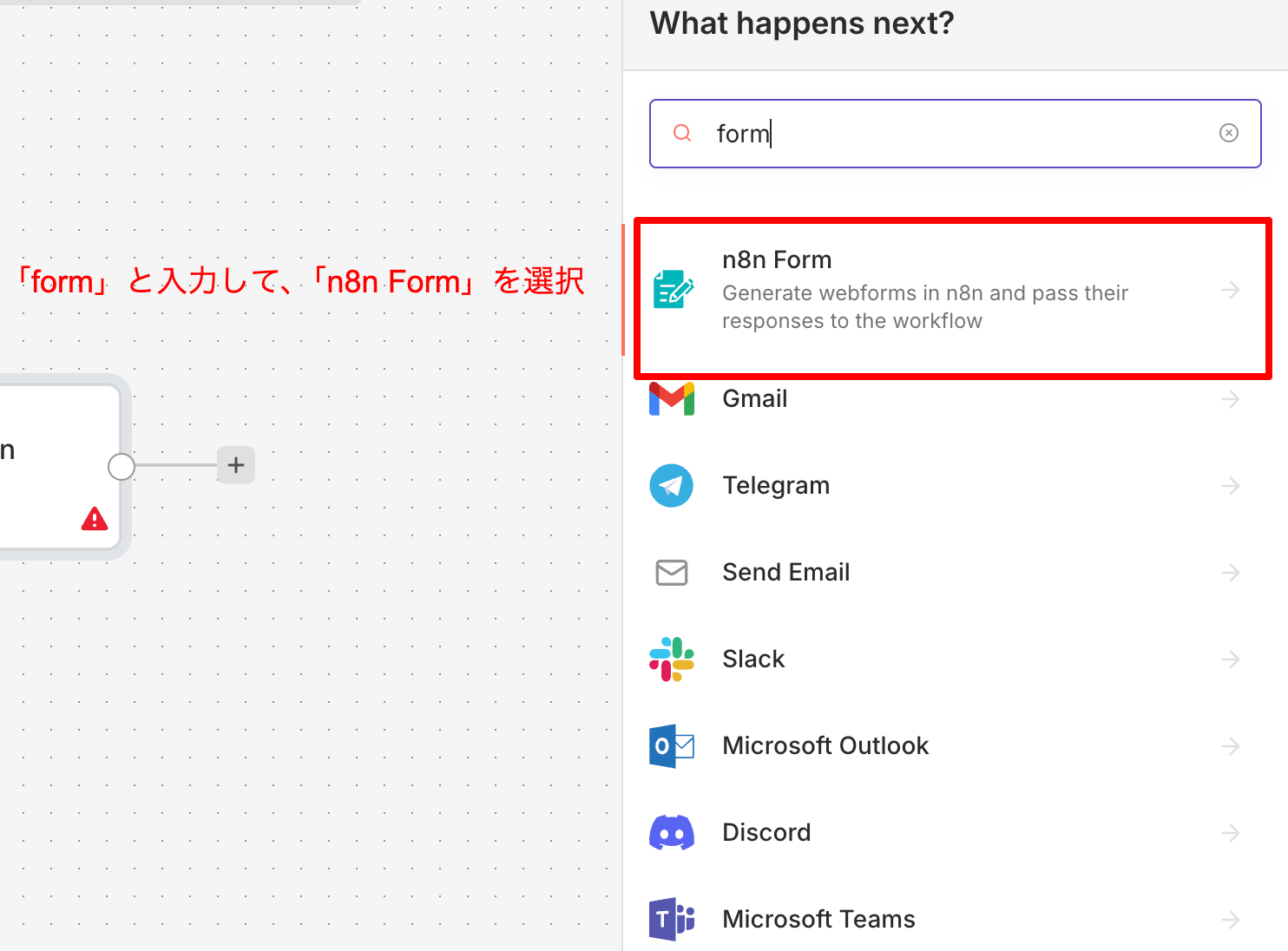
- n8n Formを選択
- On new n8n Form eventを選択
Step 1. 入口(フォーム)を作る
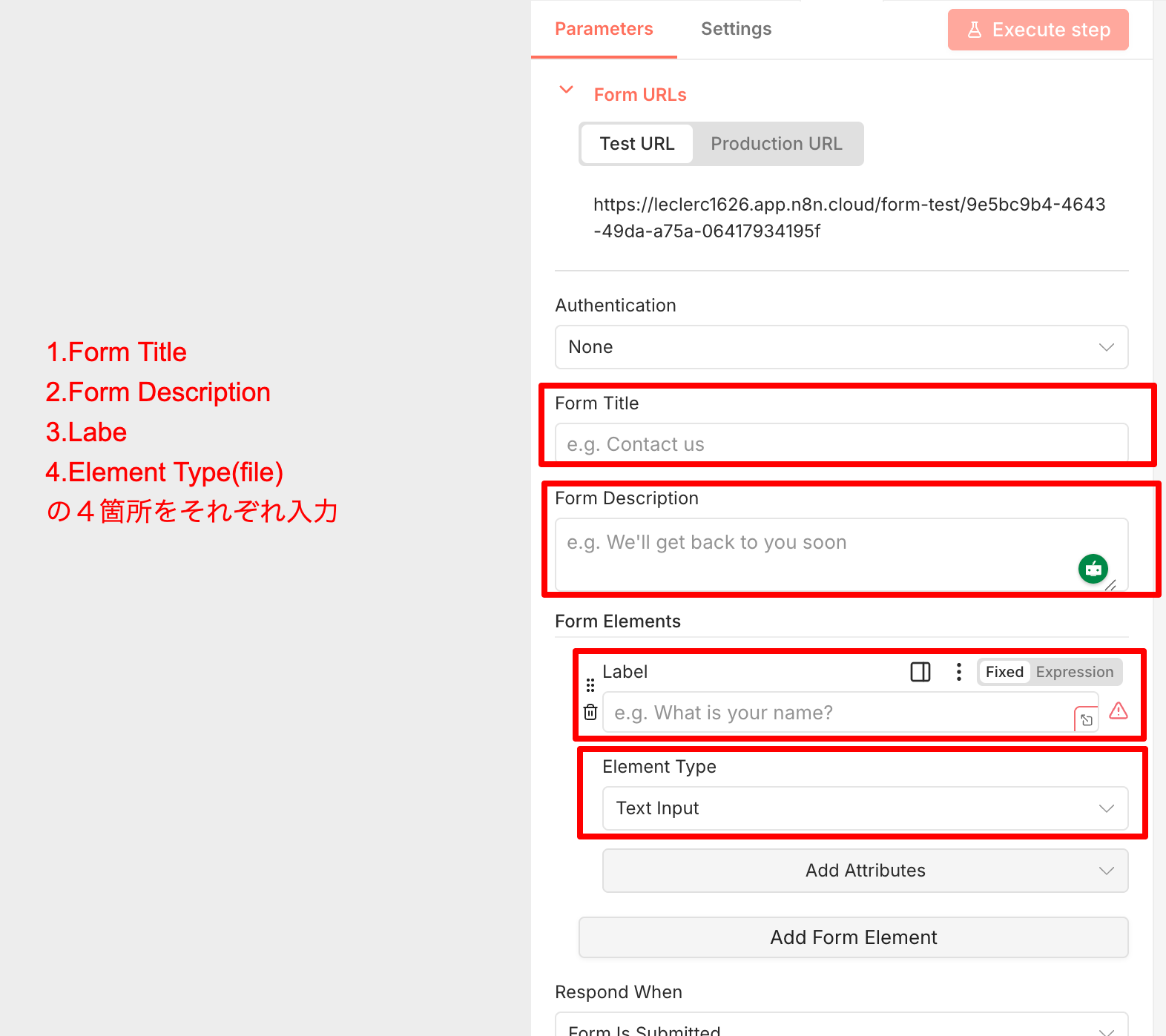
配置したフォームトリガーを開き、タイトルを「PDF解析ツール」と設定します。 ファイルを受け取るためのフォーム要素も追加します。
Add Form Element をクリックして、以下のように設定します。
- Element Type: File
Step 2. PDFからテキストを抽出する
アップロードされたPDFは、そのままではAIが読めないため、テキストに変換する必要があります。 Extract from File ノードを追加し、
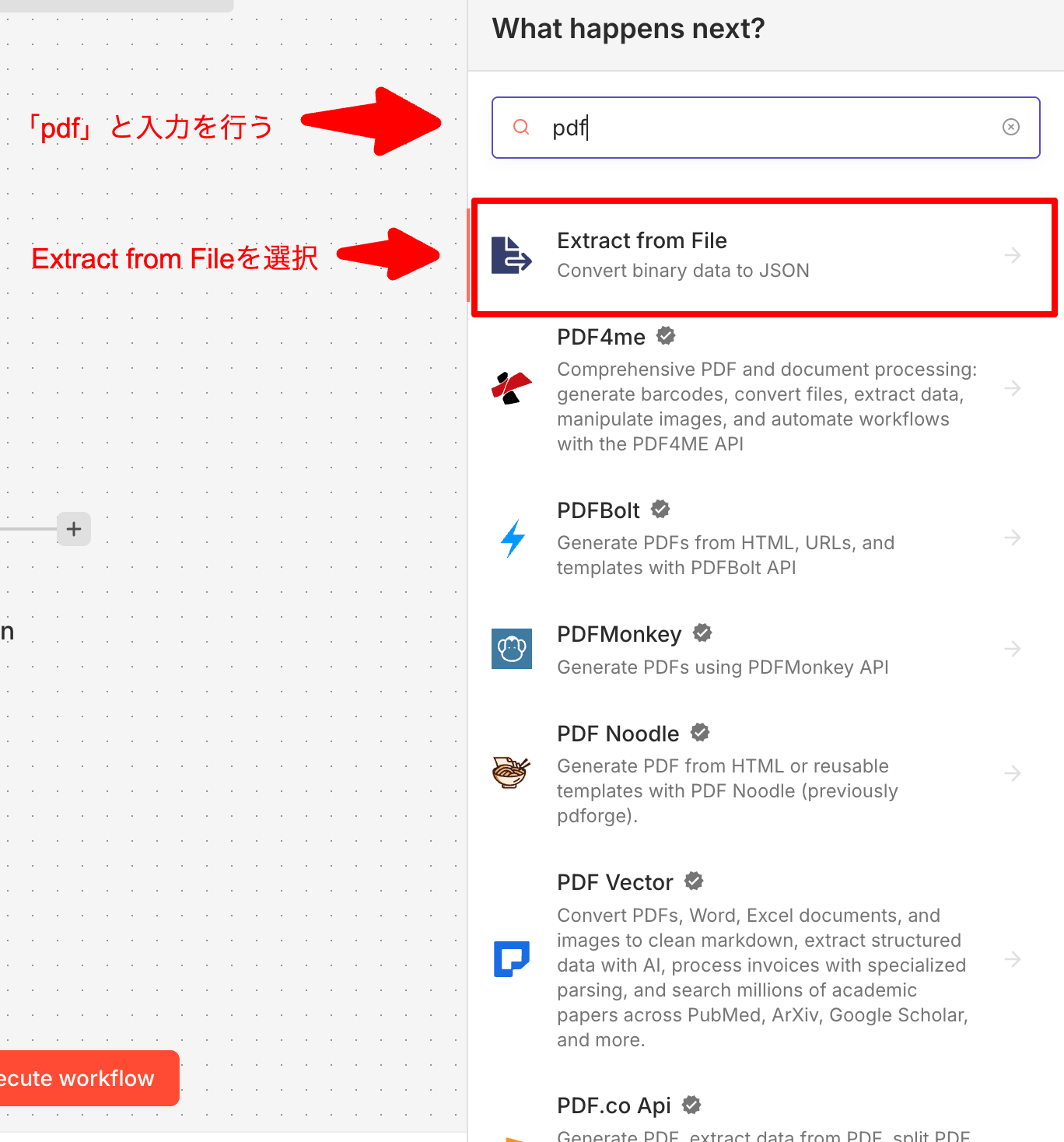
Extract From PDF に設定します。
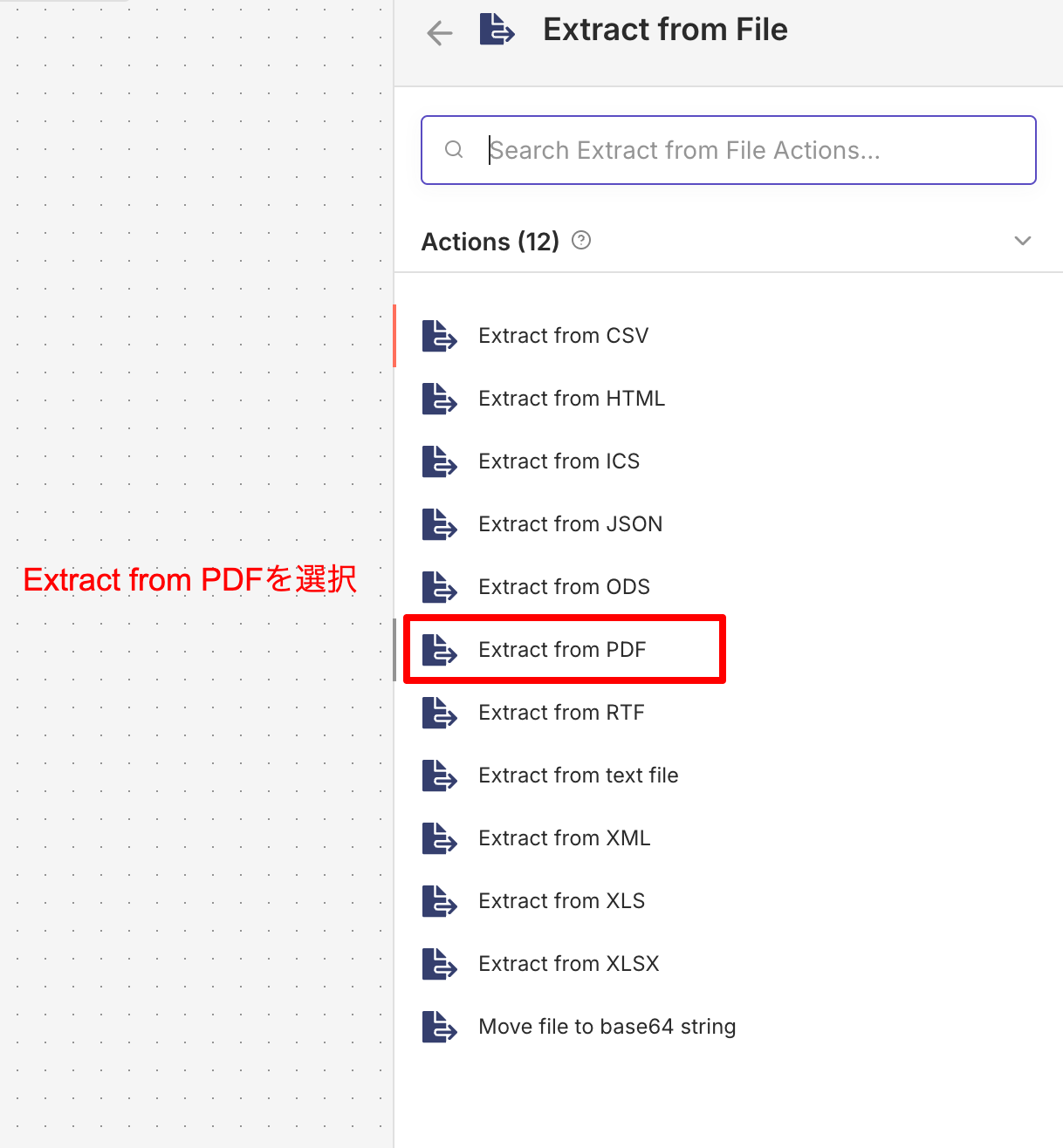
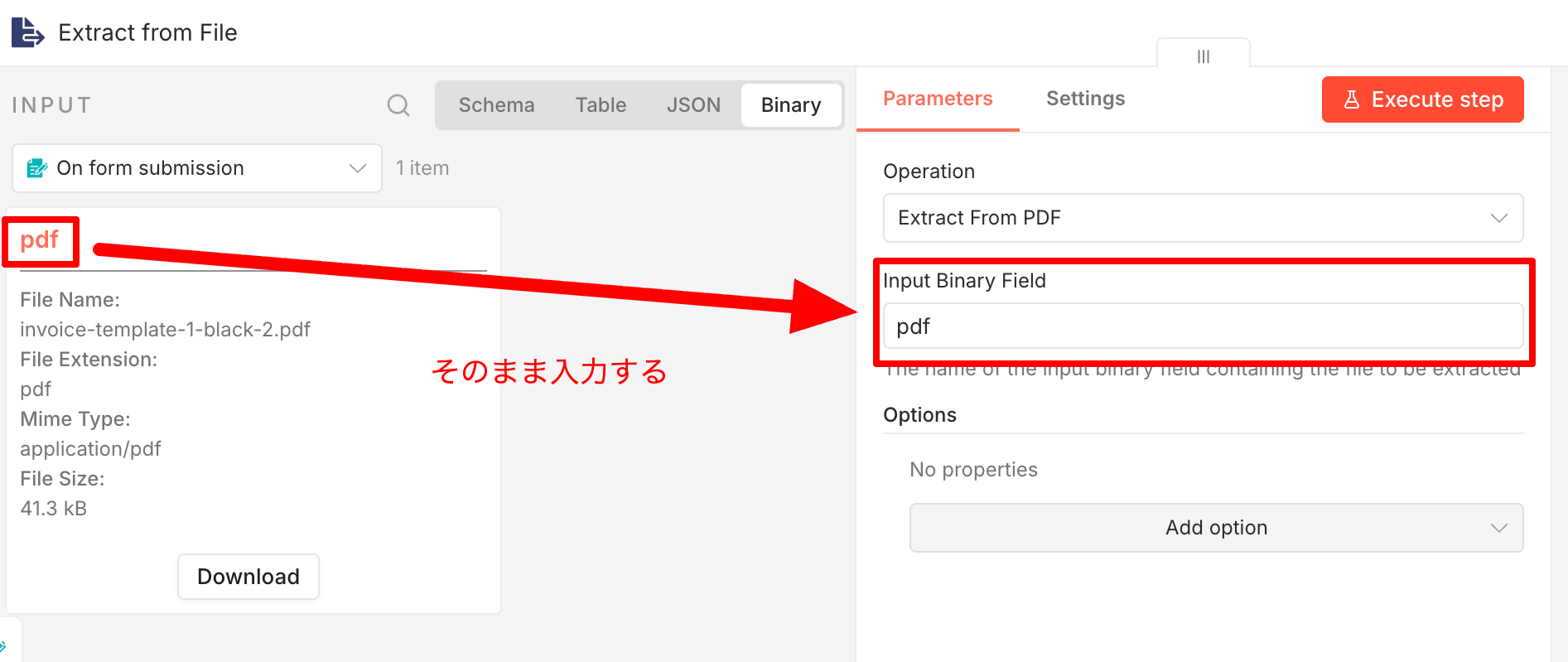
注意点として、n8nはデフォルトで data という名前のバイナリフィールドを参照しますが、フォームで作成したフィールド名は file です。このままではエラーになるため、次の手順で修正します。
Input Binary Field の値を data から file に変更します。左側のINPUTエリアにある太字の PDF のフィールド名を確認し、Input Binary Field の枠へ入力してください。
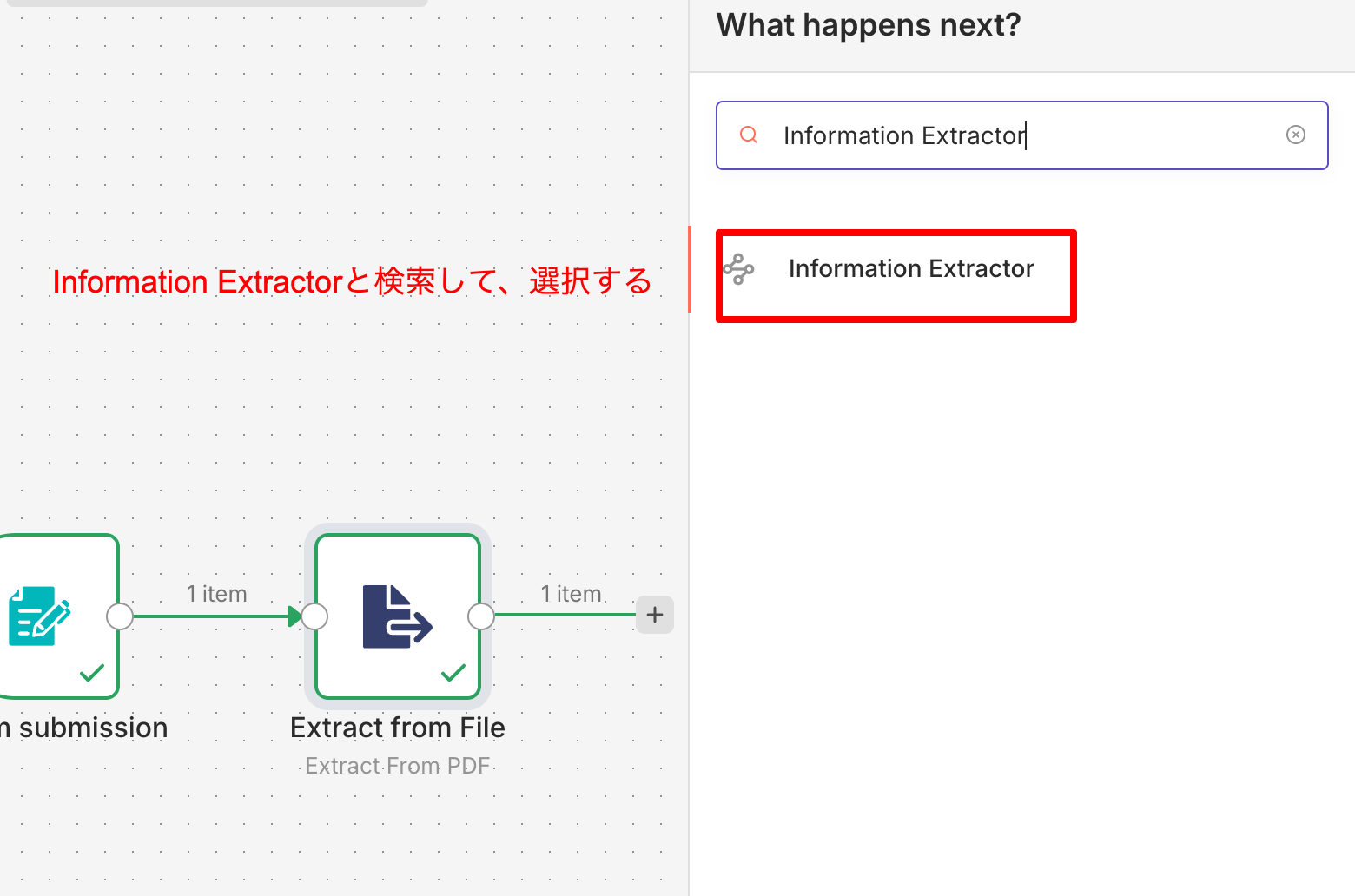
Step 3. AIでデータを抽出する
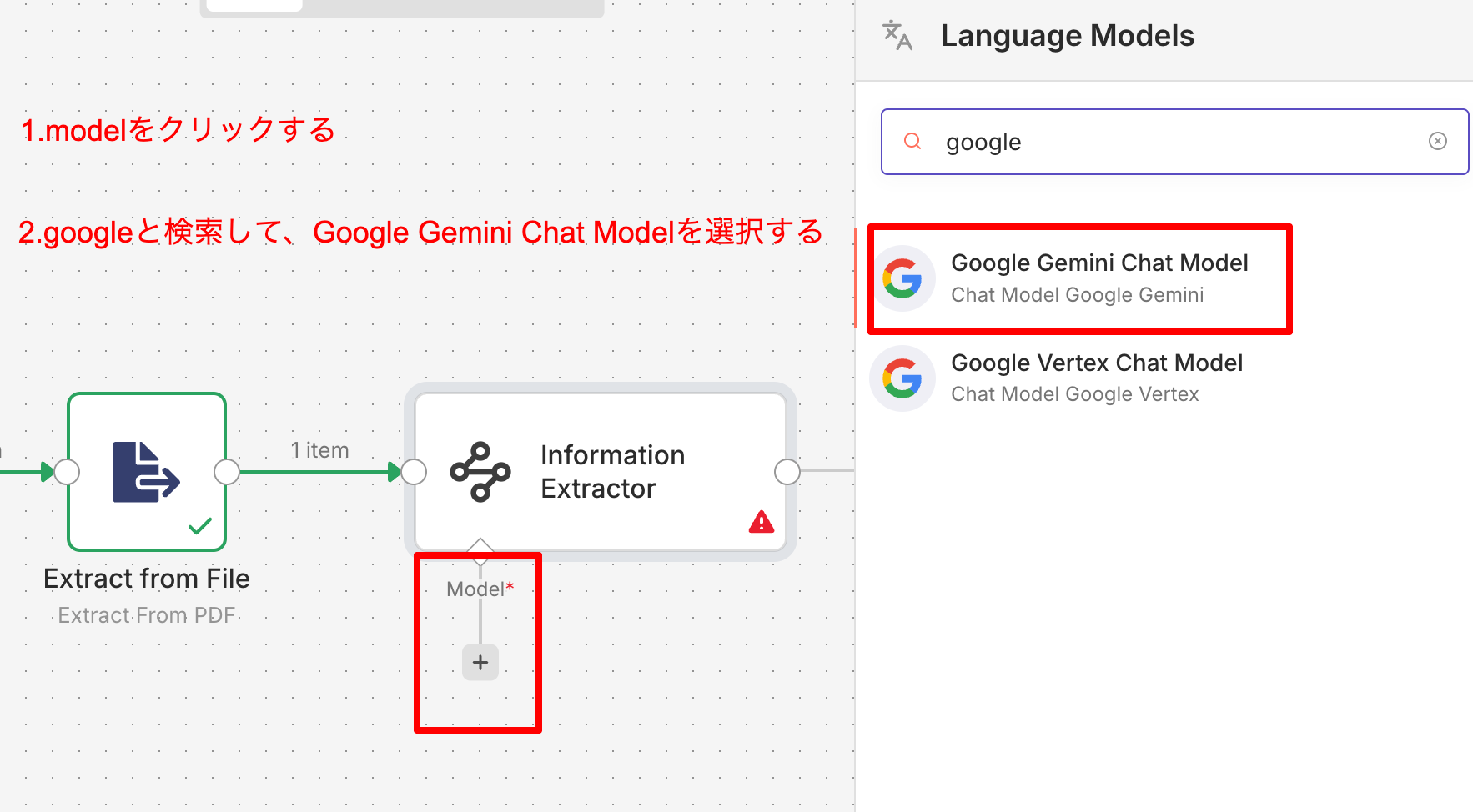
テキストになったデータをAIに読み込ませます。 Information Extractor ノードを追加し、下にGeminiのモデルを繋ぎます。ここで事前準備で取得したAPIキーを設定します。
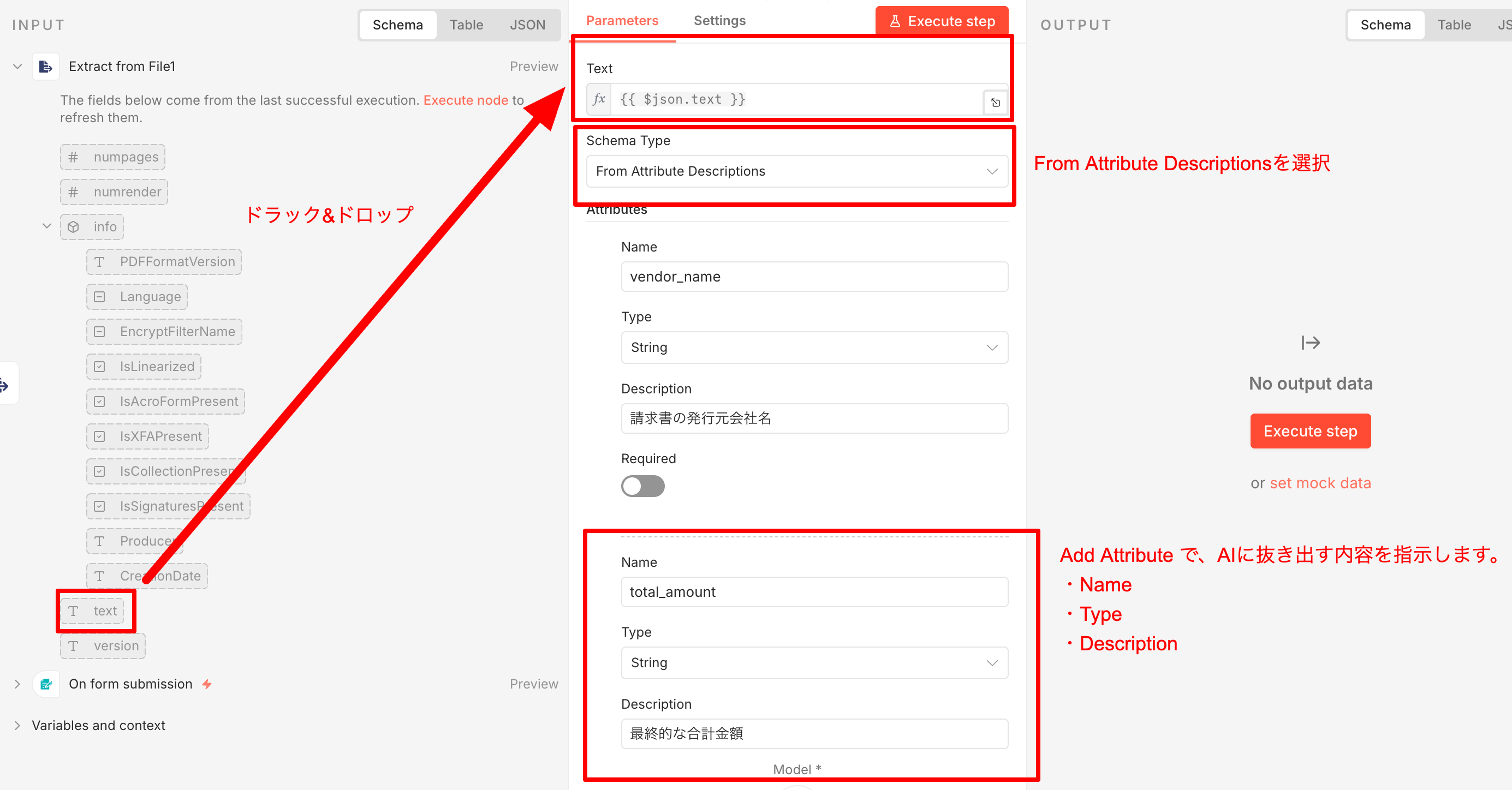
- Text 欄に、左から text をドラッグ&ドロップ(または
{{ $json.text }}と入力)。 - Schema Type は From Attribute Descriptions に。
次に Add Attribute で、AIに「何を抜き出してほしいか」を指示します。
vendor_name(String):請求書の発行元会社名total_amount(String):最終的な合計金額(税込)invoice_number(String):請求書番号ceo_name(String):代表者の氏名
Step 4. 結果を返す
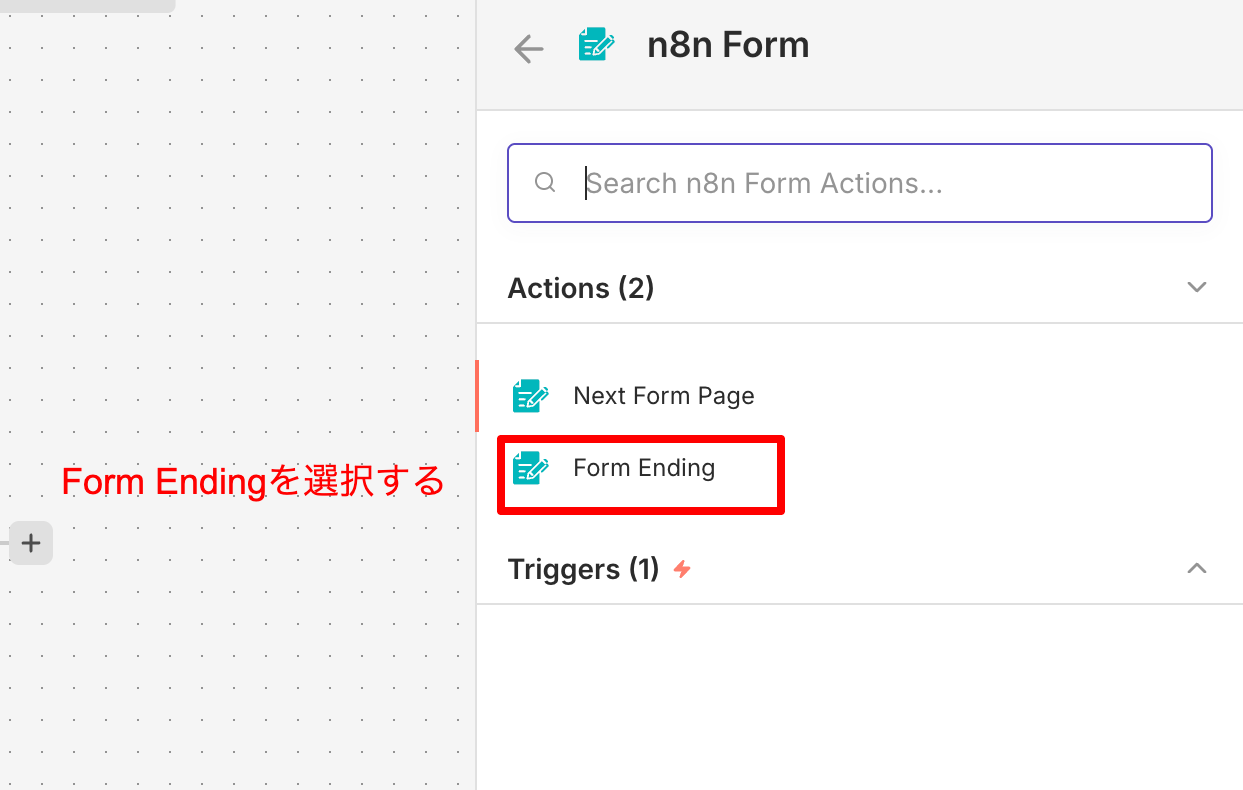
最後に、抽出したデータをアップロード画面にテキストとして返します。 n8n Form (Actionノード) を使い、Page Typeを Form Ending に設定してください。
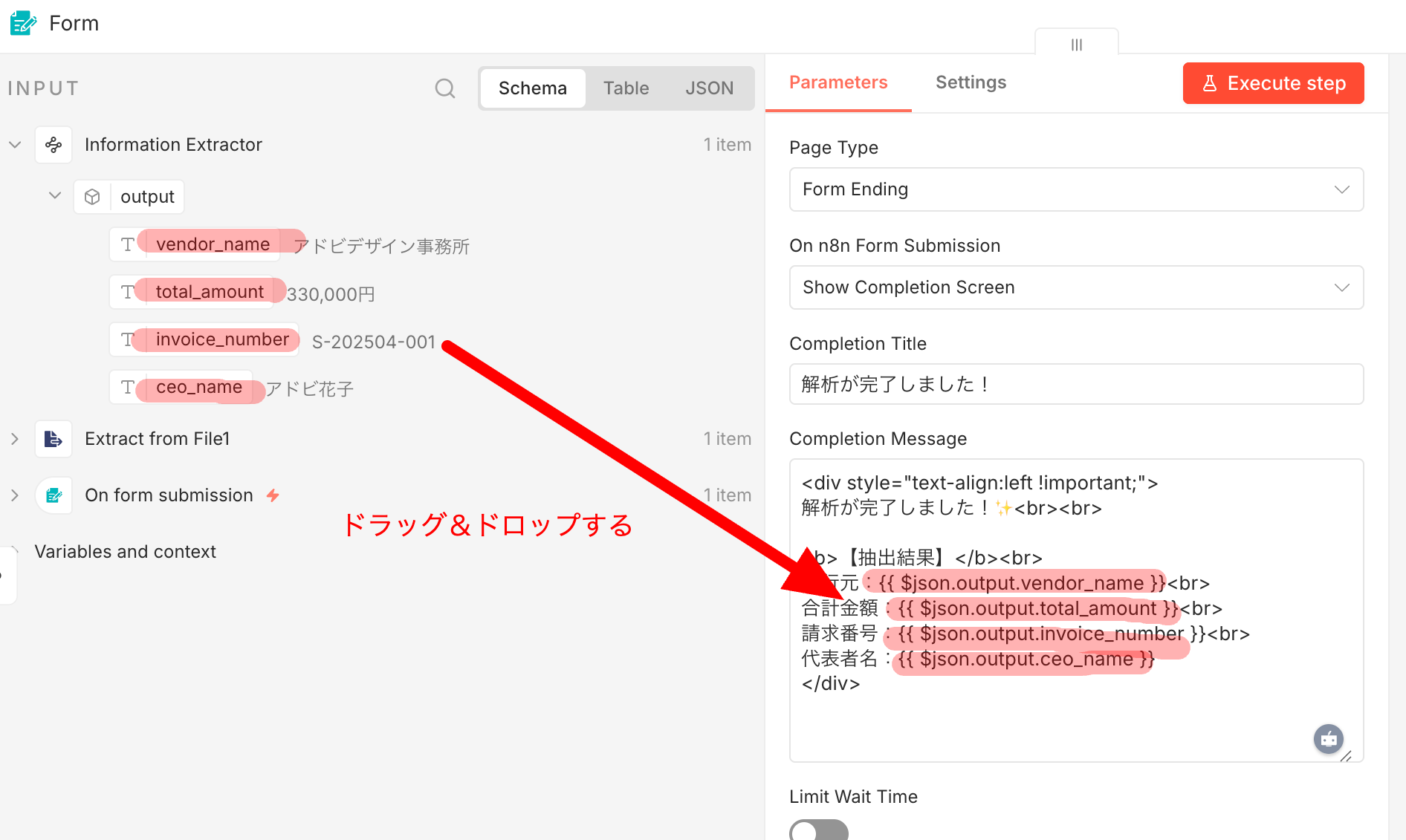
Completion Message に結果を埋め込みます。左側の「INPUT」を展開して、vendor_name などの変数を文章の中へドラッグ&ドロップで配置します。
動作確認
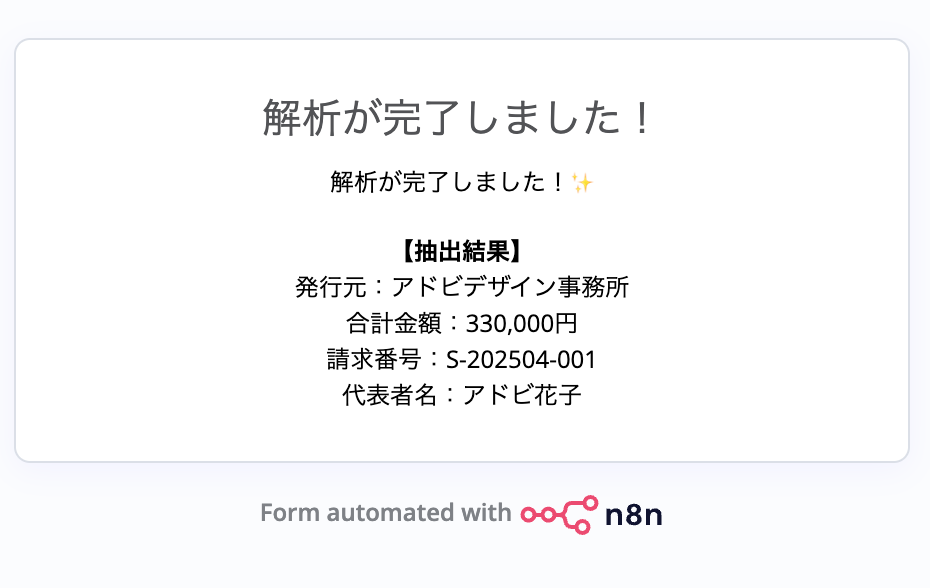
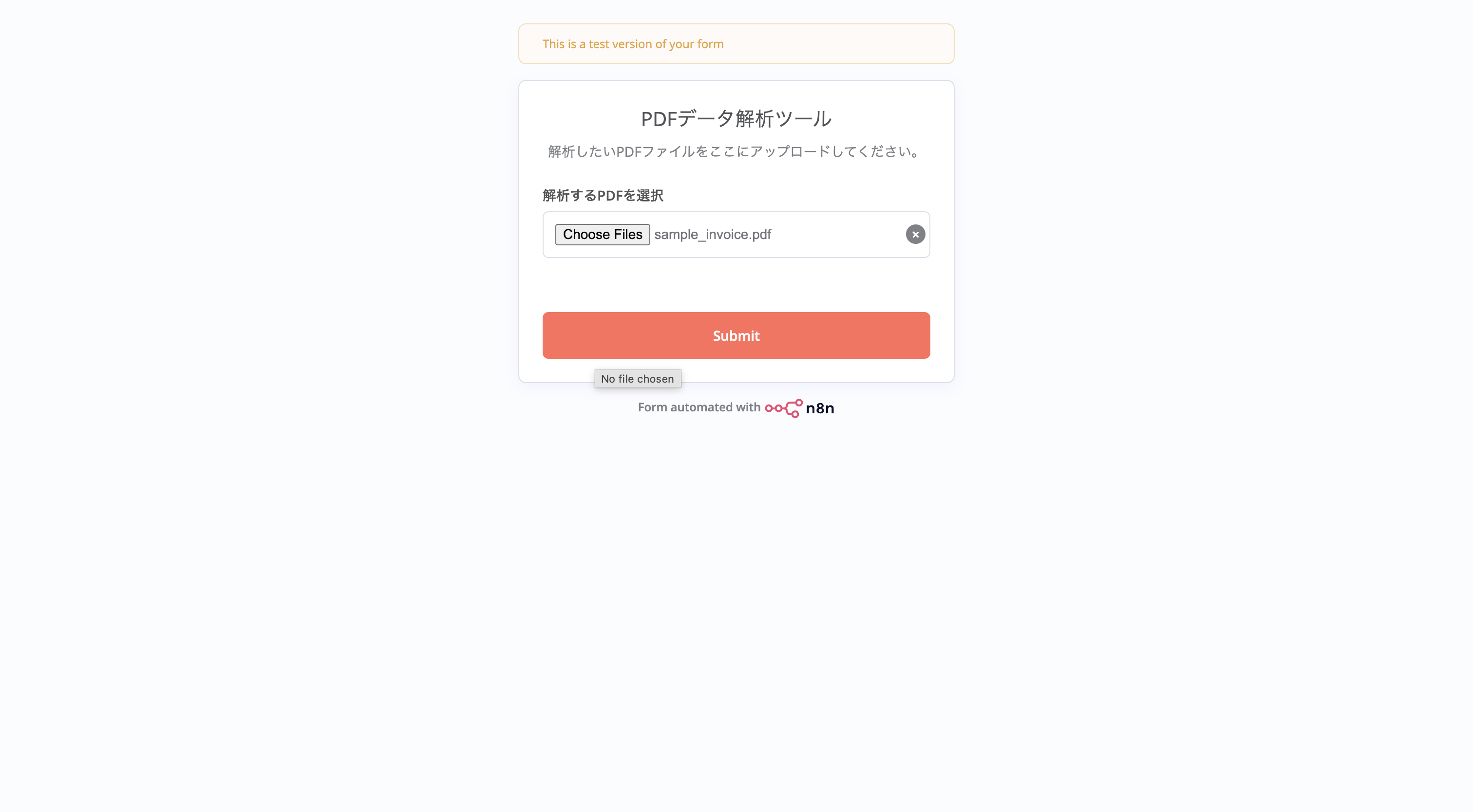
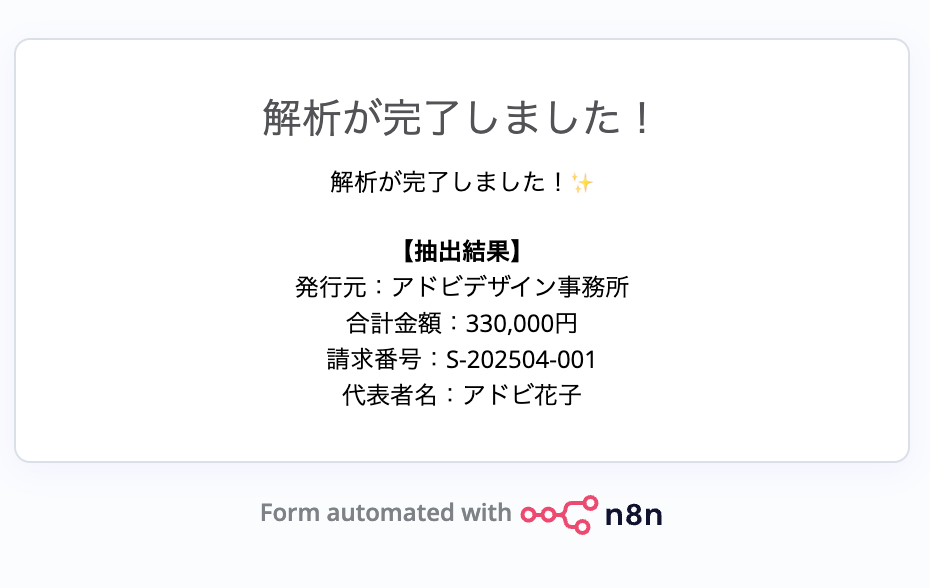
最初のフォームの「Test URL」からブラウザを開き、手元にある請求書PDFをアップロードしてみてください。
今回はAdobeが提供している 請求書テンプレート を使用してみます。
数秒待つと、指定したデータが整理されて画面に表示されます。
応用:さらに自動化するには
今回は画面表示のみですが、AIノードと完了画面の間にノードを追加することで、さらに自動化を拡張できます。
- Google Sheets ノードを挟めば、解析データを台帳へ自動追記
- Slack ノードで、処理完了を通知
- HTTP Request ノードで、自社データベースへAPI経由で直接格納
用途に応じて柔軟に拡張できます。
おわりに
PDFの転記作業が、ファイルをアップロードするだけで完結するようになりました。 非構造化データをJSONに変換する仕組みができれば、後続の処理も自動化しやすくなります。ぜひ自社の業務に合わせてカスタマイズしてみてください。
