LangExtractの概要
LangExtract は Google が開発した、Gemini モデルを含む LLM(大規模言語モデル)を使って、非構造化テキストから欲しい情報を取り出すためのオープンソース Python ライブラリです。 例えば契約書、議事録、レビュー・フィードバックなど自由形式の文章を、決まったスキーマに沿って「誰が何をいつ決めたか」「料金」「期限」などの構造化データに変換できます。 LangExtract は、
- few-shot サンプルを利用してスキーマをガイドできる
- 出力を元テキストと紐付けて位置を取得できる(検証・追跡が可能)
- 長文や複数文書にも対応できる という点で、とくにテキスト量が多い実務ドキュメントで有用です。
few-shot モデルに少数の例文とその理想的な出力例を与える手法のことです。これにより、モデルは「どんな形式で抽出すべきか」を学習し、安定した出力を返しやすくなります。大量の学習データや追加学習(fine-tuning)を行わずに、プロンプト内の例だけで目的のパターンを伝えられるのが特徴です。
特徴・メリット
- 出典と突き合わせが可能 抽出した内容が、元のテキストのどこに書かれているかを文字単位で紐付けできます。ハイライト表示もできるので、「本当にこの部分から抜き出したのか」を簡単に確認できます。
- スキーマに沿った安定した出力 あらかじめ「契約期間」「料金」などの項目を指定し、少しの例文を与えるだけで、それに沿った形で情報を整理して出力できます。これにより、毎回ばらばらな形式ではなく、統一された構造のデータを得られます。
- 長文や大規模文書に対応 ドキュメントを小さなかたまりに分けて処理し、並列で走らせる仕組みがあるため、数十ページ規模の長文や複数のファイルでも抜け漏れが少なく処理できます。
- 結果の可視化 抽出した情報をハイライト付き HTML で表示でき、数が多い場合でも動きのある UI で確認可能です。レビューやデバッグがしやすくなります。
- 幅広いモデルに対応 Google Gemini などのクラウドモデルはもちろん、手元で動かすオープンソースの言語モデルとも組み合わせて使えます。
- どんな分野にも応用可能 契約管理、医療記録、顧客対応、研究論文など、分野ごとに抽出したい項目を設定すれば、そのまま活用できます。専門的な追加学習(ファインチューニング)は不要です。
使い方
ここでは、LangExtractの基本的な使い方を紹介します。
1. インストール
pip -q install -U langextract2. プロンプト定義
次に、抽出したい情報をプロンプトで定義します。few-shot 例を与えることで、モデルが狙い通りの抽出を行いやすくなります。
import textwrap
import langextract as lx
# プロンプト定義
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# few-shot
examples = [
lx.data.ExampleData(
text=("ROMEO. But soft! What light through yonder window breaks? "
"It is the east, and Juliet is the sun."),
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"},
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"},
),
],
)
]3. 実行
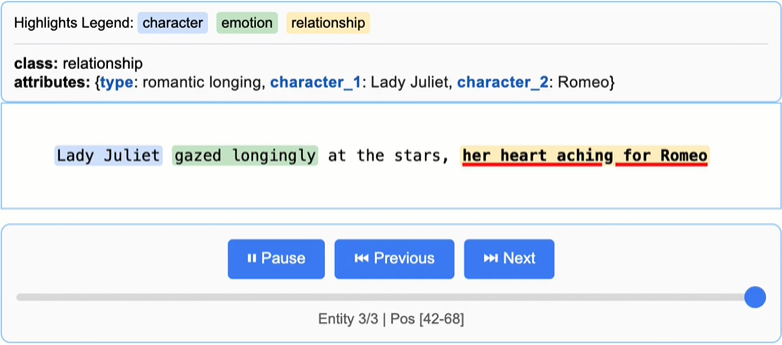
準備したプロンプトと few-shot を用いて、テキストをモデルに渡して抽出を行います。モデルは gemini-2.5-flash などを選ぶことも可能です。
# 入力テキスト
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro",
)4. 結果の保存と可視化
抽出結果は JSONL に保存でき、HTML 形式でハイライト付きで内容を確認できます。
# JSONL 保存
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# HTML 生成
html_content = lx.visualize("extraction_results.jsonl")
from IPython.display import HTML
HTML(html_content)JSONL (JSON Lines)
1行ごとに1つの JSON オブジェクトを書き連ねたテキストファイルフォーマット。
拡張子は.jsonlや.ndjsonがよく使われます。
LangExtractが標準で返すフィールド
LangExtract の出力(Extraction オブジェクト/JSON 形式)には、いくつかの標準フィールドがあります。デモ出力を理解するために以下を把握しておくと良いです。
| フィールド名 | 内容 | 補足 |
|---|---|---|
| extraction_class | 抽出対象の種類。few-shot やスキーマで定義したクラス名(例:contract_period、fee など) | どのタイプかを識別 |
| extraction_text | 抽出されたテキストそのもの(原文の表現) | 省略・意訳なしで、元の文と対応する文字列 |
| attributes | クラスに応じた追加情報(owner、start_date、end_date、renew、payment_terms など) | 抽出クラスごとに異なる内容を持つ |
| char_interval | 元のテキスト内で抽出部分の文字レベルの開始・終了位置 | 抽出の位置を示す。可視化などに使われる |
| _token_interval | トークン単位での抽出位置(言語モデルの入力トークンとの対応) | char_interval と並んで、モデル視点での位置情報 |
| alignment_status | few-shot 例との一致度/整合性(例:MATCH_EXACT、MATCH_LESSER、FAILED など) | few-shot の例との比較でどれだけ近いかを示す指標 |
| extraction_index | 抽出された順番を示すインデックス | 出力順序の識別に使える |
| group_index | 同じグループあるいは関連抽出のグループ識別 | 複数の関連する抽出があるときのまとまりを示す |
| description | 補足説明や備考(通常は null もしくは空) | モデルが付加できる補足情報 |
実際に使ってみる
事前準備
今回の実行環境は Google Colab です。 Colab 上で Gemini の API キーを環境変数に設定し、Google Drive をマウントしてファイルを扱えるようにします。
# --- APIキーの設定(Colab シークレットに保存している場合)
from google.colab import userdata
import os
api_key = userdata.get("GOOGLE_API_KEY")
os.environ["LANGEXTRACT_API_KEY"] = api_key# --- Google Drive のマウント
from google.colab import drive
drive.mount("/content/drive")短いテキスト
まずは、短いテキストで試します。今回は以下の議事録のサンプルを試します。sample1.txtという名前で保存してください。
営業(佐藤):
田中さん、本日はお時間いただきありがとうございます。まず、今回の商談の目的ですが、御社の業務効率化に向けた新システム導入について、要件の確認と今後の進め方を整理することです。
顧客(田中):
佐藤さん、こちらこそありがとうございます。現場からも問い合わせ対応に時間がかかっているという声があり、改善策を探しているところです。
営業(佐藤):
承知しました。先日お伝えしたシステムでは、問い合わせ履歴を自動で分類し、FAQを提示する機能があります。これにより一次対応の時間短縮が期待できます。
顧客(田中):
それはありがたいですね。ただ、現場からは「既存データとの連携が大丈夫か」という懸念も出ています。
営業(佐藤):
その点については、既存の顧客管理システムとAPIで接続可能です。デモ環境でも同様の連携を確認済みです。
顧客(田中):
なるほど。では、導入コストと運用コストを教えていただけますか。
営業(佐藤):
初期導入費用は約150万円、月額利用料はユーザー数に応じて変動しますが、今回の規模ですと30万円程度になります。
顧客(田中):
ありがとうございます。予算感としては想定内ですが、社内稟議を通すためにROIの見込みも示したいです。
営業(佐藤):
はい。導入によって問い合わせ対応の人件費を年間で約20%削減できると見込んでいます。その試算資料を後ほどお送りします。
顧客(田中):
助かります。スケジュール感としては、早ければ来月から検証に入りたいと思っています。
営業(佐藤):
問題ありません。来週中にPoC環境を準備しますので、そちらで実際の業務フローに即した検証を進めていただけます。
顧客(田中):
了解しました。社内で関係部署に説明し、検証体制を整えます。
営業(佐藤):
ありがとうございます。本日の内容を整理して議事録をお送りします。次回は来週金曜、検証環境を踏まえた進捗確認の場を設けましょう。
顧客(田中):
よろしくお願いいたします。今日はありがとうございました。
今回試すコードは以下です。
import textwrap, os
import langextract as lx
import pandas as pd
# --- プロンプト定義
prompt = textwrap.dedent("""\
次の会話文を議事録として整理してください。
抽出するクラスは以下の3つです:
- attendee: 出席者(name, role)
- decision: 決定事項(summary, owner)
- action_item: ToDo(task, owner, due_date)
必ず原文にある表現をそのまま使い、意訳や創作は避けてください。
日付・期限は見つかった場合だけ抽出してください。
""")
# --- few-shot 例
examples = [
lx.data.ExampleData(
text="営業(佐藤): 来週中にPoC環境を準備します。",
extractions=[
lx.data.Extraction(
extraction_class="attendee",
extraction_text="佐藤",
attributes={"role": "営業"}
),
lx.data.Extraction(
extraction_class="decision",
extraction_text="PoC環境を準備",
attributes={"summary": "来週中にPoC環境を準備する", "owner": "佐藤"}
),
lx.data.Extraction(
extraction_class="action_item",
extraction_text="PoC環境を準備",
attributes={"task": "PoC環境を準備", "owner": "佐藤", "due_date": "来週中"}
),
],
)
]
# --- 入力テキスト
TXT_PATH = "/content/drive/MyDrive/develop/Elcamy/LangExtract/sample1.txt"
with open(TXT_PATH, "r", encoding="utf-8") as f:
input_text = f.read()
# --- 抽出実行
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
# --- DataFrame 化
rows = [e.to_dict() if hasattr(e, "to_dict") else (e.model_dump() if hasattr(e, "model_dump") else e.__dict__)
for e in result.extractions]
df = pd.DataFrame(rows)
df = df[df["extraction_text"].notna() & (df["extraction_text"] != "")]
df = df[["extraction_class", "extraction_text", "attributes"]]
display(df)コード解説
-
プロンプト定義
pythonprompt = textwrap.dedent("""\ 次の会話文を議事録として整理してください。 抽出するクラスは以下の3つです: - attendee: 出席者(name, role) - decision: 決定事項(summary, owner) - action_item: ToDo(task, owner, due_date) 必ず原文にある表現をそのまま使い、意訳や創作は避けてください。 日付・期限は見つかった場合だけ抽出してください。 """)
ここでは、モデルに「どのような情報を抽出するか」を指示しています。
attendee:会議の出席者。extraction_textには名前を入れ、attributesには役割(営業・顧客など)を格納します。decision:会議中に合意された決定事項。summaryに内容、ownerに決定を下した人を入れます。action_item:ToDo(行動項目)。taskに具体的な作業内容、ownerに担当者、due_dateに期限を入れます。
-
few-shot 例の設定
pythonexamples = [ lx.data.ExampleData( text="営業(佐藤): 来週中にPoC環境を準備します。", extractions=[ lx.data.Extraction( extraction_class="attendee", extraction_text="佐藤", attributes={"role": "営業"} ), lx.data.Extraction( extraction_class="decision", extraction_text="PoC環境を準備", attributes={"summary": "来週中にPoC環境を準備する", "owner": "佐藤"} ), lx.data.Extraction( extraction_class="action_item", extraction_text="PoC環境を準備", attributes={"task": "PoC環境を準備", "owner": "佐藤", "due_date": "来週中"} ), ], ) ]
この例では、attendee として「佐藤」という名前を抽出し、その属性 role に「営業」が設定されています。これにより、モデルは「出席者の名前と役割をペアで取り出すべきだ」というパターンを学習できます。
同様に、decision では「PoC環境を準備」という決定事項を抜き出し、owner として「佐藤」を紐付けています。
さらに action_item では、同じ内容を「ToDo」として抽出し、担当者(owner)と期限(due_date)を属性に追加しています。例えば、attendee では「佐藤」という名前を抽出し、属性 role に「営業」が入っています。これによりモデルは「名前と役割をセットで抽出すべきだ」と理解できます。
-
入力テキストの読み込み
pythonTXT_PATH = "/content/drive/MyDrive/develop/Elcamy/LangExtract/sample1.txt" with open(TXT_PATH, "r", encoding="utf-8") as f: input_text = f.read()
Google Drive 上に保存したテキストファイル(ここでは会議の議事録サンプル)を読み込みます。
-
抽出の実行
pythonresult = lx.extract( text_or_documents=input_text, prompt_description=prompt, examples=examples, model_id="gemini-2.5-flash", )
lx.extract に入力テキスト・プロンプト・few-shot例を渡し、抽出を実行します。
-
DataFrame に整形
pythonrows = [e.to_dict() if hasattr(e, "to_dict") else (e.model_dump() if hasattr(e, "model_dump") else e.__dict__) for e in result.extractions] df = pd.DataFrame(rows) df = df[df["extraction_text"].notna() & (df["extraction_text"] != "")] df = df[["extraction_class", "extraction_text", "attributes"]] display(df)
結果を Pandas DataFrame に変換し、必要な列だけを表示するように整形しています。 まず抽出結果をリストにまとめて DataFrame 化し、その後で
extraction_textが 空や null の行は削除extraction_class、extraction_text、attributesの 3列だけを残す という処理を行っています。
結果と評価
今回の「短いテキスト」の実行結果では、出席者(営業=佐藤、顧客=田中)が正しく抽出されました。
さらに、「佐藤」による「試算資料を送る」、「PoC環境を準備」、「議事録を送る」などの 具体的なToDo が検出され、「田中」側の「検証体制を整える」も拾えています。また、「PoC環境を準備」や「進捗確認の場を設ける」といった 決定事項と対応するToDo が両方抽出され、議事録として必要な要点が網羅されている点は良好です。
一方で、action_itemとdecisionが同じ内容で重複して出力されている部分もあるため、今後はルール調整や後処理で整理するとさらに見やすくなると思います。
| index | extraction_class | extraction_text | attributes |
|---|---|---|---|
| 0 | attendee | 佐藤 | {'role': '営業'} |
| 1 | attendee | 田中 | {'role': '顧客'} |
| 2 | action_item | 試算資料を後ほどお送りします | {'task': '試算資料を送る', 'owner': '佐藤', 'due_date': '後ほど'} |
| 3 | decision | 来週中にPoC環境を準備 | {'summary': '来週中にPoC環境を準備する', 'owner': '佐藤'} |
| 4 | action_item | 来週中にPoC環境を準備します | {'task': 'PoC環境を準備', 'owner': '佐藤', 'due_date': '来週中'} |
| 5 | action_item | 社内で関係部署に説明し、検証体制を整えます | {'task': '社内で関係部署に説明し、検証体制を整える', 'owner': '田中', 'due_date': 'null'} |
| 6 | action_item | 本日の内容を整理して議事録をお送りします | {'task': '本日の内容を整理して議事録を送る', 'owner': '佐藤', 'due_date': 'null'} |
| 7 | decision | 次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける | {'summary': '次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける', 'owner': '佐藤'} |
| 8 | action_item | 次回は来週金曜、検証環境を踏まえた進捗確認の場を設けましょう | {'task': '次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける', 'owner': '佐藤', 'due_date': '来週金曜'} |
JSON での出力
[
{
"extraction_class": "attendee",
"extraction_text": "佐藤",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {
"role": "営業"
}
},
{
"extraction_class": "attendee",
"extraction_text": "田中",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": {
"role": "顧客"
}
},
{
"extraction_class": "action_item",
"extraction_text": "試算資料を後ほどお送りします",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": {
"task": "試算資料を送る",
"owner": "佐藤",
"due_date": "後ほど"
}
},
{
"extraction_class": "decision",
"extraction_text": "来週中にPoC環境を準備",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": {
"summary": "来週中にPoC環境を準備する",
"owner": "佐藤"
}
},
{
"extraction_class": "action_item",
"extraction_text": "来週中にPoC環境を準備します",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": {
"task": "PoC環境を準備",
"owner": "佐藤",
"due_date": "来週中"
}
},
{
"extraction_class": "action_item",
"extraction_text": "社内で関係部署に説明し、検証体制を整えます",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": {
"task": "社内で関係部署に説明し、検証体制を整える",
"owner": "田中",
"due_date": "null"
}
},
{
"extraction_class": "action_item",
"extraction_text": "本日の内容を整理して議事録をお送りします",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": {
"task": "本日の内容を整理して議事録を送る",
"owner": "佐藤",
"due_date": "null"
}
},
{
"extraction_class": "decision",
"extraction_text": "次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 8,
"group_index": 7,
"description": null,
"attributes": {
"summary": "次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける",
"owner": "佐藤"
}
},
{
"extraction_class": "action_item",
"extraction_text": "次回は来週金曜、検証環境を踏まえた進捗確認の場を設けましょう",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 9,
"group_index": 8,
"description": null,
"attributes": {
"task": "次回は来週金曜、検証環境を踏まえた進捗確認の場を設ける",
"owner": "佐藤",
"due_date": "来週金曜"
}
}
]長いテキスト
次は、4000文字程度の長いテキストを試します。今回は以下の議事録のサンプルを試します。sample2.txtという名前で保存してください。
【議事録】新規プロダクト開発キックオフ(仮称:Project Lumen)
■日時
2025年9月21日 10:00–11:30(オンライン)
■参加者
PM:中村、PdM:伊藤、開発(BE):佐々木、開発(FE):王、ML:高橋、QA:山本、デザイナー:小林、SRE:鈴木、CS:森、営業:田辺、法務:三浦、マーケ:大島、経理:吉田
■目的
次期四半期内にMVPをリリースするため、狙う顧客像、提供価値、MVP範囲、役割分担、マイルストーン、リスクと対策を合意する。
■背景
既存顧客のオンボーディングに平均14日を要し、初月解約率が8.3%と高止まり。営業デモから本番運用までの設定作業が複雑で、ユーザー自身による初期設定完了率が41%に留まる。自動化とガイド付UIで初期価値到達時間(TTFV)の短縮が喫緊課題。
■プロダクト仮説(Problem/Solution)
* ターゲット:従業員50–500名のB2B SaaS利用企業の事業部門。情シス専任ではなく、現場がツール導入を主導するケースが多い。
* 課題:導入初期に「何から設定すべきか」が不明瞭で、設定漏れや誤設定が増える。学習コストが高い。
* 提案解:ユースケース選択式のセットアップウィザード、サンプルデータ投入、チェックリスト、AIガイド(手順提案・設定値補完)を統合した「スタートセンター」を提供する。
■MVP範囲(合意)
1. セットアップウィザード(3ユースケース)
* 「問い合わせ管理の自動化」「週次レポート共有」「権限テンプレート適用」
2. サンプルデータ投入(疑似チケット100件、レポート雛形3種)
3. チェックリスト(15項目、達成率可視化)
4. AIガイド(候補設定の提案、説明、根拠リンク表示)※英語/日本語対応
5. 監査ログとロールバック(設定変更の差分記録、直近5ステップまで戻す)
非MVP:モバイル版、SSO連携の一部、複雑な権限継承、外部課金連携
■成功指標(MVP)
* TTFV中央値を14日→5日へ
* 初期設定完了率 41%→75%
* 初月解約率 8.3%→5.0%
* サポート初回返信までの前処理時間を30%削減
* NPS +10pt(オンボーディング直後のミニ調査)
■アーキテクチャと非機能
* FE:Next.js + TypeScript。ガイドはクライアントでステップ管理、条件分岐はサーバ配信。
* BE:Python/FastAPI、設定プリセットはFeature Flagで配信。監査ログはAppend-only(BigQuery)に集約。
* AI:LangExtractでヘルプ・ナレッジから手順を抽出し、候補値を提示。提案根拠として原文スニペットを表示。
* SRE:初期は単一リージョン。RPO 24h、RTO 4h。エラーバジェット0.5%。DatadogでSLO可視化。
* セキュリティ:設定変更は二段階承認オプション、PII遮蔽のプレビュー、設定エクスポートは暗号化。
■UX要件
* 初回アクセス時にユースケース選択→自動で必要メニューだけ表示(情報過多を回避)
* チェックリストは「推奨順」で並び替え。各項目に目安時間、難易度、影響範囲のラベル
* エラー時は回復手順を同画面に表示。問い合わせ導線は右下に固定
■スケジュール(合意)
* 9/30 仕様凍結(Spec Freeze)
* 10/7 デザインv1.0
* 10/21 機能フリーズ(コードフリーズ手前)
* 10/28 MVPコードフリーズ
* 11/4 内部QA完了
* 11/11 ベータ開始(10社)
* 12/2 一般提供(GA)判断会議
■役割分担
* 要件・KPI:伊藤(最終責任)、中村
* 仕様・優先度:伊藤、各リード合議
* FE:王(TL)、小林(UI支援)
* BE:佐々木(TL)
* ML/AI:高橋(LangExtractの抽出設計・精度監視)
* QA:山本(試験計画、受け入れ条件)
* SRE:鈴木(SLO、リリース手順、ロールバック)
* CS:森(ヘルプ改稿、チェックリスト文言)
* 営業:田辺(ベータ顧客調整)
* 法務:三浦(利用規約の改定、ログ保持)
* 経理:吉田(価格・原価試算)
■依存関係・前提
* ベータ顧客10社の協力確約(9/27までにNDA締結)
* ナレッジ基盤の最新化(CSが10/1までにFAQタグ付け)
* 旧オンボード手順からの移行ガイド作成(CS+PM)
■リスクと対策
1. AI提案の誤りで設定事故が発生
* 対策:提案は「シミュレーション」表示を原則。適用時に差分確認、元に戻すボタン常設。説明責任として根拠リンク必須。
2. 初回負荷集中により遅延
* 対策:サンプル投入はジョブに切り出し、進捗バーと通知。SLO逸脱時は自動で同時実行数を制限。
3. 権限モデルが複雑化
* 対策:MVPはテンプレ3種に絞る。例外要望はバックログ化し、GA後に検討。
4. ベータ顧客の利用が進まない
* 対策:週次伴走、セットアップ代行スロットを用意。KPI未達傾向の企業にはCSが介入。
■価格とパッケージ(方向性)
* スターター:月額5万円(ユーザー数50まで、AIガイドは月200提案まで)
* スタンダード:月額15万円(ユーザー数200まで、API上限拡大、監査ログ保持1年)
* エンタープライズ:個別見積(SLA、監査要件対応)
■データ計測
* TTFVは「初回ログインからチェックリスト80%達成」までを計測
* 「提案→採用」率、「提案→却下」理由をイベントで収集
* ガイド離脱点をスクリーンID単位で記録
■コミュニケーション計画
* 週次ステータス(火曜 AM)をConfluenceに掲載
* ベータ10社には木曜夕方に小更新レポート
* 重大インシデント時はSlack #lumen-incident で即時共有
■議論要旨
* 王:チェックリストは最大15項目だが、画面では5項目ずつ段階表示にしたい。完了の瞬間に関連項目を解放する設計が望ましい。
* 佐々木:監査ログは差分形式にし、設定JSONを保存。ロールバックはAPI側でスナップショットを持つ。
* 高橋:LangExtractはFAQと手順書から「次の推奨アクション」を抽出する。誤抽出監視のため、提案と採用結果を学習ログに残す。
* 山本:受け入れ条件は「3ユースケースでTTFV中央値5日以下を社内検証で確認」。E2EはPlaywrightで自動化。
* 三浦:AIガイドの根拠表示では、ライセンス/引用ポリシーに準拠すること。監査ログ保持期間はプランに応じた上限を明記。
* 田辺:ベータ企業の業務カレンダーを確認し、月初の繁忙を避ける。初回同席を2時間確保したい。
* 鈴木:インフラは一旦東京リージョン。海外アクセスはCDNで吸収。GA前に冗長化を再評価。
■決定事項
* MVP範囲5項目で合意。非MVPはバックログへ。
* マイルストーンは上記日程で進行。遅延時は翌営業日までにリカバリ案を提示。
* 受け入れ基準は「TTFV中央値5日以下」「設定完了率75%以上」。満たせない場合はGA延期。
* ベータ企業10社のNDA締結期限を9/27に設定。
■アクションアイテム
* 伊藤:仕様凍結前に優先度再確認(9/27)
* 王:チェックリストUIの段階表示プロト作成(10/4)
* 佐々木:監査ログ差分APIの設計ドラフト(10/2)
* 高橋:LangExtract抽出プロンプトv0と評価指標案(10/3)
* 山本:E2Eシナリオ草案とデータ準備(10/7)
* 鈴木:サンプル投入ジョブのスロット制御PoC(10/3)
* 森:FAQタグ付け更新と用語統一リスト(10/1)
* 田辺:ベータ10社の日程確定とNDA回収(9/27)
* 三浦:規約改定ドラフトとログ保持方針(10/8)
* 吉田:価格試算と損益分岐の整理(10/9)
■次回
2025年9月26日(金)10:00–11:00。進捗確認とデザインv1.0レビュー。
■マーケ・販売計画(要点)
* ベータ期は既存顧客の増設案件を中心に実証。導入支援をセットで提供し、ケーススタディを3件作成。
* GA時は「TTFV短縮」を前面に出したLPを新設し、導入前後の効果比較を可視化。検索連動と比較サイトへの掲載を同時展開。
* 価格はスターターの値頃感を重視し、アップセルの軸を「AI提案上限」「監査保持」「SLA」で設計。
■ローカライズ/アクセシビリティ
* 日本語/英語は同時提供。右から左の言語は非MVP。日英で表記ゆれ辞書をCSと共有。
* コントラスト比、キーボード操作、スクリーンリーダー対応をWCAG 2.2 AA準拠でチェック。
■データ移行
* 既存テナントはウィザード導入時に影響無し。希望者のみチェックリストを有効化。
* 旧手順のブックマークが残る点はリダイレクトで吸収。操作履歴は新旧で共通フォーマットに変換。
■未決事項(オープンクエスチョン)
* AI提案の生成回数超過時のUX(ハードブロックか、精度低下モードか)。
* 監査ログの可視化粒度(ユーザー向けは集約、開発向けは詳細)をどこまでとするか。今回試すコードは以下です。
import textwrap, os
import langextract as lx
import pandas as pd
# --- プロンプト定義
prompt = textwrap.dedent("""\
以下の議事録テキストから、次の3クラスのみ抽出してJSONで返す。
- attendee: 出席者(name, role)
- decision: 決定事項(summary, owner)
- action_item: ToDo(task, owner, due_date)
厳格ルール:
1) 原文にある語句だけを extraction_text に用いる。意訳・生成は禁止。
2) 存在しないクラスは一切出力しない。空文字・nullの extraction_text は出力しない。
3) owner は原則、役割や文脈により明示される個人名を用いる。曖昧なら空ではなく出力対象外。
""")
# --- few-shot 例
examples = [
# 1) 出席者
lx.data.ExampleData(
text="出席者は、PMの中村、開発の佐藤である。",
extractions=[
lx.data.Extraction(
extraction_class="attendee",
extraction_text="中村",
attributes={"role": "PM"}
),
lx.data.Extraction(
extraction_class="attendee",
extraction_text="佐藤",
attributes={"role": "開発"}
),
],
),
# 2) 決定事項(ownerが会議)
lx.data.ExampleData(
text="会議はMVPのリリース日を10月末にすることで合意した。",
extractions=[
lx.data.Extraction(
extraction_class="decision",
extraction_text="MVPのリリース日を10月末にすることで合意",
attributes={"summary": "MVPのリリース日を10月末にする", "owner": "会議"}
),
],
),
# 3) ToDo(owner + due_dateあり)
lx.data.ExampleData(
text="高橋は、10月15日までにテスト計画を提出する。",
extractions=[
lx.data.Extraction(
extraction_class="action_item",
extraction_text="テスト計画を提出",
attributes={"task": "テスト計画を提出", "owner": "高橋", "due_date": "10月15日"}
),
],
),
]
# --- 入力テキスト
TXT_PATH = "/content/drive/MyDrive/develop/Elcamy/LangExtract/sample2.txt"
with open(TXT_PATH, "r", encoding="utf-8") as f:
input_text = f.read()
# --- 抽出実行
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
# --- DataFrame 化
rows = [e.to_dict() if hasattr(e, "to_dict") else e.__dict__ for e in result.extractions]
df = pd.DataFrame(rows)
df = df[df["extraction_text"].notna() & (df["extraction_text"] != "")].copy()
df = df[["extraction_class", "extraction_text", "attributes"]]
display(df)コード解説
-
プロンプト定義
pythonprompt = textwrap.dedent("""\ 以下の議事録テキストから、次の3クラスのみ抽出してJSONで返す。 - attendee: 出席者(name, role) - decision: 決定事項(summary, owner) - action_item: ToDo(task, owner, due_date) 厳格ルール: 1) 原文にある語句だけを extraction_text に用いる。意訳・生成は禁止。 2) 存在しないクラスは一切出力しない。空文字・nullの extraction_text は出力しない。 3) owner は原則、役割や文脈により明示される個人名を用いる。曖昧なら空ではなく出力対象外。 """)
ここでは、モデルに「どのような情報を抽出するか」を指示しています。
attendee:会議の出席者。extraction_textには名前を入れ、attributesには役割(例:PM、開発など)を格納します。decision:会議中に合意された決定事項。summaryに内容、ownerに決定を下した人や会議体を入れます。action_item:ToDo(行動項目)。taskに具体的な作業内容、ownerに担当者、due_dateに期限を入れます。
-
few-shot 例の設定
pythonexamples = [ # 1) 出席者 lx.data.ExampleData( text="出席者は、PMの中村、開発の佐藤である。", extractions=[ lx.data.Extraction(extraction_class="attendee", extraction_text="中村", attributes={"role": "PM"}), lx.data.Extraction(extraction_class="attendee", extraction_text="佐藤", attributes={"role": "開発"}), ], ),
参加者を列挙した文から 人名をそのまま** **extraction_text にし、attributes.role に役割を入れる例を示しています。
# 2) 決定事項(owner が会議)
lx.data.ExampleData(
text="会議はMVPのリリース日を10月末にすることで合意した。",
extractions=[
lx.data.Extraction(
extraction_class="decision",
extraction_text="MVPのリリース日を10月末にすることで合意",
attributes={"summary": "MVPのリリース日を10月末にする", "owner": "会議"}
),
],
),決定文から要旨をsummary に整理します。主語が個人でなければ owner に「会議」 を入れる型を示しています。
# 3) ToDo(owner + due_dateあり)
lx.data.ExampleData(
text="高橋は、10月15日までにテスト計画を提出する。",
extractions=[
lx.data.Extraction(
extraction_class="action_item",
extraction_text="テスト計画を提出",
attributes={"task": "テスト計画を提出", "owner": "高橋", "due_date": "10月15日"}
),
],
),
]ToDoは task、owner、due_date の3つを明示します。期限が明記されるケースの形を教えています。
-
ハイライト表示 このセクションでは、抽出結果をハイライト付き HTML として保存・表示しています。Google Colab 上で実行し、可視化できるようにしています。
pythonOUT_DIR = "/content" OUT_JSONL = "extraction_results.jsonl" OUT_HTML = "extraction_results.html"
出力先ディレクトリと、JSONLファイル・HTMLファイルのファイル名を定義しています。
lx.io.save_annotated_documents([result], output_name=OUT_JSONL, output_dir=OUT_DIR)ここでは、抽出結果(result)を JSONL 形式で保存しています。このファイルには、抽出クラスや char_interval などのメタ情報が含まれます。
viz = lx.visualize(os.path.join(OUT_DIR, OUT_JSONL))保存した JSONL を読み込み、可視化用の HTML データを生成します。
# viz が HTMLオブジェクトでも文字列でもOKにする
html_str = viz.data if hasattr(viz, "data") else vizvisualize の戻り値は環境によってオブジェクト型や文字列型になるため、どちらでも対応できるように変換しています。
# ノートブックに表示
display(HTML(html_str))生成された HTML を Colab のノートブック内に表示します。抽出対象(Entity)が元のテキスト内でハイライトされ、視覚的に確認できます。
# ファイルにも保存
with open(os.path.join(OUT_DIR, OUT_HTML), "w", encoding="utf-8") as f:
f.write(html_str)同じHTMLをファイルとして保存します。これにより、Colab外でもブラウザで開いて確認できます。
print(f"Saved: {os.path.join(OUT_DIR, OUT_JSONL)}")
print(f"Saved: {os.path.join(OUT_DIR, OUT_HTML)}")最後に保存先をログ出力して、確認できるようにしています。
結果と評価
今回の出力では、出席者、決定事項、ToDo がバランスよく抽出されており、役割や期限付きタスクも正しく拾えています。一方で、同じ人物が複数回出てきたり、decisionとaction_item が重複したり、一部の決定事項で owner が空になるケースが見られました。重複排除やdecisionとaction_itemの優先ルールを後処理で適用すれば、より整理された結果になると思います。
| index | extraction_class | extraction_text | attributes |
|---|---|---|---|
| 0 | attendee | 中村 | {'role': 'PM'} |
| 1 | attendee | 伊藤 | {'role': 'PdM'} |
| 2 | attendee | 佐々木 | {'role': '開発(BE)'} |
| 3 | attendee | 王 | {'role': '開発(FE)'} |
| 4 | attendee | 高橋 | {'role': 'ML'} |
| 5 | attendee | 山本 | {'role': 'QA'} |
| 6 | attendee | 小林 | {'role': 'デザイナー'} |
| 7 | attendee | 鈴木 | {'role': 'SRE'} |
| 8 | attendee | 森 | {'role': 'CS'} |
| 9 | attendee | 田辺 | {'role': '営業'} |
| 10 | attendee | 三浦 | {'role': '法務'} |
| 11 | attendee | 大島 | {'role': 'マーケ'} |
| 12 | attendee | 吉田 | {'role': '経理'} |
| 13 | decision | 狙う顧客像、提供価値、MVP範囲、役割分担、マイルストーン、リスクと対策を合意する | {'summary': '狙う顧客像、提供価値、MVP範囲、役割分担、マイルストーン、リスクと対策を合意する'} |
| 14 | decision | セットアップウィザード(3ユースケース) | {'summary': 'セットアップウィザード(3ユースケース)'} |
| 15 | decision | サンプルデータ投入(疑似チケット100件、レポート雛形3種) | {'summary': 'サンプルデータ投入(疑似チケット100件、レポート雛形3種)'} |
| 16 | decision | チェックリスト(15項目、達成率可視化) | {'summary': 'チェックリスト(15項目、達成率可視化)'} |
| 17 | decision | AIガイド(候補設定の提案、説明、根拠リンク表示)※英語/日本語対応 | {'summary': 'AIガイド(候補設定の提案、説明、根拠リンク表示)※英語/日本語対応'} |
| 18 | decision | 監査ログとロールバック(設定変更の差分記録、直近5ステップまで戻す) | {'summary': '監査ログとロールバック(設定変更の差分記録、直近5ステップまで戻す)'} |
| 19 | decision | 非MVP:モバイル版、SSO連携の一部、複雑な権限継承、外部課金連携 | {'summary': '非MVP:モバイル版、SSO連携の一部、複雑な権限継承、外部課金連携'} |
| 20 | decision | 9/30 仕様凍結(Spec Freeze) | {'summary': '仕様凍結(Spec Freeze)', 'owner': ''} |
| 21 | decision | 10/7 デザインv1.0 | {'summary': 'デザインv1.0', 'owner': ''} |
| 22 | decision | 10/21 機能フリーズ(コードフリーズ手前) | {'summary': '機能フリーズ(コードフリーズ手前)', 'owner': ''} |
| 23 | decision | 10/28 MVPコードフリーズ | {'summary': 'MVPコードフリーズ', 'owner': ''} |
| 24 | decision | 11/4 内部QA完了 | {'summary': '内部QA完了', 'owner': ''} |
| 25 | decision | 11/11 ベータ開始(10社) | {'summary': 'ベータ開始(10社)', 'owner': ''} |
| 26 | decision | 12/2 一般提供(GA)判断会議 | {'summary': '一般提供(GA)判断会議', 'owner': ''} |
| 27 | attendee | 伊藤 | {'role': '要件・KPI(最終責任)'} |
| 28 | attendee | 中村 | {'role': '要件・KPI'} |
| 29 | attendee | 伊藤 | {'role': '仕様・優先度'} |
| 30 | attendee | 王 | {'role': 'FE(TL)'} |
| 31 | attendee | 小林 | {'role': 'FE(UI支援)'} |
| 32 | attendee | 佐々木 | {'role': 'BE(TL)'} |
| 33 | attendee | 高橋 | {'role': 'ML/AI(LangExtractの抽出設計・精度監視)'} |
| 34 | attendee | 山本 | {'role': 'QA(試験計画、受け入れ条件)'} |
| 35 | attendee | 鈴木 | {'role': 'SRE(SLO、リリース手順、ロールバック)'} |
| 36 | attendee | 森 | {'role': 'CS(ヘルプ改稿、チェックリスト文言)'} |
| 37 | attendee | 田辺 | {'role': '営業(ベータ顧客調整)'} |
| 38 | attendee | 三浦 | {'role': '法務(利用規約の改定、ログ保持)'} |
| 39 | attendee | 吉田 | {'role': '経理(価格・原価試算)'} |
| 40 | action_item | ベータ顧客10社の協力確約 | {'task': 'ベータ顧客10社の協力確約', 'owner': '田辺', 'due_date': '9/27'} |
| 41 | action_item | ナレッジ基盤の最新化 | {'task': 'ナレッジ基盤の最新化', 'owner': '森', 'due_date': '10/1'} |
| 42 | action_item | 旧オンボード手順からの移行ガイド作成 | {'task': '旧オンボード手順からの移行ガイド作成', 'owner': '森, 中村', 'due_date': ''} |
| 43 | decision | 提案は「シミュレーション」表示を原則 | {'summary': '提案は「シミュレーション」表示を原則とする'} |
| 44 | decision | 適用時に差分確認、元に戻すボタン常設 | {'summary': '適用時に差分確認、元に戻すボタンを常設する'} |
| 45 | decision | 説明責任として根拠リンク必須 | {'summary': '説明責任として根拠リンクを必須とする'} |
| 46 | decision | サンプル投入はジョブに切り出し、進捗バーと通知 | {'summary': 'サンプル投入をジョブに切り出し、進捗バーと通知を実装する'} |
| 47 | decision | SLO逸脱時は自動で同時実行数を制限 | {'summary': 'SLO逸脱時は自動で同時実行数を制限する'} |
| 48 | decision | MVPはテンプレ3種に絞る | {'summary': 'MVPのテンプレートを3種に絞る'} |
| 49 | decision | 例外要望はバックログ化し、GA後に検討 | {'summary': '例外要望はバックログ化し、GA後に検討する'} |
| 50 | attendee | 王 | |
| 51 | attendee | 佐々木 | |
| 52 | attendee | 高橋 | |
| 53 | attendee | 山本 | |
| 54 | attendee | 三浦 | |
| 55 | attendee | 田辺 | |
| 56 | attendee | 鈴木 | |
| 57 | decision | MVP範囲5項目で合意。非MVPはバックログへ。 | {'summary': 'MVP範囲5項目で合意。非MVPはバックログへ。'} |
| 58 | decision | マイルストーンは上記日程で進行。遅延時は翌営業日までにリカバリ案を提示。 | {'summary': 'マイルストーンは上記日程で進行。遅延時は翌営業日までにリカバリ案を提示。'} |
| 59 | decision | 受け入れ基準は「TTFV中央値5日以下」「設定完了率75%以上」。満たせない場合はGA延期。 | {'summary': '受け入れ基準は「TTFV中央値5日以下」「設定完了率75%以上」。満たせない場合はGA延期。'} |
| 60 | decision | ベータ企業10社のNDA締結期限を9/27に設定。 | {'summary': 'ベータ企業10社のNDA締結期限を9/27に設定。'} |
| 61 | action_item | 仕様凍結前に優先度再確認 | {'task': '仕様凍結前に優先度再確認', 'owner': '伊藤', 'due_date': '9/27'} |
| 62 | action_item | チェックリストUIの段階表示プロト作成 | {'task': 'チェックリストUIの段階表示プロト作成', 'owner': '王', 'due_date': '10/4'} |
| 63 | action_item | 監査ログ差分APIの設計ドラフト | {'task': '監査ログ差分APIの設計ドラフト', 'owner': '佐々木', 'due_date': '10/2'} |
| 64 | action_item | LangExtract抽出プロンプトv0と評価指標案 | {'task': 'LangExtract抽出プロンプトv0と評価指標案', 'owner': '高橋', 'due_date': '10/3'} |
| 65 | action_item | E2Eシナリオ草案とデータ準備 | {'task': 'E2Eシナリオ草案とデータ準備', 'owner': '山本', 'due_date': '10/7'} |
| 66 | action_item | サンプル投入ジョブのスロット制御PoC | {'task': 'サンプル投入ジョブのスロット制御PoC', 'owner': '鈴木', 'due_date': '10/3'} |
| 67 | action_item | FAQタグ付け更新と用語統一リスト | {'task': 'FAQタグ付け更新と用語統一リスト', 'owner': '森', 'due_date': '10/1'} |
| 68 | action_item | ベータ10社の日程確定とNDA回収 | {'task': 'ベータ10社の日程確定とNDA回収', 'owner': '田辺', 'due_date': '9/27'} |
| 69 | action_item | 規約改定ドラフトとログ保持方針 | {'task': '規約改定ドラフトとログ保持方針', 'owner': '三浦', 'due_date': '10/8'} |
| 70 | action_item | 価格試算と損益分岐の整理 | {'task': '価格試算と損益分岐の整理', 'owner': '吉田', 'due_date': '10/9'} |
JSON での出力
[
{
"extraction_class": "attendee",
"extraction_text": "中村",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {
"role": "PM"
}
},
{
"extraction_class": "attendee",
"extraction_text": "伊藤",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": {
"role": "PdM"
}
},
{
"extraction_class": "attendee",
"extraction_text": "佐々木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": {
"role": "開発(BE)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "王",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": {
"role": "開発(FE)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "高橋",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": {
"role": "ML"
}
},
{
"extraction_class": "attendee",
"extraction_text": "山本",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": {
"role": "QA"
}
},
{
"extraction_class": "attendee",
"extraction_text": "小林",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": {
"role": "デザイナー"
}
},
{
"extraction_class": "attendee",
"extraction_text": "鈴木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 8,
"group_index": 7,
"description": null,
"attributes": {
"role": "SRE"
}
},
{
"extraction_class": "attendee",
"extraction_text": "森",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 9,
"group_index": 8,
"description": null,
"attributes": {
"role": "CS"
}
},
{
"extraction_class": "attendee",
"extraction_text": "田辺",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 10,
"group_index": 9,
"description": null,
"attributes": {
"role": "営業"
}
},
{
"extraction_class": "attendee",
"extraction_text": "三浦",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 11,
"group_index": 10,
"description": null,
"attributes": {
"role": "法務"
}
},
{
"extraction_class": "attendee",
"extraction_text": "大島",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 12,
"group_index": 11,
"description": null,
"attributes": {
"role": "マーケ"
}
},
{
"extraction_class": "attendee",
"extraction_text": "吉田",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 13,
"group_index": 12,
"description": null,
"attributes": {
"role": "経理"
}
},
{
"extraction_class": "decision",
"extraction_text": "狙う顧客像、提供価値、MVP範囲、役割分担、マイルストーン、リスクと対策を合意する",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 14,
"group_index": 13,
"description": null,
"attributes": {
"summary": "狙う顧客像、提供価値、MVP範囲、役割分担、マイルストーン、リスクと対策を合意する"
}
},
{
"extraction_class": "decision",
"extraction_text": "セットアップウィザード(3ユースケース)",
"char_interval": "CharInterval(start_pos=612, end_pos=632)",
"_token_interval": "TokenInterval(start_index=81, end_index=84)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 15,
"group_index": 14,
"description": null,
"attributes": {
"summary": "セットアップウィザード(3ユースケース)"
}
},
{
"extraction_class": "decision",
"extraction_text": "サンプルデータ投入(疑似チケット100件、レポート雛形3種)",
"char_interval": "CharInterval(start_pos=678, end_pos=708)",
"_token_interval": "TokenInterval(start_index=88, end_index=93)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 16,
"group_index": 15,
"description": null,
"attributes": {
"summary": "サンプルデータ投入(疑似チケット100件、レポート雛形3種)"
}
},
{
"extraction_class": "decision",
"extraction_text": "チェックリスト(15項目、達成率可視化)",
"char_interval": "CharInterval(start_pos=712, end_pos=732)",
"_token_interval": "TokenInterval(start_index=95, end_index=98)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 17,
"group_index": 16,
"description": null,
"attributes": {
"summary": "チェックリスト(15項目、達成率可視化)"
}
},
{
"extraction_class": "decision",
"extraction_text": "AIガイド(候補設定の提案、説明、根拠リンク表示)※英語/日本語対応",
"char_interval": "CharInterval(start_pos=736, end_pos=770)",
"_token_interval": "TokenInterval(start_index=100, end_index=102)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 18,
"group_index": 17,
"description": null,
"attributes": {
"summary": "AIガイド(候補設定の提案、説明、根拠リンク表示)※英語/日本語対応"
}
},
{
"extraction_class": "decision",
"extraction_text": "監査ログとロールバック(設定変更の差分記録、直近5ステップまで戻す)",
"char_interval": "CharInterval(start_pos=774, end_pos=808)",
"_token_interval": "TokenInterval(start_index=104, end_index=107)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 19,
"group_index": 18,
"description": null,
"attributes": {
"summary": "監査ログとロールバック(設定変更の差分記録、直近5ステップまで戻す)"
}
},
{
"extraction_class": "decision",
"extraction_text": "非MVP:モバイル版、SSO連携の一部、複雑な権限継承、外部課金連携",
"char_interval": "CharInterval(start_pos=812, end_pos=846)",
"_token_interval": "TokenInterval(start_index=107, end_index=112)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 20,
"group_index": 19,
"description": null,
"attributes": {
"summary": "非MVP:モバイル版、SSO連携の一部、複雑な権限継承、外部課金連携"
}
},
{
"extraction_class": "decision",
"extraction_text": "9/30 仕様凍結(Spec Freeze)",
"char_interval": "CharInterval(start_pos=1428, end_pos=1450)",
"_token_interval": "TokenInterval(start_index=211, end_index=216)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {
"summary": "仕様凍結(Spec Freeze)",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "10/7 デザインv1.0",
"char_interval": "CharInterval(start_pos=1453, end_pos=1466)",
"_token_interval": "TokenInterval(start_index=217, end_index=223)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": {
"summary": "デザインv1.0",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "10/21 機能フリーズ(コードフリーズ手前)",
"char_interval": "CharInterval(start_pos=1469, end_pos=1492)",
"_token_interval": "TokenInterval(start_index=224, end_index=226)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": {
"summary": "機能フリーズ(コードフリーズ手前)",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "10/28 MVPコードフリーズ",
"char_interval": "CharInterval(start_pos=1495, end_pos=1511)",
"_token_interval": "TokenInterval(start_index=227, end_index=230)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": {
"summary": "MVPコードフリーズ",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "11/4 内部QA完了",
"char_interval": "CharInterval(start_pos=1514, end_pos=1525)",
"_token_interval": "TokenInterval(start_index=231, end_index=235)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": {
"summary": "内部QA完了",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "11/11 ベータ開始(10社)",
"char_interval": "CharInterval(start_pos=1528, end_pos=1544)",
"_token_interval": "TokenInterval(start_index=236, end_index=240)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": {
"summary": "ベータ開始(10社)",
"owner": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "12/2 一般提供(GA)判断会議",
"char_interval": "CharInterval(start_pos=1547, end_pos=1564)",
"_token_interval": "TokenInterval(start_index=241, end_index=245)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": {
"summary": "一般提供(GA)判断会議",
"owner": ""
}
},
{
"extraction_class": "attendee",
"extraction_text": "伊藤",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 8,
"group_index": 7,
"description": null,
"attributes": {
"role": "要件・KPI(最終責任)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "中村",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 9,
"group_index": 8,
"description": null,
"attributes": {
"role": "要件・KPI"
}
},
{
"extraction_class": "attendee",
"extraction_text": "伊藤",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 10,
"group_index": 9,
"description": null,
"attributes": {
"role": "仕様・優先度"
}
},
{
"extraction_class": "attendee",
"extraction_text": "王",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 11,
"group_index": 10,
"description": null,
"attributes": {
"role": "FE(TL)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "小林",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 12,
"group_index": 11,
"description": null,
"attributes": {
"role": "FE(UI支援)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "佐々木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 13,
"group_index": 12,
"description": null,
"attributes": {
"role": "BE(TL)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "高橋",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 14,
"group_index": 13,
"description": null,
"attributes": {
"role": "ML/AI(LangExtractの抽出設計・精度監視)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "山本",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 15,
"group_index": 14,
"description": null,
"attributes": {
"role": "QA(試験計画、受け入れ条件)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "鈴木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 16,
"group_index": 15,
"description": null,
"attributes": {
"role": "SRE(SLO、リリース手順、ロールバック)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "森",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 17,
"group_index": 16,
"description": null,
"attributes": {
"role": "CS(ヘルプ改稿、チェックリスト文言)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "田辺",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 18,
"group_index": 17,
"description": null,
"attributes": {
"role": "営業(ベータ顧客調整)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "三浦",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 19,
"group_index": 18,
"description": null,
"attributes": {
"role": "法務(利用規約の改定、ログ保持)"
}
},
{
"extraction_class": "attendee",
"extraction_text": "吉田",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 20,
"group_index": 19,
"description": null,
"attributes": {
"role": "経理(価格・原価試算)"
}
},
{
"extraction_class": "action_item",
"extraction_text": "ベータ顧客10社の協力確約",
"char_interval": "CharInterval(start_pos=1822, end_pos=1829)",
"_token_interval": "TokenInterval(start_index=288, end_index=290)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 21,
"group_index": 20,
"description": null,
"attributes": {
"task": "ベータ顧客10社の協力確約",
"owner": "田辺",
"due_date": "9/27"
}
},
{
"extraction_class": "action_item",
"extraction_text": "ナレッジ基盤の最新化",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 22,
"group_index": 21,
"description": null,
"attributes": {
"task": "ナレッジ基盤の最新化",
"owner": "森",
"due_date": "10/1"
}
},
{
"extraction_class": "action_item",
"extraction_text": "旧オンボード手順からの移行ガイド作成",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 23,
"group_index": 22,
"description": null,
"attributes": {
"task": "旧オンボード手順からの移行ガイド作成",
"owner": "森, 中村",
"due_date": ""
}
},
{
"extraction_class": "decision",
"extraction_text": "提案は「シミュレーション」表示を原則",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {
"summary": "提案は「シミュレーション」表示を原則とする"
}
},
{
"extraction_class": "decision",
"extraction_text": "適用時に差分確認、元に戻すボタン常設",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": {
"summary": "適用時に差分確認、元に戻すボタンを常設する"
}
},
{
"extraction_class": "decision",
"extraction_text": "説明責任として根拠リンク必須",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": {
"summary": "説明責任として根拠リンクを必須とする"
}
},
{
"extraction_class": "decision",
"extraction_text": "サンプル投入はジョブに切り出し、進捗バーと通知",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": {
"summary": "サンプル投入をジョブに切り出し、進捗バーと通知を実装する"
}
},
{
"extraction_class": "decision",
"extraction_text": "SLO逸脱時は自動で同時実行数を制限",
"char_interval": "CharInterval(start_pos=2050, end_pos=2053)",
"_token_interval": "TokenInterval(start_index=321, end_index=322)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": {
"summary": "SLO逸脱時は自動で同時実行数を制限する"
}
},
{
"extraction_class": "decision",
"extraction_text": "MVPはテンプレ3種に絞る",
"char_interval": "CharInterval(start_pos=2092, end_pos=2101)",
"_token_interval": "TokenInterval(start_index=328, end_index=331)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": {
"summary": "MVPのテンプレートを3種に絞る"
}
},
{
"extraction_class": "decision",
"extraction_text": "例外要望はバックログ化し、GA後に検討",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": {
"summary": "例外要望はバックログ化し、GA後に検討する"
}
},
{
"extraction_class": "attendee",
"extraction_text": "王",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "佐々木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "高橋",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "山本",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "三浦",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "田辺",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": null
},
{
"extraction_class": "attendee",
"extraction_text": "鈴木",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": null
},
{
"extraction_class": "decision",
"extraction_text": "MVP範囲5項目で合意。非MVPはバックログへ。",
"char_interval": "CharInterval(start_pos=2948, end_pos=2972)",
"_token_interval": "TokenInterval(start_index=448, end_index=454)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 8,
"group_index": 7,
"description": null,
"attributes": {
"summary": "MVP範囲5項目で合意。非MVPはバックログへ。"
}
},
{
"extraction_class": "decision",
"extraction_text": "マイルストーンは上記日程で進行。遅延時は翌営業日までにリカバリ案を提示。",
"char_interval": "CharInterval(start_pos=2975, end_pos=3011)",
"_token_interval": "TokenInterval(start_index=455, end_index=456)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 9,
"group_index": 8,
"description": null,
"attributes": {
"summary": "マイルストーンは上記日程で進行。遅延時は翌営業日までにリカバリ案を提示。"
}
},
{
"extraction_class": "decision",
"extraction_text": "受け入れ基準は「TTFV中央値5日以下」「設定完了率75%以上」。満たせない場合はGA延期。",
"char_interval": "CharInterval(start_pos=3014, end_pos=3060)",
"_token_interval": "TokenInterval(start_index=457, end_index=466)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 10,
"group_index": 9,
"description": null,
"attributes": {
"summary": "受け入れ基準は「TTFV中央値5日以下」「設定完了率75%以上」。満たせない場合はGA延期。"
}
},
{
"extraction_class": "decision",
"extraction_text": "ベータ企業10社のNDA締結期限を9/27に設定。",
"char_interval": "CharInterval(start_pos=3063, end_pos=3088)",
"_token_interval": "TokenInterval(start_index=467, end_index=474)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 11,
"group_index": 10,
"description": null,
"attributes": {
"summary": "ベータ企業10社のNDA締結期限を9/27に設定。"
}
},
{
"extraction_class": "action_item",
"extraction_text": "仕様凍結前に優先度再確認",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 12,
"group_index": 11,
"description": null,
"attributes": {
"task": "仕様凍結前に優先度再確認",
"owner": "伊藤",
"due_date": "9/27"
}
},
{
"extraction_class": "action_item",
"extraction_text": "チェックリストUIの段階表示プロト作成",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {
"task": "チェックリストUIの段階表示プロト作成",
"owner": "王",
"due_date": "10/4"
}
},
{
"extraction_class": "action_item",
"extraction_text": "監査ログ差分APIの設計ドラフト",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 2,
"group_index": 1,
"description": null,
"attributes": {
"task": "監査ログ差分APIの設計ドラフト",
"owner": "佐々木",
"due_date": "10/2"
}
},
{
"extraction_class": "action_item",
"extraction_text": "LangExtract抽出プロンプトv0と評価指標案",
"char_interval": "CharInterval(start_pos=3190, end_pos=3210)",
"_token_interval": "TokenInterval(start_index=493, end_index=497)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 3,
"group_index": 2,
"description": null,
"attributes": {
"task": "LangExtract抽出プロンプトv0と評価指標案",
"owner": "高橋",
"due_date": "10/3"
}
},
{
"extraction_class": "action_item",
"extraction_text": "E2Eシナリオ草案とデータ準備",
"char_interval": "CharInterval(start_pos=3228, end_pos=3231)",
"_token_interval": "TokenInterval(start_index=502, end_index=505)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 4,
"group_index": 3,
"description": null,
"attributes": {
"task": "E2Eシナリオ草案とデータ準備",
"owner": "山本",
"due_date": "10/7"
}
},
{
"extraction_class": "action_item",
"extraction_text": "サンプル投入ジョブのスロット制御PoC",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 5,
"group_index": 4,
"description": null,
"attributes": {
"task": "サンプル投入ジョブのスロット制御PoC",
"owner": "鈴木",
"due_date": "10/3"
}
},
{
"extraction_class": "action_item",
"extraction_text": "FAQタグ付け更新と用語統一リスト",
"char_interval": "CharInterval(start_pos=3285, end_pos=3288)",
"_token_interval": "TokenInterval(start_index=516, end_index=517)",
"alignment_status": "AlignmentStatus.MATCH_LESSER",
"extraction_index": 6,
"group_index": 5,
"description": null,
"attributes": {
"task": "FAQタグ付け更新と用語統一リスト",
"owner": "森",
"due_date": "10/1"
}
},
{
"extraction_class": "action_item",
"extraction_text": "ベータ10社の日程確定とNDA回収",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 7,
"group_index": 6,
"description": null,
"attributes": {
"task": "ベータ10社の日程確定とNDA回収",
"owner": "田辺",
"due_date": "9/27"
}
},
{
"extraction_class": "action_item",
"extraction_text": "規約改定ドラフトとログ保持方針",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 8,
"group_index": 7,
"description": null,
"attributes": {
"task": "規約改定ドラフトとログ保持方針",
"owner": "三浦",
"due_date": "10/8"
}
},
{
"extraction_class": "action_item",
"extraction_text": "価格試算と損益分岐の整理",
"char_interval": null,
"_token_interval": null,
"alignment_status": null,
"extraction_index": 9,
"group_index": 8,
"description": null,
"attributes": {
"task": "価格試算と損益分岐の整理",
"owner": "吉田",
"due_date": "10/9"
}
}
]さらに、HTMLで可視化すると以下のように表示されます。
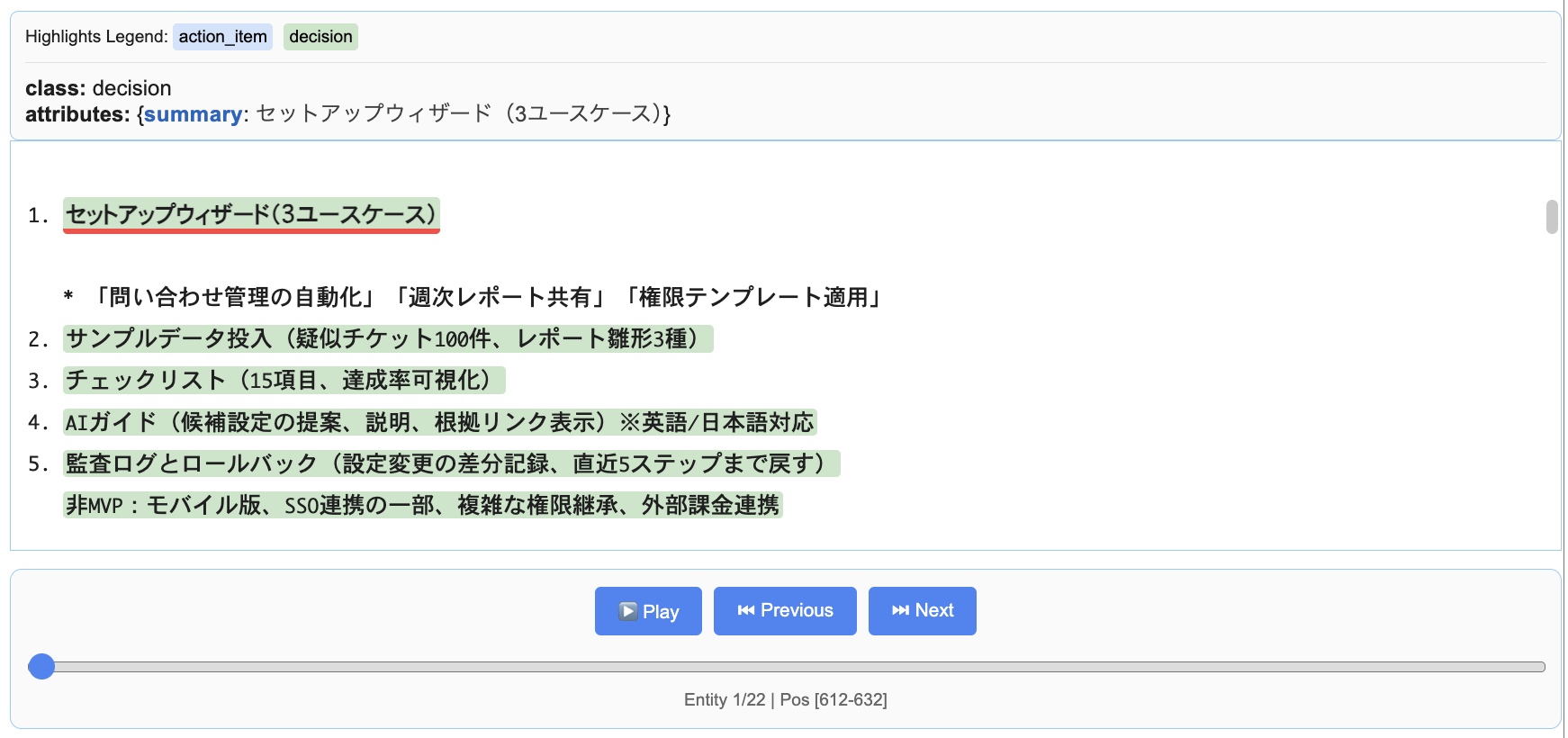 例えば、出力結果の中に以下の行が含まれていました。
例えば、出力結果の中に以下の行が含まれていました。
{
"extraction_class": "decision",
"extraction_text": "セットアップウィザード(3ユースケース)",
"char_interval": "CharInterval(start_pos=612, end_pos=632)",
"_token_interval": "TokenInterval(start_index=81, end_index=84)",
"alignment_status": "AlignmentStatus.MATCH_EXACT",
"extraction_index": 15,
"group_index": 14,
"description": null,
"attributes": {
"summary": "セットアップウィザード(3ユースケース)"
}このとき extraction_text に含まれる 「セットアップウィザード(3ユースケース)」 は、元のテキスト内で実際に記載されていた部分を指しています。
また、char_interval に記録されている「start_pos=612, end_pos=632」は、元のテキストにおける文字位置を表しており、画像では緑色でハイライトされています。
つまり、抽出結果の extraction_text と char_interval の値は、元のドキュメントの具体的な文字列(今回であれば 1行目の「セットアップウィザード(3ユースケース)」)に対応していることがわかります。
複数のテキスト
最後に、複数のテキストを試します。今回は以下の3つの契約書のサンプルを試します。それぞれsample3-1.txt、sample3-2.txt、sample3-3.txtという名前で保存してください
SaaS利用契約書
本契約は、株式会社アルファ(以下「甲」という)と、株式会社ユーザー(以下「乙」という)の間で締結される。
第1条(契約期間)
契約期間は2025年4月1日から2026年3月31日までの1年間とする。期間満了の30日前までに甲または乙から書面による解約の意思表示がない場合、自動的に1年間更新される。
第2条(利用料金)
乙は、月額10万円を甲に支払う。支払方法は毎月末締め翌月末払いとする。
第3条(解約条件)
乙は契約期間中でも、解約希望日の60日前までに通知することで中途解約できる。ただし、未経過期間の残存料金は全額支払うものとする。
第4条(準拠法)
本契約は日本法に準拠する。
ソフトウェアライセンス契約書
株式会社ベータ(以下「甲」)と有限会社ユーザー(以下「乙」)は、次の条件で契約を締結する。
第1条(ライセンス期間)
契約期間は2025年7月1日から無期限とする。ただし、乙が料金支払いを怠った場合、甲は30日の猶予期間をもって解約できる。
第2条(料金)
乙は、初期導入費50万円と、月額利用料5万円を甲に支払う。
第3条(解約条件)
乙はいつでも解約可能だが、解約日の30日前までに甲へ書面通知する必要がある。返金は行わない。
第4条(裁判管轄)
本契約に関する紛争は、東京地方裁判所を第一審の専属的合意管轄裁判所とする。
クラウドサービス利用契約書
本契約は、株式会社ガンマ(以下「甲」)と、合同会社ユーザー(以下「乙」)の間で締結される。
第1条(契約期間)
本契約は2025年1月15日から2025年12月31日まで有効とする。更新は協議のうえ書面合意が必要である。
第2条(利用料金)
乙は、年間120万円を一括前払いする。
第3条(解約条件)
乙は契約期間中の中途解約は原則できない。ただし、甲が重大な契約違反をした場合、乙は即時解約できる。その場合、未経過分の料金は日割りで返金される。
第4条(準拠法・管轄)
本契約は日本法に基づき、福岡地方裁判所を専属的管轄とする。
今回試すコードは以下です。
from pathlib import Path
import textwrap, pandas as pd
import langextract as lx
# --- プロンプト定義
prompt = textwrap.dedent("""\
以下の契約書テキストから、次の4クラスのみ抽出してください。
- contract_period: 契約期間(start_date, end_date, renew)
- fee: 料金(initial_fee, monthly_fee, annual_fee, payment_terms)
- termination: 解約条件(notice_period, refund, condition)
- governing_law: 準拠法・裁判管轄(law, court)
厳格ルール:
1) extraction_text は必ず原文の表現をそのまま用いる。
2) 空文字や null の extraction_text は出力しない。文字列 "null" は使用しない。
3) attributes は原文にある情報だけを、あるがままの単位で格納する(換算しない)。存在しない属性キーは出力しない。
""")
# --- few-shot 例
examples = [
lx.data.ExampleData(
text="契約期間は2025年4月1日から2026年3月31日までの1年間とする。",
extractions=[
lx.data.Extraction(
extraction_class="contract_period",
extraction_text="2025年4月1日から2026年3月31日までの1年間",
attributes={"start_date":"2025/04/01","end_date":"2026/03/31","renew":"自動更新あり"}
)
]
),
lx.data.ExampleData(
text="乙は、月額10万円を甲に支払う。支払方法は毎月末締め翌月末払いとする。",
extractions=[
lx.data.Extraction(
extraction_class="fee",
extraction_text="月額10万円を甲に支払う",
attributes={"monthly_fee":"10万円","payment_terms":"毎月末締め翌月末払い"}
)
]
),
lx.data.ExampleData(
text="乙は解約希望日の60日前までに通知することで中途解約できる。",
extractions=[
lx.data.Extraction(
extraction_class="termination",
extraction_text="解約希望日の60日前までに通知することで中途解約できる",
attributes={"notice_period":"60日前","refund":"なし","condition":"通知で解約可能"}
)
]
),
lx.data.ExampleData(
text="本契約は日本法に準拠する。紛争は東京地方裁判所を専属管轄とする。",
extractions=[
lx.data.Extraction(
extraction_class="governing_law",
extraction_text="日本法に準拠する。紛争は東京地方裁判所を専属管轄とする",
attributes={"law":"日本法","court":"東京地方裁判所"}
)
]
),
]
# --- 複数ファイルを Document に変換
TXT_PATH = "/content/drive/MyDrive/develop/Elcamy/LangExtract"
paths = [Path(TXT_PATH)/f for f in ("sample3-1.txt","sample3-2.txt","sample3-3.txt")]
docs = []
for p in paths:
with open(p, "r", encoding="utf-8") as fp:
text = fp.read()
docs.append(lx.data.Document(text=text, document_id=p.name))
# --- ファイルごとに抽出して行生成
rows = []
for doc in docs:
r = list(lx.extract(
text_or_documents=[doc],
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
))[0]
for e in r.extractions:
d = e.to_dict() if hasattr(e,"to_dict") else (
e.model_dump() if hasattr(e,"model_dump") else e.__dict__
)
d["document_id"] = doc.document_id
rows.append(d)
df = pd.DataFrame(rows)
df = df[df["extraction_text"].notna() & (df["extraction_text"]!="")]
df = df[["document_id","extraction_class","extraction_text","attributes"]]
display(df)コード解説
-
プロンプト定義
pythonprompt = textwrap.dedent("""\ 以下の契約書テキストから、次の4クラスのみ抽出してください。 - contract_period: 契約期間(start_date, end_date, renew) - fee: 料金(initial_fee, monthly_fee, annual_fee, payment_terms) - termination: 解約条件(notice_period, refund, condition) - governing_law: 準拠法・裁判管轄(law, court) 厳格ルール: 1) extraction_text は必ず原文の表現をそのまま用いる。 2) 空文字や null の extraction_text は出力しない。文字列 "null" は使用しない。 3) attributes は原文にある情報だけを、あるがままの単位で格納する(換算しない)。存在しない属性キーは出力しない。 """)
ここでは、契約書から抽出したい情報の種類を4つ定義しています。
contract_period:契約期間(開始日、終了日、更新条件)fee:料金(初期費用、月額、年額、支払条件)termination:解約条件(通知期限、返金有無、条件)governing_law:準拠法・裁判管轄(どの法律に従うか、裁判所の管轄) また「換算はせず、原文のまま記録」「null や空文字は出さない」といった厳格ルールも加えて、モデルの出力がぶれないように指示しています。
- few-shot 例の設定
examples = [
lx.data.ExampleData(
text="契約期間は2025年4月1日から2026年3月31日までの1年間とする。",
extractions=[
lx.data.Extraction(
extraction_class="contract_period",
extraction_text="2025年4月1日から2026年3月31日までの1年間",
attributes={"start_date":"2025/04/01","end_date":"2026/03/31","renew":"自動更新あり"}
)
]
),
...
]ここでは few-shot(例文)を使い、モデルに抽出パターンを学習させています。 例えば「契約期間」を扱う文では、
extraction_textに「2025年4月1日から2026年3月31日までの1年間」をそのまま入れるattributesに開始日、終了日、更新条件をキーごとに記録する という形を見せています。 同様に fee(料金)、termination(解約条件)、governing_law(準拠法) の例も用意し、各クラスの入力と出力の対応を具体的に教えています。
-
複数ファイルを Document に変換
pythonTXT_PATH = "/content/drive/MyDrive/develop/Elcamy/LangExtract" paths = [Path(TXT_PATH)/f for f in ("sample3-1.txt","sample3-2.txt","sample3-3.txt")] docs = [] for p in paths: with open(p, "r", encoding="utf-8") as fp: text = fp.read() docs.append(lx.data.Document(text=text, document_id=p.name))
ここでは 3つの契約書サンプルファイルを読み込み、それぞれを lx.data.Document に変換しています。
text:契約書本文document_id:ファイル名(後で DataFrame に出すと「どの契約書からの抽出か」が分かる)
-
ファイルごとに抽出して行生成
pythonrows = [] for doc in docs: r = list(lx.extract( text_or_documents=[doc], prompt_description=prompt, examples=examples, model_id="gemini-2.5-flash", ))[0] for e in r.extractions: d = e.to_dict() if hasattr(e,"to_dict") else ( e.model_dump() if hasattr(e,"model_dump") else e.__dict__ ) d["document_id"] = doc.document_id rows.append(d)
ここでは ファイルごとに lx.extract を実行し、結果を rows にまとめています。
結果と評価
今回の出力では、契約期間・料金・解約条件・準拠法の4クラスが3つの契約書から適切に抽出されており、原文の表現も保持できています。一方で、一部の attributes に空文字(law や refund など)が残っている点は改善の余地があります。全体としては、複数テキストごとの違いを正しく反映できています。
| index | document_id | extraction_class | extraction_text | attributes |
|---|---|---|---|---|
| 0 | sample3-1.txt | contract_period | 契約期間は2025年4月1日から2026年3月31日までの1年間とする。期間満了の30日前までに甲または乙から書面による解約の意思表示がない場合、自動的に1年間更新される。 | {'start_date': '2025/04/01', 'end_date': '2026/03/31', 'renew': '自動更新あり'} |
| 1 | sample3-1.txt | fee | 乙は、月額10万円を甲に支払う。支払方法は毎月末締め翌月末払いとする。 | {'monthly_fee': '10万円', 'payment_terms': '毎月末締め翌月末払い'} |
| 2 | sample3-1.txt | termination | 乙は契約期間中でも、解約希望日の60日前までに通知することで中途解約できる。ただし、未経過期間の残存料金は全額支払うものとする。 | {'notice_period': '60日前', 'refund': 'なし', 'condition': '通知することで中途解約できる。ただし、未経過期間の残存料金は全額支払うものとする。'} |
| 3 | sample3-1.txt | governing_law | 本契約は日本法に準拠する。 | {'law': '日本法', 'court': ''} |
| 4 | sample3-2.txt | contract_period | 契約期間は2025年7月1日から無期限とする | {'start_date': '2025/07/01', 'end_date': '無期限', 'renew': ''} |
| 5 | sample3-2.txt | fee | 初期導入費50万円と、月額利用料5万円を甲に支払う | {'monthly_fee': '5万円', 'payment_terms': ''} |
| 6 | sample3-2.txt | termination | 乙が料金支払いを怠った場合、甲は30日の猶予期間をもって解約できる | {'notice_period': '30日', 'refund': '', 'condition': '乙が料金支払いを怠った場合'} |
| 7 | sample3-2.txt | termination | 乙はいつでも解約可能だが、解約日の30日前までに甲へ書面通知する必要がある。返金は行わない | {'notice_period': '30日前', 'refund': '行わない', 'condition': '書面通知'} |
| 8 | sample3-2.txt | governing_law | 本契約に関する紛争は、東京地方裁判所を第一審の専属的合意管轄裁判所とする | {'law': '', 'court': '東京地方裁判所'} |
| 9 | sample3-3.txt | contract_period | 本契約は2025年1月15日から2025年12月31日まで有効とする。更新は協議のうえ書面合意が必要である。 | {'start_date': '2025/01/15', 'end_date': '2025/12/31', 'renew': '協議のうえ書面合意が必要'} |
| 10 | sample3-3.txt | fee | 年間120万円を一括前払いする。 | {'monthly_fee': '10万円', 'payment_terms': '一括前払い'} |
| 11 | sample3-3.txt | termination | 乙は契約期間中の中途解約は原則できない。ただし、甲が重大な契約違反をした場合、乙は即時解約できる。その場合、未経過分の料金は日割りで返金される。 | {'notice_period': 'なし', 'refund': '日割りで返金', 'condition': '甲が重大な契約違反をした場合'} |
| 12 | sample3-3.txt | governing_law | 本契約は日本法に基づき、福岡地方裁判所を専属的管轄とする。 | {'law': '日本法', 'court': '福岡地方裁判所'} |
JSON での出力
[
{
"document_id": "sample3-1.txt",
"extraction_class": "contract_period",
"extraction_text": "契約期間は2025年4月1日から2026年3月31日までの1年間とする。期間満了の30日前までに甲または乙から書面による解約の意思表示がない場合、自動的に1年間更新される。",
"attributes": {
"start_date": "2025/04/01",
"end_date": "2026/03/31",
"renew": "自動更新あり"
}
},
{
"document_id": "sample3-1.txt",
"extraction_class": "fee",
"extraction_text": "乙は、月額10万円を甲に支払う。支払方法は毎月末締め翌月末払いとする。",
"attributes": {
"monthly_fee": "10万円",
"payment_terms": "毎月末締め翌月末払い"
}
},
{
"document_id": "sample3-1.txt",
"extraction_class": "termination",
"extraction_text": "乙は契約期間中でも、解約希望日の60日前までに通知することで中途解約できる。ただし、未経過期間の残存料金は全額支払うものとする。",
"attributes": {
"notice_period": "60日前",
"refund": "なし",
"condition": "通知することで中途解約できる。ただし、未経過期間の残存料金は全額支払うものとする。"
}
},
{
"document_id": "sample3-1.txt",
"extraction_class": "governing_law",
"extraction_text": "本契約は日本法に準拠する。",
"attributes": {
"law": "日本法",
"court": ""
}
},
{
"document_id": "sample3-2.txt",
"extraction_class": "contract_period",
"extraction_text": "契約期間は2025年7月1日から無期限とする",
"attributes": {
"start_date": "2025/07/01",
"end_date": "無期限",
"renew": "null"
}
},
{
"document_id": "sample3-2.txt",
"extraction_class": "fee",
"extraction_text": "初期導入費50万円と、月額利用料5万円を甲に支払う",
"attributes": {
"monthly_fee": "5万円",
"payment_terms": "null"
}
},
{
"document_id": "sample3-2.txt",
"extraction_class": "termination",
"extraction_text": "乙が料金支払いを怠った場合、甲は30日の猶予期間をもって解約できる",
"attributes": {
"notice_period": "30日",
"refund": "null",
"condition": "料金支払いを怠った場合"
}
},
{
"document_id": "sample3-2.txt",
"extraction_class": "termination",
"extraction_text": "乙はいつでも解約可能だが、解約日の30日前までに甲へ書面通知する必要がある。返金は行わない。",
"attributes": {
"notice_period": "30日前",
"refund": "行わない",
"condition": "いつでも解約可能だが、書面通知が必要"
}
},
{
"document_id": "sample3-2.txt",
"extraction_class": "governing_law",
"extraction_text": "本契約に関する紛争は、東京地方裁判所を第一審の専属的合意管轄裁判所とする",
"attributes": {
"law": "null",
"court": "東京地方裁判所"
}
},
{
"document_id": "sample3-3.txt",
"extraction_class": "contract_period",
"extraction_text": "本契約は2025年1月15日から2025年12月31日まで有効とする。更新は協議のうえ書面合意が必要である。",
"attributes": {
"start_date": "2025/01/15",
"end_date": "2025/12/31",
"renew": "協議のうえ書面合意が必要"
}
},
{
"document_id": "sample3-3.txt",
"extraction_class": "fee",
"extraction_text": "年間120万円を一括前払いする。",
"attributes": {
"monthly_fee": "10万円",
"payment_terms": "一括前払い"
}
},
{
"document_id": "sample3-3.txt",
"extraction_class": "termination",
"extraction_text": "乙は契約期間中の中途解約は原則できない。ただし、甲が重大な契約違反をした場合、乙は即時解約できる。その場合、未経過分の料金は日割りで返金される。",
"attributes": {
"notice_period": "なし",
"refund": "日割りで返金",
"condition": "甲が重大な契約違反をした場合"
}
},
{
"document_id": "sample3-3.txt",
"extraction_class": "governing_law",
"extraction_text": "本契約は日本法に基づき、福岡地方裁判所を専属的管轄とする。",
"attributes": {
"law": "日本法",
"court": "福岡地方裁判所"
}
}
]実用例
LangExtract は、自由記述のテキストから必要な情報を構造化できるため、幅広い分野で活用可能です。
- 医療分野:臨床レポートや診断書から薬剤・所見・異常箇所を抽出し、構造化データ化できます。
- 契約管理:契約期間・料金・解約条件・準拠法などを自動抽出し、レビューや更新管理を効率化できます。
- 顧客対応:アンケートやサポートチケットを分類し、要望や不具合報告を整理できます。
- 財務処理:請求書や発注書から金額や支払条件を抽出し、会計入力や監査を省力化できます。
- 研究文献:論文やレポートから目的・手法・結果などを自動で整理し、レビュー作業を支援できます。
おわりに
この記事では、LangExtractを用いてテキストから情報を抽出・構造化する方法を解説しました。 チュートリアルを通じて、会話文や契約書といった異なる種類のテキストを対象に、プロンプト定義やfew-shot例を設定し、抽出結果を DataFrame などで可視化する方法を紹介しました。また、複数のテキストを一括で処理する方法も紹介しました。 ぜひLangExtractを活用して、自由記述のテキストから価値ある情報を効率的に抽出し、実務や研究の場で活かしてみてください。
参考
https://github.com/google/langextract https://developers.googleblog.com/en/introducing-langextract-a-gemini-powered-information-extraction-library/ https://medium.com/illumination/7-real-world-use-cases-for-langextract-you-can-try-today-98dda8cc69dd https://medium.com/data-science-in-your-pocket/google-langextract-ai-powered-information-extraction-using-gemini-290cd4ab1b2c
