はじめに
先日、Difyのv1.11.0がリリースされ、画像や表などのマルチモーダルなコンテンツをナレッジとして扱えるようになりました。
マルチモーダルとは テキスト、画像、音声、動画、センサーデータなど、複数の異なる種類の情報(モダリティ)が統合されたコンテンツのこと。AI分野で特に注目されており、このようなコンテンツを処理できるようになることで、人間のように多様な情報を組み合わせてより深く理解し、高度な判断や分析を可能にします。
これまでDifyでRAG(検索拡張生成)を構築する際に、PDF内のグラフや図表は大きな壁でした。従来のテキストベースの処理では画像が無視されてしまったり、別途OCRツールでテキスト化してから登録するといった手間が必要だったりと、情報の欠落が課題となっていたからです。 しかし、v1.11.0ではMarkdown形式への変換処理などを柔軟に組み合わせることで、画像情報を保持したまま埋め込みを行い、より具体的で正確な回答を引き出せるようになりました。 本記事では、この新機能を使って「画像を含むPDF」をナレッジ化するパイプラインを実際に構築してみます。また、実際にマルチモーダルなコンテンツがどのようにナレッジに登録されているかを確認します。 なお、ナレッジパイプラインの基本的なテンプレートについては以下の記事でも紹介していますので併せてご覧ください。
https://blog.elcamy.com/posts/78d7dc55/
この記事の対象者
- Difyのv1.11.0のアップデート内容について気になっている方
- マルチモーダルな文書をナレッジに活用することに興味がある方
環境
- Difyクラウド版 v1.11.2(v1.11.0から実装可能)
作成手順
完成イメージ
このセクションから画像や表を含むPDFをナレッジに登録するカスタムナレッジパイプラインを作成していきます。今回作成するパイプラインの完成イメージは以下の通りです。
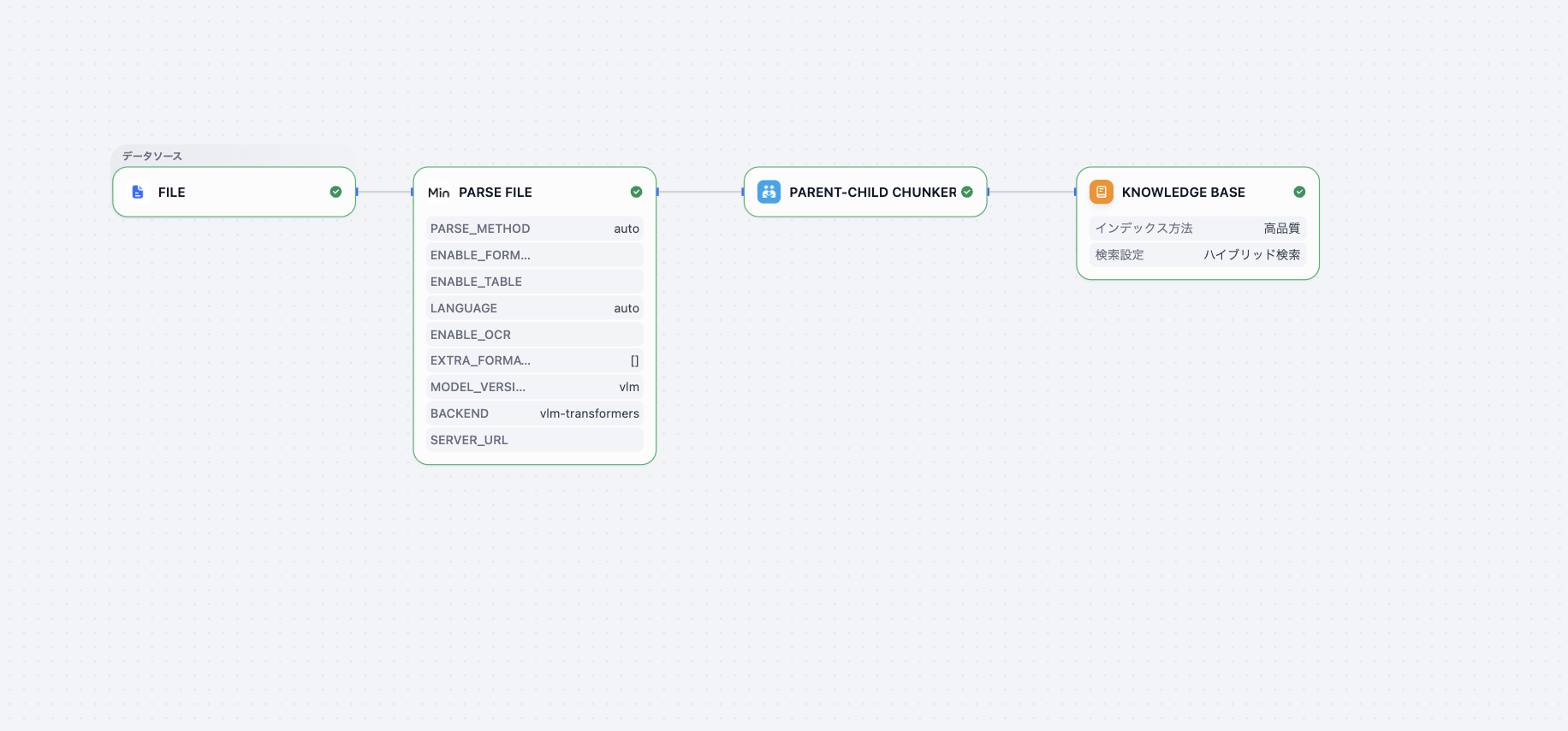 **FILE: **インプット(マルチモーダルコンテンツを含むPDF)
**PARSE FILE: **PDF入力に対して、画像付きのMarkdown形式に変換
**PARENT-CHILD-CHUNKER: **親子チャンク処理
**KNOWLEDGE BASE: **マルチモーダル対応の埋め込み処理
また今回のパイプラインを作成するに先立って以下のAPIキーを取得しておいてください。
**FILE: **インプット(マルチモーダルコンテンツを含むPDF)
**PARSE FILE: **PDF入力に対して、画像付きのMarkdown形式に変換
**PARENT-CHILD-CHUNKER: **親子チャンク処理
**KNOWLEDGE BASE: **マルチモーダル対応の埋め込み処理
また今回のパイプラインを作成するに先立って以下のAPIキーを取得しておいてください。
- 「MinerU」APIキー(使用申請が必要です)
- 「Jina AI」APIキー
作成手順
このセクションからは実際にパイプラインを作成する手順を説明していきます。
1. ナレッジパイプラインの新規作成
-
最初の画面の「ナレッジ」から遷移し、「知識パイプラインから作成する」を選択します。
-
「空白のナレッジパイプライン」を選択します。
2. パイプライン作成画面上での作業
-
作成画面に遷移したら「+データソースを追加」を選択します。
-
データソースから「FILE」を選択します。
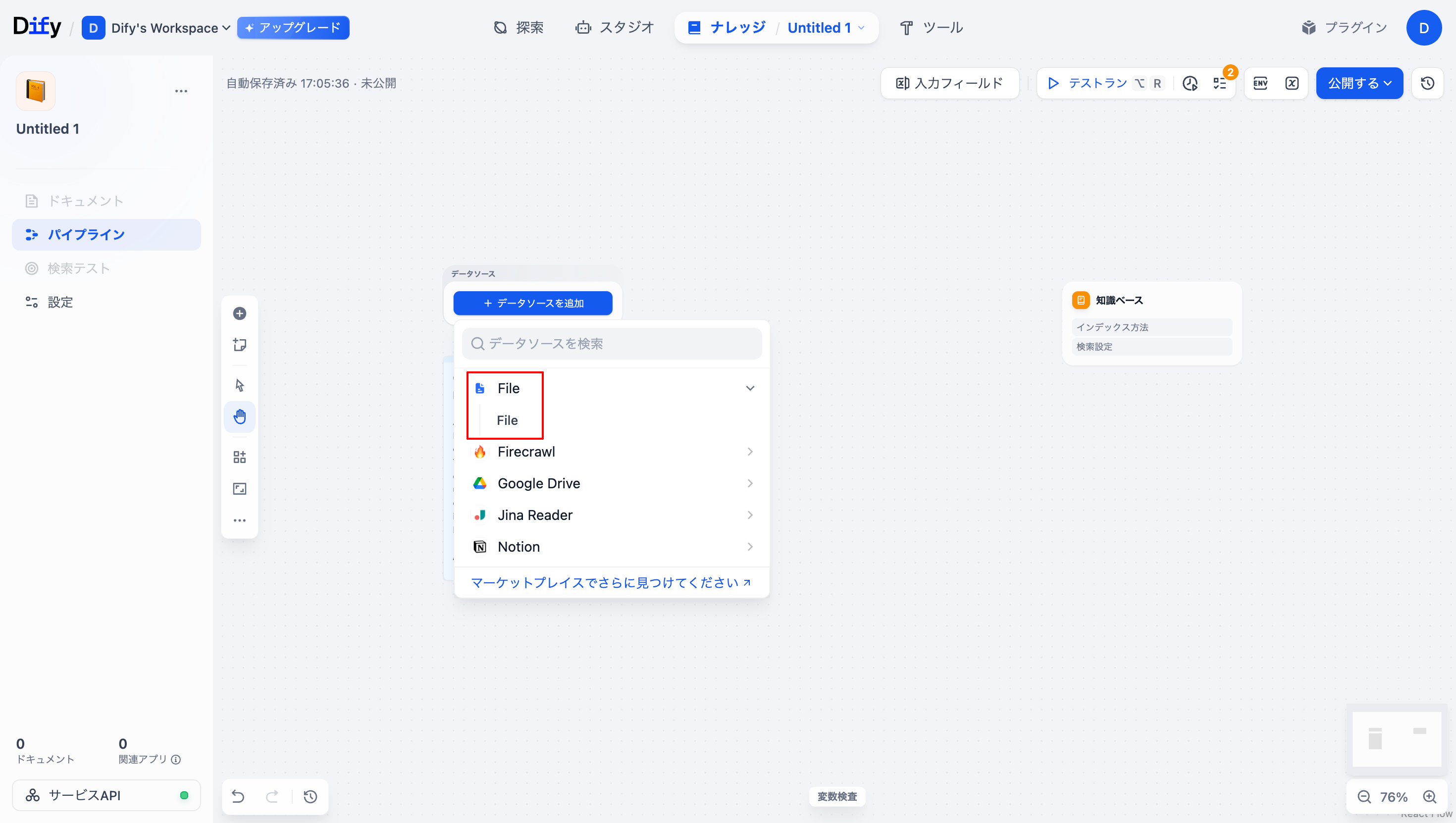
-
「FILE」ノードの「+」ボタンからMinerUプラグインの「Parse File」ノードを追加します。 (ツールから出てこない場合は「マーケットプレイス」からMinerUプラグインをインストールしてください。)
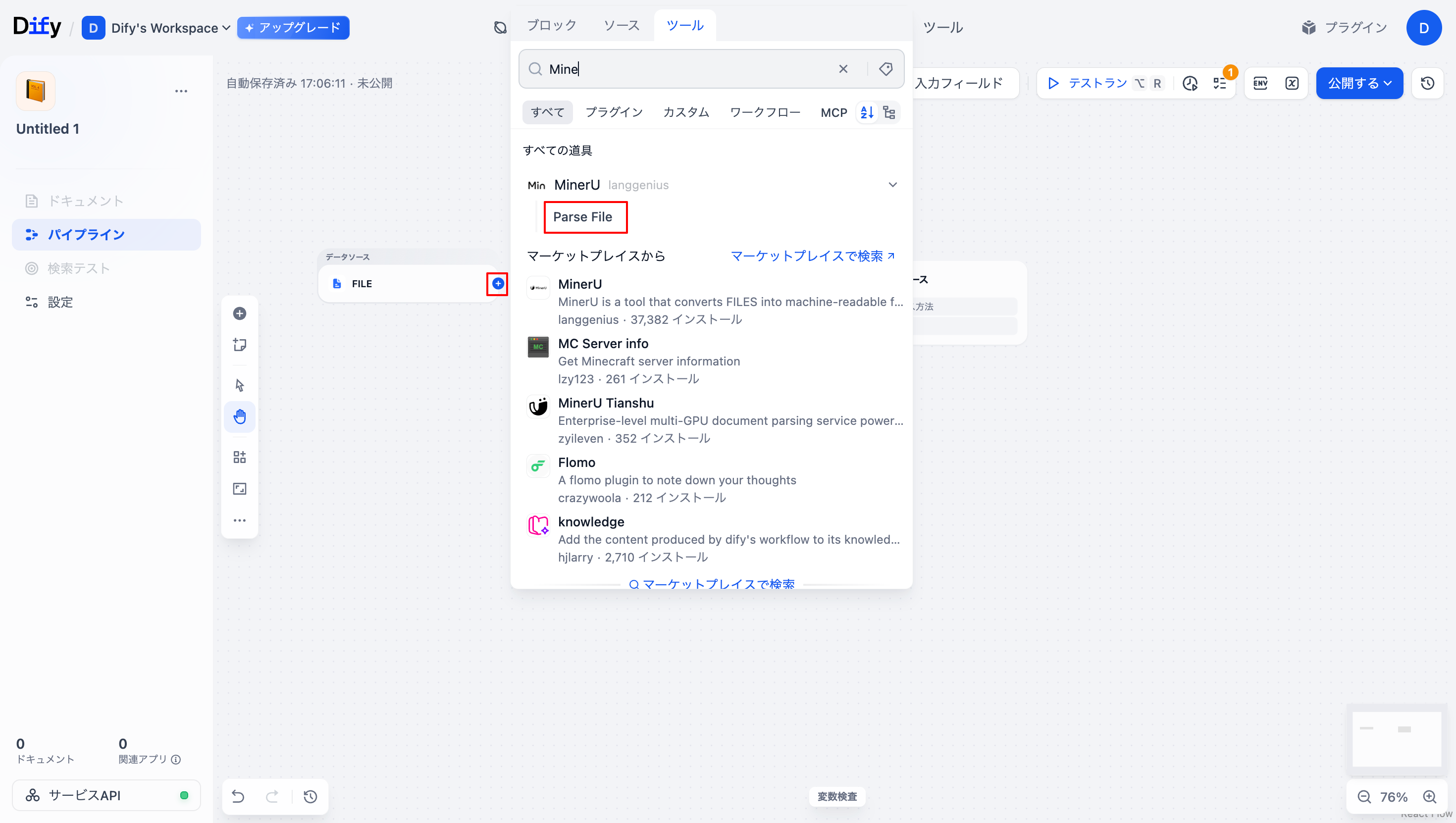
-
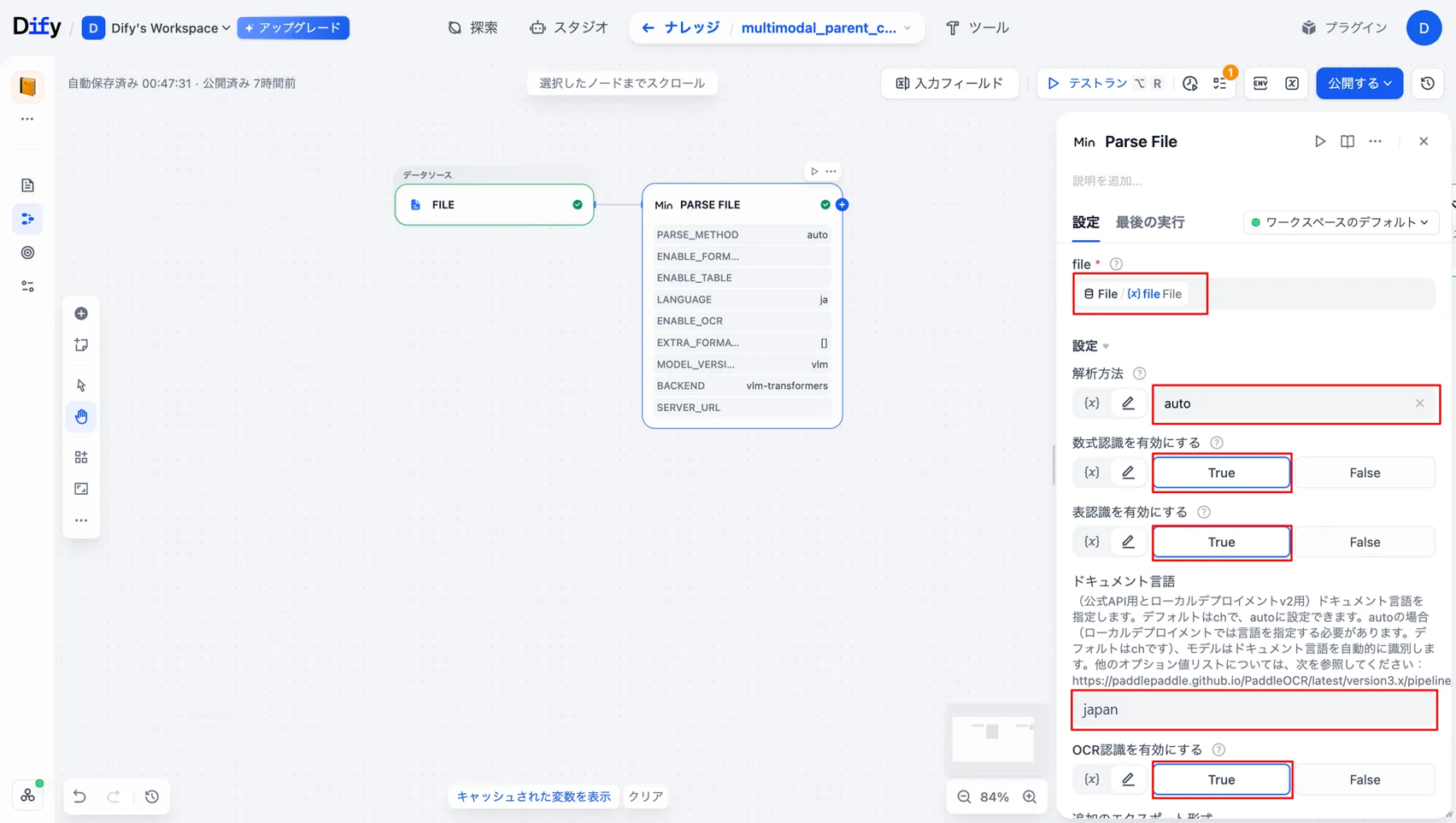
以下の表のようにパラメータ設定を行います。
| 項目 | 値 |
|---|---|
| 項目 | 値 |
| file | file/File |
| 解析方法 | auto(デフォルト) |
| 数式認識を有効にする | True(デフォルト) |
| 表認識を有効にする | True(デフォルト) |
| ドキュメント言語 | japan |
| OCR認識を有効にする | True(要変更) |
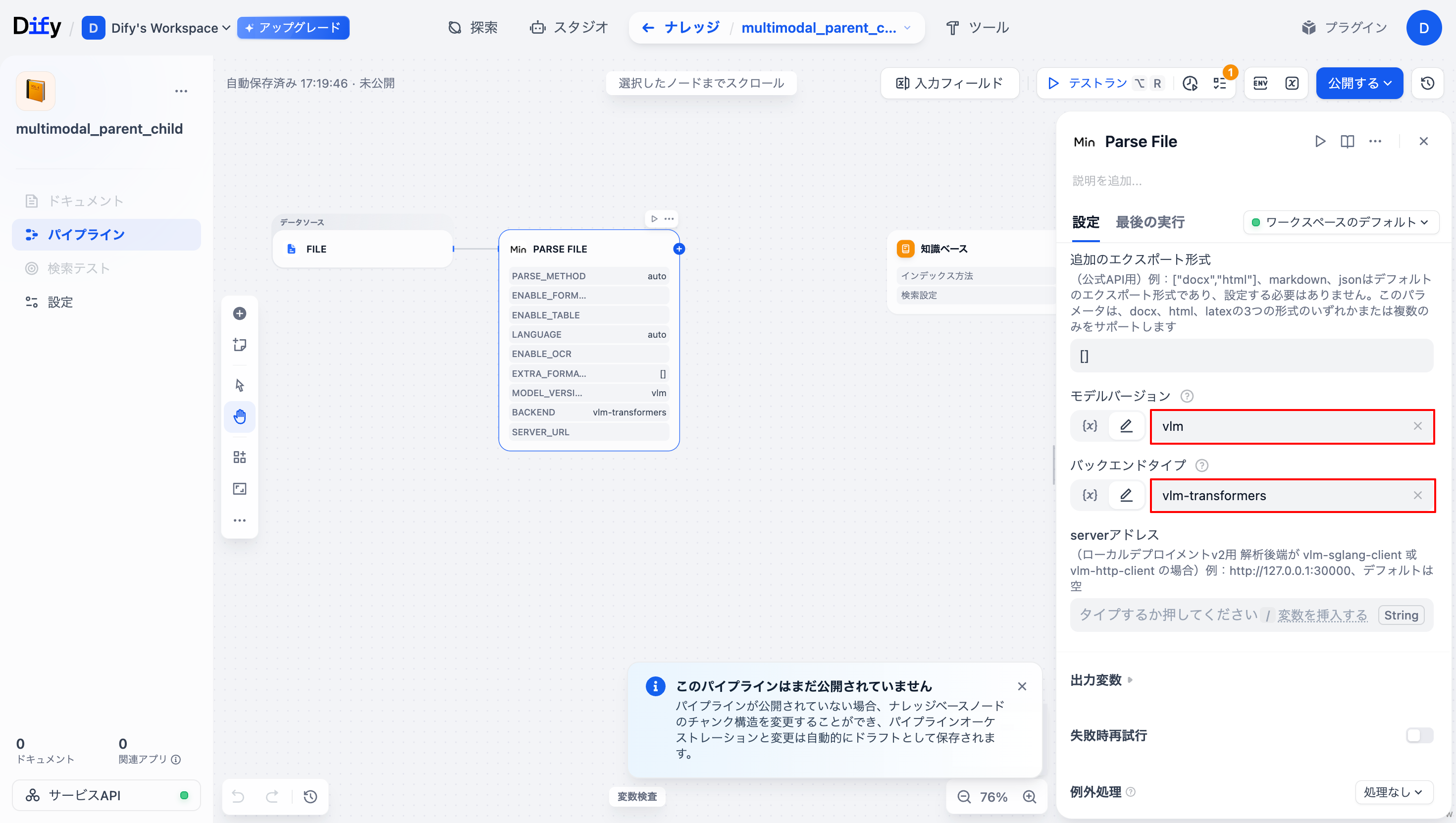
| モデルバージョン | vlm(要変更) |
| バックエンドタイプ | vlm-transformers(要変更) |
ドキュメント言語は、デフォルトの「auto」から「japan」に変更しています。「auto」の場合、一部の漢字が中国語として認識されてしまうため、ドキュメント言語が日本語であることを明示しています。 なお、「ja」と入力するとエラーになってしまうため、「japan」と設定する必要があります。
以下の表のようになっていればOKです。
-
「Parse File」ノードの「+」ボタンから「Parent-child Chunker」ノードを追加します。
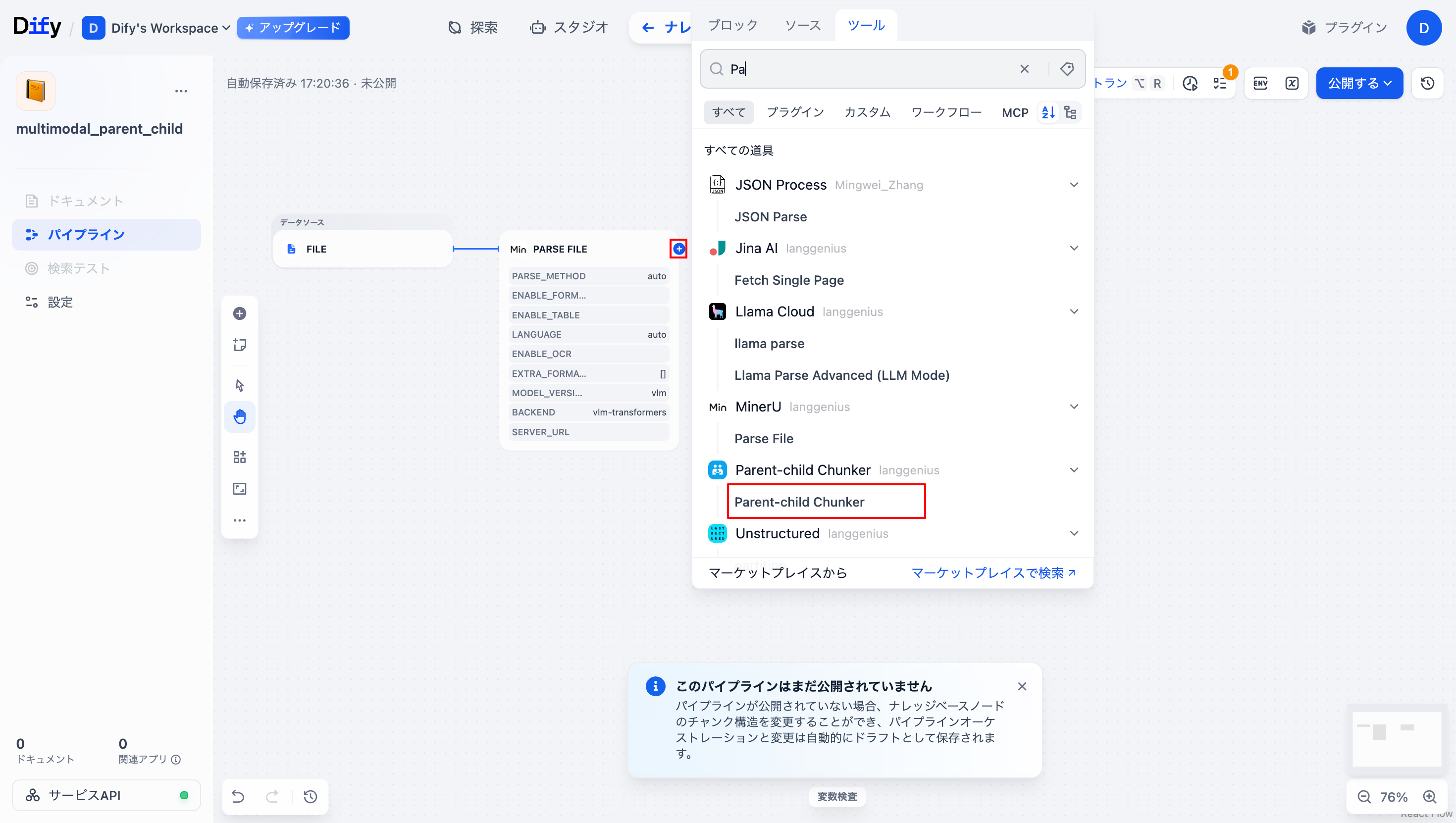
-
「Input Content」に「Parse File/Text」を追加します。
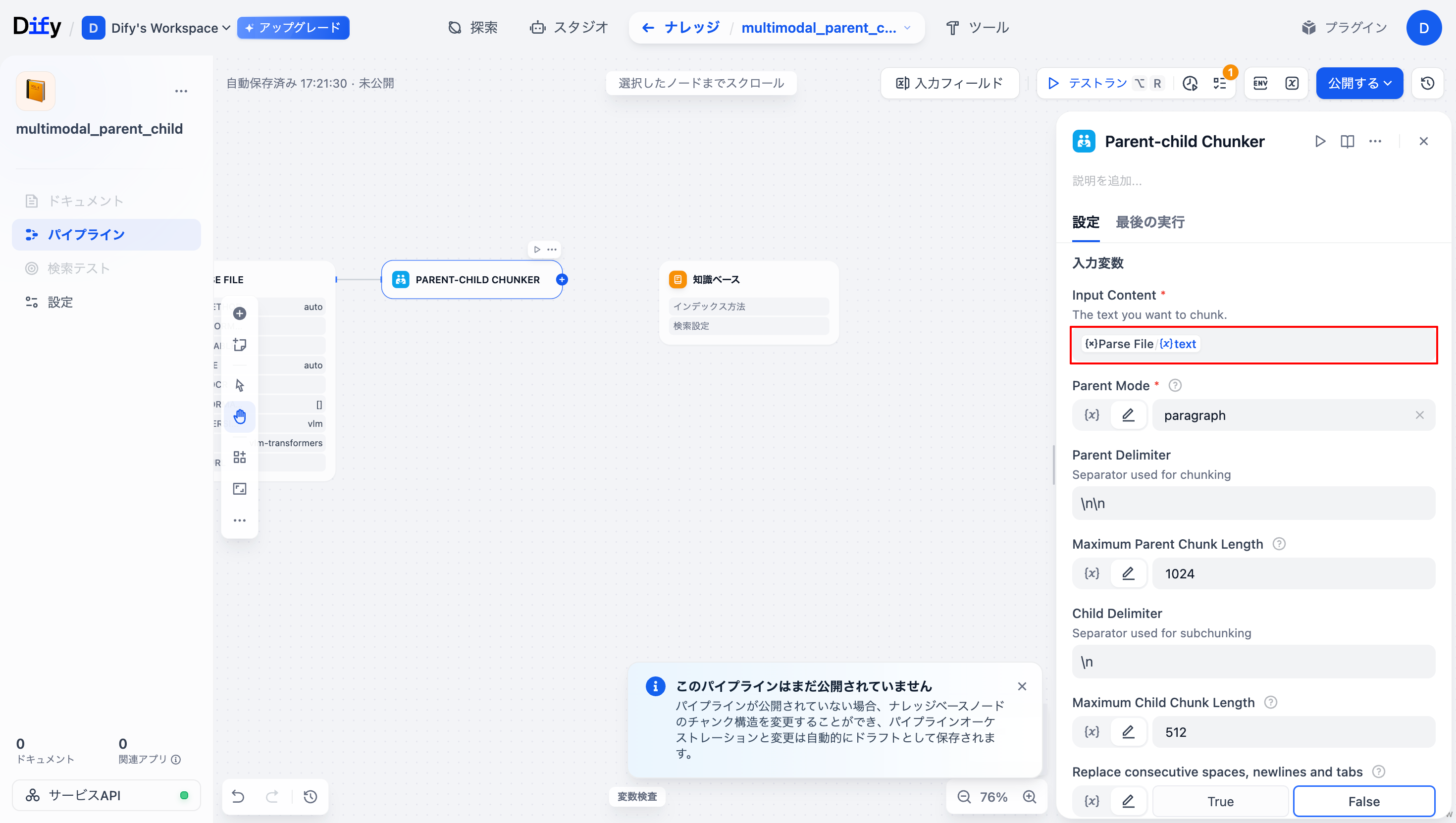
-
「Parent-child Chunker」ノードと「知識ベース」ノードをつなぎ、「知識ベース」ノードを選択し、「+チャンク構造を選択する」から「親子」チャンクを選択します。
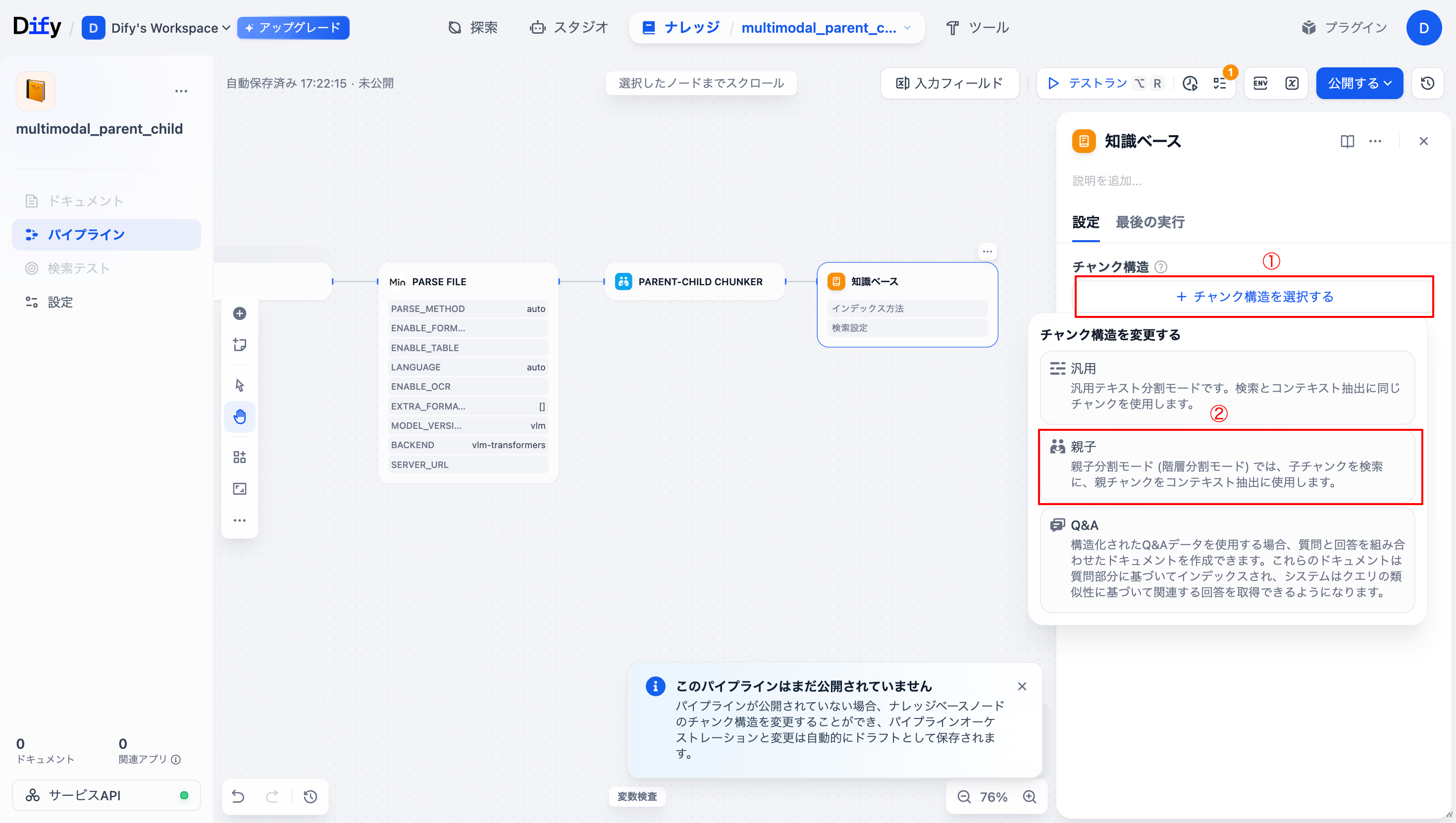
-
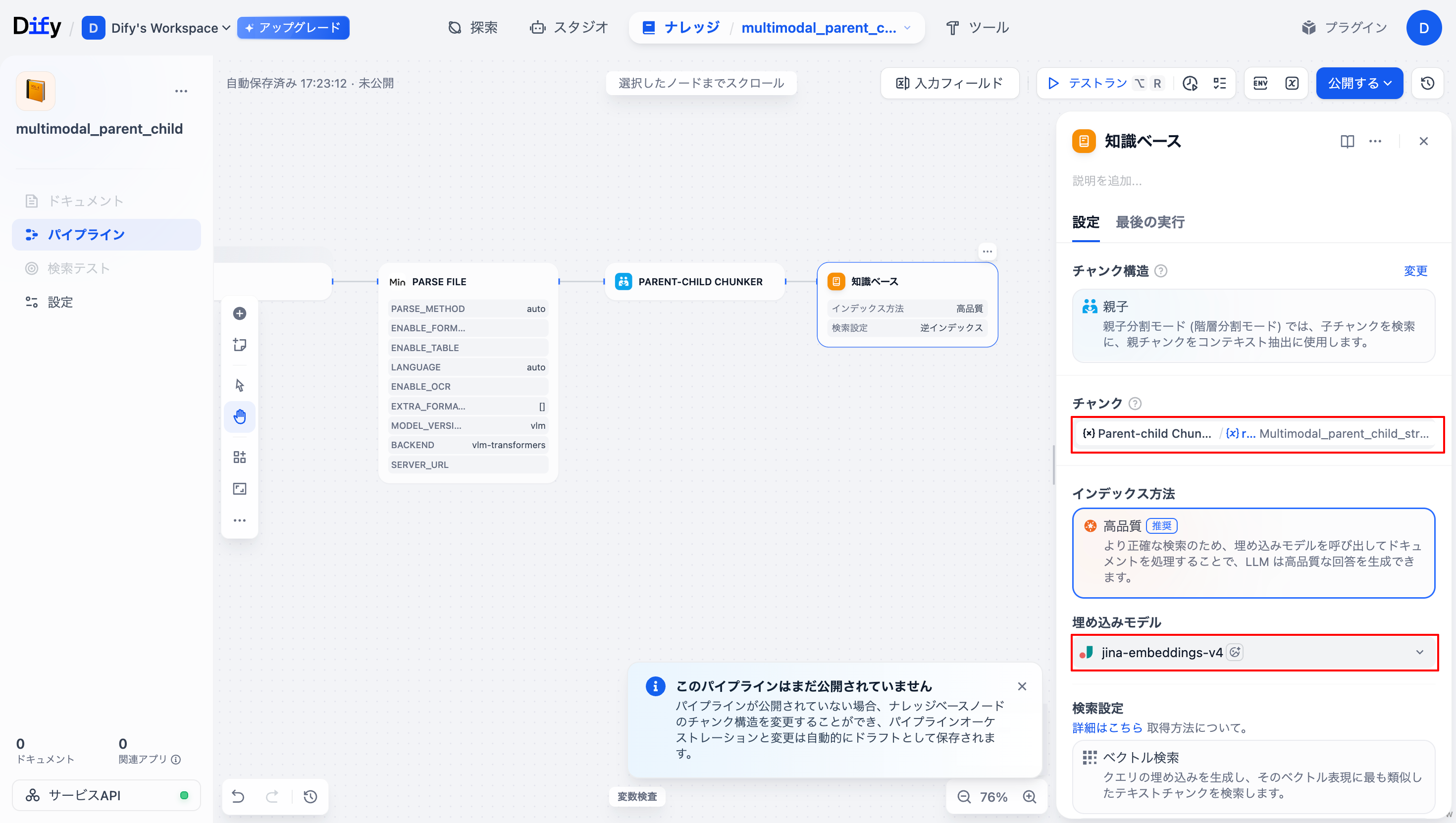
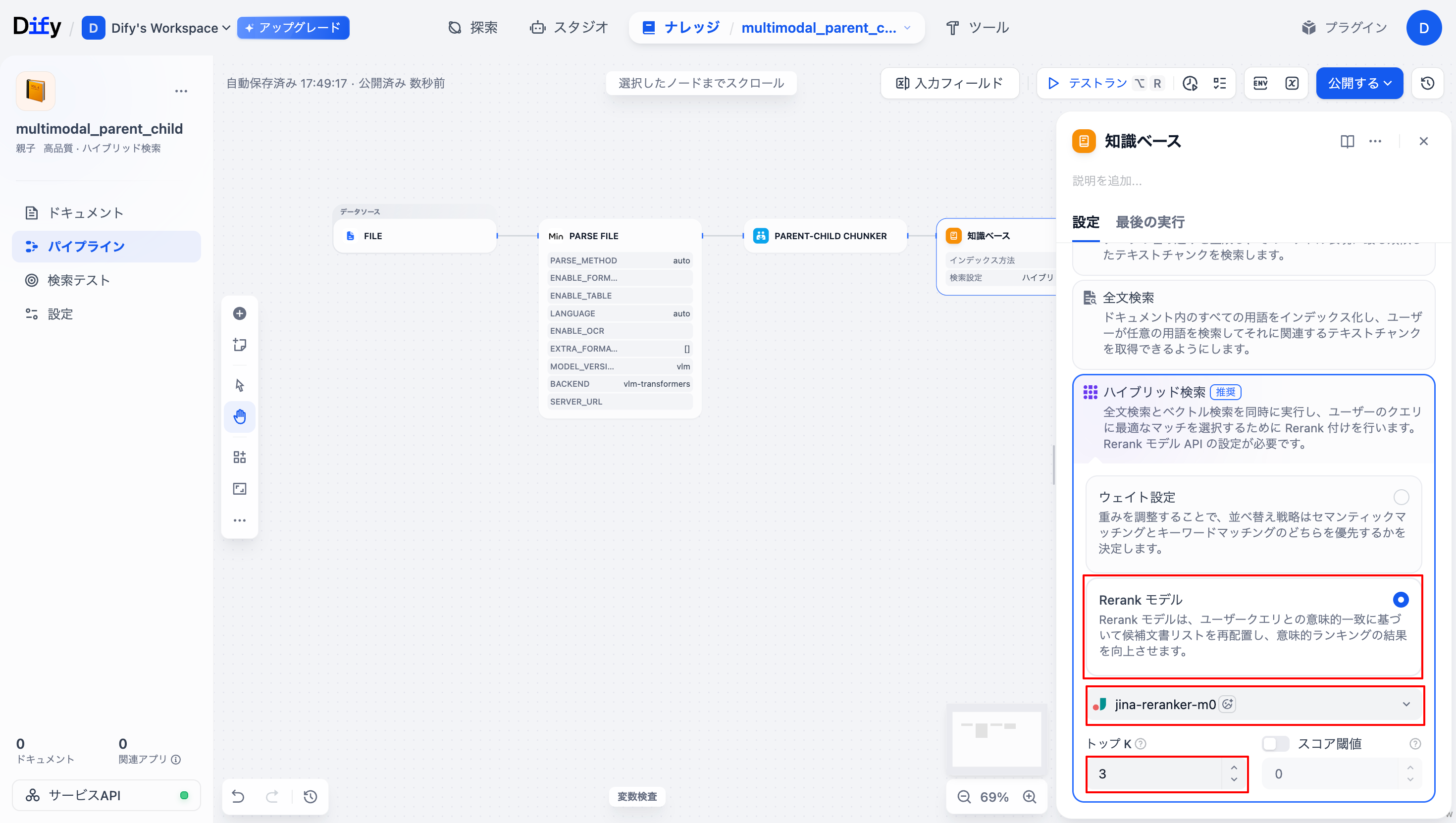
以下の表のようにパラメータ設定を行います。
| 項目 | 値 |
|---|---|
| 項目 | 値 |
| チャンク | Parent-child Chunker/result |
| 埋め込みモデル | jina-embeddings-v4 |
| 検索設定 | ハイブリッド検索 |
| Rerankモデル | jina-reranker-m0 |
| トップ K | 3 |
以下の画像のようになっていればOKです。
 以上で作成画面上での作業は終了です。
以上で作成画面上での作業は終了です。
3. ナレッジを登録する
-
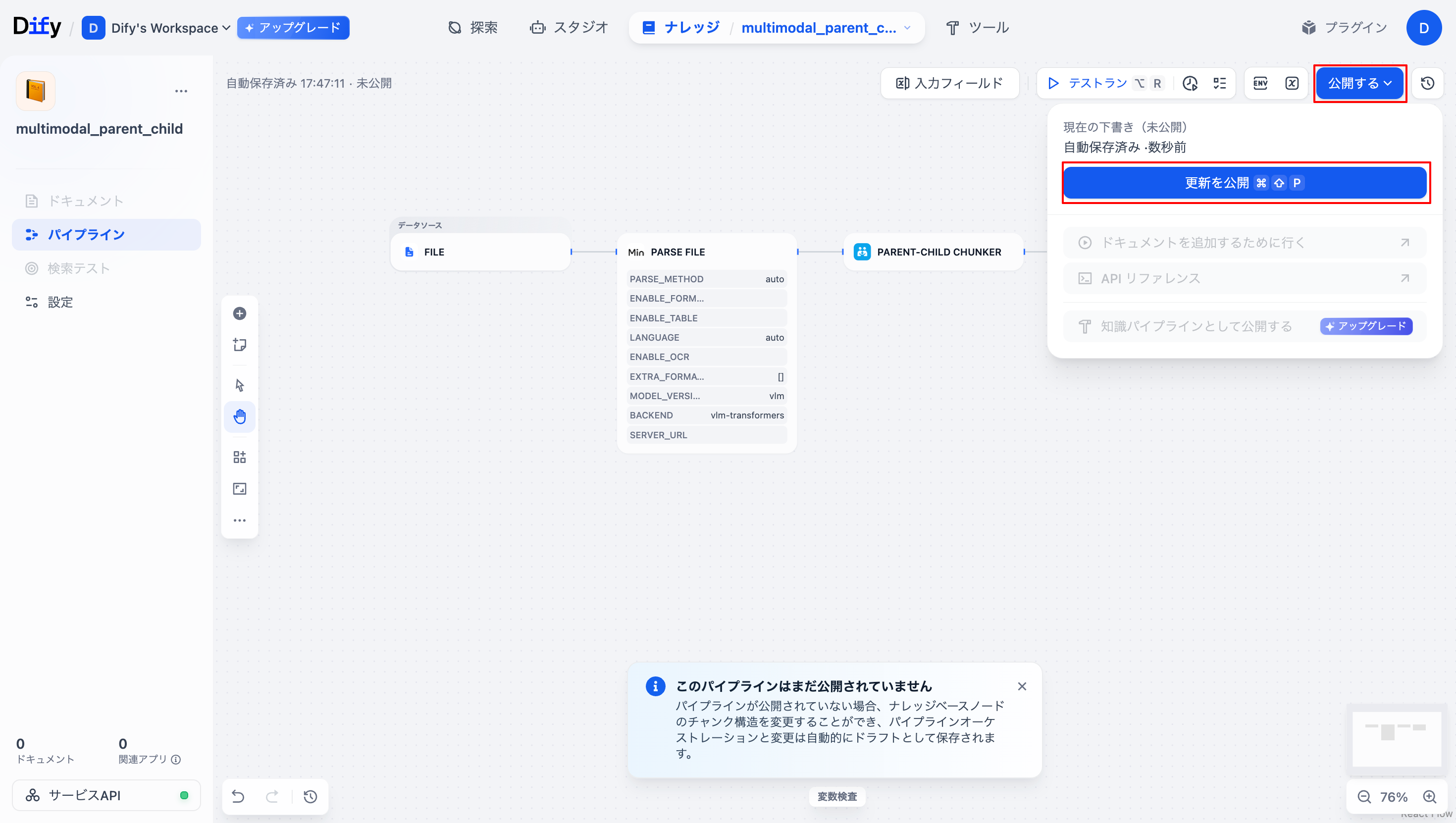
出来上がったナレッジパイプラインにナレッジを登録していきます。作成画面左上の「公開する」から「更新を公開」を選択します。
-
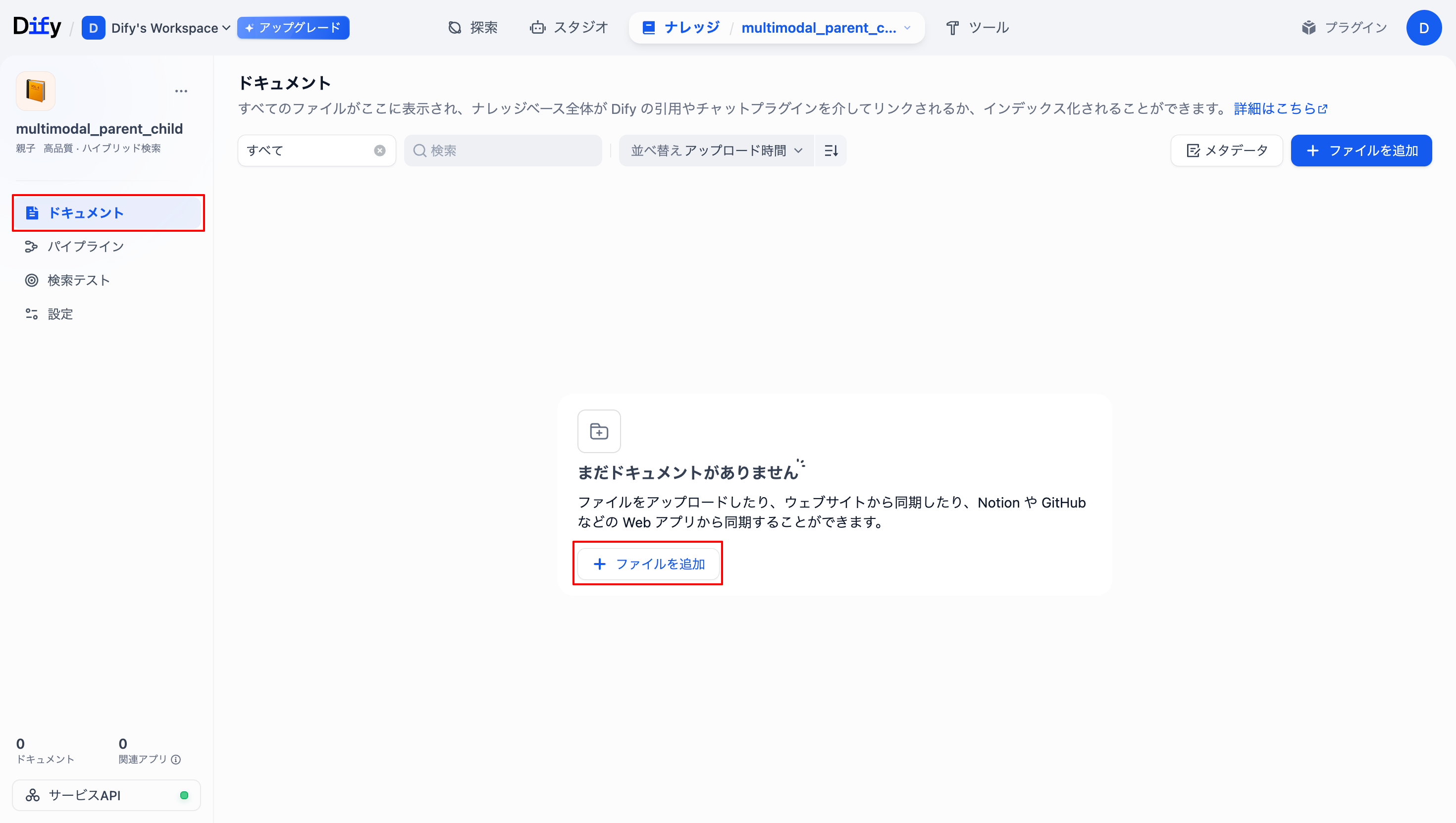
ナレッジにドキュメントを実際に追加していきます。「ドキュメント」を選択し、「+ファイルを追加」を選択します。
-
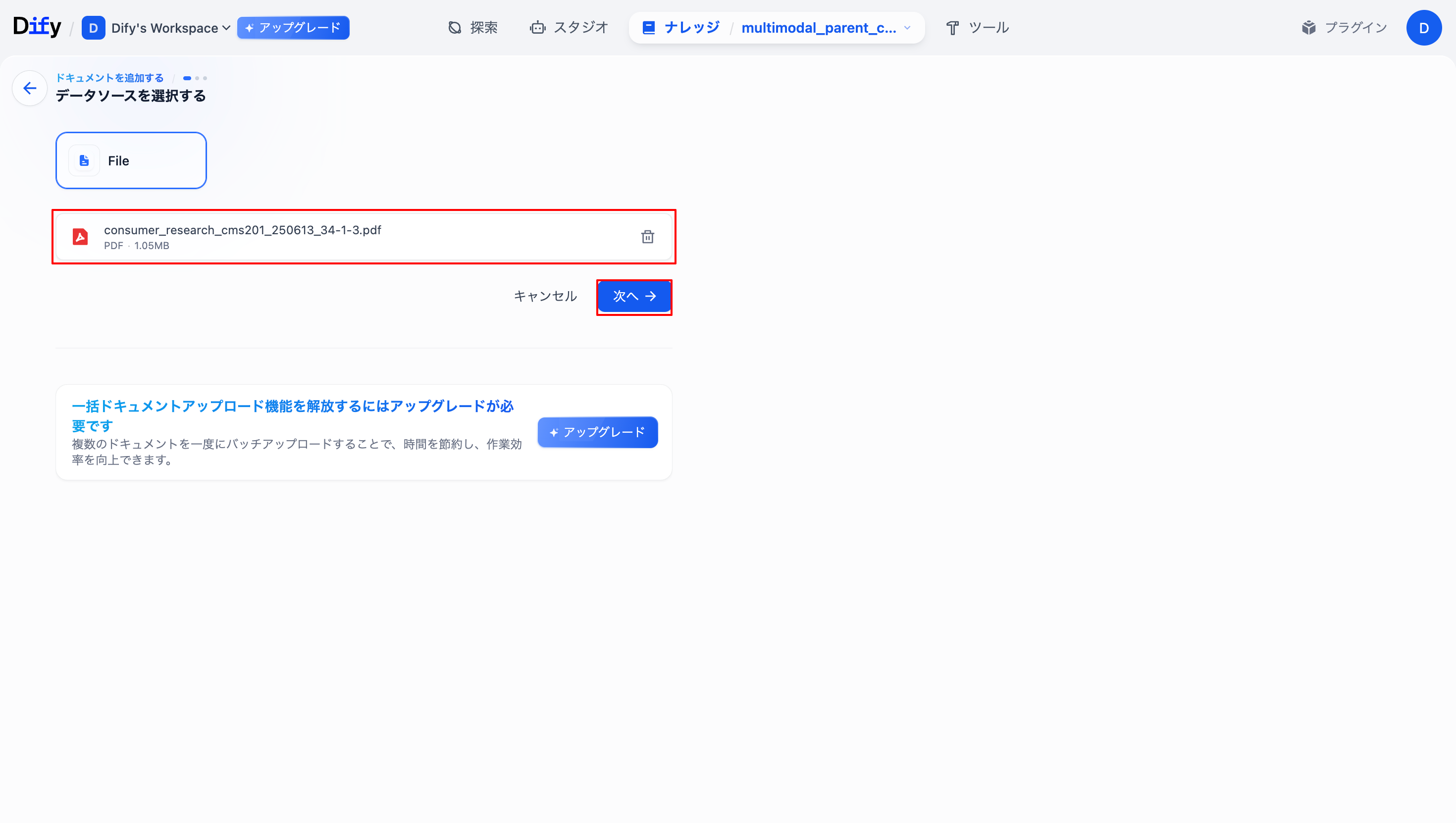
ナレッジ登録したいドキュメントを選択し、「次へ」を選択します。なお今回は消費者庁が刊行している消費者白書を引用しています。
-
「保存して処理する」を選択します。
 これでナレッジ登録は完了です。完成したナレッジを確認してみると、テキストベースのナレッジが親子チャンクとして登録されていることはもちろん、グラフなどの画像情報が画像のままナレッジとして登録されており、子チャンクに画像情報についての説明がされていることがわかります。
これでナレッジ登録は完了です。完成したナレッジを確認してみると、テキストベースのナレッジが親子チャンクとして登録されていることはもちろん、グラフなどの画像情報が画像のままナレッジとして登録されており、子チャンクに画像情報についての説明がされていることがわかります。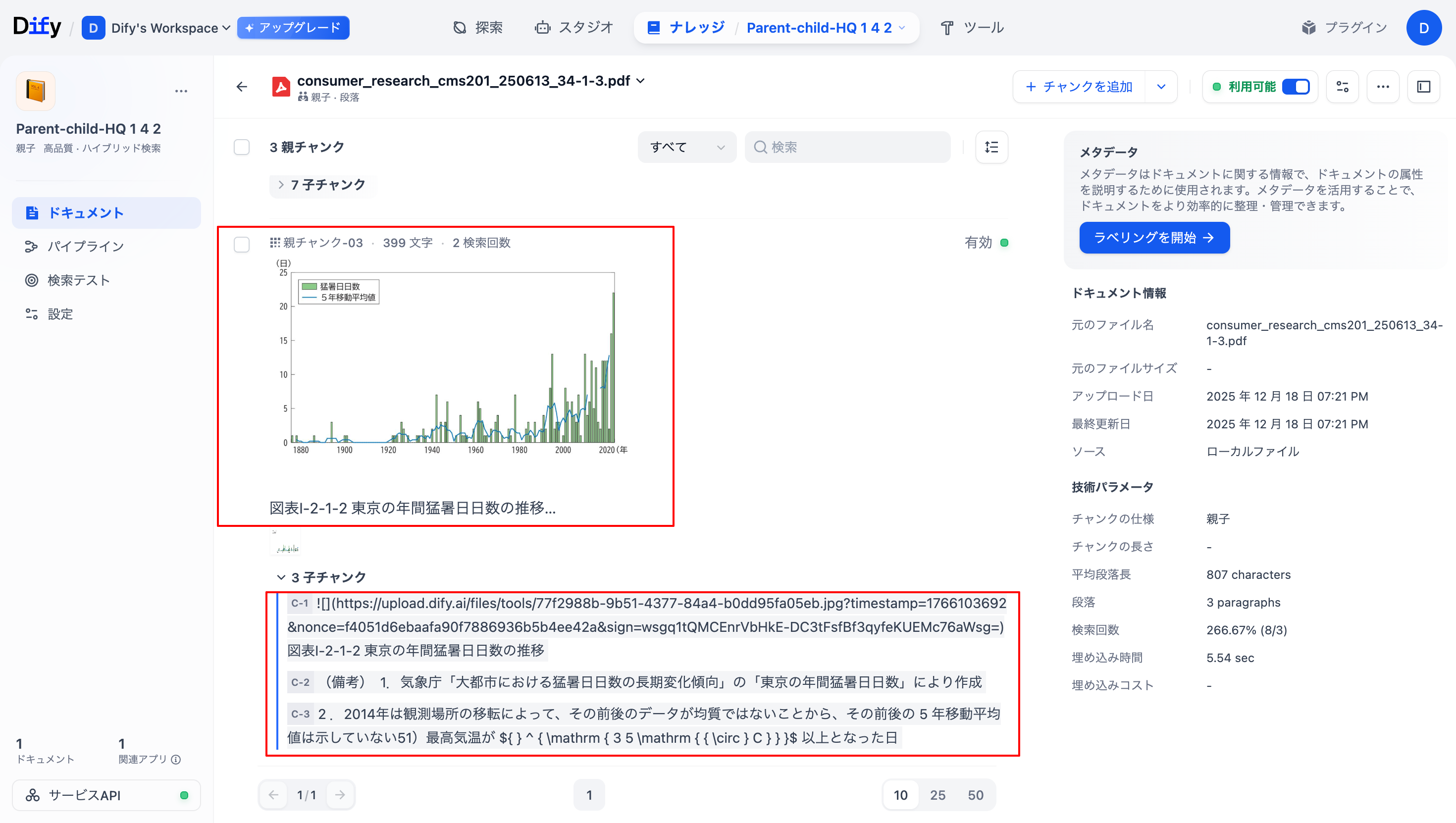
試した結果
作成したパイプラインで「検索テスト」を行ったところ、テキストだけでなくMarkdown形式で埋め込まれた画像データ(グラフ)そのものが検索スコアの上位にヒットしていることが確認できました。
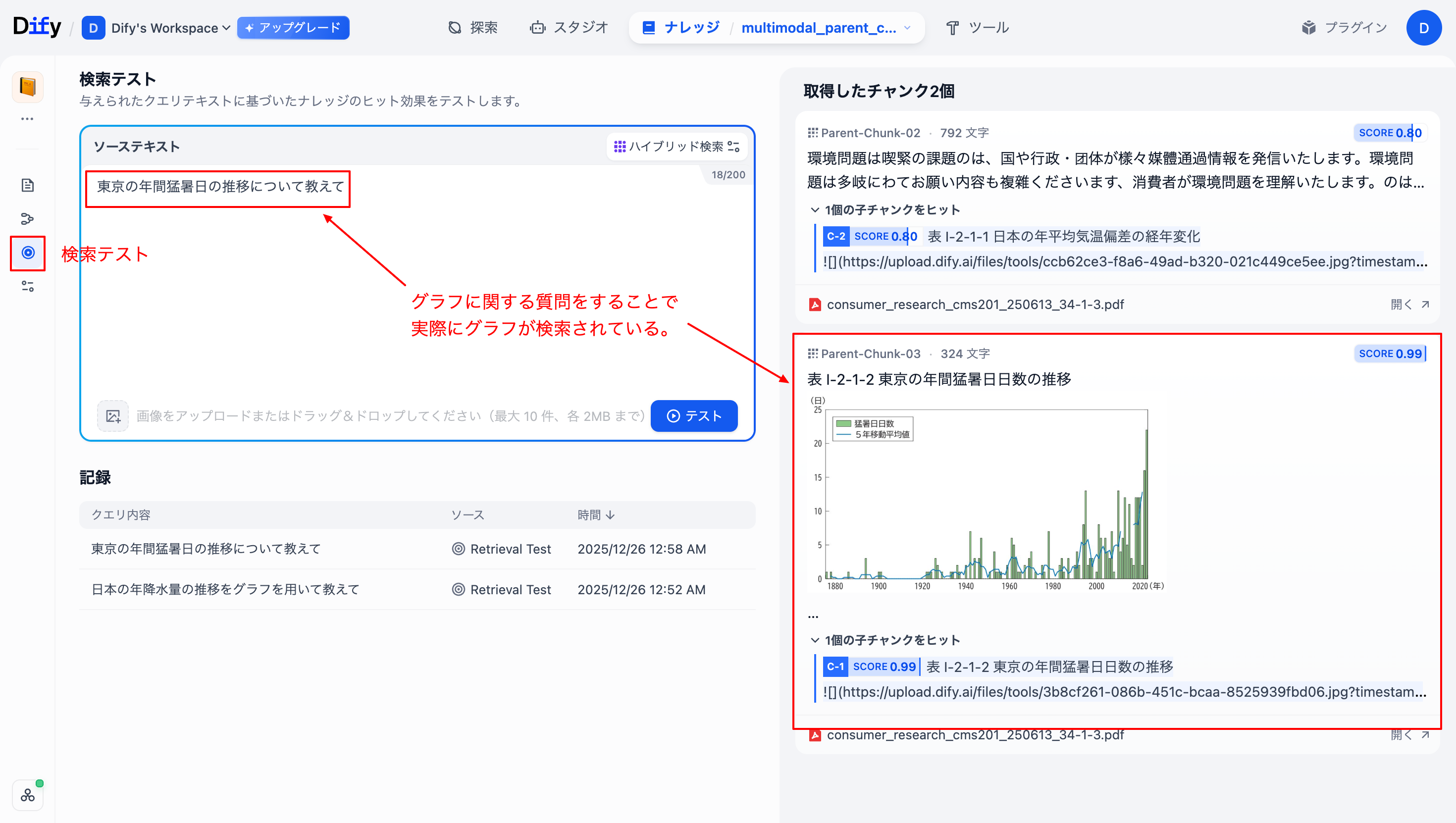 さらに、このナレッジを連携させたチャットボットで検証を行いました。
実際のレスポンスに画像自体は表示されませんでしたが、LLMが検索されたグラフの傾向(猛暑日の増加など)を視覚的に読み取り、その内容を言語化して回答に反映している様子が確認できました。
さらに、このナレッジを連携させたチャットボットで検証を行いました。
実際のレスポンスに画像自体は表示されませんでしたが、LLMが検索されたグラフの傾向(猛暑日の増加など)を視覚的に読み取り、その内容を言語化して回答に反映している様子が確認できました。
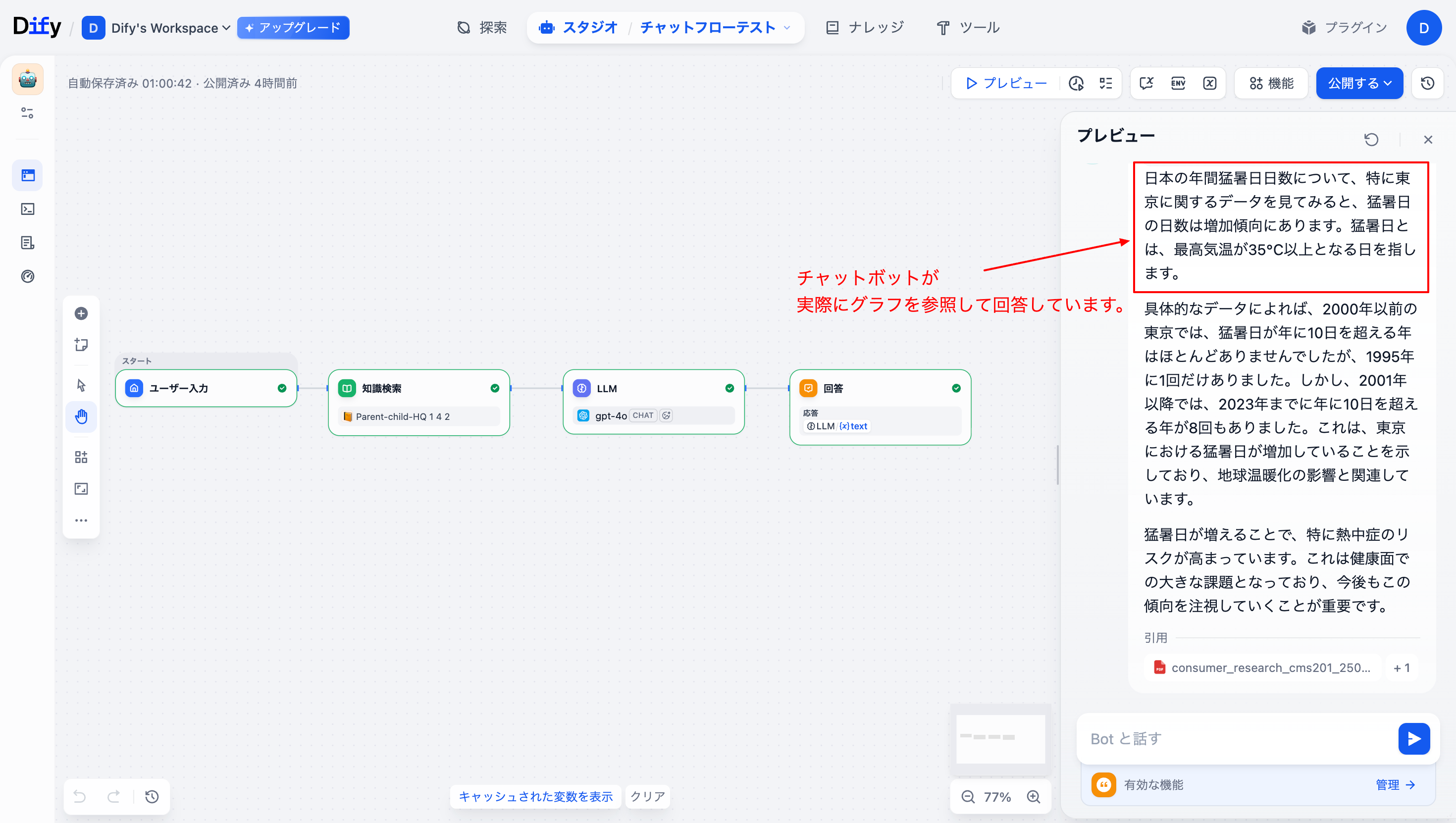
現時点(2025/12/26)のDifyの仕様上、参照元の画像チャンクをチャットの回答欄に直接引用表示することはできませんが、LLMのコンテキスト(入力)には画像情報が正しく渡されていることがわかります。
応用例
今回のようなマルチモーダル処理ができるナレッジパイプラインのおかげで、従来のテキスト抽出のみでは欠落していた視覚的コンテキストを保持できるため、特にマニュアルや統計資料を扱う際の回答精度が向上します。一方で、マルチモーダル処理は実行時間やコストが増大する傾向にあります。PDFの内容に応じて条件分岐ノードを活用し、「画像を含む文書のみマルチモーダル処理を行う」といったパイプラインを組むことで、コスト効率と精度のバランスを最適化できるでしょう。
おわりに
本記事では、Dify v1.11.0で実装されたカスタムナレッジパイプラインによるマルチモーダル処理を試しました。 これまでRAGの課題であった「画像情報の欠落」が解消されることで、Difyでの開発体験は次のフェーズへ進んだと言えます。今後もDifyのアップデートを追跡し、実践的な活用方法を紹介していきます。
