はじめに
RAG(Retrieval-Augmented Generation)は、外部知識を検索して応答を生成する仕組みとして広く使われていますが、検索・コンテキスト取得・応答生成のどこが適切に機能しているのかを評価するのは簡単ではありません。 本記事では、RAGの評価指標を体系化した論文**「Ragas: Automated Evaluation of Retrieval Augmented Generation」**で提案された3つの基本指標を紹介します。さらに、その指標を実際に利用できる形で提供するフレームワーク「RAGAS」、Pythonライブラリ版が提供する追加指標、そしてNVIDIAが定めた評価指標も整理します。実際にコードを実行しながら、それぞれの指標がどのように働くのかを確認していきます。
https://arxiv.org/html/2309.15217v2
この記事の対象者
- 構築したRAGパイプラインの評価方法を探している方
- 最新のRAGの技術動向を把握しておきたい方
RAGASとは?
ここでは、まず論文で提案された3つの基本指標を整理します。論文では、RAGの評価指標として以下の3つが提案されています。
-
Faithfulness(忠実性)
-
Answer Relevance(回答の妥当性)
-
Context Relevance(コンテキストの妥当性)
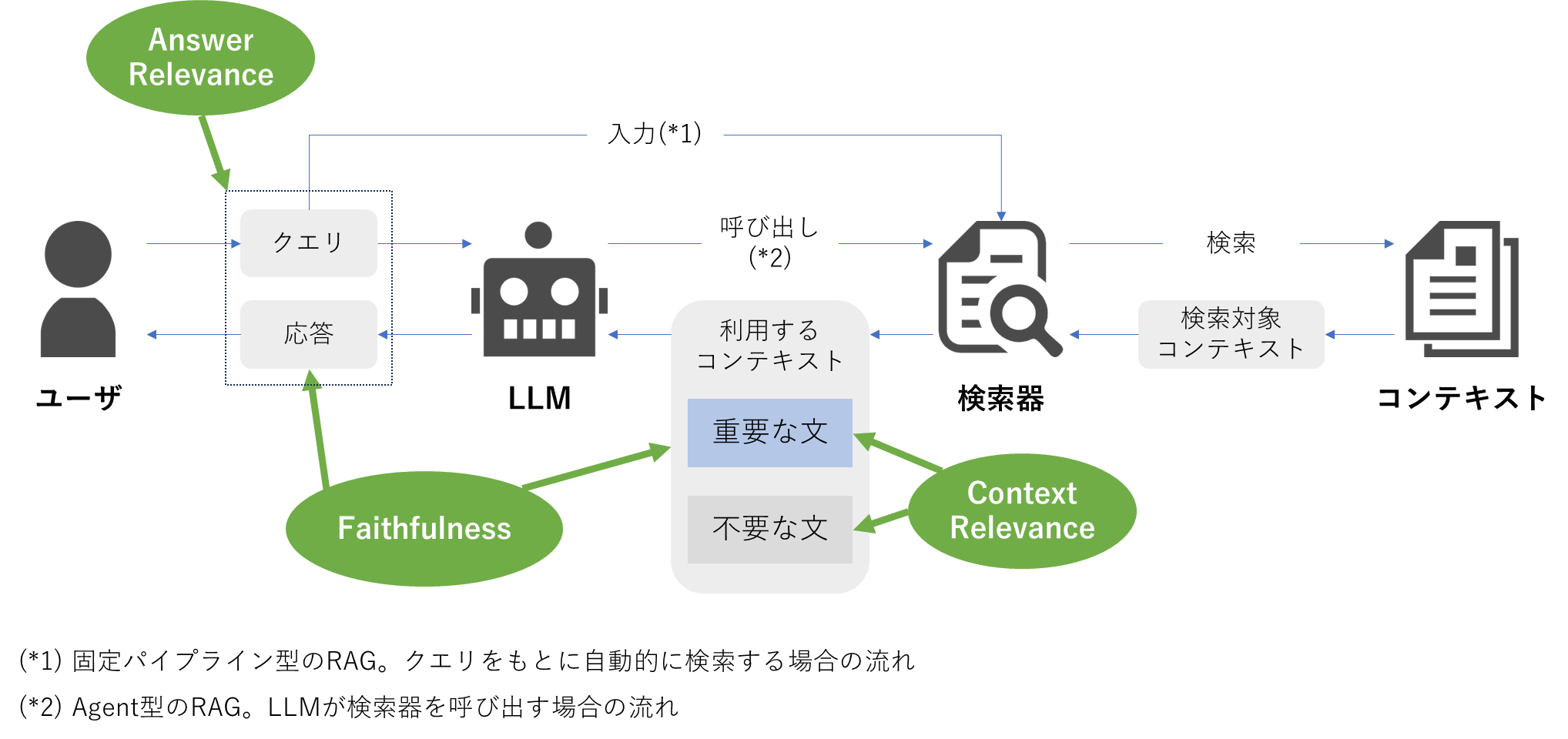 RAGのフローと評価指標の位置づけ(筆者作成)
RAGのフローと評価指標の位置づけ(筆者作成)
指標1:Faithfulness(忠実性)
| 項目 | 内容 |
|---|---|
| 概要 | 生成された応答が、取得したコンテキストの内容にどれだけ正しく基づいているかを測ります。 |
| 背景 | コンテキストが正しく与えられていても、応答がコンテキストにない内容を勝手に述べてしまう「ハルシネーション」が起こり得ます。これを抑えるための指標です。 |
| 評価方法 | 応答を短い主張に分解し、それぞれがコンテキストから根拠をもって説明できるかを確認します。コンテキストと一致していれば評価が高くなります。 |
指標2:Answer Relevance(回答の妥当性)
| 項目 | 内容 |
|---|---|
| 概要 | 応答が質問の意図にきちんと答えられているかを評価します。 |
| 背景 | 応答が詳しくても、そもそも質問に答えていなければ意味がありません。質問とのズレを防ぐための指標です。 |
| 評価方法 | 応答文をもとに「この応答に対応する質問」をLLMに生成させ、元の質問とどれくらい似ているかを測ります。似ているほど、質問に適切に答えていると判断されます。 |
指標3:Context Relevance(コンテキストの妥当性)
| 項目 | 内容 |
|---|---|
| 概要 | 検索で取得したコンテキストが、その質問に答えるために本当に役立つ内容かを測ります。 |
| 背景 | 不要なコンテキストが多いと、生成モデルが必要な情報を取り出しにくくなり、応答品質が下がります。検索精度を見直すための指標です。 |
| 評価方法 | 質問に対して、コンテキストのどの部分が実際に回答に使えるかをLLMに判定させます。関連性が高い部分が多いほど、検索の妥当性が高いと評価されます。 |
RAGASライブラリについて
 https://github.com/explodinggradients/ragas
https://github.com/explodinggradients/ragas
ライブラリの概要
RAGASライブラリは、論文で整理された3つの基本指標を土台に、実運用で必要となる複数の評価指標を備えたRAG評価用のPythonパッケージです。検索、コンテキスト取得、応答の生成といった処理の段階ごとに品質を確認できるよう、指標が大きく拡張されています。 この後のセクションでは、ライブラリが提供する各評価指標を詳しく見ていきます。
RAGAS Metrics
ここでは代表的な8つの指標を取り上げます。
1. Context Precision
| 項目 | 内容 |
|---|---|
| 概要 | 検索で取得したコンテキストの中で、本当に役立つチャンクを上位にランキングできたかを評価する指標 |
| 背景 | 検索が適切でも、チャンクの順番が悪い(不要なチャンクが上位に来る)と、生成応答の質が落ちます。この指標では検索におけるランキングの正確さをチェックします。 |
| 算出方法 | 1. 取得したコンテキストのチャンクについて「クエリへの回答に役立つか」を評価して、関連度(0/1)としてスコアリングする 2. 上位1~k件のチャンクを用いて、それぞれ関連するチャンクの割合(Precision@k)を算出する 3. Precision@kの関連度を使った加重平均をContext Precisionとする \text{Context Precision@K} = \frac{\sum_{k=1}^{K}(\text{Precision@k} × 関連度@k)} {\text{上位K件のうち関連するチャンク数}} |
| 指標の見方 | 取得されたコンテキストを上から順に眺めて、「このチャンクは質問を解くのに役立つか」を判断します。上位のチャンクに役立つものが多ければスコアが高くなり、少なければ低くなります。 ・範囲:0~1 ・0の意味:クエリに関連するチャンクを1つも取得できない(最悪) ・1の意味:クエリに関連するチャンクのみを取得できている(最良) |
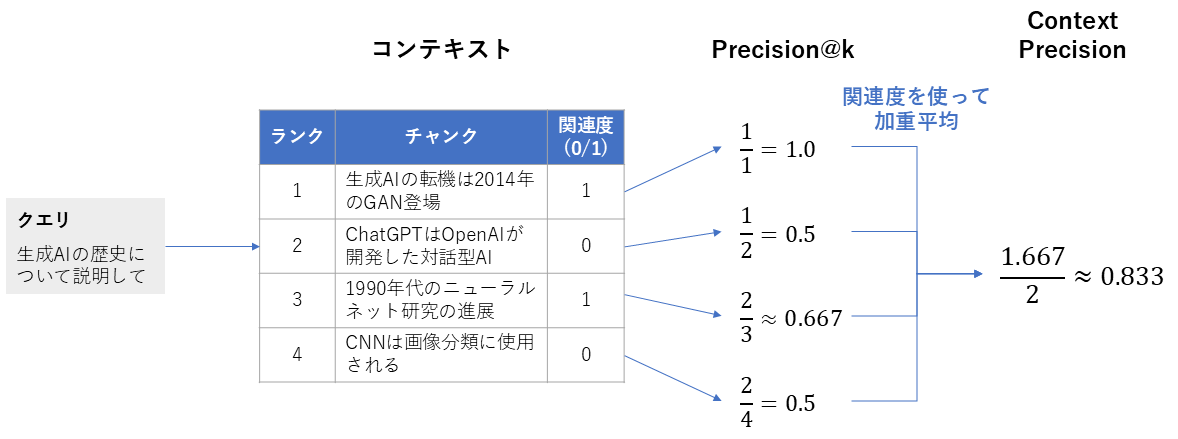 Context Precisionの計算方法(筆者作成)
Context Precisionの計算方法(筆者作成)
2. Context Recall
| 項目 | 内容 |
|---|---|
| 概要 | 質問を解くうえで必要なコンテキストを、どれだけ漏らさず取得できているかを評価する指標 |
| 背景 | 関連文書の一部しか取得できず、情報の取りこぼしがあると、回答は不完全になりがちです。そこで検索の「網羅性」をチェックします。 |
| 算出方法 | 1. 正解には複数の情報が含まれるため、それらを評価可能な最小単位の情報要素(主張、claim)に分割する。 2. 各主張について、「この主張を裏付ける情報が取得済みコンテキスト内に存在するか」を LLM で判定し、含まれていれば 1、含まれなければ 0 としてスコア化する。 3. 次の式を計算し、その値をContext Recallとする。 \text{Context Recall} = \frac{\text{コンテキストでカバーできた主張数}} {\text{正解に含まれる主張の総数}} |
| 指標の見方 | 正解に含まれる情報要素のうち、どれだけ多くを取得したコンテキストで裏付けられているかを見ます。取得漏れが少なければスコアが高くなります。 ・範囲:0~1 ・0の意味:正解を構成する主張がコンテキストでカバーされていない(必要な情報を取得できていない) ・1の意味:正解を構成する主張をコンテキストだけですべてカバーできている(必要な情報を取りこぼしていない) |
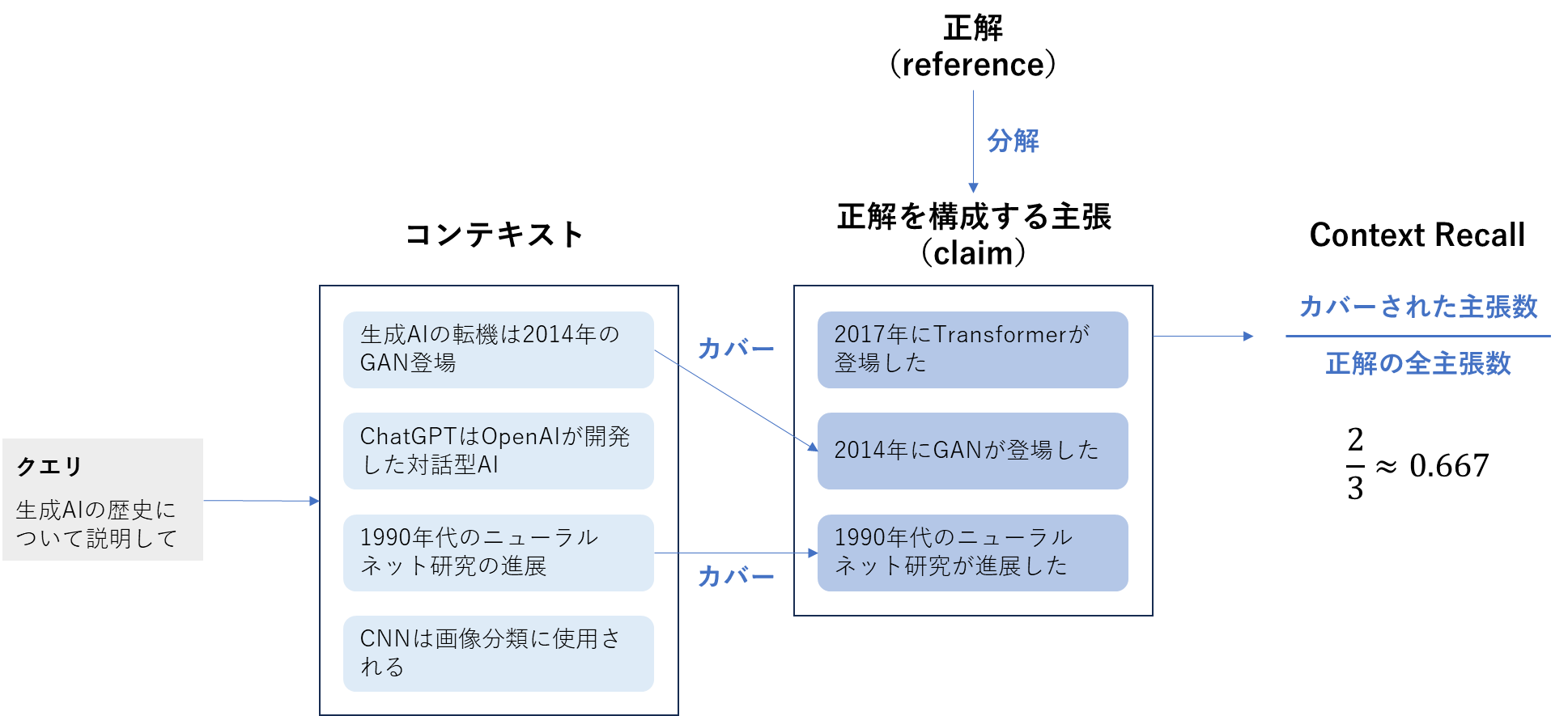 Context Recallの計算方法(筆者作成)
Context Recallの計算方法(筆者作成)
3. Context Entities Recall
| 項目 | 内容 |
|---|---|
| 概要 | 正解に含まれる重要な固有表現(エンティティ)が、取得されたコンテキストにどれだけ含まれているかを測る指標 |
| 背景 | 特に「固有名詞」「数値」「日付」などが重要な問いでは、コンテキストがそれらを拾えているかどうかが大きな鍵となります。 |
| 算出方法 | 1. 正解となる回答(reference)から、エンティティ(例:人名、地名、組織名、日付、数値)を抽出して集合REを作る 2. 取得コンテキスト(retrieved_contexts)から、同様にエンティティを抽出して集合RCEを作る 3. 次の式を計算し、その値をContext Entities Recallとする \ \text{Context Entities Recall} = \frac{\lvert RCE \cap RE \rvert}{\lvert RE \rvert} \ |
| 指標の見方 | 正解に含まれる重要なエンティティが、取得コンテキスト側でどれだけ取りこぼされずに拾えているか(網羅性)を見ます。固有名詞・数値・日付などが重要な質問で特に有効です。 ・範囲:0〜1 ・0の意味:正解に含まれるエンティティが、取得コンテキストに含まれていない(全て取りこぼしている) ・1の意味:正解に含まれるエンティティを、取得コンテキストがすべて含んでいる(取りこぼしがない) |
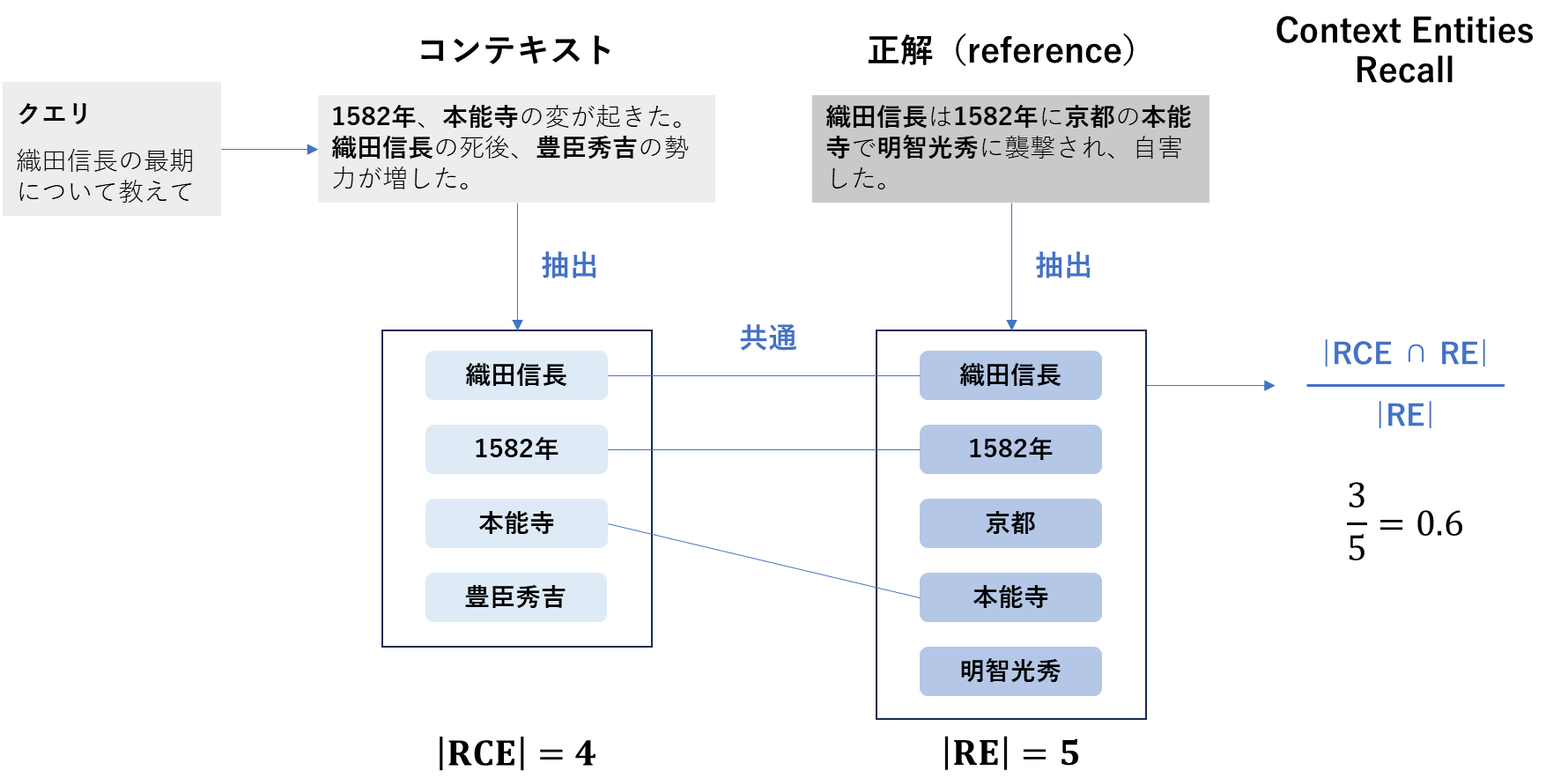 Context Entities Recallの計算方法(筆者作成)
Context Entities Recallの計算方法(筆者作成)
4. Noise Sensitivity
| 項目 | 内容 |
|---|---|
| 概要 | 検索で取得されたコンテキストに関連性の低い情報やノイズが混ざっている場合でも、生成応答が誤った主張をどれだけ出すかを評価する指標 |
| 背景 | 検索結果に関連度の低い情報が含まれていると、それが応答の誤った主張につながる可能性があります。そこで、誤った主張がどれだけ多く生じるかを測定します。 |
| 算出方法 | 1. 生成された応答(response)を主張(claim)ごとに分解する 2. 各主張について、正解(reference)を根拠としてその主張が正しいかどうかを判定し、あわせてその主張が取得されたコンテキスト(retrieved_contexts)に含まれる情報に基づいているかを確認する 3. 応答中に含まれる誤った主張の総数と、応答中の主張の総数を数える 4. 次の式を計算し、それをNoise Sensitivityとする \text{Noise Sensitivity} = \frac{誤った主張の総数}{応答中の主張の総数} |
| 指標の見方 | 生成された応答に含まれる主張のうち、誤った主張がどれだけ含まれているかを評価します。取得コンテキストに関連性の低い情報や無関係な文書が混ざっている場合でも、応答がそれらに惑わされず正しい主張を出せているかを見る指標です。 ・範囲:0〜1 ・0の意味:応答中に誤った主張が含まれていない(ノイズの影響を受けず正しい内容を出せている) ・1の意味:応答中の全ての主張が誤っている(ノイズの影響を受けて全て間違った内容である) |
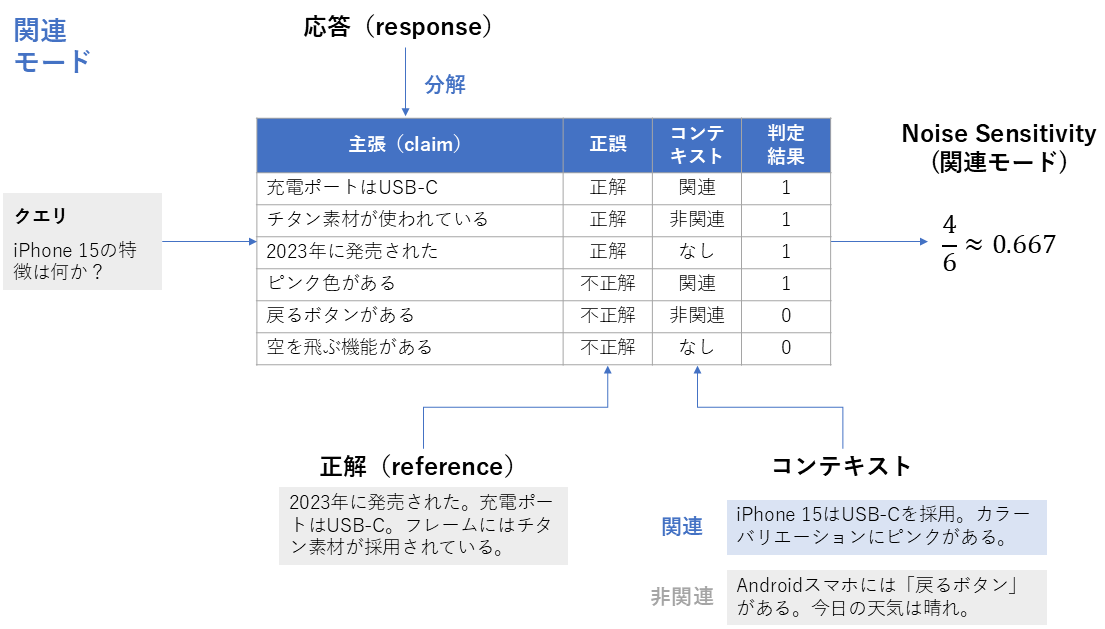 Noise Sensitivity (mode=”relevant”) の計算方法(筆者作成)
Noise Sensitivity (mode=”relevant”) の計算方法(筆者作成)
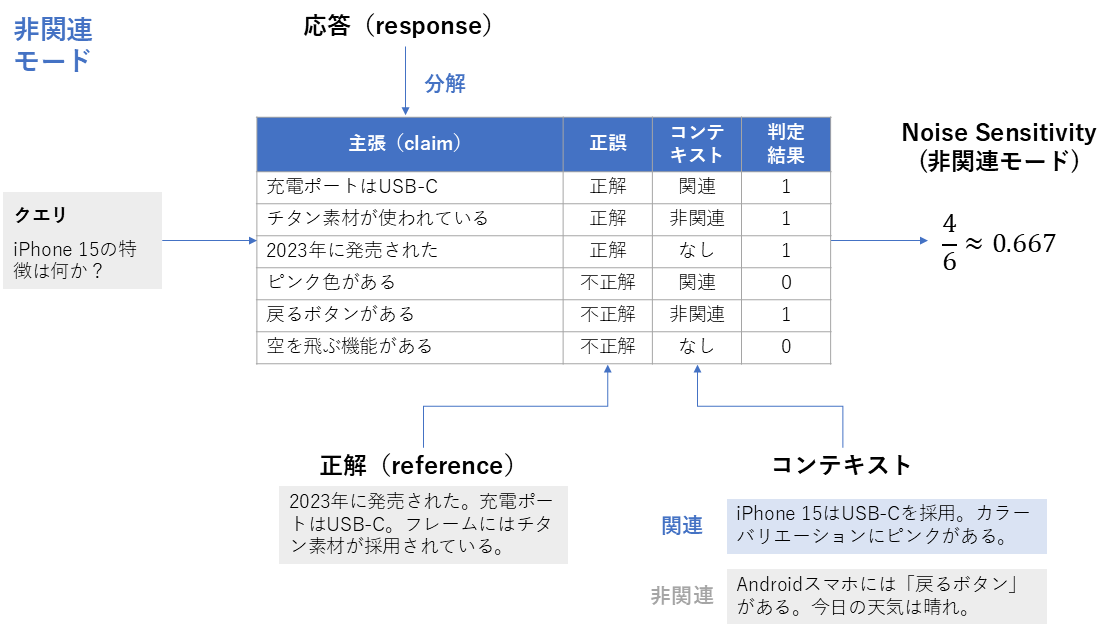 Noise Sensitivity (mode=”irrelevant”) の計算方法(筆者作成)
Noise Sensitivity (mode=”irrelevant”) の計算方法(筆者作成)
5. Response Relevancy
| 項目 | 内容 |
|---|---|
| 概要 | 生成された応答が質問に対してどれだけ適切に答えているかを評価する指標 |
| 背景 | 応答が正しい内容を含んでいても、質問の意図から外れていれば評価は下がります。そこで、質問と応答の整合性を確認します。 |
| 算出方法 | 1. 生成された応答(response)を基にして、複数の人工的な質問を生成する(通常はデフォルトで3件) 2. 質問(user_input)と各人工質問に対して埋め込み(embedding) を算出する ・元の質問の埋め込みをEo ・i番目の人工質問の埋め込みをE_{g_i} 3. 元の質問と人工質問それぞれのベクトル間で、コサイン類似度を計算する ・\text{cosine similarity}(E_{g_i}, E_o) 4. コサイン類似度の平均値を取り、それをAnswer Relevancy(Response Relevancy)とする \text{Answer Relevancy} = \frac{1}{N} \sum_{i=1}^{N} \text {cosine similarity}(E_{g_i}, E_o) |
| 指標の見方 | 単に内容が正確かどうかではなく、質問の意図に適切に応答できているかを測ります。 ・範囲:通常は 0〜1(コサイン類似度の理論範囲は −1〜1 だが、応答と人工質問の平均では通常 0〜1 に収まる) ・値が高い:応答が元の質問の意図と強く関連しており、質問に適切に答えている ・値が低い:応答が質問の意図から外れており、関連性が低い可能性がある |
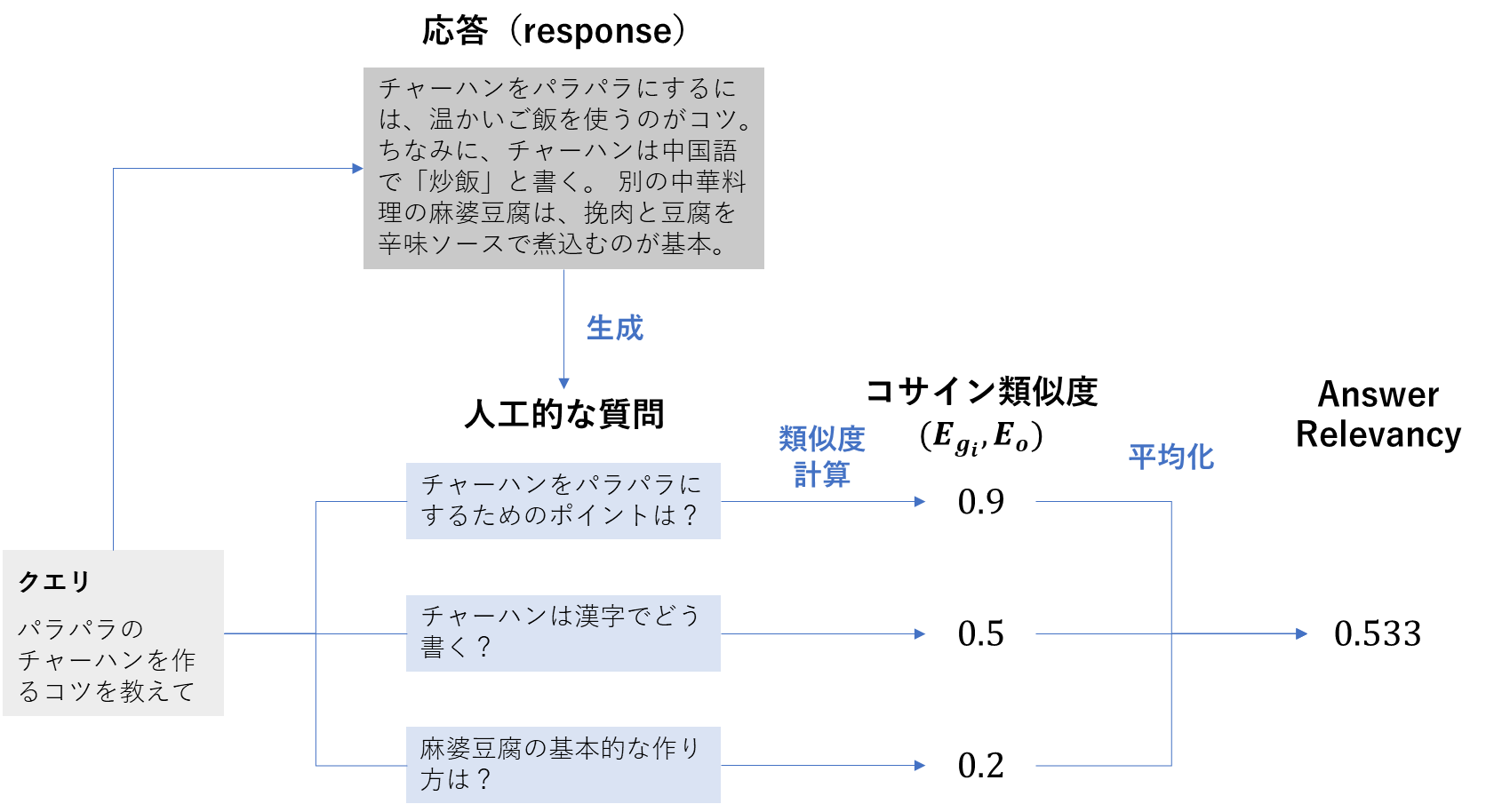 Response Relevancyの計算方法(筆者作成)
Response Relevancyの計算方法(筆者作成)
6. Faithfulness
| 項目 | 内容 |
|---|---|
| 概要 | 生成された応答が、取得されたコンテキストに忠実に基づいているかを評価する指標 |
| 背景 | RAGでは事実と矛盾する内容(ハルシネーション)が生じる可能性があります。そのため、応答内の主張が実際に取得コンテキストから支持できるかを確認します。 |
| 算出方法 | 1. 生成された応答(response)を個々の主張(claim)に分解する 2. 各主張について、取得されたコンテキストから支持できるかを判定する 3. 次の式を計算し、それをFaithfulnessとする \text{Faithfulness score} = \frac{\text{取得コンテキストから支持される主張の数 }}{\text{応答内の主張の総数}} |
| 指標の見方 | 応答が元のコンテキストの情報にどれだけ基づいているかを測ります。 ・範囲:0〜1 ・値が高い:応答内の主張が取得コンテキストに基づいている ・値が低い:応答が取得コンテキストと矛盾しているか、支持できない主張を含む可能性がある |
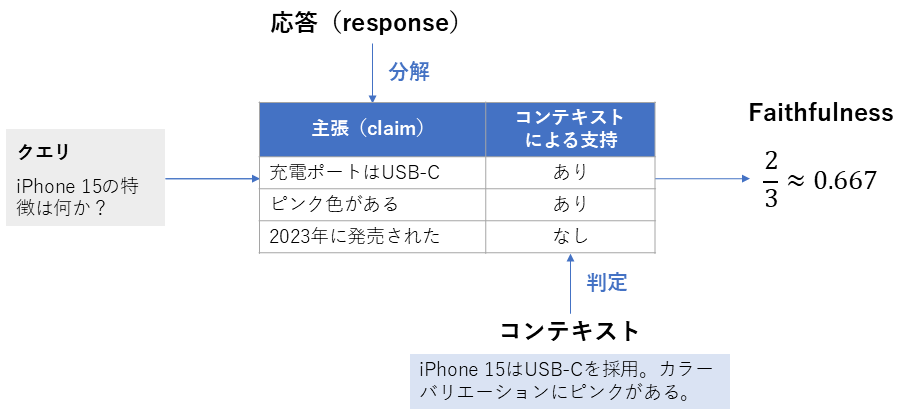 Faithfulnessの計算方法(筆者作成)
Faithfulnessの計算方法(筆者作成)
7. Multimodal Faithfulness
| 項目 | 内容 |
|---|---|
| 概要 | テキストだけでなく画像などの視覚情報も含めたマルチモーダルなコンテキストに対して、生成された応答がどれだけ忠実かを測る指標 |
| 背景 | マルチモーダルなRAGシステムでは、文書だけでなく画像・動画などを参照するケースも増えており、視覚・テキスト両方の根拠性を評価できる必要があります。 |
| 算出方法 | 1. 生成された応答( response )を、事実確認が可能な細かい主張(claim)に分解する 2. 分解した各主張について、取得されたテキストコンテキストまたは画像コンテキストの中に、その内容を裏付ける証拠があるかを判定する 3. 全ての主張に対して証拠が見つかればスコアを 1 とし、一つでも証拠がない(ハルシネーションを含む)主張があれば 0 とする |
| 指標の見方 | 0または1の二値評価です。 ・0の意味:応答の中に、コンテキストによる裏付けがない主張が含まれている ・1の意味:応答内のすべての主張が、取得された視覚またはテキストコンテキストによって完全に裏付けられている |
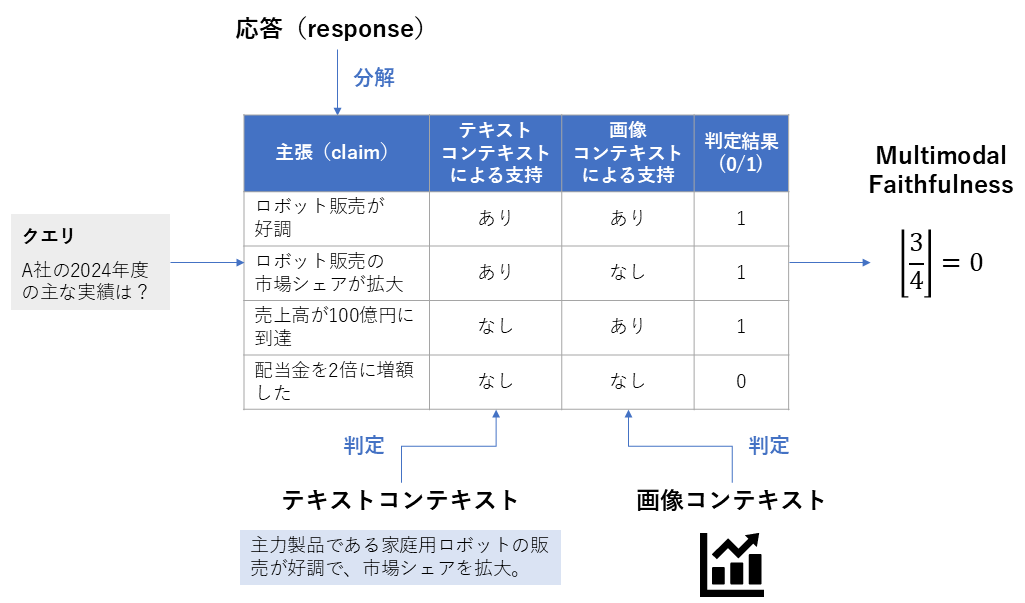 Multimodal Faithfulnessの計算方法(筆者作成)
Multimodal Faithfulnessの計算方法(筆者作成)
8. Multimodal Relevance
| 項目 | 内容 |
|---|---|
| 概要 | マルチモーダルな(テキスト+画像など)コンテキストに対して、生成された応答が質問意図に対して適切に関連しているかを評価する指標 |
| 背景 | 視覚情報やテキストの組み合わせを用いるシステムでは、適切なコンテキスト(画像・図・表)を選び、それが質問に合致しているかを確認することも重要です。 |
| 算出方法 | 1. 質問、生成された応答、集めたコンテキスト(テキスト・画像)を用意する 2. 答えが、コンテキストの内容に合っているかを確認する 3. 合っていれば1、合っていなければ0とする |
| 指標の見方 | 0または1の二値評価です。 ・1の意味:応答が、テキストか画像のどちらかのコンテキストに合っている ・0の意味:応答が、テキストか画像どちらのコンテキストにも合っていない可能性がある |
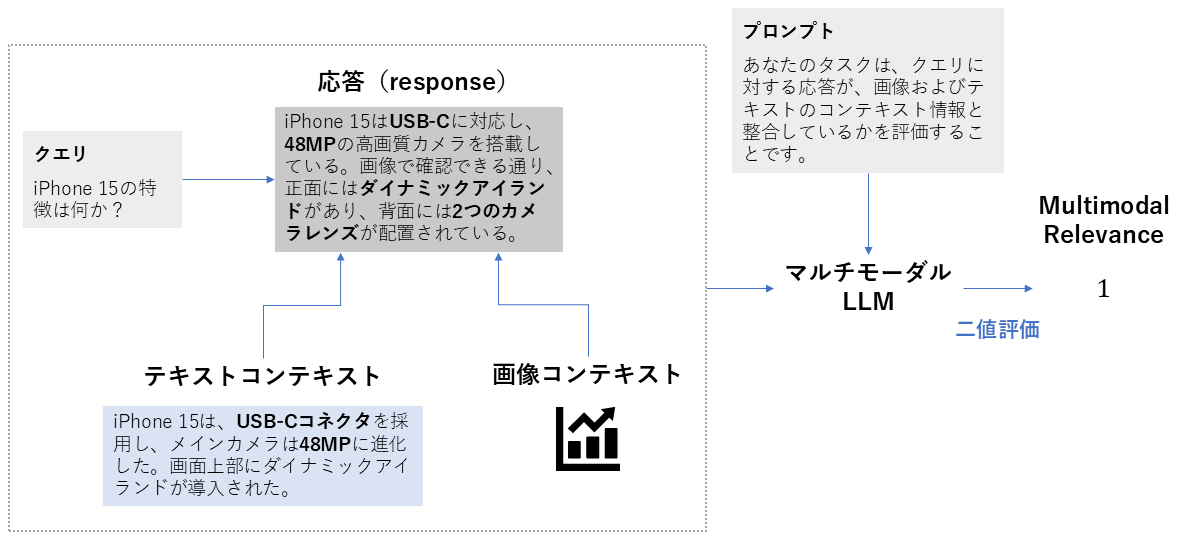 Multimodal Relevanceの計算方法(筆者作成)
Multimodal Relevanceの計算方法(筆者作成)
NVIDIA Metrics
NVIDIA Metricsは、正解ラベルが用意されているデータセットや、定期的に品質を確認したい運用環境で特に有効です。RAGASでは、NVIDIAが定義する以下の3つの指標を利用できます。
1. Answer Accuracy
| 項目 | 内容 |
|---|---|
| 概要 | モデルの応答が、用意された正解とどれだけ一致しているかを評価する指標 |
| 背景 | 応答の正確性が明確なタスク(FAQ、自動質問応答など)において、正解との整合性を直接測ることが非常に有効です。主に、生成された応答の品質を確認するために利用されます。 |
| 算出方法 | 1. 質問(user_input)、応答(response)、正解(reference)を評価用のLLM(評価者)に入力する 2. LLMは、質問と正解を基準として、応答が「正確に答えているか」「部分的に答えているか」「全く答えていないか」を2つのプロンプトを用いて評価する(通常0、2、4のスコアを与える) 3. 得られた評価結果を正規化し、最終的なAnswer Accuracy スコア(0〜1)を得る |
| 指標の見方 | 質問に対してどれだけ正確に答えられているかを測ります。 ・範囲: 0〜1 ・値が高い:応答が正解とほぼ完全に一致しており、質問に非常に正確に答えている ・値が低い:応答が正解と大きく異なっており、誤った情報を含んでいるか、質問に答えていない |
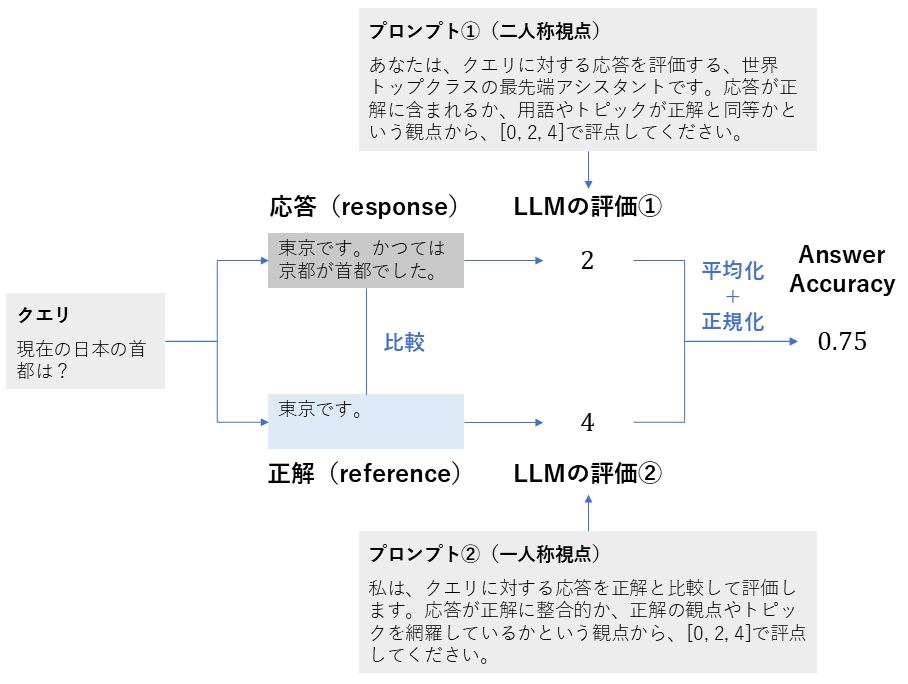 Answer Accuracyの計算方法(筆者作成)
Answer Accuracyの計算方法(筆者作成)
2. Context Relevance
| 項目 | 内容 |
|---|---|
| 概要 | 取得されたコンテキストが、質問に対してどれだけ関連しているかを評価する指標 |
| 背景 | 検索段階で取得された情報が質問と無関係であれば、その後の生成応答の質も低くなる可能性が高まります。生成の前段階で、検索の質(関連性)を早期に検出するために有効です。 |
| 算出方法 | 1. 質問(user_input)と取得されたコンテキスト(retrieved_contexts)を評価用のLLMに入力する 2. 2つのプロンプトを使用し、LLMがコンテキストの関連性を「0(全く関連なし)」「1(部分的)」「2(完全に関連)」の3段階で評価する 3. 得られたスコアを正規化(0〜1に変換)し、その平均値を最終的なスコアとする |
| 指標の見方 | コンテキストが質問にどれだけ深く関わっているかを評価します。 ・範囲: 0〜1 ・値が高い: 取得されたコンテキストが質問の意図に合致しており、回答に役立つ情報を多く含んでいる。 ・値が低い: 取得されたコンテキストが質問と無関係である。 |
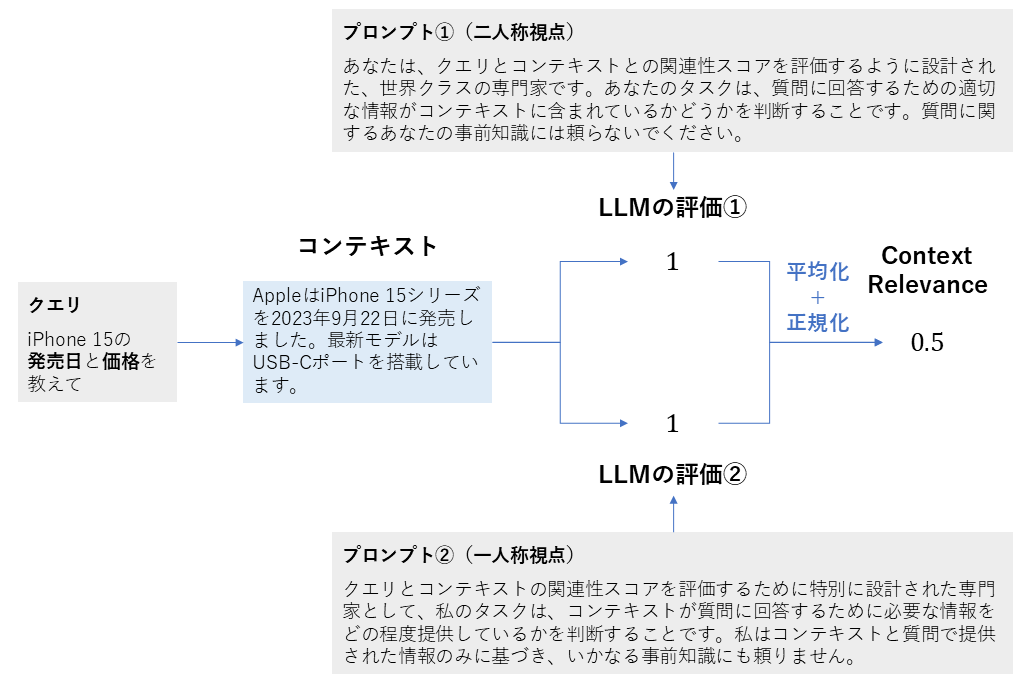 Context Relevanceの計算方法(筆者作成)
Context Relevanceの計算方法(筆者作成)
3. Response Groundedness
| 項目 | 内容 |
|---|---|
| 概要 | 生成された応答の主張が、取得されたコンテキストにどれだけ根拠を持っているかを評価する指標 |
| 背景 | 応答が質問に答えていても、提示されたコンテキストを無視した内容であれば「根拠がない」とみなされ、信頼性に欠けます。応答が与えられた情報からどれだけ裏付けられているかを見るための指標です。 |
| 算出方法 | 1. 応答(response)と取得されたコンテキスト( retrieved_contexts )を評価用のLLMに入力する 2. 2つのプロンプトを使用し、LLMが応答内の各主張がコンテキスト内に存在するかを確認し、「0(根拠なし)」「1(部分的)」「2(完全)」の3段階で評価する 3. 得られたスコアを正規化(0〜1に変換)し、その値を最終的なスコアとする |
| 指標の見方 | 応答がコンテキストに基づいているか(ハルシネーションがないか)を評価します。 ・範囲:0〜1 ・値が高い: 応答のすべての主張が、取得されたコンテキストによって裏付けられている。 ・値が低い: 応答がコンテキストを無視しており、根拠のない情報を含んでいる。 |
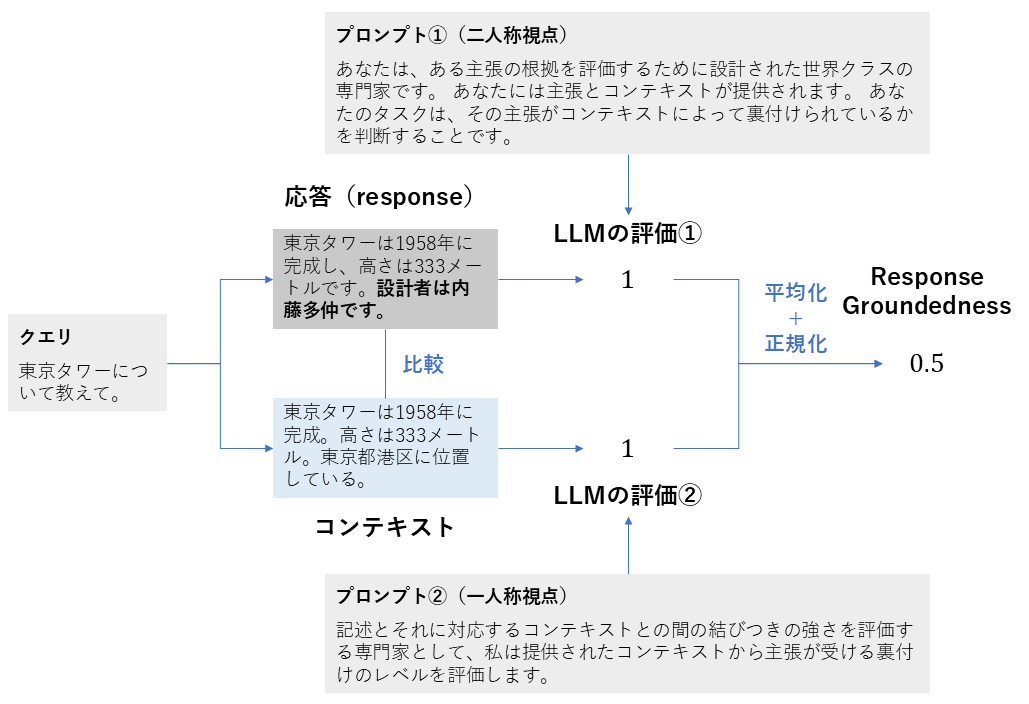 Response Groundednessの計算方法(筆者作成)
Response Groundednessの計算方法(筆者作成)
RAGAS MetricsとNVIDIA Metricsの使い分け
RAGAS Metricsは検索・コンテキスト取得・応答の生成といった各フェーズを細かく評価できるため、開発段階で「どこがボトルネックか」を切り分けるのに適しています。一方、NVIDIA Metricsは指標数が少なく計算が軽いため、運用時に「全体の状態を手早く確認する」用途に適しています。 開発段階ではまずRAGAS Metricsで分析・改善し、運用段階ではNVIDIA Metricsでモニタリング、異常が見られたら再びRAGAS Metricsを使って深掘る、といった使い方がおすすめです。
RAGASライブラリを使ってみる
このセクションでは、まず論文で提案された3つの指標(Faithfulness / Answer Relevance / Context Relevance)に対応する、RAGASライブラリの機能を実際に試します。続いて、同じ3つの指標に対応する、NVIDIAが定義した3つの評価機能も動かしてみます。 最初に、論文での指標とRAGAS Metrics、NVIDIA Metricsの対応関係を以下の表で示し、その後コード例と実行結果を通じてそれぞれをどう使うかを順に解説します。
「論文での指標」と「RAGAS Metrics・NVIDIA Metrics」の対応関係
| 観点 | 論文での指標 | RAGAS Metrics | NVIDIA Metrics |
|---|---|---|---|
| 忠実性 | Faithfulness | Faithfulness | Response Groundedness |
| 回答の妥当性 | Answer Relevance | Response Relevancy | Answer Accuracy |
| コンテキストの妥当性 | Context Relevance | Context Precision Context Recall | Context Relevance |
事前準備
- OpenAIのAPIキーの取得 サインアップした後、こちらからAPIキーを作成し、保存します。
- Python実行環境の準備 今回はGoogle Colaboratoryを使用します。
- ライブラリのインストール
pip install ragas- APIキーのセットアップ Google Colaboratoryで以下を実行してAPIキーを登録します。
import os
import getpass
api_key = getpass.getpass("Enter your OPENAI_API_KEY: ")
os.environ["OPENAI_API_KEY"] = api_key
print("API Key has been set as an environment variable.")- 共通するライブラリのインポートとLLMのセットアップ
from openai import AsyncOpenAI
from ragas.llms import llm_factory
client = AsyncOpenAI()
llm = llm_factory("gpt-4o-mini", client=client)1. RAGAS Metrics
1.1 Faithfulness
from ragas.metrics.collections import Faithfulness
scorer = Faithfulness(llm=llm)
result = await scorer.ascore(
user_input="光合成とは何ですか?",
response = (
"光合成は、植物・藻類・シアノバクテリアが太陽光を使って"
"水と二酸化炭素から酸素と有機物を作り出す生化学的過程です。"
"葉緑体内のクロロフィルが光エネルギーを捉えて反応を進めます。"
),
retrieved_contexts=[
"光合成(Photosynthesis)は、植物・藻類・シアノバクテリアが太陽光を使って水 (H2O) と二酸化炭素 (CO2) から酸素 (O2) と有機物を合成する生化学的過程である。",
"葉緑体内のクロロフィルが光エネルギーを捕らえ、水の分解と二酸化炭素の固定を可能にする。"
]
)
print(f"Faithfulness スコア: {result.value}")コード解説
scorer = Faithfulness(llm=llm)Faithfulnessを使用するためのオブジェクトを作成します。result = await scorer.ascore(...)質問 (user_input)、応答 (response)、検索で取得したコンテキスト (retrieved_contexts)を入力し、スコアを計算します。result.value評価結果の数値(0〜1)を取得します。値が高いほど、応答の内容がコンテキストに忠実であると判断されます。 実行結果
Faithfulness スコア: 0.5- 質問:「光合成とは何ですか?」
- 応答:「光合成は、植物・藻類・シアノバクテリアが太陽光を使って水と二酸化炭素から酸素と有機物を作り出す生化学的過程です。葉緑体内のクロロフィルが光エネルギーを捉えて反応を進めます。」
- スコア:0.5 この結果は、生成された応答の主張のうち、コンテキストに基づいて裏付けられた部分と、明示的に根拠が確認できなかった部分が半々だったためです。基本的な説明はコンテキストと一致している一方、「有機物を作り出す」といった表現がコンテキストと完全には一致せず、部分的な不一致として扱われたことが影響しています。
1.2 Response Relevancy
from ragas.embeddings.base import embedding_factory
from ragas.metrics.collections import AnswerRelevancy
embeddings = embedding_factory("openai", model="text-embedding-3-small", client=client, interface="modern")
scorer = AnswerRelevancy(llm=llm, embeddings=embeddings)
result = await scorer.ascore(
user_input = "第一回スーパーボウルはいつ行われましたか?",
response = "第一回スーパーボウルは1967年1月15日に開催されました。"
)
print(f"Answer Relevancy Score: {result.value}")コード解説
embeddings = embedding_factory("openai", model="text-embedding-3-small", …)埋め込みモデルを設定し、質問や応答を数値ベクトルに変換できるようにします。scorer = AnswerRelevancy(llm=llm, embeddings=embeddings)Answer Relevancyを使用するためのオブジェクトを作成します。ここには LLMと埋め込みモデルを組み込んでいます。result = await scorer.ascore(user_input=…, response=…)質問 (user_input)と応答(response)を入力して、関連性スコアを計算します。 実行結果
Answer Relevancy Score: 0.43362125571535076- 質問:「第一回スーパーボウルはいつ行われましたか?」
- 応答:「第一回スーパーボウルは1967年1月15日に開催されました。」
- スコア:0.43362125571535076 このようにスコアが低く出る主な理由は、RAGASの既定の評価プロンプトやfew-shot例が英語テキストを前提として設計されているためです。公式ドキュメントでも、英語以外の言語で利用する場合は評価プロンプトを使用したい言語向けに適応させることが推奨されています。
1.3 Context Precision
from ragas.metrics.collections import ContextPrecision
scorer = ContextPrecision(llm=llm)
result = await scorer.ascore(
user_input="エッフェル塔はどこにありますか?",
reference="エッフェル塔はパリにあります。",
retrieved_contexts=[
"エッフェル塔はパリにあります。",
"ブランデンブルク門はベルリンにあります。"
]
)
print(f"Context Precision Score: {result.value}")コード解説
scorer = ContextPrecision(llm=llm)ContextPrecisionを使用するためのオブジェクトを作成します。result = await scorer.ascore(...)質問(user_input)、正解(reference)、検索で取得したコンテキスト(retrieved_contexts)を入力として、スコアを計算します。 実行結果
Context Precision Score: 0.9999999999- 質問:「エッフェル塔はどこにありますか?」
- 正解:「エッフェル塔はパリにあります。」
- 取得されたコンテキスト: 1.「エッフェル塔はパリにあります。」 2.「ブランデンブルク門はベルリンにあります。」
- スコア:0.9999999999 この結果は、取得されたコンテキストの上位(1番目)に質問に対して明確に有用なコンテキストが配置されており、そのため非常に高い値となったことを示しています。
1.4 Context Recall
from ragas.metrics.collections import ContextRecall
scorer = ContextRecall(llm=llm)
result = await scorer.ascore(
user_input="エッフェル塔はどこにありますか?",
retrieved_contexts=["パリはフランスの首都です。"],
reference="エッフェル塔はパリにあります。"
)
print(f"Context Recall Score: {result.value}")コード解説
scorer = ContextRecall(llm=llm)Context Recallを使用するためのオブジェクトを作成します。result = await scorer.ascore(...)質問(user_input)、取得したコンテキスト(retrieved_contexts)、正解文(reference)を入力し、必要な情報がコンテキスト内に含まれているかを評価します。 実行結果
Context Recall Score: 1.0- 質問:「エッフェル塔はどこにありますか?」
- 正解:「エッフェル塔はパリにあります。」
- 取得されたコンテキスト:「パリはフランスの首都です。」
- スコア:1.0 この結果は、正解文に含まれる重要語句(「パリ」など)が取得されたコンテキストに含まれており、必要な情報の取りこぼしがなかったと評価されたことを示します。
2. NVIDIA Metrics
2.1 Response Groundedness
from ragas.metrics.collections import ResponseGroundedness
scorer = ResponseGroundedness(llm=llm)
result = await scorer.ascore(
response="アルベルト・アインシュタインは1879年に生まれました。",
retrieved_contexts=[
"アルベルト・アインシュタインは1879年3月14日に生まれました。",
"アルベルト・アインシュタインはドイツのヴュルテンベルク州ウルムで生まれました。",
]
)
print(f"Response Groundedness Score: {result.value}")コード解説
scorer = ResponseGroundedness(llm=llm)Response Groundednessを使用するためのオブジェクトを作成します。result = await scorer.ascore(...)応答(response)と、取得されたコンテキスト(retrieved_contexts)を入力として、応答がそのコンテキストにどれだけ根拠を持っているかを評価します。 実行結果
Response Groundedness Score: 1.0- 応答:「アルベルト・アインシュタインは1879年に生まれました。」
- 取得されたコンテキスト:
- 「アルベルト・アインシュタインは1879年3月14日に生まれました。」
- 「アルベルト・アインシュタインはドイツのヴュルテンベルク州ウルムで生まれました。」
- スコア:1.0 この結果は、応答の主張が取得されたコンテキストに完全に支持されており、根拠に基づいていると評価されたことを示しています。
2.2 Answer Accuracy
from ragas.metrics.collections import AnswerAccuracy
scorer = AnswerAccuracy(llm=llm)
result = await scorer.ascore(
user_input="アインシュタインはいつ生まれましたか?",
response="アルベルト・アインシュタインは1879年に生まれました。",
reference="アルベルト・アインシュタインは1879年に生まれました。"
)
print(f"Answer Accuracy Score: {result.value}")コード解説
scorer = AnswerAccuracy(llm=llm)Answer Accuracyを使用するためのオブジェクトを作成します。result = await scorer.ascore(...)質問(user_input)、応答(response)、正解(reference)を入力し、応答が正解にどれだけ近いかを評価します。 実行結果
Answer Accuracy Score: 1.02.3 Context Relevance
from ragas.metrics.collections import ContextRelevance
scorer = ContextRelevance(llm=llm)
result = await scorer.ascore(
user_input="アインシュタインはいつ生まれましたか?",
retrieved_contexts=[
"アルベルト・アインシュタインは1879年3月14日に生まれました。",
"アルベルト・アインシュタインはドイツのヴュルテンベルク州ウルムで生まれました。",
]
)
print(f"Context Relevance Score: {result.value}")コード解説
scorer = ContextRelevance(llm=llm)Context Relevanceを使用するためのオブジェクトを生成します。result = await scorer.ascore(...)質問 (user_input)と取得したコンテキスト(retrieved_contexts)を入力として、コンテキストが質問にどれだけ関係しているかを評価します。 実行結果
Context Relevance Score: 1.0- 質問:「アインシュタインはいつ生まれましたか?」
- 取得されたコンテキスト:
- 「アルベルト・アインシュタインは1879年3月14日に生まれました。」
- 「アルベルト・アインシュタインはドイツのヴュルテンベルク州ウルムで生まれました。」
- スコア:1.0 この結果は、提供されたコンテキストが質問に対して完全に関連しており、取得されたコンテキストの関連性が非常に高く評価されたことを示しています。
おわりに
本記事では、RAGを評価するための仕組みとしてRAGASを紹介し、論文の基本指標からライブラリ版が提供する指標、NVIDIAの指標までを整理しました。実際にコードを動かしながら確認することで、それぞれの指標がどの段階を評価しているのかを掴めたと思います。 RAGは検索・コンテキスト取得・応答生成のどこで問題が起きているかが分かりにくい構造ですが、RAGASを使うことで原因を切り分けやすくなります。開発中の品質チェックにも、運用時の確認にも活用できるため、自分のRAGパイプラインを改善する際の参考にしてみてください。
参考文献
https://arxiv.org/html/2309.15217v2
https://github.com/explodinggradients/ragas
