1. はじめに
1.1 この記事について
本記事では、論文「Retrieval-Augmented Generation for AI-Generated Content: A Survey」を基に、RAGのアーキテクチャや基礎構造、性能を高める工夫、そして応用事例を紹介します。
論文そのものは膨大かつ専門的ですが、ここでは 「どんな種類があるのか」「どんな改善方法があるのか」 に焦点を絞り、まとめています。
https://arxiv.org/html/2402.19473v6
1.2 対象者
- RAGの全体像を知りたい人
- 社内QAや検索付きアプリを作っていて、RAGをどう活かせるか気になっている人
- 論文を全部読む時間はないけれど、ポイントだけ押さえたい人
1.3 これを読むと何が嬉しいのか?
- RAGの基本4パターンと強化ポイント5つをまとめて把握できる
- 設計時のつまずきを減らすチェックポイントや代表的な手法がわかる
- テキストやコード、画像など用途ごとの事例を探す入口になる
2. RAGとは?
2.1 RAGとは(アーキテクチャ)
RAG(Retrieval-Augmented Generation)は、「生成の前に検索を挟む仕組み」です。まず検索器(Retriever)が外部のデータベースや文書群から関連する情報を取り出し、それを生成器(Generator)に渡して出力を作ります。流れとしては 入力 → 検索 → 増強 → 生成 というシンプルな形です。
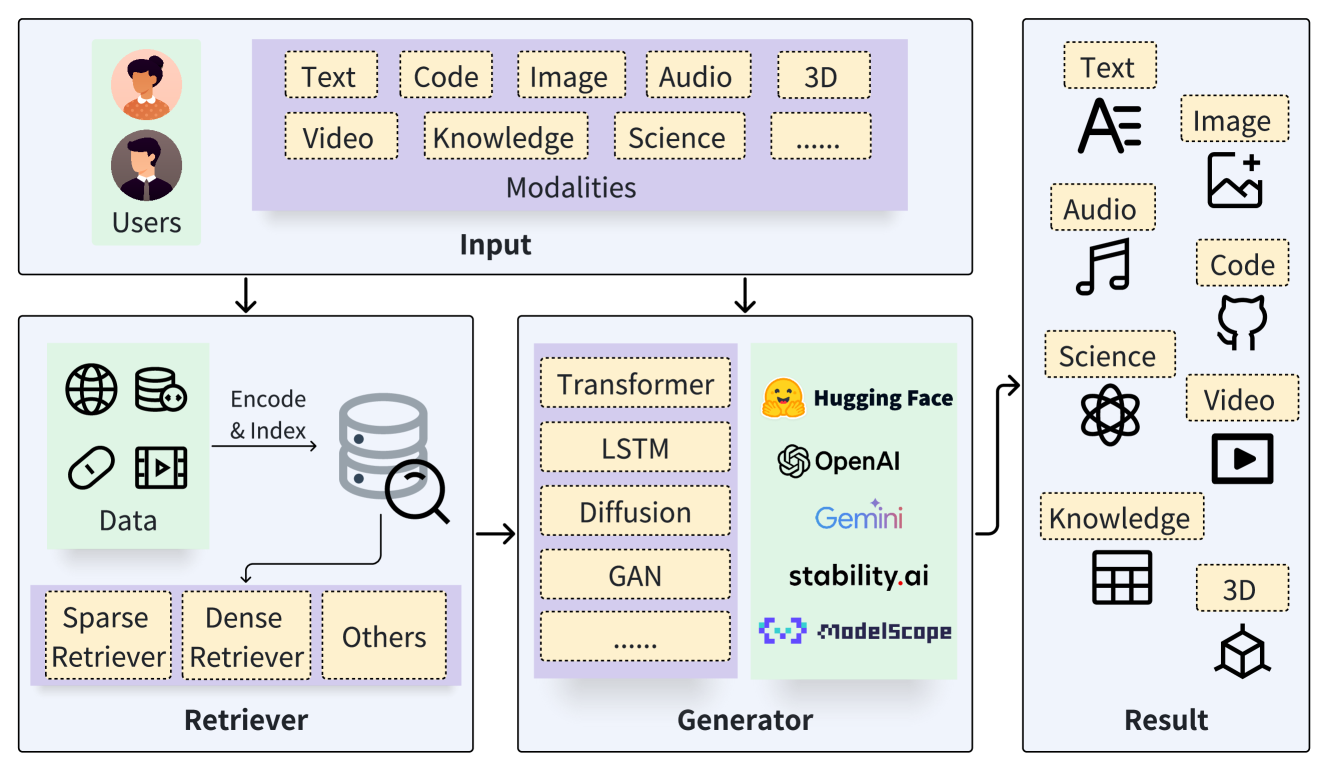 汎用的なRAGアーキテクチャ。ユーザーのクエリ(複数モダリティ)は検索器と生成器に入力され、検索器はデータソースから関連情報を取得し、生成器がそれを利用して最終的な出力を生成します。
汎用的なRAGアーキテクチャ。ユーザーのクエリ(複数モダリティ)は検索器と生成器に入力され、検索器はデータソースから関連情報を取得し、生成器がそれを利用して最終的な出力を生成します。
典型的な流れ
- ユーザーからの入力(テキスト、画像、コードなど)を受け取ります。
- 検索器が関連する情報をデータソースから探します。
- 見つけた情報を生成器に渡して、回答や文章を補強します。
- 生成器が最終的な出力を返します。
何が嬉しいのか
- 知識を外部に置ける:モデル内部に全部を覚えさせる必要がなく、後から情報を更新しやすいです。
- 広い領域をカバーできる:出現頻度は低いが種類は多いニッチな知識や最新情報にも対応しやすいです。
- コスト削減にもつながる:大きなモデルに丸投げするよりも効率よく答えを出せます。
2.2 RAGの予備知識(検索器・生成器)
RAGを構成する中心的な要素は「生成器(Generator)」と「検索器(Retriever)」です。ここでは基本的な役割と代表的な種類を整理します。
生成器(Generator)
生成器は最終的な出力を担うモデル群です。扱うデータや用途に応じて形式が変わりますが、代表的なものは次の通りです。
- Transformer:現在の主流。自己注意機構を用いて文脈を捉えつつ、単語やトークンを逐次生成します。
- LSTM:RNNの一種。長期依存関係を保持しながら系列データを処理できます。
- 拡散モデル:ノイズを段階的に除去してデータを生成する手法。特に画像生成で活用されています。
- GAN:生成器と識別器を競わせながら学習させる仕組み。よりリアルなデータを生成する際に用いられます。
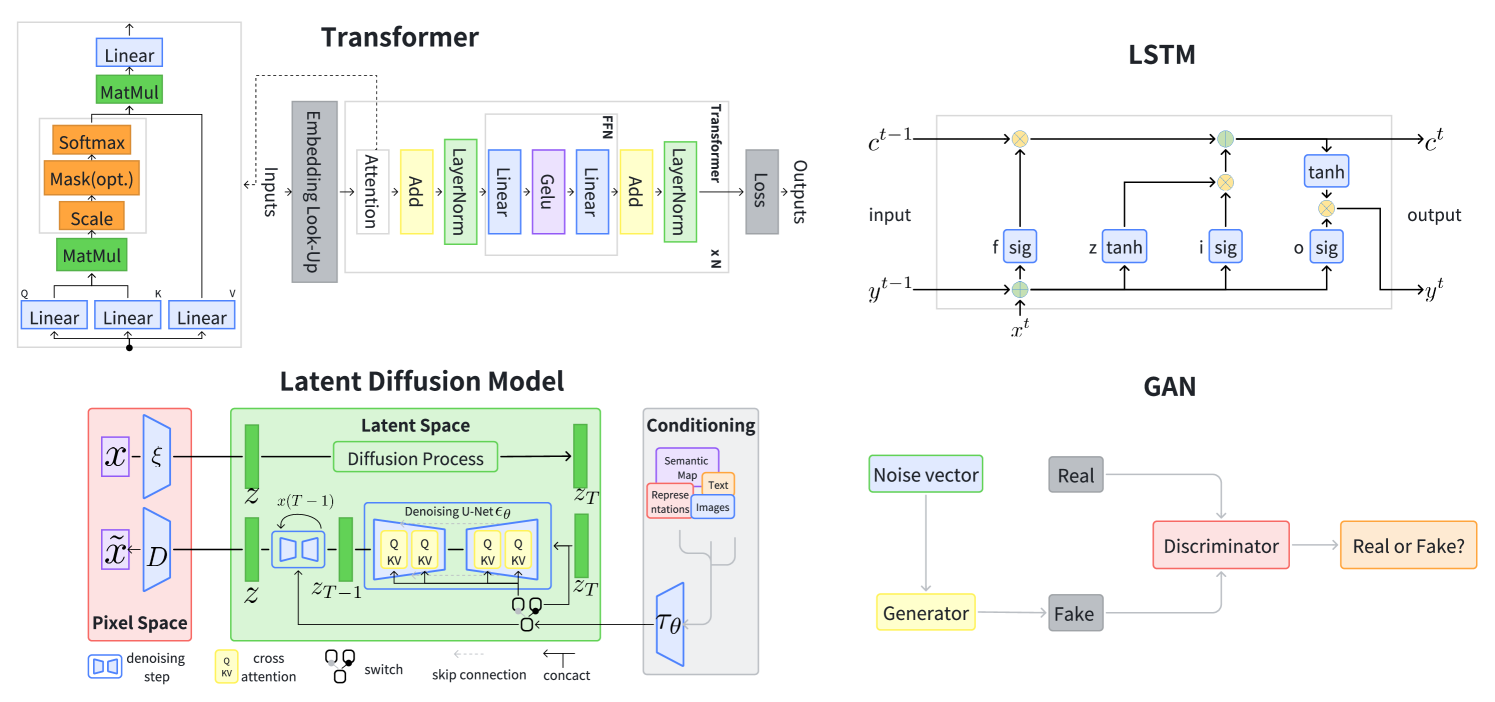 生成器の一般的なアーキテクチャ。
生成器の一般的なアーキテクチャ。
検索器(Retriever)
検索器は外部の知識ベースや文書群から関連情報を取り出す役割を持ちます。基本的には 表現の作成(知識ベースや文書群をコンピュータが扱えるベクトルなどに変換する処理)と **高速探索 **の二段階で処理が進み、以下のような系統があります。
- Sparse Retriever:単語の一致度を基準に検索します。TF-IDFやBM25などが代表的で、倒立インデックスを用いた高速化が一般的です。
- Dense Retriever:テキストやクエリを埋め込みベクトルに変換し、類似度計算で近いものを検索します。DPR(Dense Passage Retrieval)に代表され、近似最近傍探索(HNSWなど)を併用して効率的に動作します。テキストだけでなくコードや画像・音声にも応用されています。
- その他の手法:文字列編集距離のように直接比較するものや、コードの構造に基づく検索、知識グラフ探索やエンティティベースの検索などがあります。
3. RAGの基礎構造(III-A RAG Foundations)
ここでは、RAGの中核をなす4つの基盤アプローチ(Query-based、Latent Representation-based、Logit-based、Speculative)について、それぞれの特徴や応用例を説明します。それぞれの強みと使いどころを理解することがポイントです。
 Foundations分類図(4類型の位置づけ)。
Foundations分類図(4類型の位置づけ)。
3.1 Query-based RAG
| 項目 | 内容 |
|---|
| 概要 | 検索した文書をユーザーの質問に結合し、そのまま生成モデルに渡す方法です。最もシンプルで広く使われています。 |
| メリット | 実装が簡単で、ローカルモデルでもAPI経由のLLMでも利用可能です。既存の部品を組み合わせやすく、すぐに試せます。 |
| 留意点 | 入力が長くなりやすく、処理が重くなることがあります。検索内容をどうプロンプトに組み込むかの設計が大切です。 |
| 代表手法 | REALM、RAG(DPR + BART)、Self-RAG、REPLUG、In-Context RALM |
| 主な応用領域 | QAやKBQA、コード生成・補完、医療支援(Chat-Orthopedist)、画像生成(RetrieveGAN、IC-GAN)、3D生成(RetDream) |
3.2 Latent Representation-based RAG
| 項目 | 内容 |
|---|
| 概要 | 検索した内容を潜在表現に変換し、モデル内部の隠れ層に組み込んで使う方法です。 |
| メリット | 情報を効率的に取り込み、生成の質を高められます。長いコンテキストの問題を和らげられます。 |
| 留意点 | モデル内部に組み込むため、追加の学習や改造が必要になることが多いです。 |
| 代表手法 | FiD、RETRO、EaE、TOME、ReMoDiffuse、AMD、Re-AudioLDM、R-ConvED、CARE、EgoInstructor |
| 主な応用領域 | QAや要約、コード関連タスク、科学分野での活用、画像(クロスアテンションなど)、3Dモーション生成、音声キャプション、ビデオキャプション |
3.3 Logit-based RAG
| 項目 | 内容 |
|---|
| 概要 | 生成の途中で出る「次の単語の確率」に、検索結果からの情報を足して補正する方法です。 |
| メリット | めったに出ない単語や表現に強く、生成の精度を上げやすいです。また、確率を使うのでシーケンス生成と相性が良いです。 |
| 留意点 | 特になし |
| 代表手法 | kNN-LM、TRIME、NPM、EDITSUM、MA |
| 主な応用領域 | テキスト生成、コード(出力の制御や要約)、画像キャプション生成 |
3.4 Speculative RAG
| 項目 | 内容 |
|---|
| 概要 | 検索結果を「下書き」や「コピー&ペースト」として活用し、生成を省エネ・高速化する方法です。 |
| メリット | 重い生成を減らせるのでコスト削減や応答速度の改善につながります。既存のLLMや検索器をそのまま組み合わせやすいです。 |
| 留意点 | 主にテキストなど逐次データで効果を発揮します。 |
| 代表手法 | REST、GPTCache、COG、Caoらの phrase-level retrieval |
| 主な応用領域 | テキスト生成全般、特にAPI経由のLLM利用でレイテンシを下げたい場面(キャッシュ利用など) |
4. RAGの強化手法(III-B RAG Enhancements)
RAGの性能を高める工夫は、入力・検索器・生成器・結果・パイプライン全体の5つに分類されます。 入力から出力までの各段階で、どんな工夫で性能を高められるかに注目すると理解しやすいです。
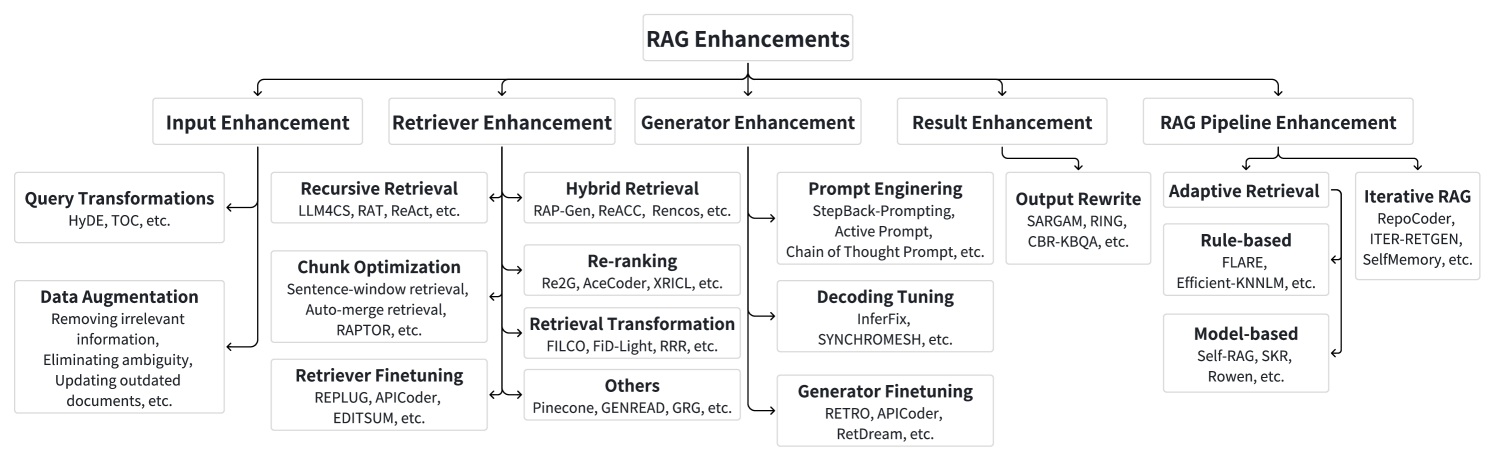 RAG強化手法の分類。
RAG強化手法の分類。
クエリやデータの扱いを改善し、検索と生成の質を底上げします。
| 項目 | 内容 |
|---|
| クエリ変換(Query Transformation) | 短い質問を文章化したり、仮想文書を生成したり、複雑な質問を小さく分割することで検索精度を高めます。few-shotや文脈を追加してクエリを改良する工夫もあります。 例:Query2doc、HyDE、RQ-RAG、補助的な質問生成 |
| データ拡張(Data Augmentation) | 検索前にデータを改善します。不要情報の削除、曖昧さの解消、古いデータの更新、新しいデータの統合などで正確性を高めます。音声やコード、専門領域の語彙を補強する工夫もあります。 例:Make-An-Audio、LESS、ReACC、Telco-RAG |
4.2 検索器の強化(Retriever Enhancement)
検索の質が生成結果を大きく左右するため、アルゴリズムや分割の工夫が重要です。
| 項目 | 内容 |
|---|
| 再帰的検索(Recursive Retrieval) | 思考や推論の流れに沿って複数回検索を行い、必要な情報を段階的に集約します。 例:ReACT、RATP |
| チャンク最適化(Chunk Optimization) | 文書を分割・要約・階層化することで、検索精度と効率を高めます。 例:LlamaIndex、RAPTOR、Prompt-RAG |
| 検索器のファインチューニング(Retriever Fine-tuning) | 特定ドメインに合わせて埋め込みモデルを再学習し、検索精度を向上させます。 例:REPLUG、APICoder、EDITSUM |
| ハイブリッド検索(Hybrid Retrieval) | 疎検索と密検索を組み合わせ、複数ソースを柔軟に切り替えます。 例:BlendedRAG、CRAG、UniMS-RAG |
| リランキング(Re-ranking) | 初期の検索結果を再評価して順序を最適化します。 例:Re2G、AceCoder、XRICL |
| 検索変換(Retrieval Transformation) | 取得したコンテキストを正規化・構造化し、下流タスクに適した形式へ変換します。 例:CORE、OmniTab、StructGPT |
| その他(Others) | 特定タスクや複合的な応用に合わせて検索プロセスを拡張します。 例:CRAG、UniMS-RAG、LlamaIndex |
4.3 生成器の強化(Generator Enhancement)
検索結果を効果的に活かすために生成モデル自体を改良します。
| 項目 | 内容 |
|---|
| プロンプト設計(Prompt Engineering) | 入力を圧縮したり、複雑な記述を分割したり、Chain-of-Thoughtを組み込むことで生成の精度や効率を高めます。 例:LLMLingua、ReMoDiffuse、ActiveRAG |
| デコーディング調整(Decoding Adjustment) | 出力の温度や語彙制約を工夫し、多様性と品質のバランスを取りつつ誤りを防ぎます。 例:InferFix、SYNCHROMESH |
| 生成器のファインチューニング(Generator Fine-tuning) | 検索器との連携や特定ドメインへの適応を目指して再学習します。マルチモーダルやLoRA(Low-Rank Adaptation)による調整も用いられます。 例:RETRO、APICoder、CARE、Animate-A-Story、RetDream |
4.4 出力の強化(Result Enhancement)
生成結果を後処理で修正し、精度や一貫性を高めます。
| 項目 | 内容 |
|---|
| 出力リライト(Output Rewrite) | 生成された内容をリライトして精度を高めます。 例:SARGAM、RING、CBR-KBQA |
4.5 パイプライン全体の強化(RAG Pipeline Enhancement)
検索から生成までの流れ全体を最適化し、柔軟に制御します。
| 項目 | 内容 |
|---|
| 適応的検索(Adaptive Retrieval) | 生成器の確信度や内部表現を見て、検索が必要かどうかを判断します。小型モデルを判定器として組み込む工夫もあります。アプローチの方法には、ルールベースとモデルベースがあります。 ルールベース モデルの内部指標(不確実度など)の固定ルールや閾値で検索の要否を判断。 例:FLARE、Efficient-KNNLM モデルベース 学習して作成された分類器やゲートを使って検索の要否を判断。 例:Self-RAG、AdaptiveRAG、SKR |
| 反復型RAG(Iterative RAG) | 生成途中で再検索を行い、段階的に精度を改善します。 例:RepoCoder、ITER-RETGEN、SelfMemory、RAT |
5. 応用分野(IV Applications)
ここでは、RAGがどのように実際のタスクやドメインに応用されているのかを見ていきます。テキスト・コード・画像など具体的な応用例を押さえ、自分の関心領域に近い事例を探すのがポイントです。
5.1 テキスト向けのRAG(RAG for Text)
1. 質問応答(Question Answering)
| 項目 | 内容 |
|---|
| 概要 | 外部の文書や知識を検索して質問に答えるタスクです。 |
| 主なアプローチ | Query-based RAG が広く使われます。 |
| 代表的な手法 | FiD、REALM、RETRO、SKR、TOG、NPM、CL-ReLKT |
| 特徴・工夫 | 複数スニペットを入力に統合したり、検索要否を判定したり、知識グラフや多言語検索を組み合わせて精度を高めます。法令分野の DISC-LawLLM や複数の文書を辿って回答する MultiHop-RAG も応用例です。 |
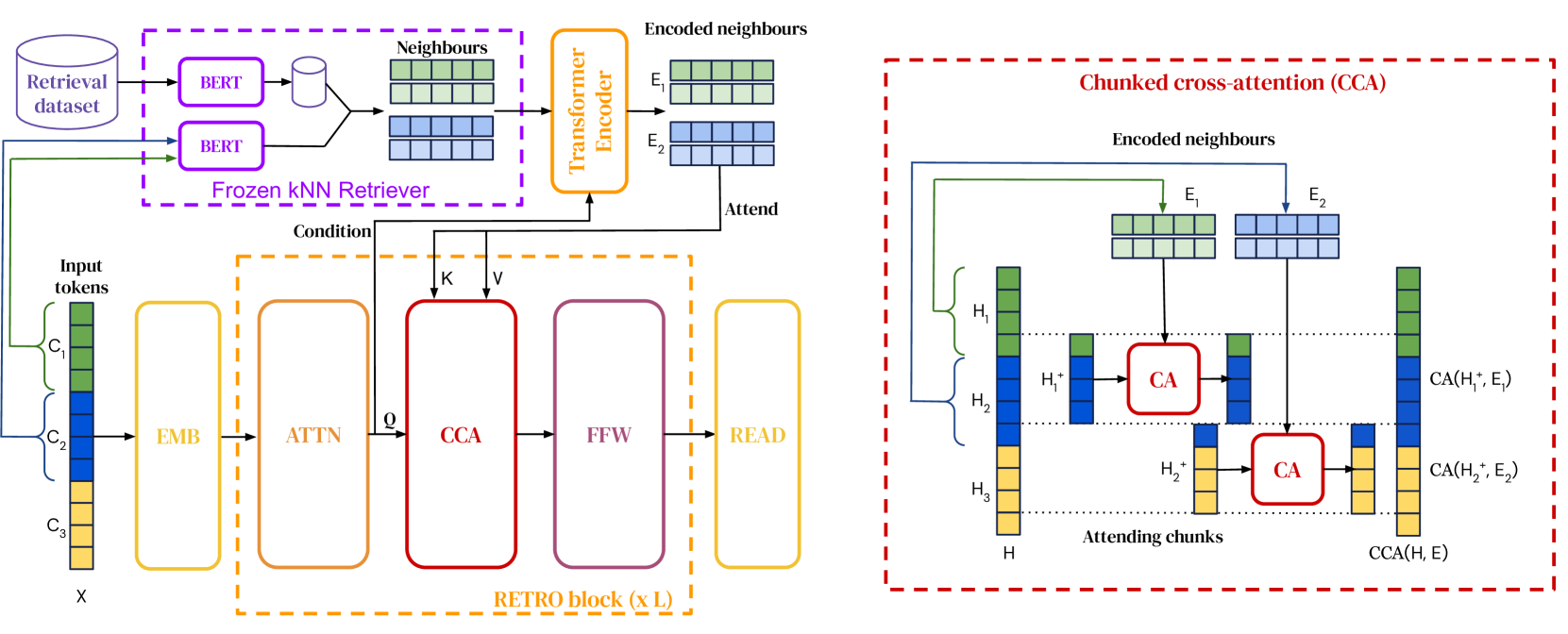 RETRO モデルのアーキテクチャ。
RETRO モデルのアーキテクチャ。
2. 事実検証(Fact Verification)
| 項目 | 内容 |
|---|
| 概要 | テキスト中の主張が正しいかどうかを確認します。 |
| 主なアプローチ | Query-based、Latent Representation 両方が利用されます。 |
| 代表的な手法 | CONCRETE、Atlas、Stochastic RAG |
| 特徴・工夫 | 多言語検索で証拠を収集し、検索を工夫することでモデル拡大より一貫性改善に効果があると示されています。 |
3. 常識推論(Commonsense Reasoning)
| 項目 | 内容 |
|---|
| 概要 | 常識的な知識や人間らしい推論を外部知識で補います。 |
| 主なアプローチ | Latent Representation が利用されます。 |
| 代表的な手法 | KG-BART |
| 特徴・工夫 | 知識グラフの概念関係を組み込んで論理性を高めたり、矛盾のある回答を含むデータでモデルの頑健性を検証します。 |
4. 人間と機械の対話(Human-Machine Conversation)
| 項目 | 内容 |
|---|
| 概要 | 自然な対話を実現するために外部知識を利用します。 |
| 主なアプローチ | Query-based が中心です。 |
| 代表的な手法 | ConceptFlow、BlenderBot3、CEG |
| 特徴・工夫 | 知識グラフで会話の流れを整理したり、Web検索や履歴を組み合わせたり、事後検証で幻覚を抑えます。多言語対応も注目されています。 |
5. ニューラル機械翻訳(Neural Machine Translation)
| 項目 | 内容 |
|---|
| 概要 | ソース言語をターゲット言語に翻訳します。 |
| 主なアプローチ | Logit-based が使われます。 |
| 代表的な手法 | kNN-MT、TRIME |
| 特徴・工夫 | トークンごとに近傍検索を行ったり、検索器と生成器を同時学習して翻訳精度を高めます。単言語+多言語の併用も進められています。 |
| 項目 | 内容 |
|---|
| 概要 | テキストから「何が起きたか」「誰が関与したか」を抽出します。 |
| 主なアプローチ | Query-based RAG が使われます。 |
| 代表的な手法 | R-GQA |
| 特徴・工夫 | 関連QAペアを検索して文脈を補強し、イベント抽出の精度を高めます。 |
7. 要約(Summarization)
| 項目 | 内容 |
|---|
| 概要 | 長文を短く要約して主要な情報をまとめます。 |
| 主なアプローチ | Query-based、Latent Representation の両方が利用されます。 |
| 代表的な手法 | Unlimiformer、RPRR、RIGHT、M-RAG、RAMKG |
| 特徴・工夫 | 入力長の制限に対応したり、段階的に検索を繰り返して長文をまとめたり、非英語の要約にも対応します。 |
5.2 コードのためのRAG(RAG for Code)
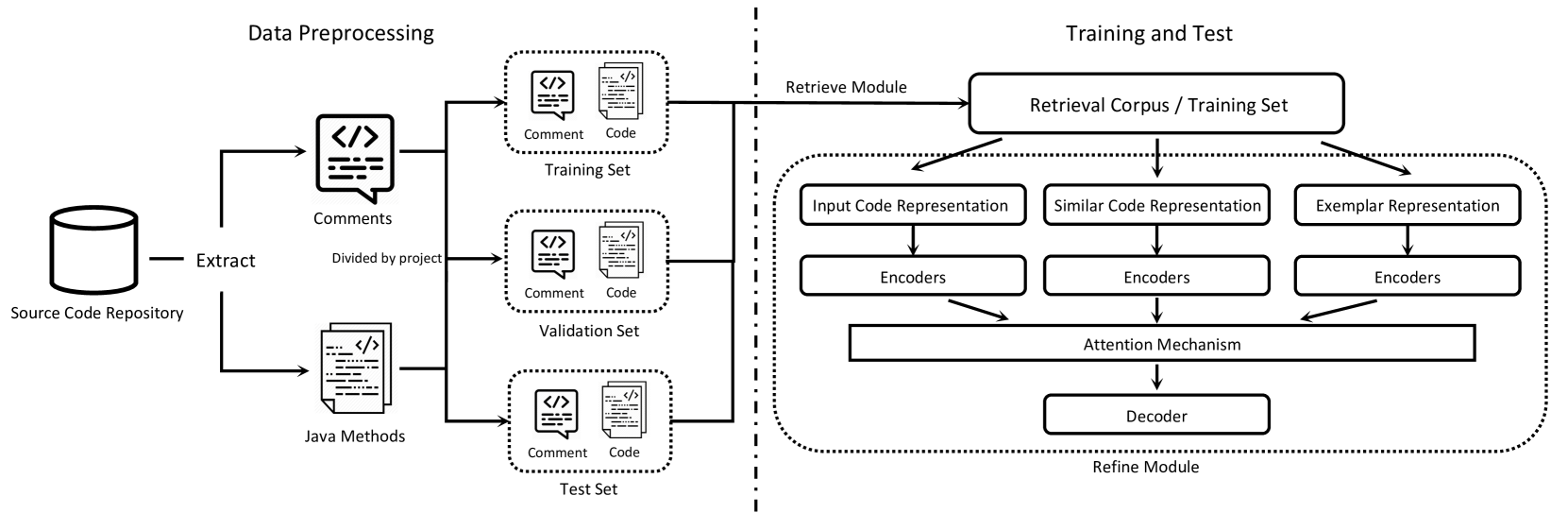 Re2Com モデルのアーキテクチャ。
Re2Com モデルのアーキテクチャ。
1. コード生成(Code Generation)
| 項目 | 内容 |
|---|
| 概要 | 自然言語の説明や要件からコードを生成します。 |
| 主なアプローチ | Query-based が主流、Logit-based や Speculative も活用されます。 |
| 代表的な手法 | SKCODER、CODEAGENT、RECODE、kNN-TRANX、ToolCoder |
| 特徴・工夫 | 類似コードやAPI情報を取り込み、ロジット統合や下書き生成で効率化します。 |
2. コード要約(Code Summarization)
| 項目 | 内容 |
|---|
| 概要 | コードを自然言語で説明する要約を生成します。 |
| 主なアプローチ | Latent Representation、Query-based、Logit-based が活用されます。 |
| 代表的な手法 | RACE、READSUM、REDCODER、ASAP、Rencos、CoRec |
| 特徴・工夫 | 潜在表現や確率分布に検索結果を組み込み、コード要約の精度を高めます。 |
3. コード補完(Code Completion)
| 項目 | 内容 |
|---|
| 概要 | 入力中のコードの続きを予測します。 |
| 主なアプローチ | Query-based が主流、Latent Representation や Logit-based も活用されます。 |
| 代表的な手法 | ReACC、RepoCoder、REPOFUSE、RepoFusion、EDITAS、kNN-LM |
| 特徴・工夫 | 関数やAPIを検索して補完したり、潜在表現やロジット統合で精度を改善します。 |
4. 自動プログラム修正(Automatic Program Repair)
| 項目 | 内容 |
|---|
| 概要 | バグのあるコードを自動で修正します。 |
| 主なアプローチ | Query-based が中心です。 |
| 代表的な手法 | RING、CEDAR、RAP-Gen、InferFix、SARGAM、RTLFixer |
| 特徴・工夫 | エラーメッセージや過去の修正例を検索してプロンプトに利用します。SARGAMは生成結果を別モデルで精緻化し、RTLFixerはエラーと解法を反復的に検索して修正します。 |
5. Text-to-SQL、コード系セマンティックパーシング(Text-to-SQL and Semantic Parsing)
| 項目 | 内容 |
|---|
| 概要 | 自然言語をSQLや形式コードに変換します。 |
| 主なアプローチ | Query-based が主流です。 |
| 代表的な手法 | XRICL、SYNCHROMESH、RESDSQL、MURRE |
| 特徴・工夫 | 類似問い合わせやスキーマ情報を検索してプロンプトに組み込み、制約付きデコーディングや多段階検索で精度を高めます。 |
6. その他
| 項目 | 内容 |
|---|
| 概要 | 主要タスク以外にも多様な応用があります。 |
| 主なアプローチ | Query-based RAGパラダイムを採用し、類似例を組み込んでプロンプトを構築します。 |
| 代表的な手法 | De-fine、E&V、Code4UIE、StackSpotAI、InputBlaster |
| 特徴・工夫 | プログラムを推論の途中に挟んだり、生成したコードを学習資源として活用したり、静的解析や開発支援に組み込むなどの実装指向の拡張が進みます。 |
5.3 知識のためのRAG(RAG for Knowledge)
1. 知識ベース質問応答(Knowledge Base QA)
| 項目 | 内容 |
|---|
| 概要 | 知識ベースを使って質問に答えるタスクです。多くの場合は質問をSPARQL(知識ベースを検索するためのクエリ言語)などの論理式に変換して処理します。 |
| 主なアプローチ | Query-based RAG がよく使われ、疎検索・密検索やグラフ探索と組み合わせます。 |
| 代表的な手法 | Uni-Parser、RNG-KBQA、ECBRF、CBR-KBQA、GMT-KBQA、TIARA、FC-KBQA、StructGPT |
| 特徴・工夫 | 知識ベース内の類似例を使った事例ベース推論や関係分類、曖昧性解消、サブグラフを段階的に取得する工夫で精度を高めます。 |
2. 知識拡張オープンドメインQA(Knowledge-augmented Open-domain QA)
| 項目 | 内容 |
|---|
| 概要 | オープンドメインQAに知識グラフなどの構造化知識を組み合わせて答えの精度を高めるタスクです。 |
| 主なアプローチ | FiD(Fusion-in-Decoder)を中心とした Latent Representation 型が多く使われますが、最近は Query-based も増えています。 |
| 代表的な手法 | UniK-QA、KG-FiD、GRAPE、OREOLM、SKURG、DIVKNOWQA、KnowledGPT、GenTKGQA、KnowledgeNavigator、GNN-RAG |
| 特徴・工夫 | 推論経路やメモリを隠れ状態に統合したり、検索と生成を繰り返して一貫性を高める仕組みが工夫されています。 |
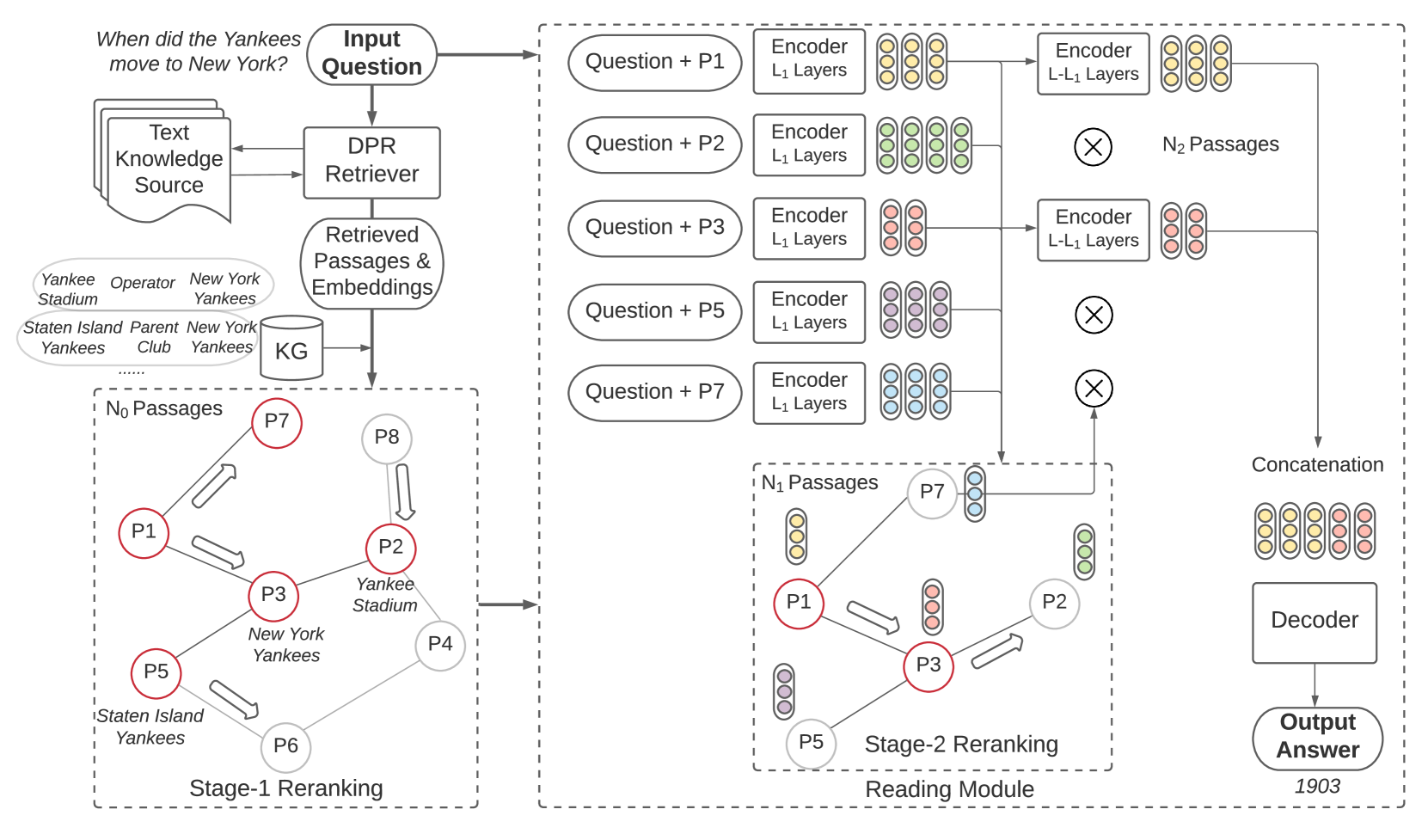 KG-FiD モデルのアーキテクチャ。
KG-FiD モデルのアーキテクチャ。
3. 表を用いた質問応答(Table QA)
| 項目 | 内容 |
|---|
| 概要 | 表データを活用して質問に答えるタスクです。テキストと表を合わせて処理します。 |
| 主なアプローチ | FiD系の統合にリランキングや Query-based を組み合わせます。 |
| 代表的な手法 | Dual Reader-Parser、CORE、Convinse、RINK、TAG-QA、T-RAG、OmniTab、CARP、StructGPT、cTBLS、ERATTA |
| 特徴・工夫 | 検索した表やテキストをリランキングして利用します。表をグラフ化やテキスト化する工夫があり、複数ソースを組み合わせた検索も行います。さらに、SQL生成や表とパッセージを組み合わせる手法も提案されています。 |
4. その他
| 項目 | 内容 |
|---|
| 概要 | QA以外にも、知識を活用する対話や補助タスクに応用されています。 |
| 主なアプローチ | Query-based や Latent Representation を状況に応じて使います。 |
| 代表的な手法 | Prototype-KRG、SURGE、RHO |
| 特徴・工夫 | 対話のプロトタイプや関連サブグラフ、エンティティの埋め込みを統合して、文脈の一貫性や知識利用の効率を高めます。 |
5.4 画像のためのRAG(RAG for Image)
1. 画像生成(Image Generation)
| 項目 | 内容 |
|---|
| 概要 | 珍しい対象でも高品質な画像を生成しやすくし、パラメータ数や計算量を抑えることを目指します。GAN系と拡散モデル系の双方で利用されています。 |
| 主なアプローチ | GAN系ではパッチ選択や特徴量による条件付けを行い、拡散系ではCLIP(画像とテキストを同時に理解するモデル)の埋め込みや近傍画像を条件に使います。取得した画像やテキスト情報を生成過程に組み込む工夫がされています。 |
| 代表的な手法 | RetrieveGAN、IC-GAN、KNN-Diffusion、RDM、Re-imagen、Retrieve&Fuse、RPG |
| 特徴・工夫 | 微分可能な検索器でパッチを選ぶ、インスタンス特徴を使って条件付けする、CLIP近傍を条件にする、取得画像とノイズを結合して自己注意で相互作用させる、といった工夫があります。 |
2. 画像キャプション生成(Image Captioning)
| 項目 | 内容 |
|---|
| 概要 | 画像の内容を自然な文章で説明するタスクです。 |
| 主なアプローチ | 取得したキャプションをメモリやコンテキストとして参照し、生成モデルに組み込みます。クロスアテンションや取得スコアに応じた重み付けが使われます。 |
| 代表的な手法 | MA、RAMP、RA-Transformer、EXTRA、REVEAL、SMALLCAP、CRSR |
| 特徴・工夫 | 取得キャプションをメモリバンクやインコンテキスト例として活用する、スコアに応じて注意を配分する、リモートセンシング画像では誤誘導を避けて顕著な情報を強調する、といった工夫があります。 |
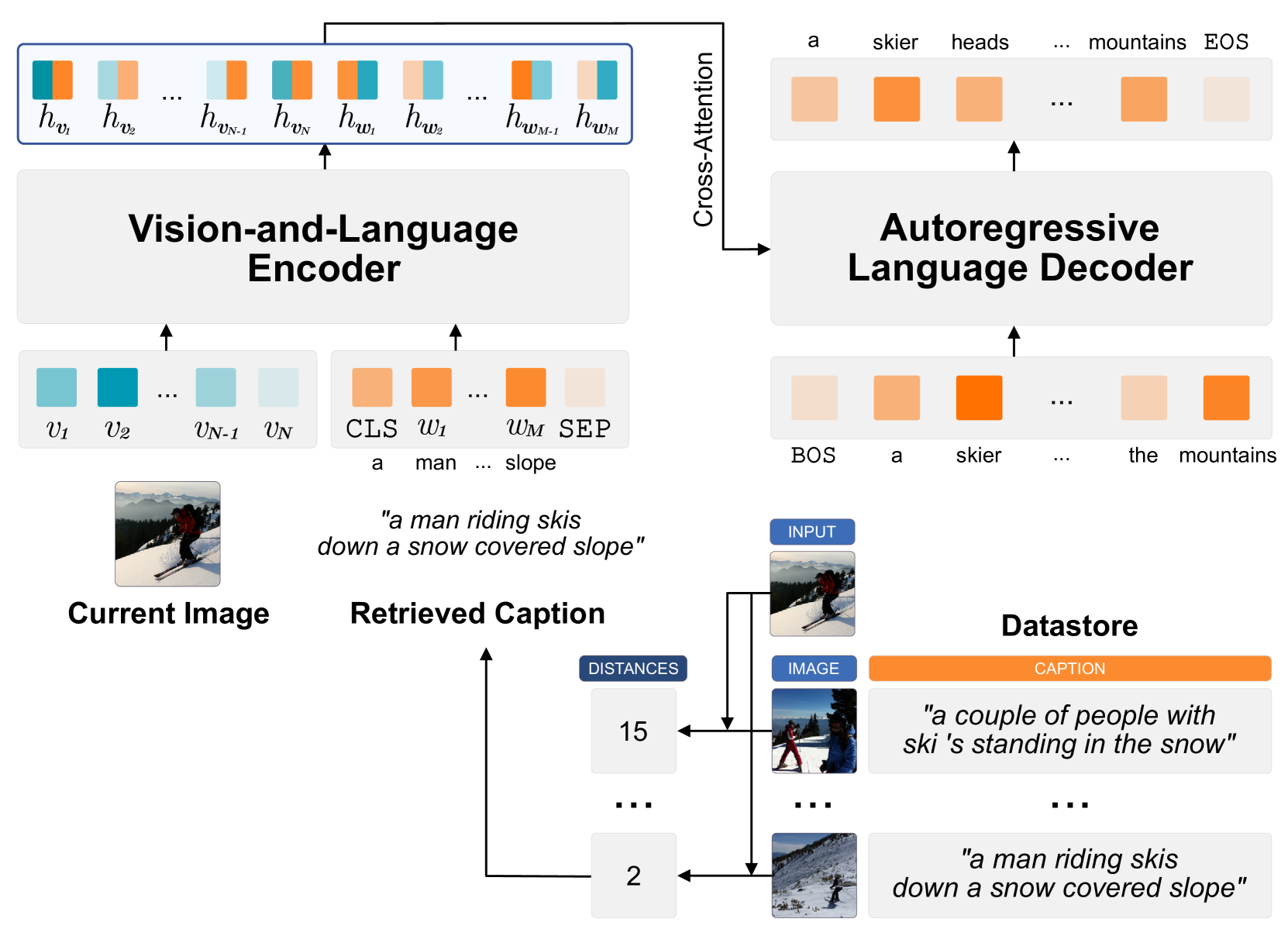 EXTRA モデルのアーキテクチャ。
EXTRA モデルのアーキテクチャ。
3. その他
| 項目 | 内容 |
|---|
| 概要 | VQA(Visual Question Answering)、視覚根拠付き対話、マルチモーダル翻訳などにも応用が広がっています。 |
| 主なアプローチ | 画像をテキストに変換してLLMに渡す、微分可能な検索でエンドツーエンド学習を行う、外部の視覚知識を加える、フレーズ単位で視覚情報を翻訳に取り込む、といった方法があります。 |
| 代表的な手法 | PICa、RA-VQA、KIF、Maria |
| 特徴・工夫 | マルチクエリをアンサンブルする、検索を微分可能にして直接学習する、外部知識を対話に統合する、翻訳で視覚的手掛かりを補う、といった工夫があります。 |
5.5 動画のためのRAG(RAG for Video)
1. 動画キャプション生成(Video Captioning)
SARGAM
| 項目 | 内容 |
|---|
| 概要 | 動画の内容をわかりやすい文章で説明するタスクです。 |
| 主なアプローチ | 関連テキストや外部知識を検索して、フレームや音声と合わせて生成モデルに統合します。 |
| 代表的な手法 | KaVD、R-ConvED、CARE、EgoInstructor |
| 特徴・工夫 | ニュース動画に関連する固有表現やイベントを検索して補強したり、フレーム・音声・テキストを一緒に扱ってより自然なキャプションを作ります。エゴセントリック動画(一人称視点の動画)では外部視点の情報を取り込み、クロスアテンションで文脈を豊かにします。 |
2. 動画QA・対話(Video QA & Dialogue)
| 項目 | 内容 |
|---|
| 概要 | 動画の内容に基づいて質問に答えたり、会話を続けるタスクです。 |
| 主なアプローチ | 外部メモリや類似テキストを検索して長期依存を補い、関連する場面や概念を取得して生成に反映します。 |
| 代表的な手法 | MA-DRNN、R2A、TVQA+、VGNMN |
| 特徴・工夫 | メモリで有用な情報を保持・検索して長い文脈を扱ったり、意味的に近いテキストをCLIPで取得して補強します。関連区間や視覚概念を取り込み、時系列を考慮した自然な回答や対話を実現します。 |
3. その他
| 項目 | 内容 |
|---|
| 概要 | キャプションやQAにとどまらず、動画の将来予測や運転シーンの説明、テキストからの動画生成にも応用されています。 |
| 主なアプローチ | 動画を時間情報付きのプロンプトに変換してLLMに渡したり、専門家デモを検索して根拠を補強したり、物語プロットと拡散生成を組み合わせます。 |
| 代表的な手法 | VidIL、RAG-Driver、Animate-A-Story |
| 特徴・工夫 | 時間軸を意識したプロンプト化で多様な下流タスクに対応したり、運転デモを検索して説明に活かしたり、プロット強化と拡散生成を分けて進める工夫があります。 |
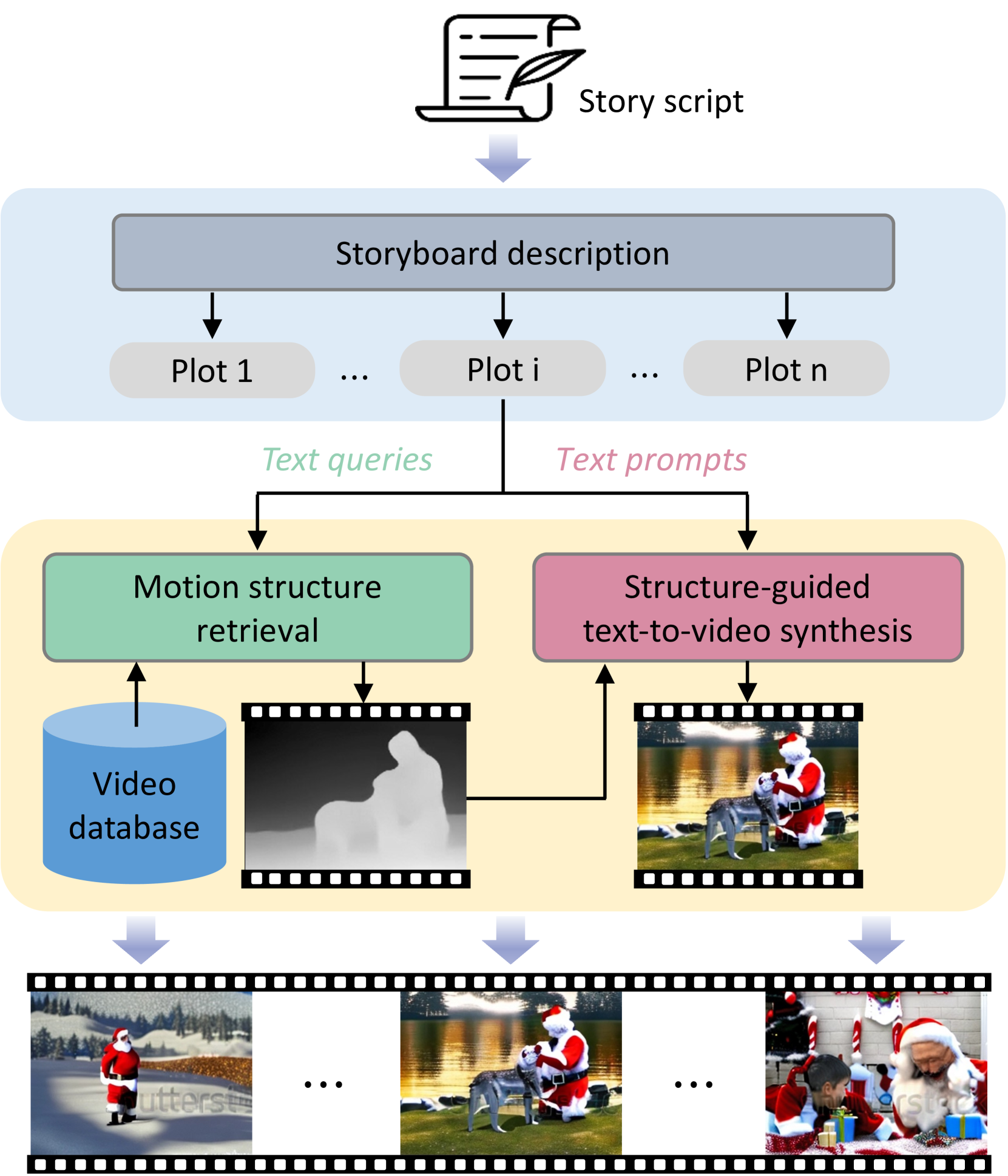 Animate-A-Story モデルのアーキテクチャ。
Animate-A-Story モデルのアーキテクチャ。
5.6 音声のためのRAG(RAG for Audio)
1. 音声生成(Audio Generation)
| 項目 | 内容 |
|---|
| 概要 | テキストや追加の情報を条件に音を生成するタスクです。 |
| 主なアプローチ | 関連する音素材や説明文を検索し、拡散モデルの注意機構に組み込みます。 |
| 代表的な手法 | Make-An-Audio、Re-AudioLDM |
| 特徴・工夫 | 検索で得たキャプションや概念音を条件として使い、生成の精度を高めます。テキストと音声の特徴量をそれぞれのエンコーダで抽出し、注意機構で統合する工夫も見られます。 |
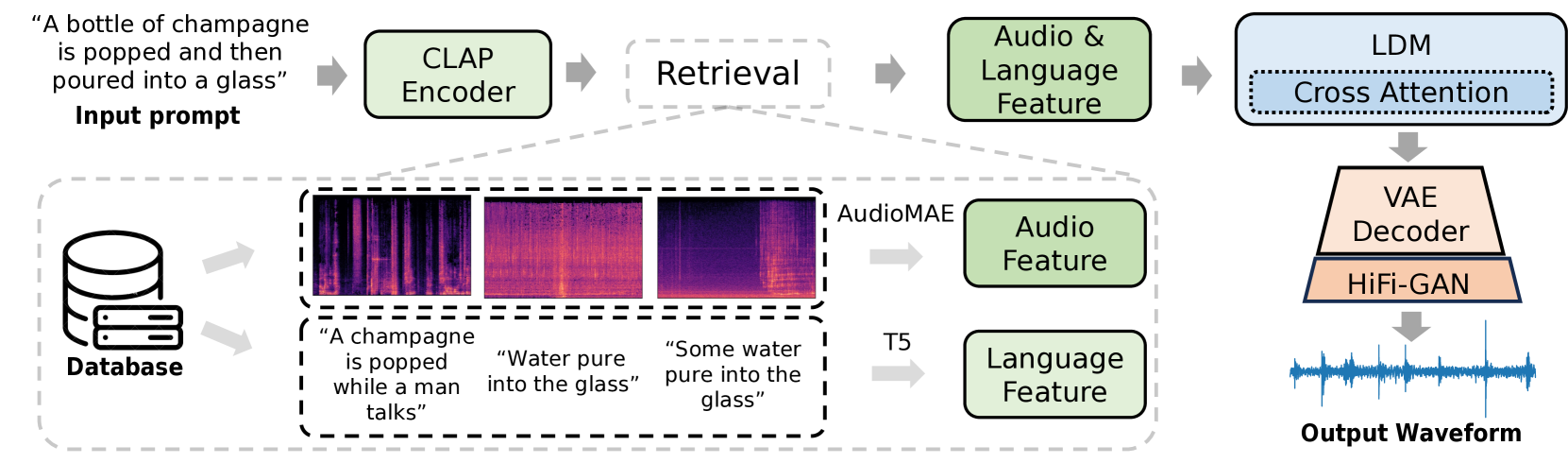 Re-AudioLDM モデルのアーキテクチャ。
Re-AudioLDM モデルのアーキテクチャ。
2. 音声キャプション生成(Audio Captioning)
| 項目 | 内容 |
|---|
| 概要 | 音の内容を自然な文章で説明するタスクです。 |
| 主なアプローチ | 取得した音響特徴や既存キャプションを組み込み、言語モデルで文章を生成します。 |
| 代表的な手法 | RECAP |
| 特徴・工夫 | テキスト用と音声用のエンコーダで別々に特徴を抽出し、統合して使うことで、音に即した表現をより的確に生成します。 |
5.7 3DのためのRAG(RAG for 3D)
1. Text-to-3D
| 項目 | 内容 |
|---|
| 概要 | テキストの指示に沿って3Dコンテンツ(形状やモーション)を生成するタスクです。 |
| 主なアプローチ | Latent Representation 型で取得情報を潜在表現として統合します。Query-based 型では関連3Dアセットを取得して入力段階で組み込みます。 |
| 代表的な手法 | ReMoDiffuse、AMD、RetDream |
| 特徴・工夫 | テキストと取得情報を結びつける注意機構を用いて整合性を高めます。拡散過程同士を融合して効率よく3Dモーションに変換します。CLIPなどで近い3Dアセットを検索し、ユーザー入力と併せて生成を安定させます。 |
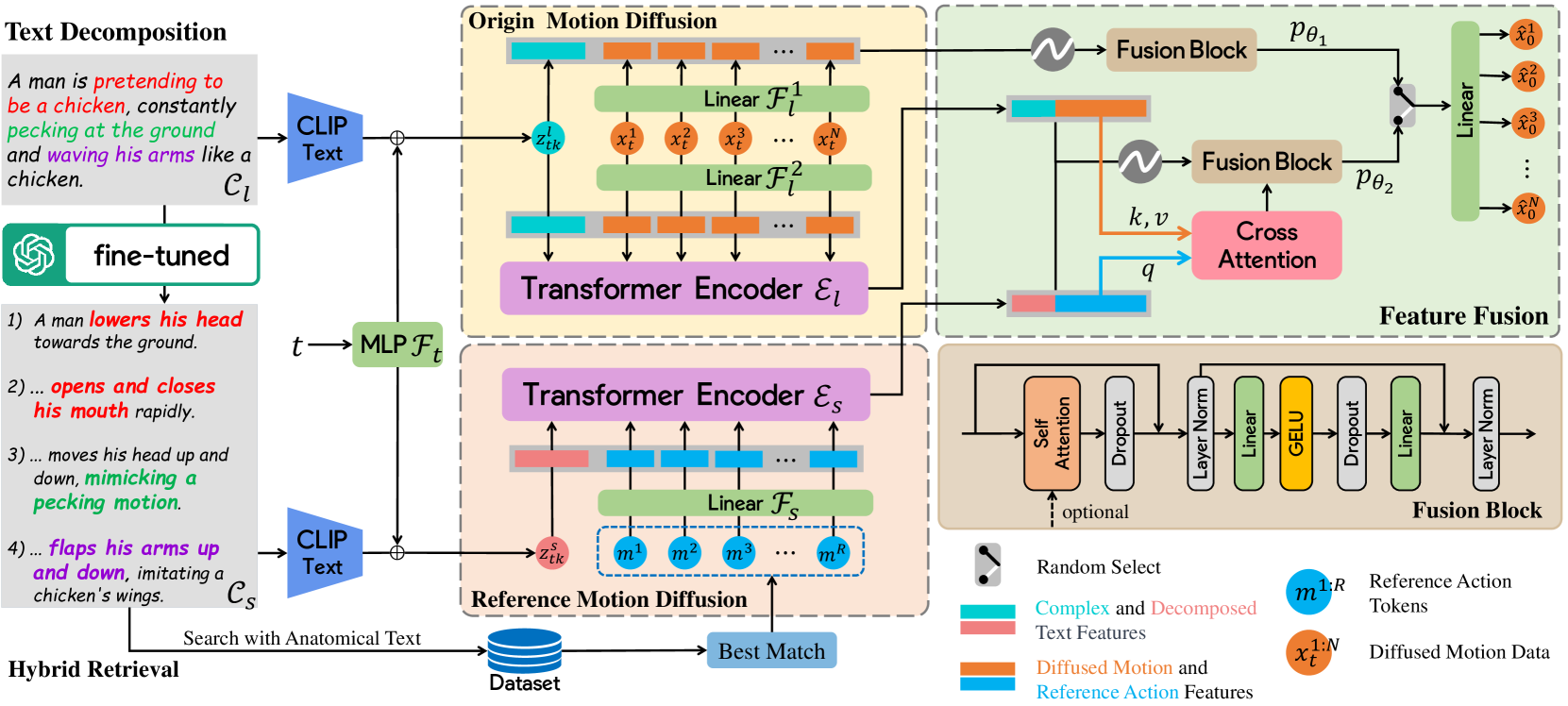 AMD モデルのアーキテクチャ。
AMD モデルのアーキテクチャ。
5.8 科学のためのRAG(RAG for Science)
1. 創薬(Drug Discovery)
| 項目 | 内容 |
|---|
| 概要 | 多様な特性を同時に満たす分子を生成したり、設計基準に合うリガンド合成を導くことを目指します。 |
| 主なアプローチ | Latent Representation 型(RetMol)や Query-based 型(PromptDiff)を使います。 |
| 代表的な手法 | RetMol、PromptDiff |
| 特徴・工夫 | 模範分子やリガンド参照などの関連情報を検索し、事前学習済みの生成モデルに統合して分子生成を制御します。 |
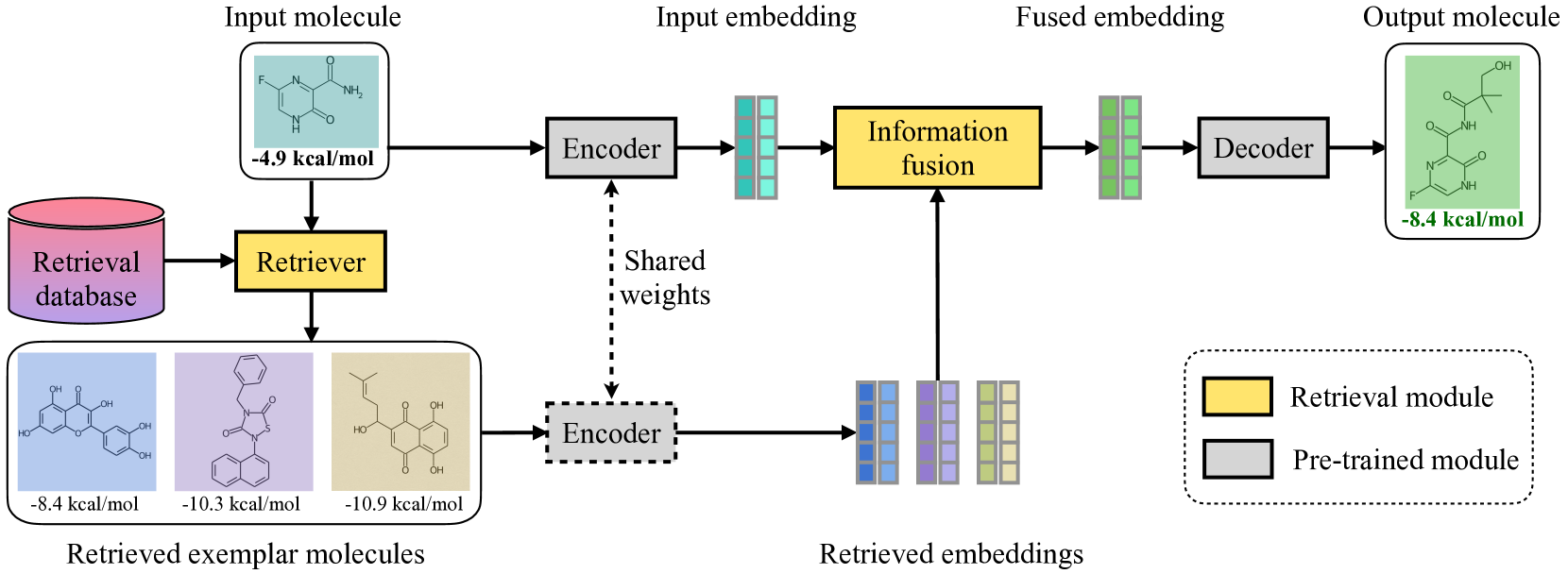 RetMol モデルのアーキテクチャ。
RetMol モデルのアーキテクチャ。
| 項目 | 内容 |
|---|
| 概要 | ドメイン固有のデータベースや資料を取り込み、医療タスクでの判断や説明を支援します。 |
| 主なアプローチ | Query-based(Chat-Orthopedist、QA-RAG)や Latent Representation 型(BIOREADER)を使います。 |
| 代表的な手法 | Chat-Orthopedist、BIOREADER、QA-RAG |
| 特徴・工夫 | 外部の知識ベースや規制ガイドラインを検索してプロンプトに組み込み、LLMの有効性と情報精度を高めます。 |
3. 数学的応用(Math Applications)
| 項目 | 内容 |
|---|
| 概要 | 前提や教科書の知識を取り込み、定理証明や応答生成を支援します。 |
| 主なアプローチ | Query-based 型を使います。 |
| 代表的な手法 | LeanDojo、RAG-for-math-QA |
| 特徴・工夫 | 関連する前提や高品質な教材を検索して統合し、定理証明の自動化・一般化やLLMの回答強化に活用します。 |
6. おわりに
本記事では、RAGのサーベイ論文をもとに、基礎構造から強化手法、応用分野までを整理しました。RAGは「検索 → 増強 → 生成」というシンプルな流れを持ちながら、入力・検索器・生成器・出力・パイプラインの各段階で多彩な工夫が試みられており、テキストやコードにとどまらず、画像・動画・音声・3D・科学分野まで幅広く応用が広がっています。
一方で、論文中(VI-A Limitations)でも指摘されているように、検索品質への依存、長いコンテキストの処理負荷、幻覚や誤情報の混入、計算コストの高さといった課題は残されています。これらをどう克服していくかが今後の重要なテーマです。
RAGはまだ発展の途中にあり、研究と実装の両面で進化を続けています。本記事が、設計や実装を検討する際の整理の助けになり、最新の研究動向に触れる入り口となれば幸いです。
7. 参考文献
https://arxiv.org/html/2402.19473v6
