はじめに
この記事について
この記事では、**Mixture-of-Agents Enhances Large Language Model Capabilities **の論文を解説します。
https://arxiv.org/abs/2406.04692 より具体的には、エージェントを組み合わせることによりLLM(大規模言語モデル)の機能が強化する技術 MoA (Mixture-of-Agents) について解説していきます。
対象者
- MoA についてざっくり知りたい人
- MoA の特徴を知りたい人
これを読むと何が嬉しいのか
- 複数のLLMを組み合わせて文章の質を向上させるMoAの技術を知ることが出来る
MoA (Mixture-of-Agents) とは
MoAとは、複数のLLM(大規模言語モデル)を組み合わせることのより、生成文の品質を向上させる技術を言います。MoAの構造を以下の図に示します。最初のレイヤーで各エージェントがLLMで個別に文章を生成し、次のレイヤーのエージェントが前のレイヤーの生成文を改良していきます。この反復的プロセスにより、より精度が高い文章の生成が可能になります。
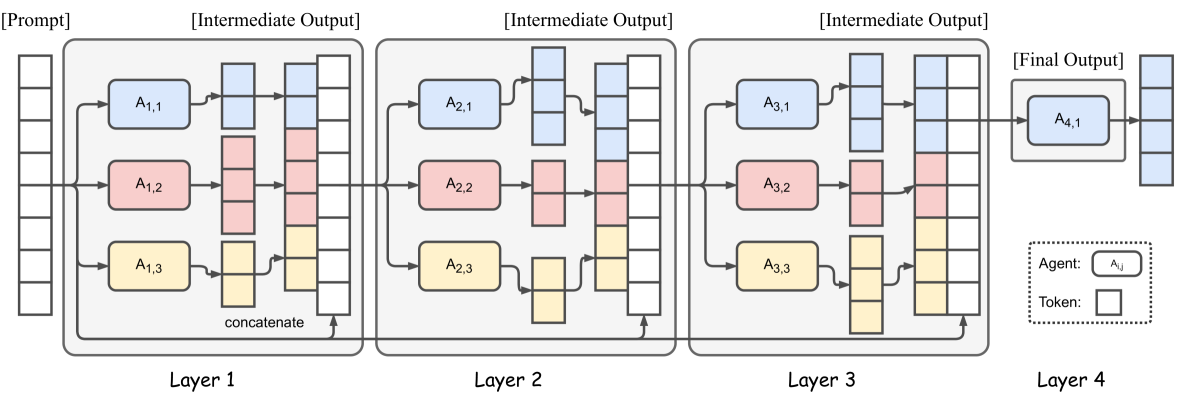 Mixture-of-Agents構造の図。この例では4つのMoAレイヤーと各レイヤーに3つのエージェントを示しています。ここでのエージェントは同じLLMを共有できます。
LLM間の効果的な協調と全体的な生成文の品質を向上させるためには、各レイヤーでのLLMの選定が必要になります。このLLM選定プロセスには次の2つの基準があります。
Mixture-of-Agents構造の図。この例では4つのMoAレイヤーと各レイヤーに3つのエージェントを示しています。ここでのエージェントは同じLLMを共有できます。
LLM間の効果的な協調と全体的な生成文の品質を向上させるためには、各レイヤーでのLLMの選定が必要になります。このLLM選定プロセスには次の2つの基準があります。
- パフォーマンス指標
- LLMの平均勝率などの実証されたパフォーマンス指標に基づいて選択することで、高品質な出力につながります。
- 多様性
- LLM出力に多様性を持たせることが重要です。異なるLLMから生成された文章は、同一LLMで文章された応答よりも精度が高くなります
MoAは、AlpacaEval2.0、MT-Bench、FLASKという言語問題のタスクで、GPT-4 Omniを超える性能を達成しています。
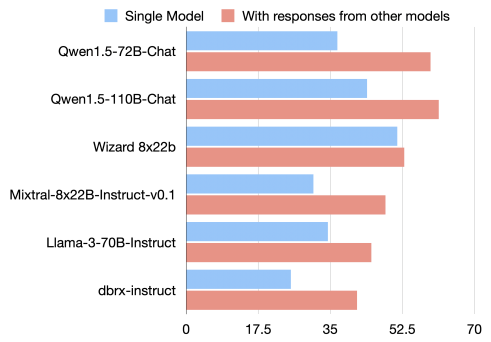 AlpacaEval 2.0 ベンチマーク
他のモデルからのレスポンスを提供すると、性能が向上します
AlpacaEval 2.0 ベンチマーク
他のモデルからのレスポンスを提供すると、性能が向上します
MoA の仕組みについて
ここからは、複数のLLMでパフォーマンスを向上させるためのMoAの仕組みを紹介していきます。 まず、LLMは協調性を備えているため、ほかのモデルの出力に基づいて応答を改善できることを示します。これに続いて、MoA 手法を紹介し、その設計上の意味合いについて説明します。
LLM の協調性
LLMは他のモデルからの出力を参照することで、より質の高い応答を生成する能力を持っています。協調のプロセスでは、LLM を プロポーザーとアグリゲータの2 つの異なる役割に分類できます。
プロポーザー (Proposer) 他のLLMで使用されるのに有用な文章を生成する。優れたプロポーザーは、必ずしも単体で高品質な文章を生成するわけではありませんが、より多くのコンテキストと多様な視点を提供し、最終的にはアグリゲータによって参照されたときに、より優れた最終応答に貢献する必要があります。
アグリゲータ (Aggregator) 他のLLMからの応答を統合します。優れたアグリゲータは、自身の品質よりも低い入力を統合する場合でも、出力の品質を維持または向上させる必要があります。
プロポーザーは有用な参照応答を生成し、アグリゲーターはこれらの応答を高品質な出力に統合します。多くのLLMが両方の役割を担う能力を持つ一方で、特定のモデルは特定の役割で優れた性能を示しています。例えば、GPT-4oやLLaMA-3は両方の役割で効果的ですが、WizardLMはプロポーザーとして優れていますが、アグリゲーターとしては不適切です。 より高品質な応答を生成するために、複数のアグリゲーターを導入し、応答を反復的に合成して改良します。このアイデアは MoA の設計の基礎となっています。
MoA の構造
MoAの構造は、複数のレイヤーと各レイヤー内の複数のLLMで構成されています。また、LLMは、同じレイヤー内または異なるレイヤー間で再利用可能です。
シングルプロポーザー(single-proposer) シングルプロポーザーとは、レイヤー内で同一LLM を使い複数の異なる出力を生成するための設定です。 具体的には「temperture」パラメータによるサンプリング確率を利用して複数の異なる出力を生成します。
MoE (Mixture-of-Experts) との類似性
MoE は、複数の異なるスキルセットを持ったエキスパートネットワークが、複雑な問題を解決する機械学習手法です。MoE は、ゲーティングネットワークとエキスパートネットワークで構成され、各エキスパートネットワークがタスクに集中できるようにしています。
MoA フレームワークは、このMoEの概念を拡張したものです。MoA はLLMのプロンプトインターフェースを利用し、内部アクティベーションやウェイトの変更を必要とせず、異なるレイヤーの複数のLLMを活用します。これにより、柔軟性とスケーラビリティを提供し、最新のLLMにも適用可能です。 MoA は、ゲーティングネットワークとエキスパートネットワークの役割をLLMが統合して担い、入力を効率的に正規化します。プロンプト機能に依存するため、ファインチューニングに関連する計算オーバーヘッドを排除でき、幅広いモデルに柔軟に対応できます。
MoA がうまく機能する理由
MoA の内部メカニズムを理解するための実験結果を示します。主なインサイトは以下の通りです。
- LLMランカーを上回る性能
- MoA は、プロポーザーの回答を単純に選択するLLMランカーを大幅に上回っています。これは プロポーザーによって提案されたすべてのレイヤーに対して高度な集計を行っていることを示唆します。
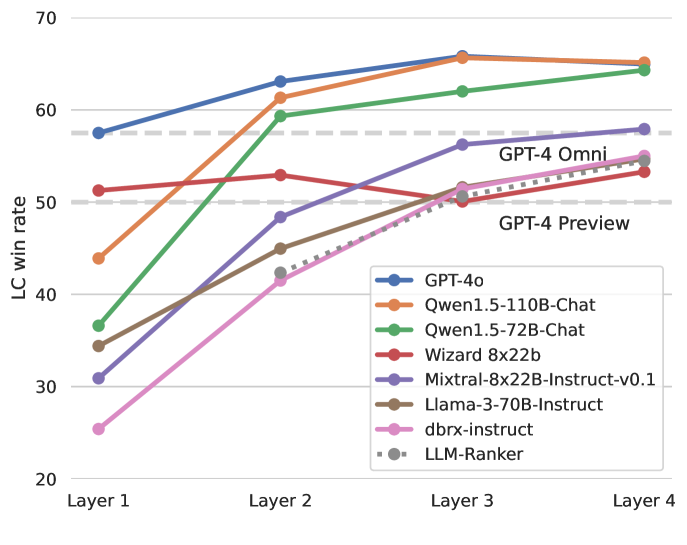 異なるアグリゲーターを使用した MoA セットアップのLC勝率を示しており、MoA は一貫して高い性能を示しています。
異なるアグリゲーターを使用した MoA セットアップのLC勝率を示しており、MoA は一貫して高い性能を示しています。
- 最適な回答の組み込み
- MoA のアグリゲーターが生成する回答は、プロポーザーの回答に基づいて高いBLEUスコア(n-gramのオーバーラップを反映)を持ち、提案された回答の中から最適なものを組み込む傾向があります。スコアにはまさにその相関が見られます。
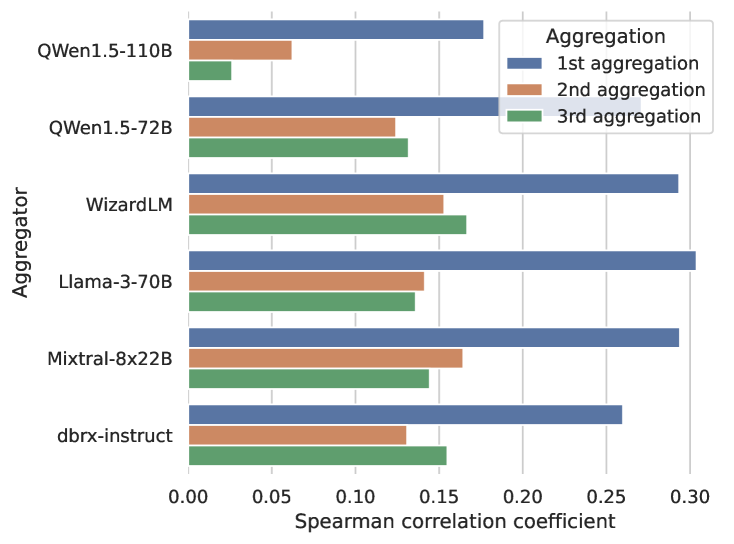 BLEUスコアと提案された出力の勝率との正のスピアマン相関が確認できます。
BLEUスコアと提案された出力の勝率との正のスピアマン相関が確認できます。
モデルの多様性とプロポーザーの数の影響
プロポーザーの数が最終的な出力品質にどのように影響するかを分析した結果、プロポーザーの数が増加するにつれ品質は向上することがわかりました。さらに、プロポーザーとして多様なLLM(マルチプルプロポーザー)を使用すると、より良い結果が得られることが確認されました。
AlpacaEval 2.0におけるプロポーザーの数の影響。
| プロポーザーの数 | マルチプルプロポーザー | シングルプロポーザー |
|---|---|---|
| 6 | 61.3% | 56.7% |
| 3 | 58.0% | 56.1% |
| 2 | 58.8% | 54.5% |
| 1 | 47.8% | 47.8% |
MoA レイヤー内のエージェントの数。アグリゲータとして Qwen1.5-110B-Chat を使用し、2 つの MoA レイヤーを使用。
MoA エコシステムにおけるモデルの専門化
特定の役割でどのモデルが優れているかを判断するための実験も行いました。Qwen、LLaMA-3が汎用性の高いモデルとしてアグリゲーターとプロポーザーの役割に効果的であることを示しています。一方、WizaraLMはプロポーザーとして優れていますが、アグリゲーターには向かないです。
異なるモデルがアグリゲーターとプロポーザーになった場合の影響。
| モデル | アグリゲーターとして | プロポーザーとして |
|---|---|---|
| Qwen1.5-110B-Chat | 61.3% | 56.7% |
| Qwen1.5-72B-Chat | 59.3% | 53.3% |
| LLaMA-3-70b-Instruct | 45.0% | 60.6% |
| WizardLM 8x22B | 52.9% | 63.8% |
| Mixtral-8x22B-Instruct | 48.4% | 54.8% |
| dbrx-instruct | 41.5% | 55.1% |
異なるアグリゲータを評価する場合、6つのモデルすべてが提案者となり、プロポーザーを評価する場合、Qwen1.5-110B-Chatがアグリゲータとなる。この表では2つのMoAレイヤーを使用している。 GPT-4oは、評価のために使用するためプロポーザーとして使わない
コストについて(トークン使用量、LC勝率の関係)
予算とトークンの使用量がLC勝率にどのように影響するかを分析しました。
費用対効果
下記の図は、AplacaEval 2.0ベンチマークの各インスタンスでのLC勝率と平均推論コストをプロットしています。このグラフは、費用対効果の最適なバランスを取るモデルを示すパレートフロント(複数のパレート解で構成される曲面)を描いており、特定のモデルが費用対効果に優れていることを示しています。具体的には、品質を重視するならばMoAが最適で、品質とコストのバランスを重視するならばMoA-Liteが推奨されます。特に、GPT-4 Turboよりもコスト効率が2倍以上高いです。
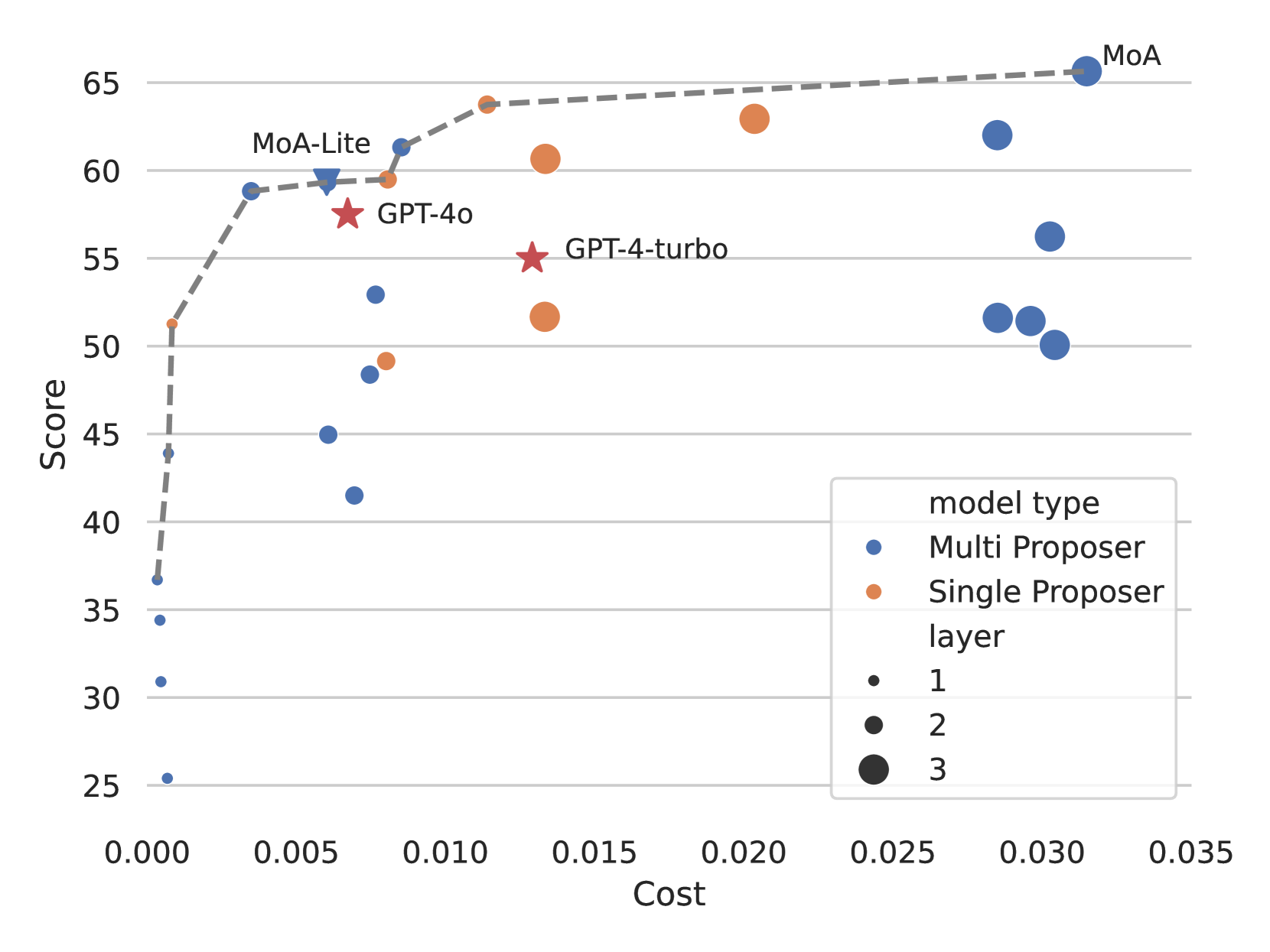
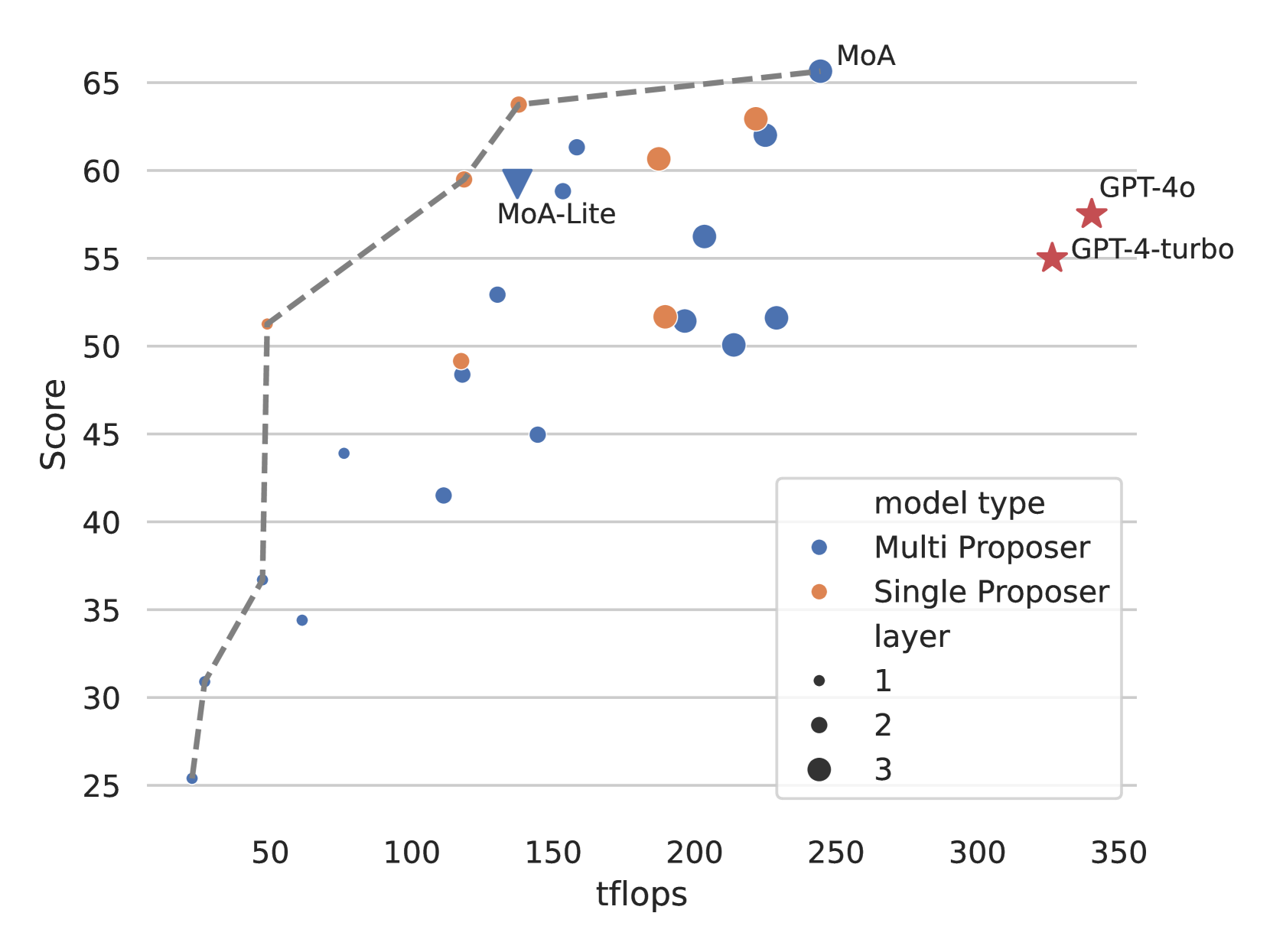
Tflops(コンピュータ処理速度をあらわす単位)の消費
下の図は、LC勝率とtflops数(レイテンシーの代用)との関係を示しています。この分析は、各モデルがパフォーマンスを維持または改善しながら予算を管理する方法を理解するのに重要です。計算リソースを効果的に活用するモデルもパレートフロントに位置しています。
まとめ
MoA は、LLM の協調性を最大限に活用することで、生成品質を向上させる新しいフレームワークです。その高性能、多様性、および費用対効果は、様々な分野における応用を期待させるものです。
