はじめに
LangGraphは、大規模言語モデル(LLM)を活用し、複数のエージェントが連携するアプリケーションを構築するためのツールを提供します。LangChainとは異なり、LangGraphはループを含むフローの実装や、エージェントの行動を細かく制御する機能を備えています。また、ワークフローに人間が介入することも可能で、エージェントの動作を柔軟に調整できます。 本記事では、LangGraphの基本的な機能から、その具体的な構成要素、インストール方法まで解説します。LangGraphを利用することで、より効率的で高度なエージェントベースのアプリケーション開発が可能となります。この記事を通じて、LangGraphの基本を理解し、実際の開発に役立てていただければ幸いです。
この記事の対象者
- LangGraphとはなにか知りたい方
- LangGraphの概念がわからない方
- LangGraphの使い方を知りたい方
LangGraphとは
LangGraphは、LLMを使って複数のアクターが連携するアプリケーションを構築するためのライブラリです。エージェントやマルチエージェントのワークフローを作成するために使われます。他のLLMフレームワークと比較して、LangGraphは以下の5つのメリットがあります。
メリット
- 従来のDAG(有向非巡回グラフ)ベースのソリューションとは異なり、LangGraphはループを含むフローを容易に実装可能
- アプリケーションのフローと状態を細かく制御可能
- グラフの各ステップ後に自動的に状態を保存し、グラフの実行を任意のポイントで一時停止および再開が可能
- ワークフローに人間が介入し、エージェントが計画した次のアクションを承認または中断可能
- LangChainおよびLangSmithとシームレスに統合可能(LangChainおよびLangSmithが必須ではない)
LangChainとの違い
LangGraphとLangChainはどちらもLLMを用いたアプリケーション構築に使用されるフレームワークですが、そのアーキテクチャと機能に大きな違いがあります。LangChainはシンプルなワークフローに適しているのに対し、LangGraphは複雑で動的なエージェントアーキテクチャに強みを発揮します。
DAGベースのLangChain
LangChainは、DAG(Directed Acyclic Graph:有向非巡回グラフ)ベースのフレームワークです。DAGの特徴は、各ノード(タスク)が一方向に進み、ループが存在しない点です。単純なタスクに適しているといえます。
サイクルを含むLangGraph
一方で、LangGraphはサイクル(ループ)を含むフローをサポートしています。これにより、エージェントが繰り返し行動を取ることが可能になり、より複雑なエージェントアーキテクチャを実現できます。例えば、人間のフィードバックを受け取って行動を修正するといった高度なエージェント機能を簡単に実装できます。
コーディング不要で高度なエージェントを構築したい方へ LangGraphのような複雑なマルチエージェントや人間の承認(Human-in-the-loop)を含むワークフローを、ノーコード(Dify)で手軽に実現してみませんか?** 「自社に合わせたエージェントをスピーディに開発したい」「プログラミングなしで運用できるAI基盤が欲しい」**という企業様は、お気軽にご相談ください。 プロが最適な設計と実装をサポートします!
LangGraphの構成
LangGraphの中心的な役割は、エージェントワークフローをグラフとしてモデル化することです。エージェントの動作を定義するための主要なコンポーネントは以下の通りです。
- Graph
- State
- Node
- Edge それぞれについて具体的に説明していきます。
Graphs
LangGraphの基本的な機能は、エージェントの作業の流れをグラフとして表現することです。例えば、以下のようなグラフ構造を構築することができます。
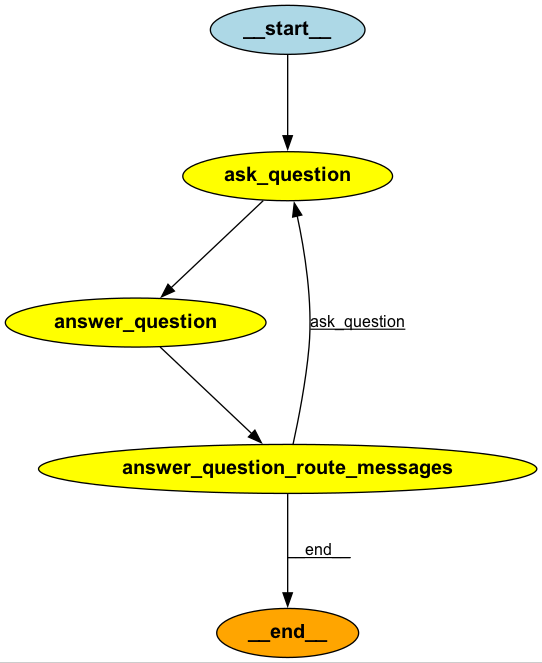 https://github.com/langchain-ai/langgraph/blob/main/examples/storm/storm.ipynb
グラフ構造には、以下の3つの主要なコンポーネントが使用されます。
https://github.com/langchain-ai/langgraph/blob/main/examples/storm/storm.ipynb
グラフ構造には、以下の3つの主要なコンポーネントが使用されます。
-
State
:::message
アプリケーションの現在の状態を示すデータ構造です。任意のPython型を使えますが、通常はTypedDictやPydanticのBaseModelが用いられます。ステートは、エージェントが作業を進めるための情報を保持します。
:::
-
Nodes
:::message
エージェントが行う具体的な作業を示すPython関数です。ノードは現在のステートを入力として受け取り、特定の処理を行った後に更新されたステートを返します。エージェントの各タスクやアクションはノードによって表現されます。
:::
-
Edges
:::message
現在のステートに基づいて次に実行するノードを決定するPython関数です。エッジはワークフローの流れを制御し、どのノードが次に実行されるかを指示します。
:::
Graphの種類
- StateGraph StateGraphクラスは、主に使用されるグラフクラスで、ユーザー定義のステートオブジェクトによってパラメータ化されます。StateGraphは、複雑なデータ構造を持つアプリケーションに適しています。
- MessageGraph MessageGraphクラスは、特別なタイプのグラフです。MessageGraphのステートはメッセージのリストのみで、主にチャットボットで使用されます。
グラフのコンパイル
グラフを構築する際には、まずステートを定義し、次にノードとエッジを追加し、それからコンパイルします。グラフのコンパイルは、グラフの整合性と一貫性を保証するための基本的なチェックを行うステップです。また、チェックポインタやブレークポイントを指定することもできます。コンパイルは、単に.compileメソッドを呼び出すだけで行います。
graph = graph_builder.compile(...)
State
グラフを定義する最初のステップは、Stateを定義することです。Stateはグラフのデータ構造と、データをどのように更新するかを指定するリデューサ関数で構成されています。Stateのデータ構造は、グラフ内のすべてのノードやエッジにとっての入力形式になります。これには、TypedDictやPydanticモデルが使えます。
スキーマ(データの構造)
グラフのデータ構造を指定する方法として、TypedDictを使うのが一般的です。また、PydanticのBaseModelを使ってデフォルト値や追加のデータ検証を行うこともできます。 以下はTypedDictを使ったStateの定義例です。
from typing import TypedDict
class State(TypedDict):
foo: int
bar: list[str]
リデューサ(データの更新方法)
リデューサは、ノードからのデータ更新がStateにどのように適用されるかを決める関数です。Stateの各データ項目(キー)には、それぞれリデューサ関数があります。リデューサ関数が指定されていない場合、デフォルトではその項目を上書きする形で更新が行われます。 以下にリデューサの動作例を示します。 例1:デフォルトのリデューサ
from typing import TypedDict
class State(TypedDict):
foo: int
bar: list[str]
この例では、リデューサ関数は指定されていません。初期Stateが{"foo": 1, "bar": ["hi"]}で、最初のノードが{"foo": 2}を返した場合、更新後のStateは{"foo": 2, "bar": ["hi"]}になります。次に別のノードが{"bar": ["bye"]}を返すと、Stateは{"foo": 2, "bar": ["bye"]}になります。
例2:カスタムリデューサを使った更新
from typing import TypedDict, Annotated
from operator import add
class State(TypedDict):
foo: int
bar: Annotated[list[str], add]
この例では、barという項目に対してoperator.addというリデューサ関数を指定しています。初期Stateが{"foo": 1, "bar": ["hi"]}で、最初のノードが{"foo": 2}を返すと、更新後のStateは{"foo": 2, "bar": ["hi"]}になります。次に別のノードが{"bar": ["bye"]}を返すと、Stateは{"foo": 2, "bar": ["hi", "bye"]}になります。ここで、bar項目はリストの結合によって更新されます。
MessageState
MessageStateは、LangGraphで特別なStateの一つで、メッセージのリストを管理するために使われます。具体的には、以下のように定義されます。
from langchain_core.messages import AnyMessage
from langgraph.graph.message import add_messages
from typing import Annotated, TypedDict
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
この定義では、メッセージのリストを扱うためのTypedDictを作成しています。このクラスは、メッセージの追加や形式の変換、メッセージIDに基づく更新など、便利な機能を提供します。 メッセージ以外のデータも管理したい場合は、このStateを拡張し、以下のように追加のフィールドを持つことができます。
from langgraph.graph import MessagesState
class State(MessagesState):
documents: list[str]
Nodes
LangGraphにおいて、Nodesはエージェントの特定の作業を実行するPython関数(同期または非同期)です。以下の図の赤枠で囲まれた部分がノードを表します。
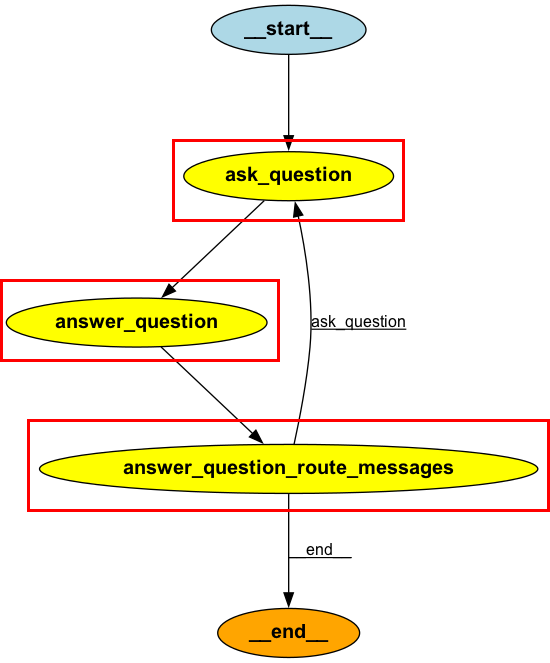 Nodesの最初の引数はStateで、オプションの2番目の引数には設定パラメータを含む辞書型変数が渡されます。
具体的にはノードは、以下のようにしてグラフに追加されます。
Nodesの最初の引数はStateで、オプションの2番目の引数には設定パラメータを含む辞書型変数が渡されます。
具体的にはノードは、以下のようにしてグラフに追加されます。
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph
builder = StateGraph(dict)
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def my_other_node(state: dict):
return state
builder.add_node("my_node", my_node)
builder.add_node("other_node", my_other_node)
ノードをグラフに追加する際に名前を指定しない場合、関数名がデフォルト名として使用されます。
builder.add_node(my_node)
# このノードは"my_node"として追加される
STARTノード
STARTノードは、ユーザー入力をグラフに送信する特別なノードで、どのノードが最初に実行されるかを指定します。
from langgraph.graph import START
graph.add_edge(START, "node_a")
ENDノード
ENDノードは、処理の終わりを示す特別なノードです。このノードは、これ以上続きがないエッジを示します。
from langgraph.graph import END
graph.add_edge("node_a", END)
ノードの追加とエッジの作成
ノードをグラフに追加するにはadd_nodeメソッドを使用します。これにより、関数がノードとして登録され、エッジを使ってノード間の関係が定義されます。
builder.add_node("my_node", my_node)
builder.add_node("other_node", my_other_node)
graph.add_edge("my_node", "other_node")
このように、LangGraphではノードとエッジを組み合わせて、複雑なエージェントのワークフローを構築できます。各ノードは特定のタスクを実行し、エッジが次に実行するノードを決定します。
Edges
Edgesは、エージェントの動作を制御し、異なるノード間の通信を定義する重要な要素です。エッジは以下の図の矢印にあたります。
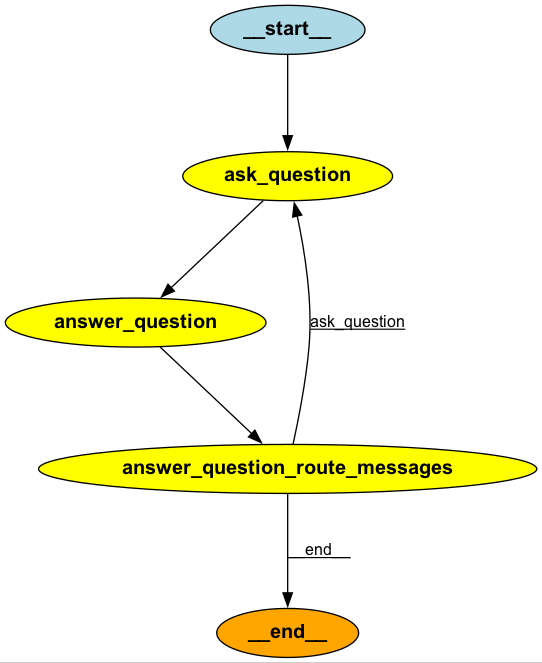 Edgesの種類は以下の通りです。
Edgesの種類は以下の通りです。
- 通常のエッジ:一つのノードから次のノードへ直接移動します。
- 条件付きエッジ:次にどのノードに移動するかを決定するための関数を使用します。
- エントリーポイント:ユーザー入力が到着したときに最初に呼び出されるノードです。
- 条件付きエントリーポイント:ユーザー入力が到着したときに最初にどのノードを呼び出すかを決定するための関数を使用します。 ノードは複数の出力エッジを持つことができ
通常のエッジ
あるノードから別のノードへ常に移動したい場合は、add_edgeメソッドを使います。
graph.add_edge("node_a", "node_b")
条件付きエッジ
条件に基づいて次に進むノードを決定したい場合は、add_conditional_edgesメソッドを使います。このメソッドはノードの名前と、そのノードが実行された後に呼び出される「ルーティング関数」を受け取ります。
graph.add_edge("node_a", routing_function)
routing_functionは、現在の状態を受け取り、次に実行するノードの名前を返します。ルーティング関数の出力を次のノードの名前にマッピングする辞書を提供することもできます。
graph.add_edge("node_a", routing_function, {True: "node_b", False: "node_c"})
エントリーポイント
エントリーポイントは、グラフが開始されるときに最初に呼び出されるノードです。set_entry_pointを使って指定します。
graph.set_entry_point("node_a")
これは、STARTノードとこのノードの間にエッジを追加するのと同じです。複数のノードを最初に呼び出したい場合には、STARTを直接使用します。
from langgraph.graph import START
graph.add_edge(START, "node_a")
条件付きエントリーポイント
条件付きエントリーポイントは、最初にどのノードを呼び出すかを決定するための関数を指定したい場合に使用します。set_conditional_entry_pointを使って指定します。
graph.set_conditional_entry_point(routing_function)
ルーティング関数の出力を次のノードの名前にマッピングする辞書を提供することもできます。
graph.set_conditional_entry_point(routing_function, {True: "node_b", False: "node_c"})
エッジの活用
エッジを活用することで、ノード間のロジックの流れを柔軟に制御できます。これにより、複雑なワークフローを効率的に管理し、エージェントの動作を細かく制御することが可能になります。LangGraphでは、エッジを効果的に利用することで、エージェントのワークフローをスムーズに運営することができます。
LangGraphのインストール方法
以下の手順に従ってインストールできます。
-
Pythonのインストール:LangGraphはPythonで動作するため、まずPythonをインストールする必要があります。
-
LangGraphのインストール:以下のコマンドを実行してLangGraphをインストールします。
pip install -U langgraph -
サンプルプロジェクトの実行:インストールが完了したら、公式のGitHubリポジトリからサンプルプロジェクトをクローンして実行できます。
examplesディレクトリ配下に多くのサンプルがあるので、試すことが可能です。git clone git@github.com:langchain-ai/langgraph.git cd examples
おわりに
LangGraphは、エージェントベースのアプリケーションを構築するための、便利なツールです。直感的なグラフ構造と豊富な機能により、複雑なワークフローの実装が可能となり、エージェントの動作を細かく制御することができます。他のLLMフレームワークと比較しても、ループを含むフローや状態管理、フローに人間が介入可能であるなど、多くの優れた特徴を持っています。これからのエージェントベースのアプリケーション開発において、LangGraphは欠かせないツールとなると思います。ぜひ、LangGraphを試してみてください。
高度なエージェント開発、もっと手軽に実現しませんか? 本記事ではLangGraphの仕組みを解説しましたが、**「コードを書いて運用するのはハードルが高い」「もっとスピーディに自社用のAIエージェントを構築したい」**という企業様には、ノーコード開発ツール「Dify」の活用がおすすめです。 弊社では、プロがDifyを使って複雑なワークフローやエージェントを設計・構築するDify導入ソリューションをご提供しています。「こんな業務を自動化したい」と、まずはざっくばらんにご相談ください!