関連記事
https://blog.elcamy.com/posts/136913a3/
https://blog.elcamy.com/posts/ed655d0a/
https://blog.elcamy.com/posts/54294ff0
https://blog.elcamy.com/posts/a5744c61/
はじめに
LangGraphを知らない方、わからない方は、まず「LangGraphとは」をご覧ください。 この記事ではLangGraphを初めて使う方に向けて、LangGraphの公式ページに用意されているチュートリアルを解説します。今回解説するチュートリアルは「Adaptive-RAG」です。 また、Adaptive-RAGの一部はSelf-RAGで構成されています。知らない方は、「LangGraphのチュートリアル解説Self-RAG編」をご覧ください。
記事の対象者
- LangGraph初学者
- LangChain初学者
Adaptive-RAGとは
Adaptive-RAG(Adaptive Retrieval-Augmented Generation) とは、LLMが質問に対して回答を生成する際に、質問を分類し、適切な情報源を選択して回答の精度を高める仕組みです。 具体的には、次のような流れで動きます:
- 質問を受け取る
- 質問を分類し、インデックス(過去データ)検索またはWeb検索のどちらが適切か判断
- 適切な情報源から関連情報を取得する
- 取得した情報を基に回答を生成する
- 回答が事実に基づいているか、質問に対して適切か評価する このように、質問に応じて柔軟に検索方法を切り替えながら回答生成を行うことで、信頼性の高い回答と広範囲な情報検索を両立できるのが Adaptive-RAG の特徴です。
チュートリアルの概要
まず質問を分類して、インデックス検索(Self-RAG)またはWeb検索のどちらを使用するかを決定します。選択された方法で情報を取得し、関連するドキュメントを基に回答を生成します。その後、生成された回答の妥当性を評価し、必要に応じて質問を改善して再試行し、最終的な回答を出力します。 今回作成するシステムは以下の通りです。
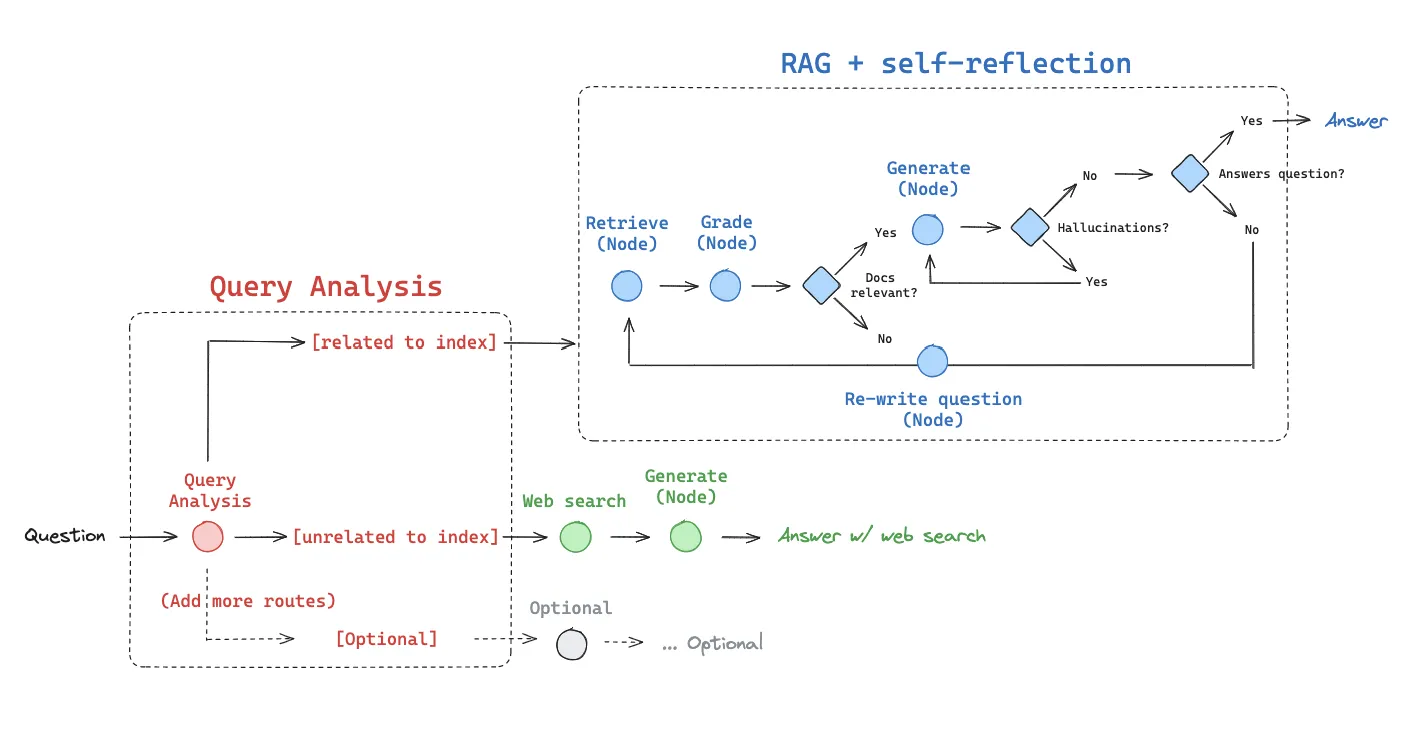
チュートリアルの解説
✅ステップ
- 準備
- インデックスの構築
- 適切なデータソースの選択
- Self-RAGプロセスの構築
- Web Search Toolの実装
- グラフの定義
- グラフの実装
1.準備
今回のチュートリアルに必要なライブラリのインストール、APIキーの設定をします。 ライブラリのインストールは以下のコマンドを実行してください。
%%capture --no-stderr
! pip install -U langchain_community tiktoken langchain-openai langchain-cohere langchainhub chromadb langchain langgraph tavily-python次にOpenAI、Cohere、TavilyのAPIキーを環境変数に設定します。チュートリアルに以下のコードを追加してください。
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
_set_env("COHERE_API_KEY")
_set_env("TAVILY_API_KEY")2.インデックスの構築
ここでは、指定したウェブページからデータを取得し、それをベクトル化して検索可能なインデックスを構築します。
### Build Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
### from langchain_cohere import CohereEmbeddings
# Set embeddings
embd = OpenAIEmbeddings()
# Docs to index
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Split
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorstore
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embd,
)
retriever = vectorstore.as_retriever()コード解説
OpenAIの埋め込みモデルを使用して、テキストをベクトルに変換します。
embd = OpenAIEmbeddings()インデックス化するデータのソースとして使用するURLのリストを定義します。
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]データをロードします。
WebBaseLoader(url).load():各URLからデータを取得し、リストとして返します。[item for sublist in docs for item in sublist]:ネストされたリスト(docs)をフラットなリスト(docs_list)に変換します。
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]テキストを分割し、埋め込みモデルが効率的に処理できるようにします。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)検索時に入力クエリと関連するベクトルを効率的に見つけるため、分割されたドキュメント(doc_splits)をベクトルストアに登録します。
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embd,
)ベクトルストアを検索可能なオブジェクト(レトリーバー)として使用できるように設定します。 これにより、質問や検索クエリが入力された際に関連するベクトルデータを高速に取得できます。
retriever = vectorstore.as_retriever()3.適切なデータソースの選択
ここでは、ユーザーの質問に応じて適切なデータソース(vectorstoreまたはweb_search)を選択する「ルーター」を構築しています。
### Router
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print(question_router.invoke({"question": "Who will the Bears draft first in the NFL draft?"}))
print(question_router.invoke({"question": "What are the types of agent memory?"}))コード解説
ユーザーの質問を適切なデータソースにルーティングするためのデータモデルを定義します。
datasource:"vectorstore"または"web_search"のどちらかを選択します。
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)OpenAIの言語モデルを初期化します。
さらに、with_structured_output を使用して、モデルの出力をRoutQuery データモデルの従うよう設定します。結果としてvectorstoreまたはweb_search を出力します。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)プロンプトを設定します。
system:モデルの役割や目的を説明を記述しています。ここでは、「質問を適切なデータソースにルーティングする専門家」としてモデルを設定しています。vectorstoreを選択:質問が「エージェント」「プロンプトエンジニアリング」「逆攻撃」に関連する場合web_searchを選択: それ以外の質問の場合
route_prompt:チャット形式のプロンプトを作成します。システムメッセージ(モデルの説明)と、ユーザーの質問({question})を入力として受け取ります。
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)プロンプト(route_prompt)と言語モデル(structured_llm_router)
question_router = route_prompt | structured_llm_router実行してみます。
print(question_router.invoke({"question": "Who will the Bears draft first in the NFL draft?"}))
print(question_router.invoke({"question": "What are the types of agent memory?"}))- 質問1:「Who will the Bears draft first in the NFL draft?(シカゴ・ベアーズがNFLドラフトで最初に誰を指名するか?)」
- この質問は「エージェント」「プロンプトエンジニアリング」「逆攻撃」に関連しないため、
web_searchが選択されます。
- この質問は「エージェント」「プロンプトエンジニアリング」「逆攻撃」に関連しないため、
- 質問2:「What are the types of agent memory?(エージェントのメモリの種類は?)」
- この質問は「エージェント」に関連しているため、
vectorstoreが選択されます。
- この質問は「エージェント」に関連しているため、
4.Self-RAGプロセスの構築
前プロセスにおいてvectorstore が選択されると、Self-RAGを用いてドキュメントを検索します。
ここでは、Self-RAGプロセスを構築します。
Self-RAGプロセスは以下のステップで構成されます:
Self-RAGのコードの詳細についてはこちらを参照してください。
1.情報の取得**(Retrieval Grader)**
### Retrieval Grader
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))2.回答の生成(Generate)
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)3.生成結果の評価(Hallucination Grader)
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})4.回答の適合性評価(Answer Grader)
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})5.質問の改善(Question Re-writer)
### Question Re-writer
# LLM
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
# Prompt
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})5.Web Search Toolの実装
このプロセスは、ユーザーの質問が vectorstore ではなく web_search に分類された場合に実行され、インターネットから関連情報を取得します。
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)コード解説
TavilySearchResults:- LangChainのコミュニティツールで、Web検索を実行するためのクラスです。
- TavilyのAPIを使用して、検索クエリに基づいた結果を取得します。
TavilySearchResults(k=3):- 検索結果として最大3件の関連ドキュメントを返すように設定します(
k=3)。 - このにより、質問に関連する最も重要な情報を効率的に収集します。
- 検索結果として最大3件の関連ドキュメントを返すように設定します(
6.グラフの定義
ここでは、質問に基づいて情報を取得し、回答を生成する一連のプロセスを構築します。Adaptive-RAGにおける動的なデータ処理フローを定義しています。
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
### Edges ###
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"グラフ状態の定義
GraphState:質問、生成された回答(generation)、および関連ドキュメント(documents)を保持する状態の構造を定義します。
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]ノード
-
retrieve:質問(state["question"])をもとに、vectorstoreから関連するドキュメントを取得します。pythondef retrieve(state): """ Retrieve documents Args: state (dict): The current graph state Returns: state (dict): New key added to state, documents, that contains retrieved documents """ print("---RETRIEVE---") question = state["question"] # Retrieval documents = retriever.invoke(question) return {"documents": documents, "question": question} -
generate:ドキュメントを基に質問に対する回答を生成します。pythondef generate(state): """ Generate answer Args: state (dict): The current graph state Returns: state (dict): New key added to state, generation, that contains LLM generation """ print("---GENERATE---") question = state["question"] documents = state["documents"] # RAG generation generation = rag_chain.invoke({"context": documents, "question": question}) return {"documents": documents, "question": question, "generation": generation} -
grade_documents:各ドキュメントを質問と比較し、関連性を評価します。「関連性あり」と判断されたドキュメントのみを状態に保持します。pythondef grade_documents(state): """ Determines whether the retrieved documents are relevant to the question. Args: state (dict): The current graph state Returns: state (dict): Updates documents key with only filtered relevant documents """ print("---CHECK DOCUMENT RELEVANCE TO QUESTION---") question = state["question"] documents = state["documents"] # Score each doc filtered_docs = [] for d in documents: score = retrieval_grader.invoke( {"question": question, "document": d.page_content} ) grade = score.binary_score if grade == "yes": print("---GRADE: DOCUMENT RELEVANT---") filtered_docs.append(d) else: print("---GRADE: DOCUMENT NOT RELEVANT---") continue return {"documents": filtered_docs, "question": question} -
transform_query:質問を改善し、次回の情報取得でより適切な結果が得られるようにします。pythondef transform_query(state): """ Transform the query to produce a better question. Args: state (dict): The current graph state Returns: state (dict): Updates question key with a re-phrased question """ print("---TRANSFORM QUERY---") question = state["question"] documents = state["documents"] # Re-write question better_question = question_rewriter.invoke({"question": question}) return {"documents": documents, "question": better_question} -
web_search:再構築された質問をもとにWeb検索を行い、結果をドキュメントとして状態に追加します。pythondef web_search(state): """ Web search based on the re-phrased question. Args: state (dict): The current graph state Returns: state (dict): Updates documents key with appended web results """ print("---WEB SEARCH---") question = state["question"] # Web search docs = web_search_tool.invoke({"query": question}) web_results = "\n".join([d["content"] for d in docs]) web_results = Document(page_content=web_results) return {"documents": web_results, "question": question}
エッジ
- 質問のルーティング(
toute_question)
- 質問を
web_searchまたはvectorstoreに振り分けます。 - 出力は、次に実行するノードの名前(
web_searchまたはvectorstore)です。
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"- 生成の必要性を判断(
decide_to_generate)
- ドキュメントが存在しない場合は質問を再構築(
transform_query)、存在する場合は回答を生成(generate)します。
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"- 生成結果の評価(
grade_generation_v_documents_and_question)
- 生成結果がドキュメントに基づいており、質問に適切に答えているかを評価します。
- 結果に基づき、次のステップを選択します。
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"7.グラフの実装
ここでは、Adaptive-RAGの全体的な処理フローを構築し、実行可能な形にコンパイルします。処理フローは、ノードとエッジを組み合わせたグラフ構造として設計されています。
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()コード解説
GraphState を基盤にした新しい状態遷移グラフを作成します。
workflow = StateGraph(GraphState)各ノードをグラフに追加します。
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_queryここから、エッジを定義します。
まず、START から質問のルーティングを行い、route_question を使って次のノードを条件分岐します。質問が web_search に分類される場合は web_search に進み、vectorstore に分類される場合は retrieve に進みます。
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)次に、web_search が実行された後、直接 generate に進んで回答を生成します。
workflow.add_edge("web_search", "generate")一方で、retrieve が実行された後、取得されたドキュメントの関連性を評価するために grade_documents に進みます。
workflow.add_edge("retrieve", "grade_documents")grade_documents の後は、decide_to_generate を使って次のステップを条件分岐します。適切なドキュメントが存在しない場合は質問を再構築するために transform_query に進み、適切なドキュメントが存在する場合は generate に進みます。
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)質問が再構築された場合(transform_query)、再度ドキュメントを取得するために retrieve に戻ります。
workflow.add_edge("transform_query", "retrieve")最後に、generate が実行された後、生成された回答を評価するために grade_generation_v_documents_and_question を使って次のステップを条件分岐します。回答が適切であれば終了(END)し、回答が不適切であれば質問を再構築(transform_query)します。回答がドキュメントに基づいていない場合は再生成(generate)を行います。
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)全体の流れ
- START:ワークフローの開始。質問のルーティングを実行。
- 質問がWeb検索に分類された場合:
web_searchに進む。 - 質問がインデックス検索(
vectorstore)に分類された場:retrieveに進む。
- 質問がWeb検索に分類された場合:
- web_search:質問に基づいてWeb検索を実行。
- 次:
generateで回答を生成。
- 次:
- retrieve: :質問に基づいてインデックス(
vectorstore)から関連ドキュメントを取得。- 次:ドキュメントの関連性を評価(
grade_documents)。
- 次:ドキュメントの関連性を評価(
- grade_documents:取得したドキュメントの関連性を評価。
- 関連性がない場合:質問を再構築(
transform_query)。 - 関連性がある場合:回答を生成(
generate)。
- 関連性がない場合:質問を再構築(
- transform_query:質問を再構築して改善。
- 次に進む:再度
retrieveでドキュメントを取得。
- 次に進む:再度
- generate:ドキュメントやWeb検索結果を基に回答を生成。
- 回答が適切でない場合(not useful):質問を再構築(
transform_query)。 - 回答がドキュメントに基づいていない場合(not supported):再度回答を生成。
- 回答が適切な場合(useful):終了(
END)。
- 回答が適切でない場合(not useful):質問を再構築(
- END:ワークフローの終了。
実際に使ってみる
出力の構造
- ROUTE QUESTION
- 質問を
web_searchまたはvectorstoreにルーティングします。
- WEB SEARCH
- 質問に基づいてWeb検索を実行します。
- GENERATE
- 検索結果に基づいて回答を生成します。
- CHECK HALLUCINATIONS
- 生成された回答が検索結果に基づいているか確認します。
- GRADE GENERATION vs QUESTION
- 生成された回答が質問に適切に答えているか評価します。
- FINAL GENERATION
- 最終的な回答を出力します。
例1
from pprint import pprint
# Run
inputs = {
"question": "ベアーズが2024年のNFLドラフトで最初に指名すると予想される選手は誰ですか?"
}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])出力結果と詳細
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('2024年のNFLドラフトでシカゴ・ベアーズが最初に指名する選手は、
南カリフォルニア大学出身のQBケーレブ・ウィリアムズと予想されています。 '
'ベアーズは2024年のNFLドラフトで全体1位指名権を獲得し、ウィリアムズを指名する可能性が高いです。')
質問:ベアーズが2024年のNFLドラフトで最初に指名すると予想される選手は誰ですか? 結果:
- 質問のルーティング
- Node:
route_question質問がインデックス(vectorstore)には存在しない、もしくは時事的な内容と判断されたため、Web検索に振り分けられました。
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
- Web検索
- Node:
web_searchWeb検索を実行し、質問に関連するWeb情報を取得しました。
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
- 回答生成
- Node:
generate取得したWeb検索結果を基に、言語モデルが回答を生成しました。
---GENERATE---
- 生成結果の評価
- Node:
generate- CHECK HALLUCINATIONS:生成された回答が取得したWeb情報に基づいているか評価され、「基づいている(grounded)」と判定。
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
- GRADE GENERATION vs QUESTION:生成された回答が質問に適切に答えているか評価され、「適切に答えている」と判定されました。
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
- 最終回答
- Node:
generate
"Node 'generate':"
'\n---\n'
('2024年のNFLドラフトでシカゴ・ベアーズが最初に指名する選手は、
南カリフォルニア大学出身のQBケーレブ・ウィリアムズと予想されています。 '
'ベアーズは2024年のNFLドラフトで全体1位指名権を獲得し、ウィリアムズを指名する可能性が高いです。')
例2
# Run
inputs = {"question": "エージェントの記憶の種類にはどのようなものがありますか?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])出力結果と詳細
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
'短期記憶、長期記憶の種類があります。それぞれ、視覚、聴覚、触覚などの感覚情報を保持する感覚記憶と、
学習や推論などの複雑な認知タスクを実行するために必要な情報を保持する作業記憶があります。
長期記憶には、事実や出来事の記憶を意味する陳述記憶と、自動的に実行されるスキルやルーチンを含む
暗黙の記憶があります。'
質問:エージェントの記憶の種類にはどのようなものがありますか? 結果:
- 質問のルーティング
- Node:
route_question質問がインデックス(vectorstore)内の情報と関連すると判断されたため、質問が**RAG(インデックス検索)**にルーティングされました。
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
- ドキュメント取得
- Node:
retrieveインデックス(vectorstore)から関連するドキュメントを検索し、取得しました。
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
- ドキュメントの関連性チェック
- Node:
grade_documents取得した各ドキュメントの関連性を評価しました。- 評価結果:
- 関連性あり:3件
- 関連性なし:1件
- 評価結果:
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
- 次のステップの決定
- Node:
grade_documents関連性のあるドキュメントが存在するため、回答生成(generate)に進むと判断されました。
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
- 回答生成
- Node:
generate関連性のあるドキュメントをもとに回答を生成しました。
---GENERATE---
- 生成結果の評価
- Node:
generate- CHECK HALLUCINATIONS:生成された回答が関連ドキュメントに基づいているか評価され、「基づいている(grounded)」と判定されました。
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
- GRADE GENERATION vs QUESTION:生成された回答が質問に適切に答えているか評価され、「適切に答えている」と判定。
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
- 最終回答
- Node:
generate
"Node 'generate':"
'\n---\n'
'短期記憶、長期記憶の種類があります。それぞれ、視覚、聴覚、触覚などの感覚情報を保持する感覚記憶と、
学習や推論などの複雑な認知タスクを実行するために必要な情報を保持する作業記憶があります。
長期記憶には、事実や出来事の記憶を意味する陳述記憶と、自動的に実行されるスキルやルーチンを含む
暗黙の記憶があります。'
まとめ
この記事では、LangGraphを使用して質問応答生成システム「Adaptive-RAG」を構築する方法を解説しました。 チュートリアルを通じて、質問をWeb検索やインデックス検索にルーティングし、適切な情報源からデータを取得して回答を生成する流れを学びました。また、生成された回答の妥当性を評価し、必要に応じて質問を再構築する動的で柔軟なプロセスの管理方法についても説明しました。 ぜひAdaptive-RAGを活用して、複数のデータソースを統合した信頼性の高い情報検索・応答生成ツールを開発してみてください。
参考文献
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/
