更新日: 2025-07-31
はじめに
Dify というサービスを聞いたことがあるけれど、「何ができるかわからない」、「どう使うのかわからない」などの理由で使ったことがない方は多いのではないでしょうか。
そのような方のために、「Dify で何ができるのか?」や Dify を使った活用事例を紹介する記事をシリーズ化していきます。
シリーズ記事はこちらです 【Difyで作るシリーズ 1】 PDFファイルの要約 【Difyで作るシリーズ 2】会社情報Q&Aチャットボット 【Difyで作るシリーズ 3】 ニュース要約チャットボット
今回は第4回目で、arXivから特定の論文を要約し、その論文の引用数も取得するワークフローを作成する方法について紹介します。
この記事の対象者
- Dify という言葉を聞いたことがあるが、何ができるのかがわからない方
- Dify を業務に取り入れたいと検討している方
事前準備
環境
- Dify v1.15.1(2025年07月26日時点)
作成するAIアプリの概要
完成イメージ
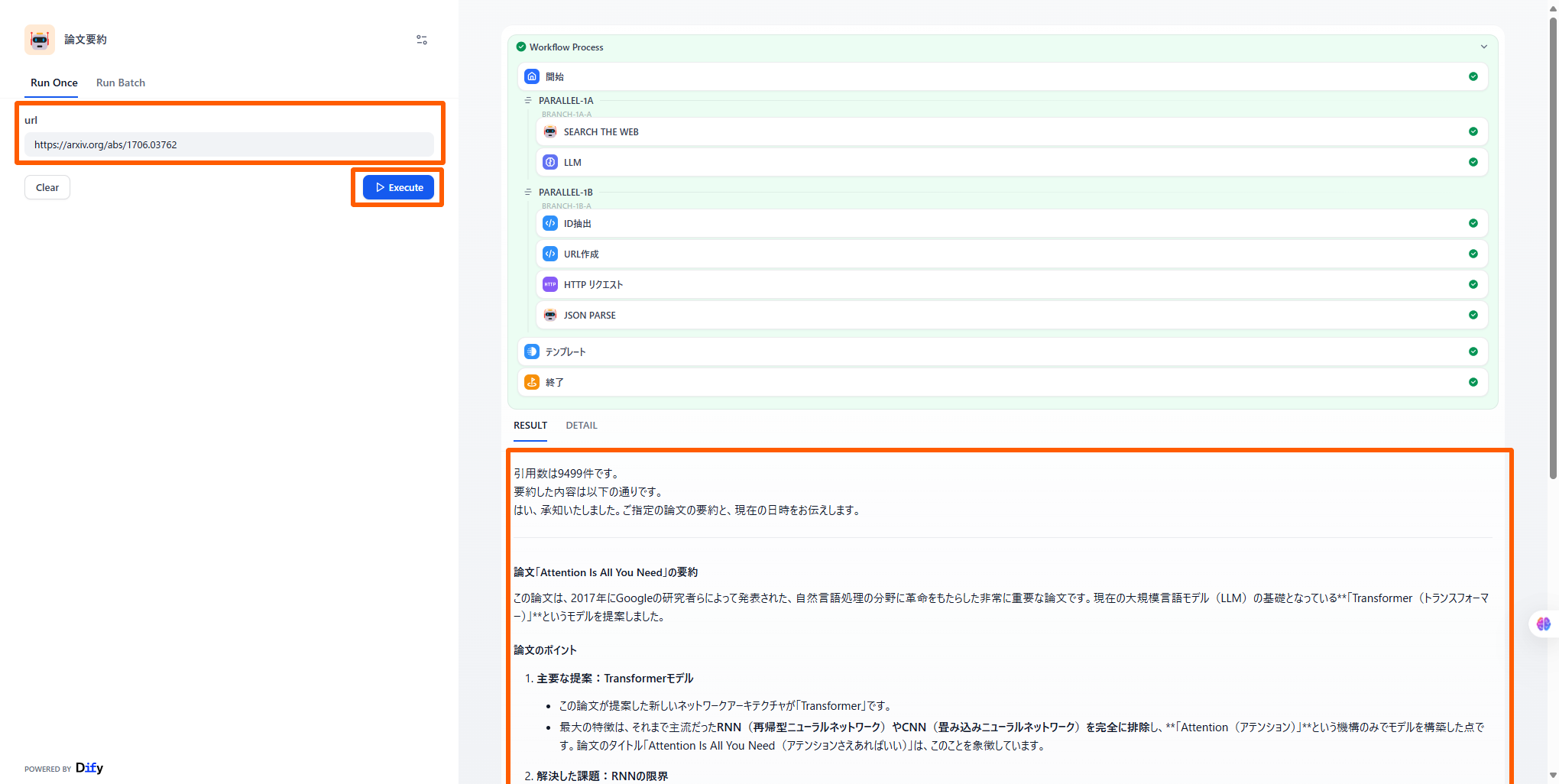
まずは、今回作成するアプリの完成イメージについてです。
イメージ
- 左側の「url」に、対象の論文のURLを入力します。
- 右側に論文の引用数と要約が表示されます。
 上記のアプリを構築するためにワークフローを作る説明をします。
上記のアプリを構築するためにワークフローを作る説明をします。
ワークフローとは 一つ一つの処理を小さな**ブロック(ノード)**としてつなぎ合わせて、一連のプロレスを自動化する機能です。
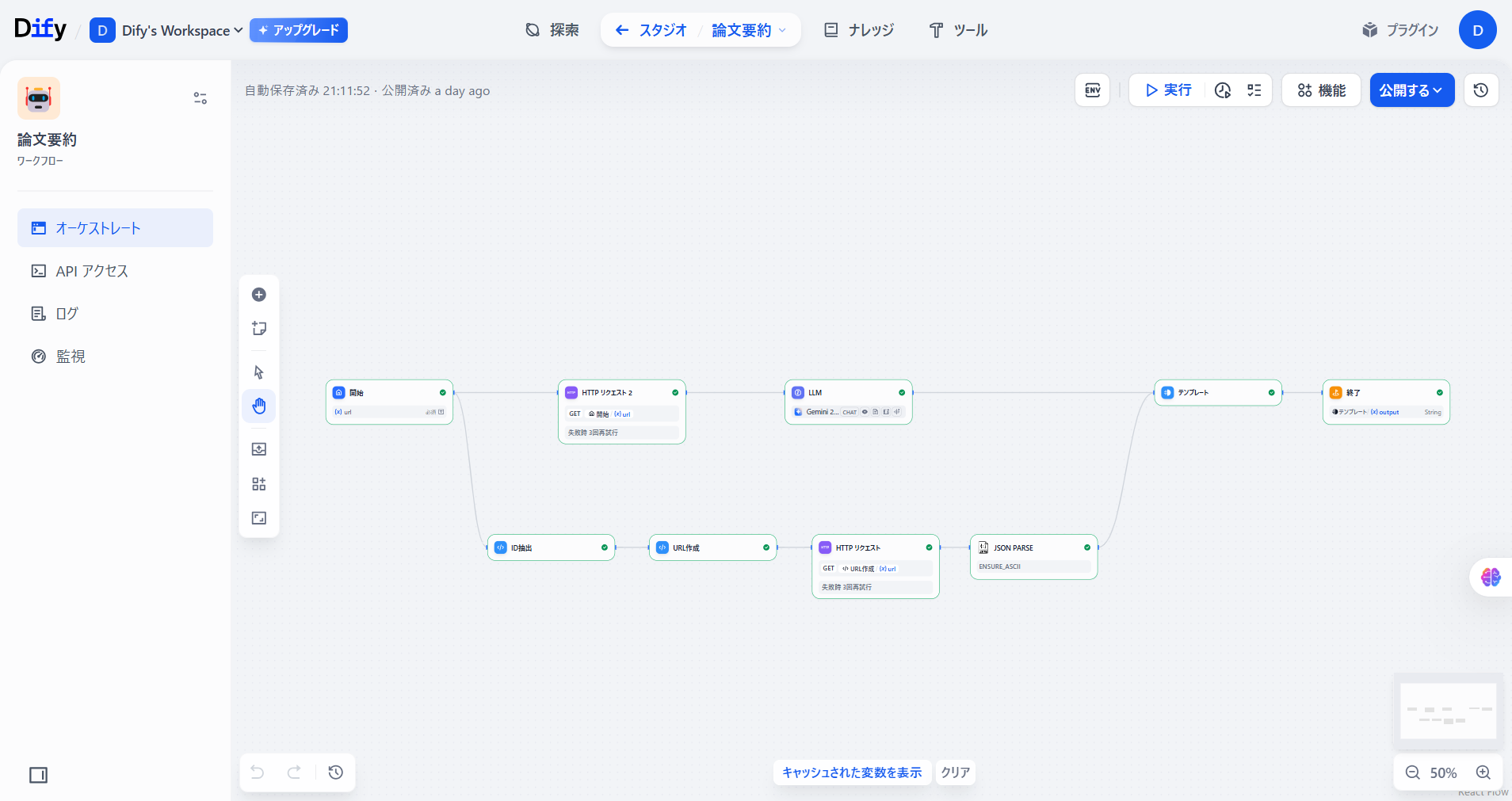
今回作成するワークフローのDifyの画面です。
 このワークフローは、以下のブロックで構成されます。
このワークフローは、以下のブロックで構成されます。
- 開始:要約したい論文のURLを入力するノードです。
- HTTPリクエスト:入力されたURLをもとに、論文の内容を取得します。
- LLM:論文の内容を要約します。
- ID抽出(コード):URLから論文のIDを抽出します。
- URL作成(コード):論文のIDを使って、引用数を取得するためのURLを作ります。
- HTTPリクエスト:URLをもとに論文の引用数を取得します。
- JSON Parse:HTTPリクエストの結果(JSONデータ)から、論文の引用数だけを取り出します。
- テンプレート:出力する形式を指定します。
- 終了:結果を出力します。
作業手順
ここからは、ワークフロー構築の手順について説明します。
手順
- ワークフローの新規作成
- ワークフロー作成画面上での作業
- ワークフローの動作確認
1. ワークフローの新規作成
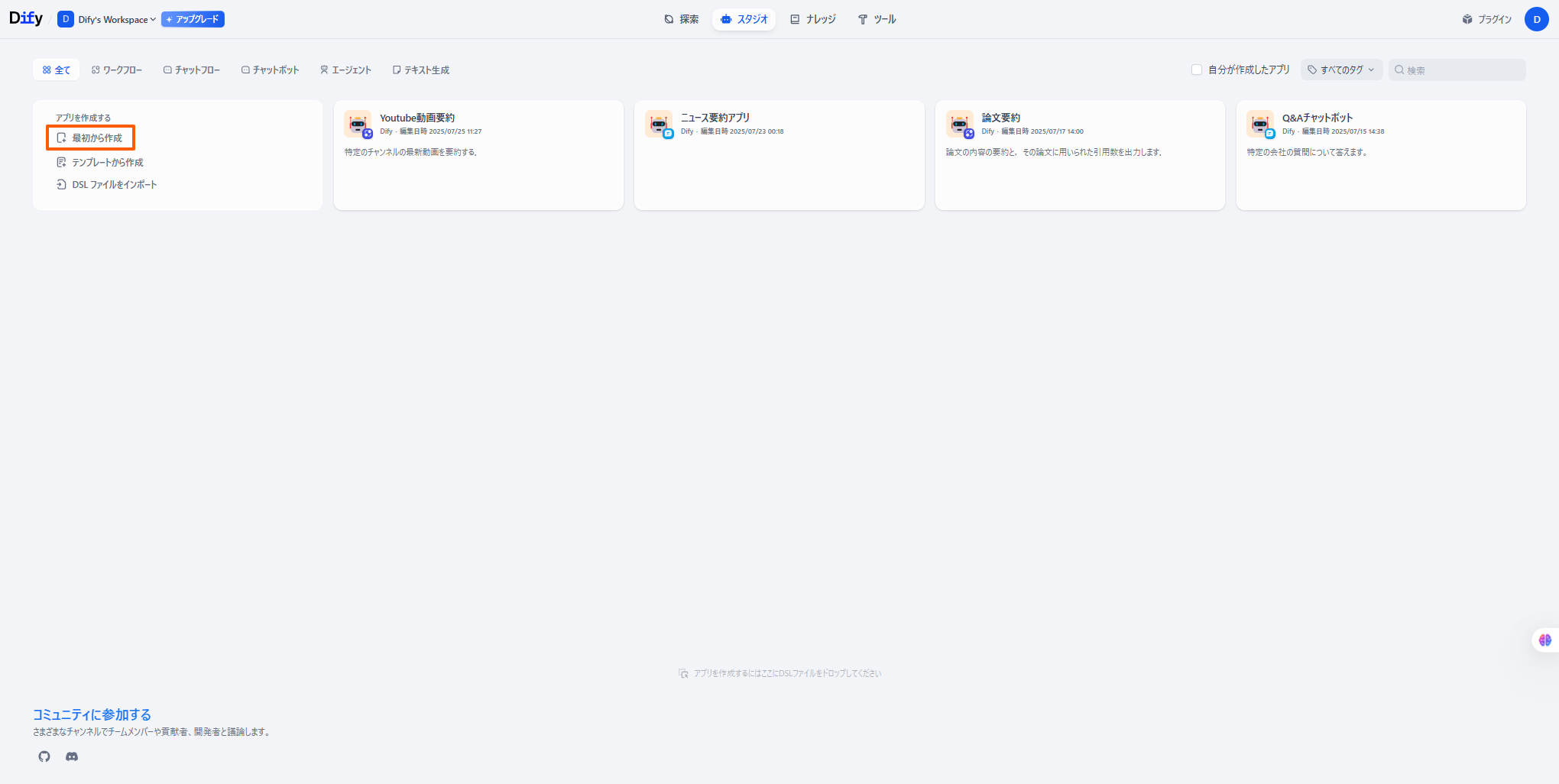
-
最初の画面の「最初から作成」を選択します。
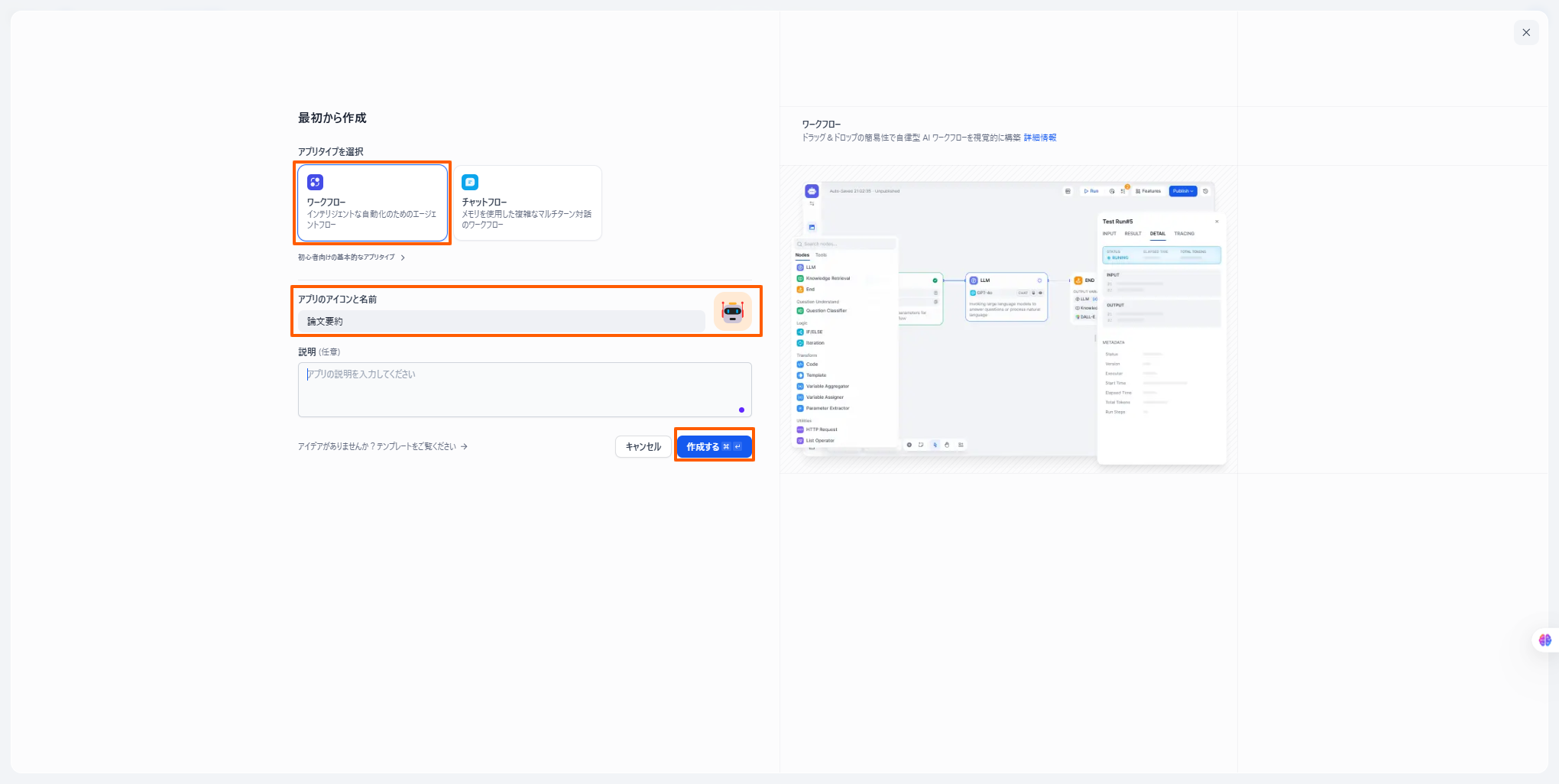
-
「ワークフロー」を選択し、「アプリのアイコンと名前」を入力してから「作成する」を押します。
2. ワークフロー作成画面上での作業
最初に論文を取得し、要約する処理を作ります。
-
**「開始」**ノードを選択します。 入力フィールドの「フィールドタイプ」を「短文」で選択し、「変数名」と「ラベル名」に名前を入力して「保存」を選択します。
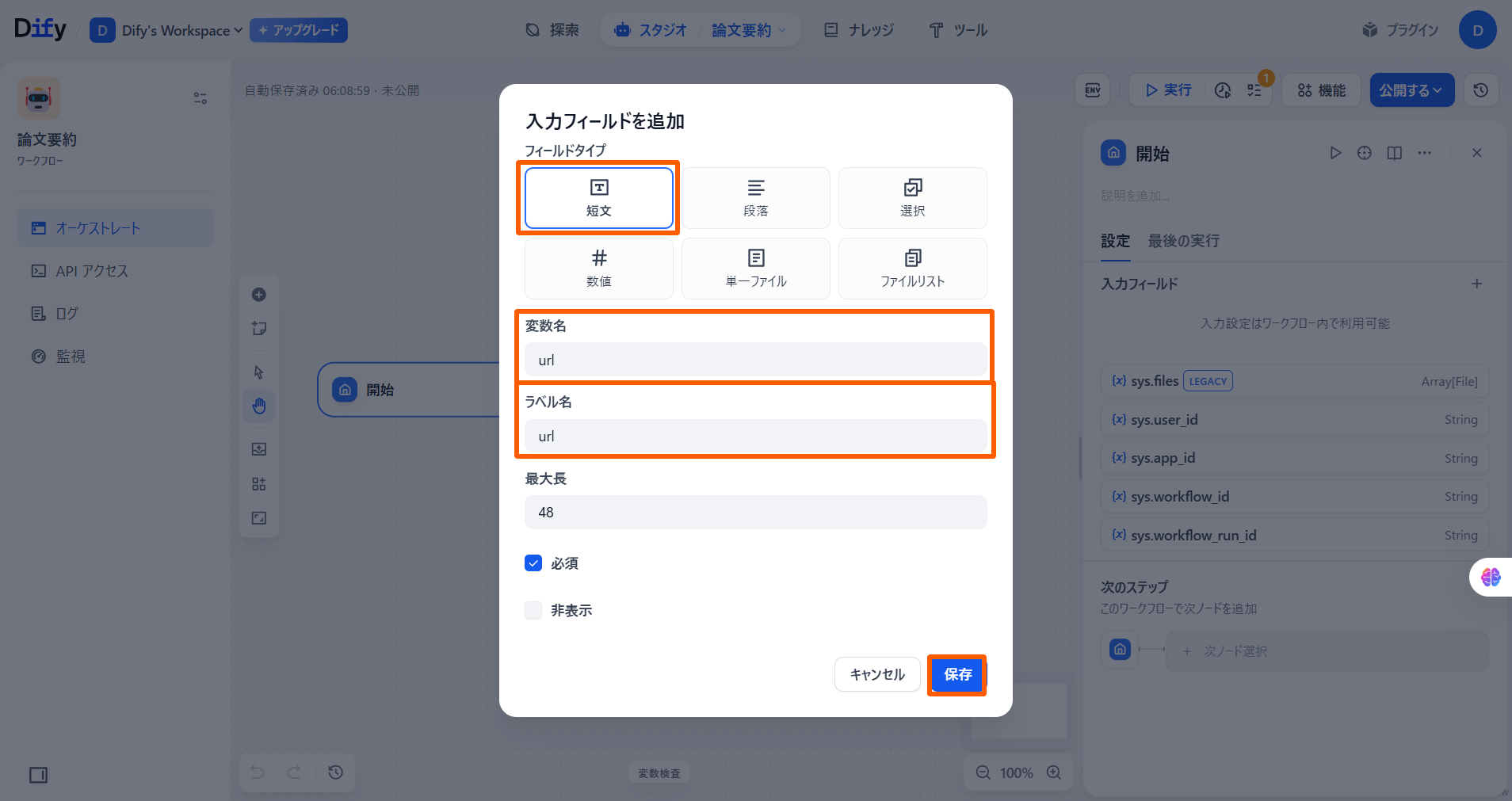
-
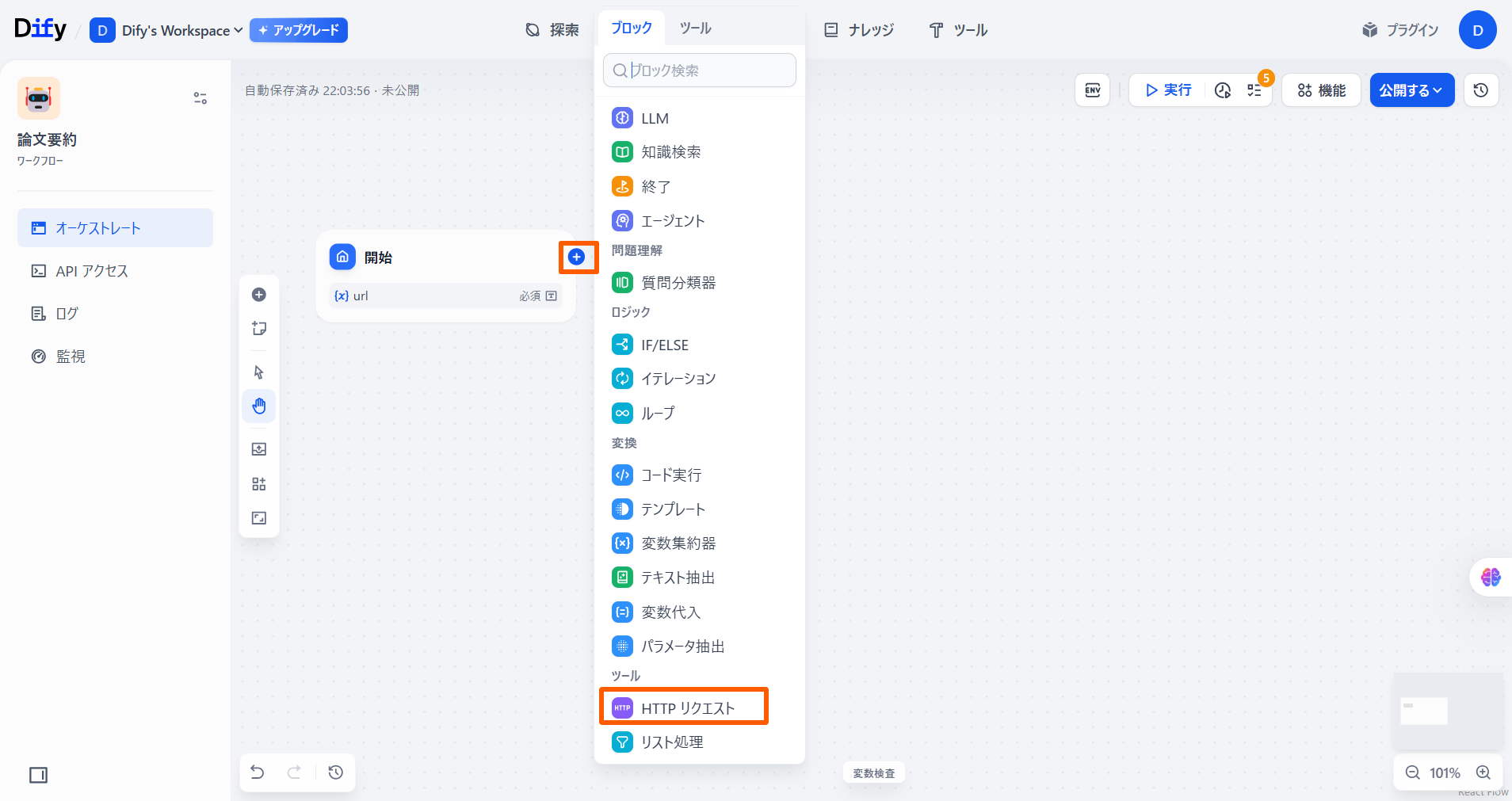
「開始」ノードの「+」ボタンを押し、「ツール」の**「HTTPリクエスト」**を選択します。
 「API」で「GET」を選択します。右の欄で「/」を入力した後、「開始」の「{X}url」を選択します。
「API」で「GET」を選択します。右の欄で「/」を入力した後、「開始」の「{X}url」を選択します。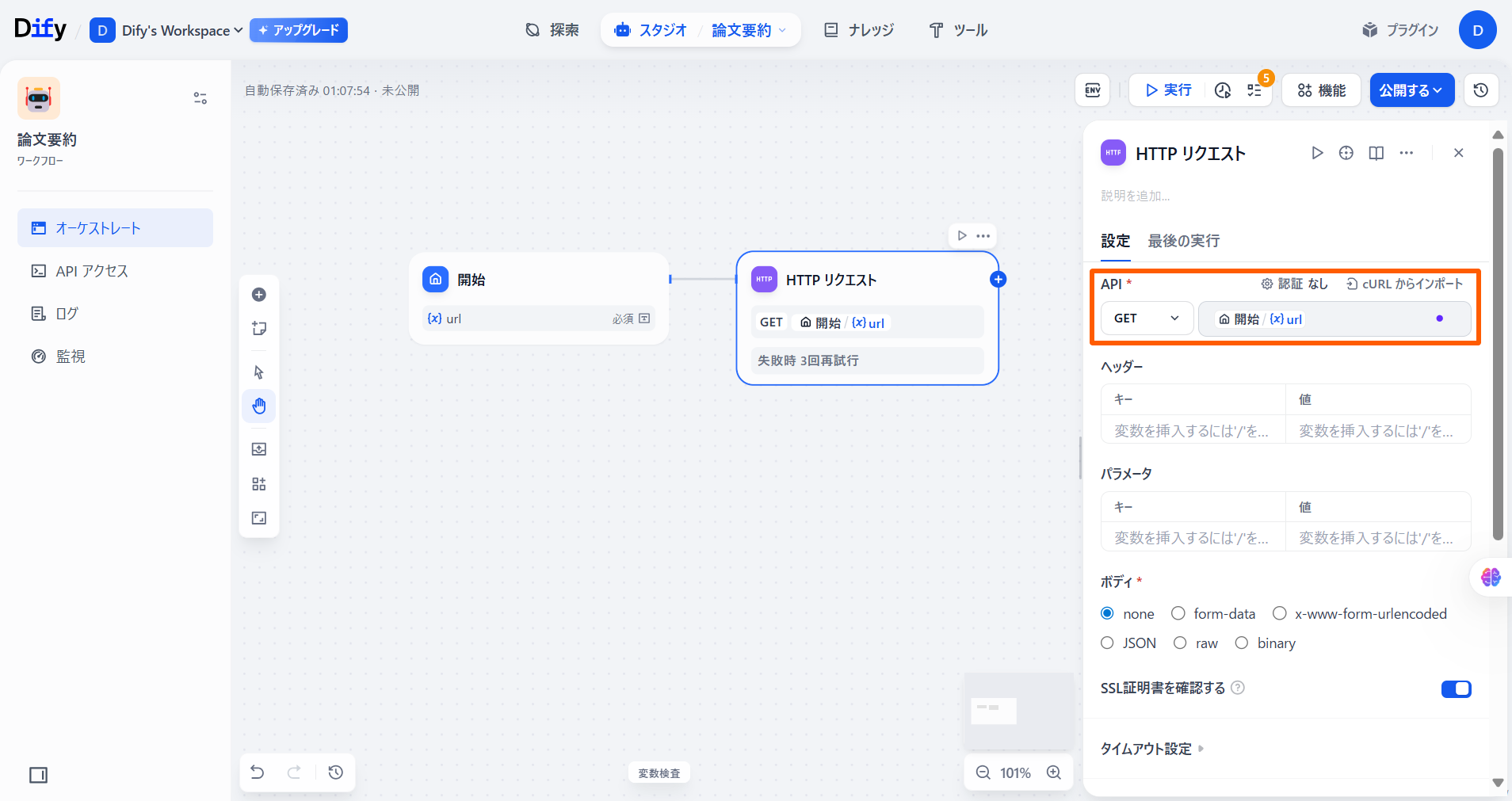
-
「HTTPリクエスト」ノードの「+」ボタンを押し、**「LLM」**を選択します。
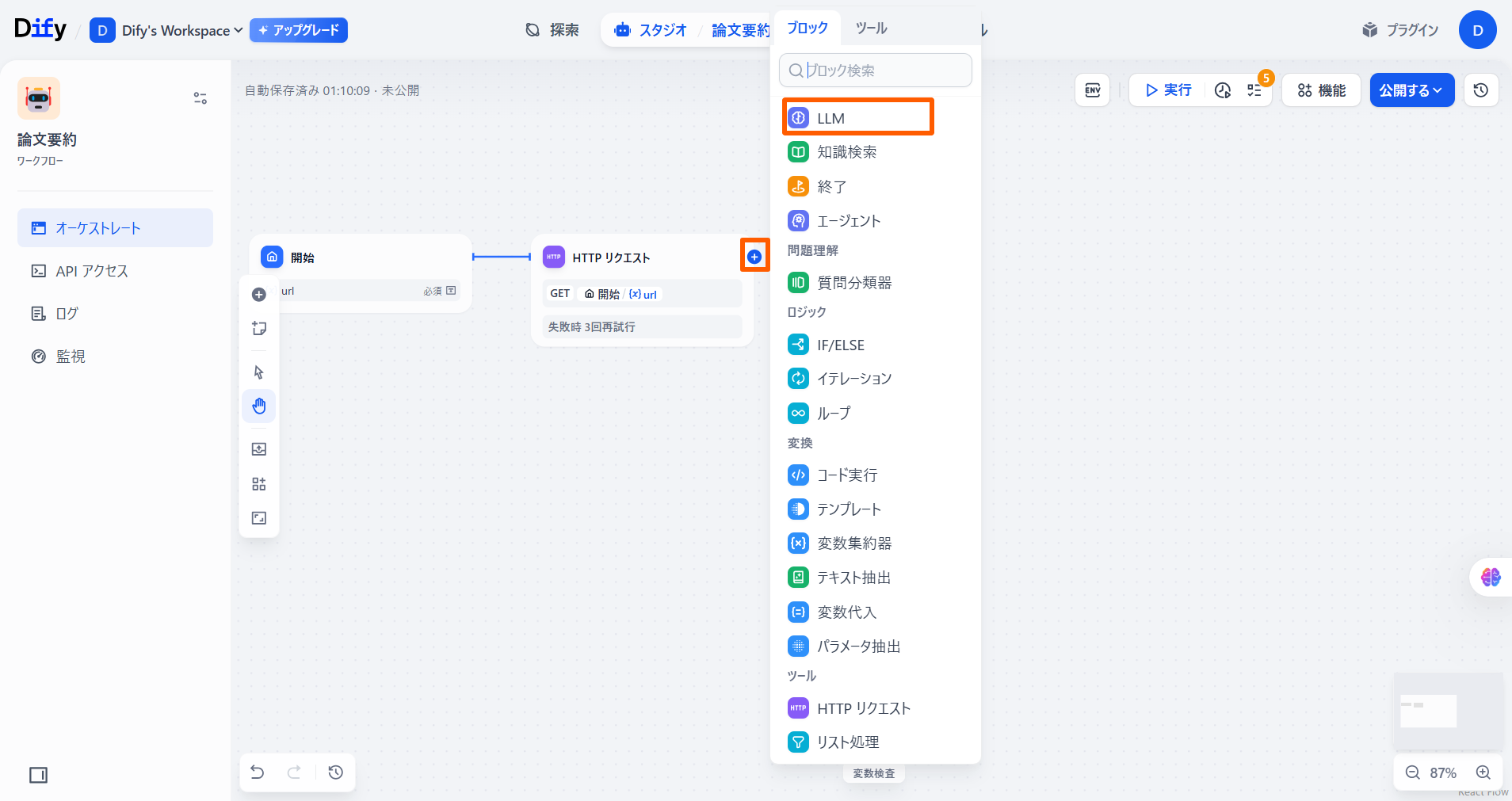 「LLM」ノードを選択し、「コンテキスト」に「開始」の「url」を選択します。
「SYSTEM」「{x}」ボタンをクリックし、「コンテキスト」を追加します。
改行し、以下のプロンプトを入力します。
「LLM」ノードを選択し、「コンテキスト」に「開始」の「url」を選択します。
「SYSTEM」「{x}」ボタンをクリックし、「コンテキスト」を追加します。
改行し、以下のプロンプトを入力します。この文章の内容を要約してください。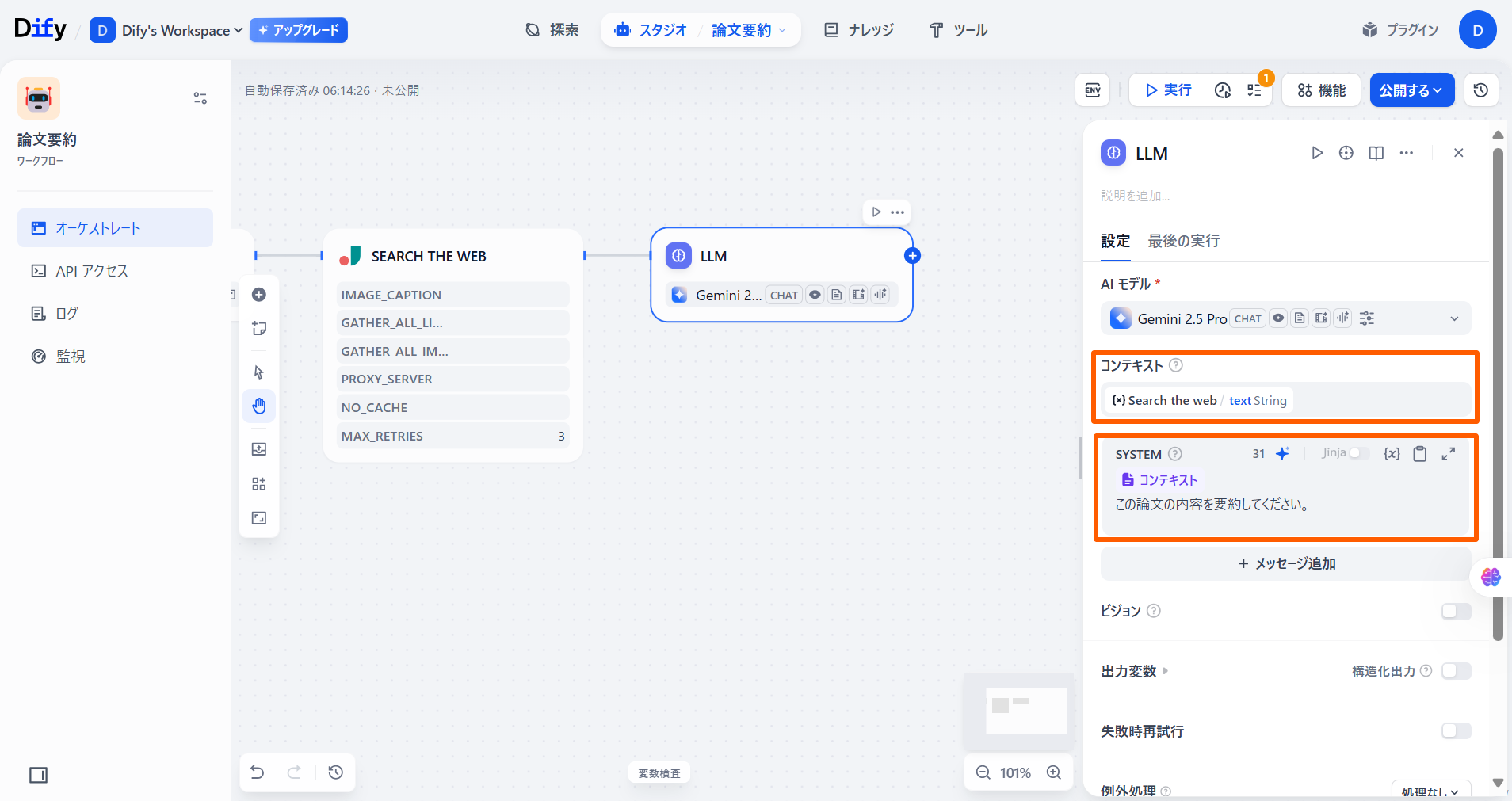 これにより、与えられた論文の要約が完了したので、並列で論文の引用数を取得していきます。
これにより、与えられた論文の要約が完了したので、並列で論文の引用数を取得していきます。 -
「開始」ノードの「+」ボタンを押し、**「コード実行」**ノードを追加します。 論文の引用数を取得するためには、まず論文のURL中にある論文のIDを取得する必要があります。
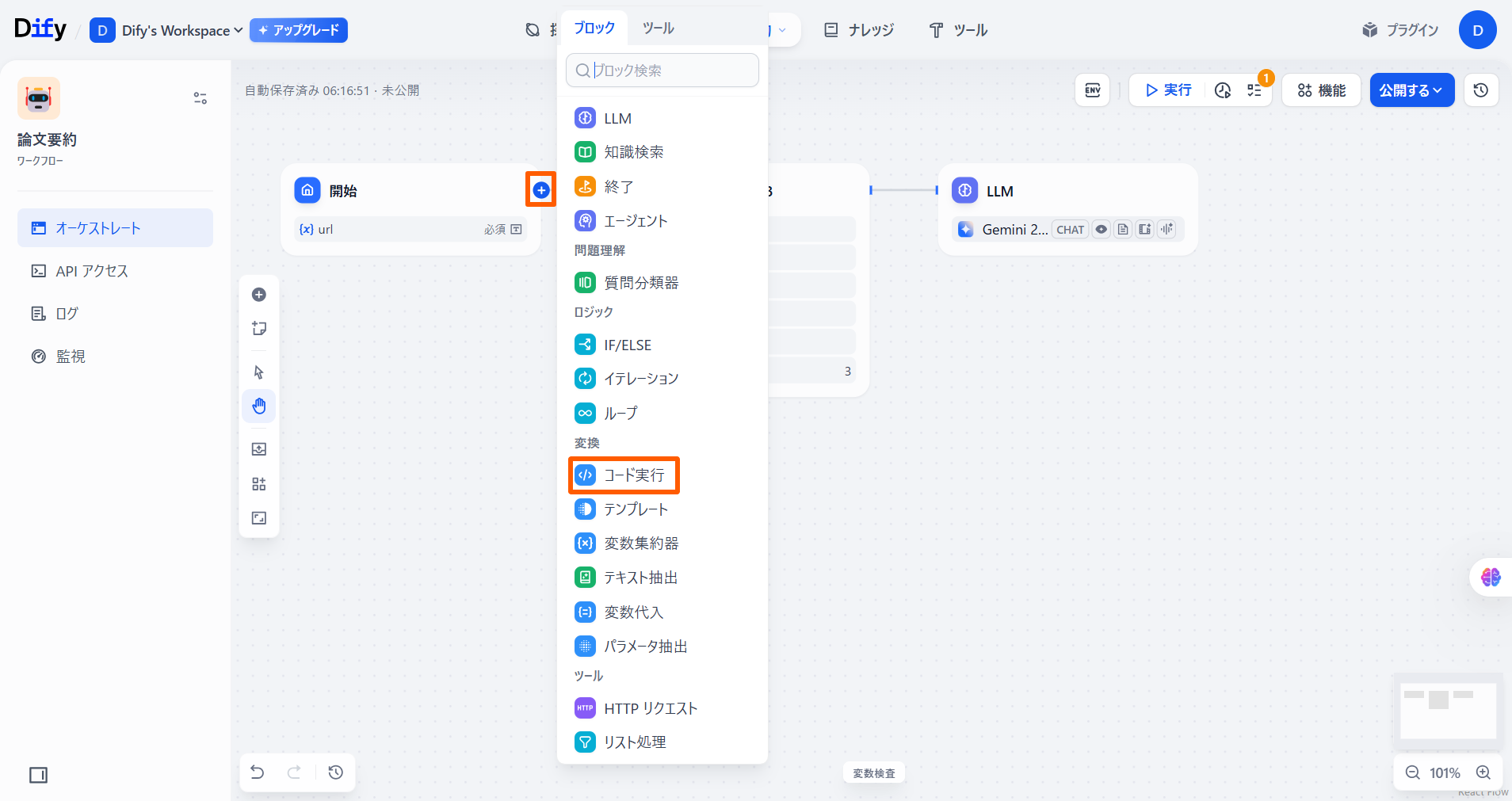 「コード実行」ノードを編集をします。
「入力変数」の値を削除します。
「変数名」に「arxiv_url」と入力し、「開始」の「{x}url」を設定します。
「コード実行」ノードを編集をします。
「入力変数」の値を削除します。
「変数名」に「arxiv_url」と入力し、「開始」の「{x}url」を設定します。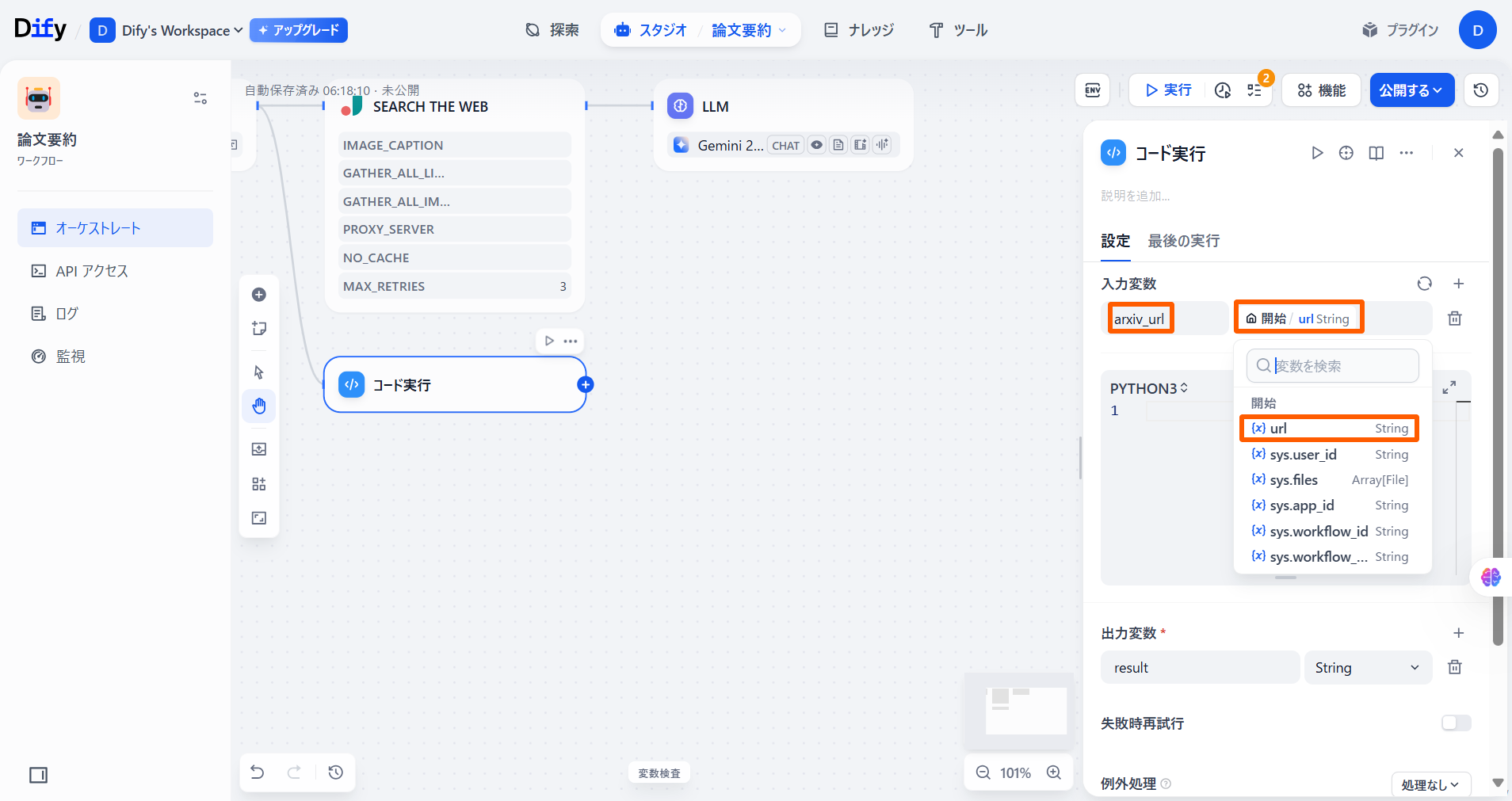 コードブロックに以下のコードを入力します。python
コードブロックに以下のコードを入力します。pythonimport re def main(arxiv_url: str) -> dict: pattern = r"(?:arxiv\.org/abs/)?(\d+\.\d+)" match = re.search(pattern, arxiv_url) if match: arxiv_id = match.group(1) return {"arxiv_id": arxiv_id} else: return {"arxiv_id": None}
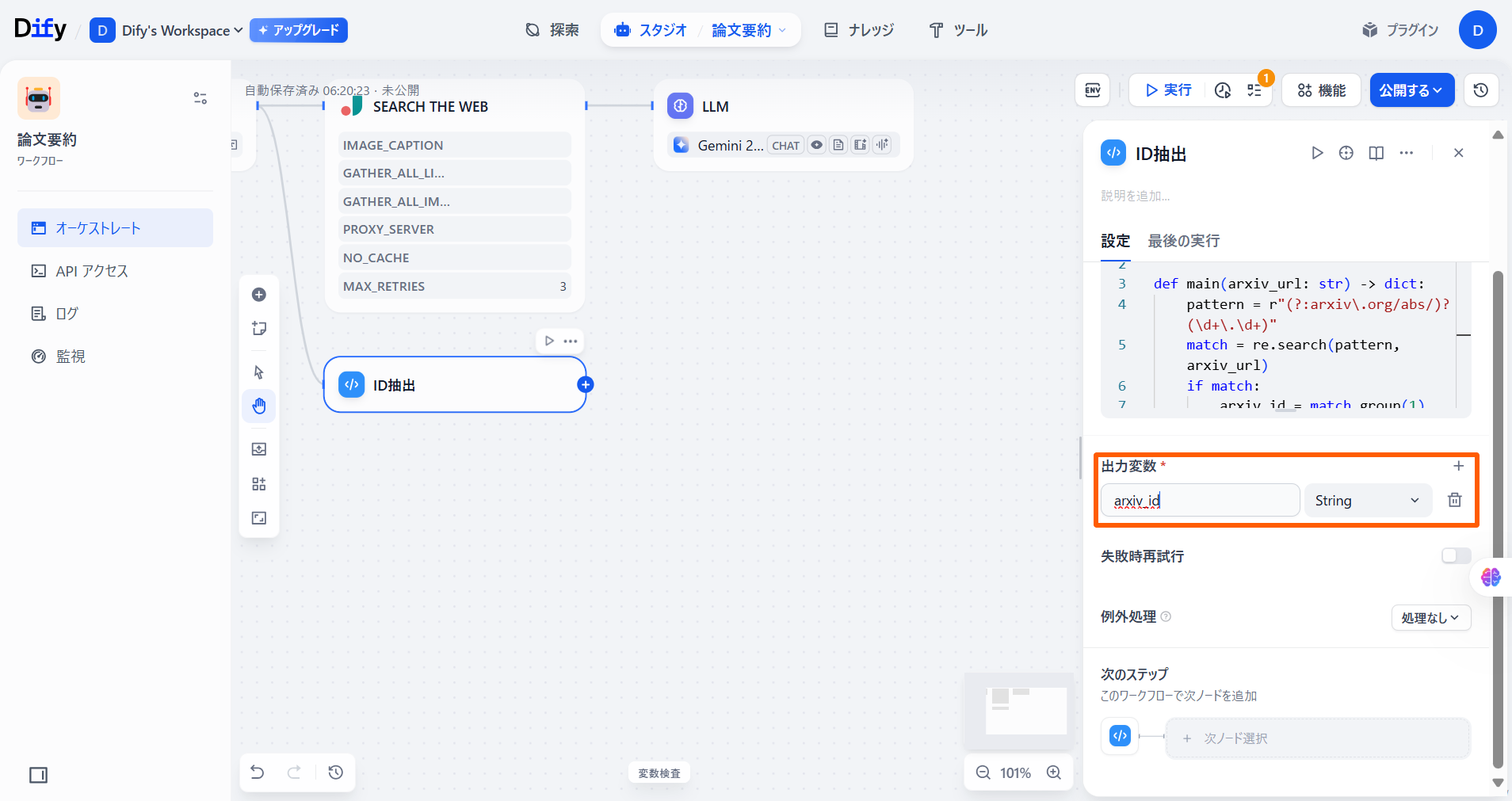
ここではPythonで、URL中の論文のIDを抽出する処理を書いています。ここでわかりやすくするために、コード実行の名前を「ID抽出」にしてあげましょう。
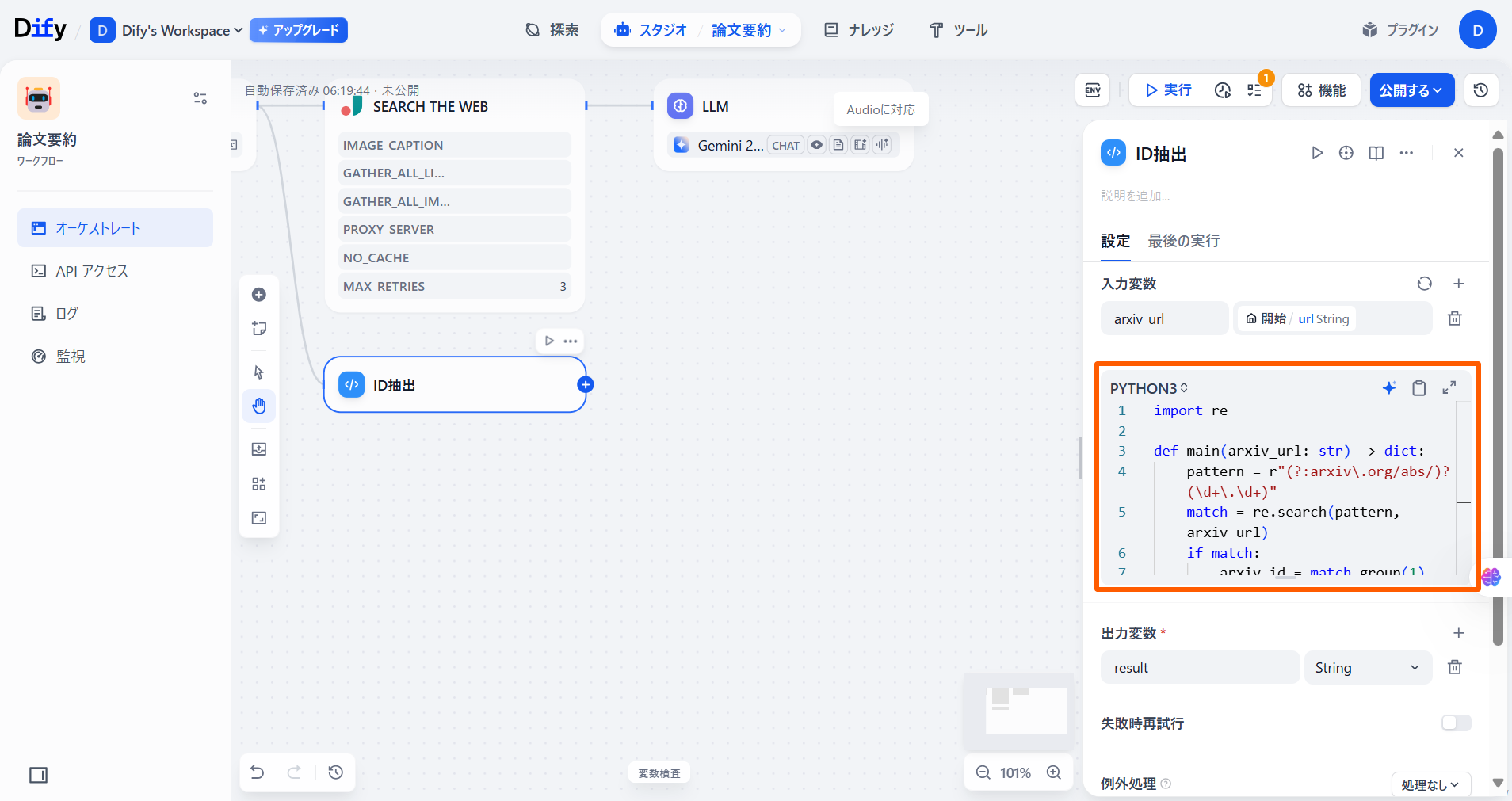 「出力変数」の「変数名」に「arxiv_id」と入力します。
「出力変数」の「変数名」に「arxiv_id」と入力します。
-
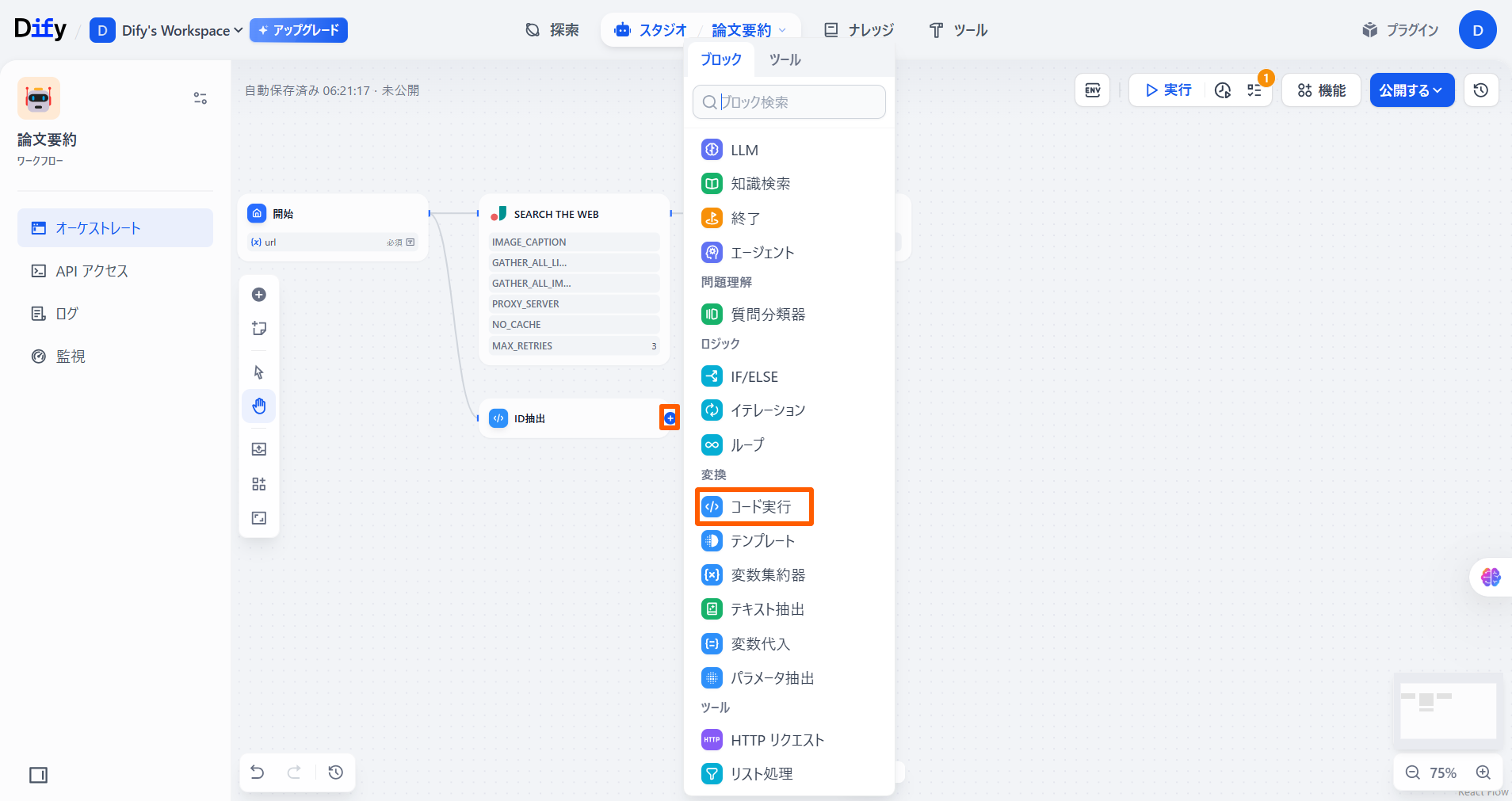
「コード実行」ノードの「+」ボタンを押して、**「コード実行」**を選択します。 特定の論文の引用数を取得するために、論文のIDを使用してADS APIにアクセスするためのURLを作成します。
 既定の入力変数を削除し、「変数名」に「arxiv_id」を入力して「ID抽出」の「{x}arxiv_id」を選択します。コード実行の名前もわかりやすく「URL作成」に変えてあげましょう。
既定の入力変数を削除し、「変数名」に「arxiv_id」を入力して「ID抽出」の「{x}arxiv_id」を選択します。コード実行の名前もわかりやすく「URL作成」に変えてあげましょう。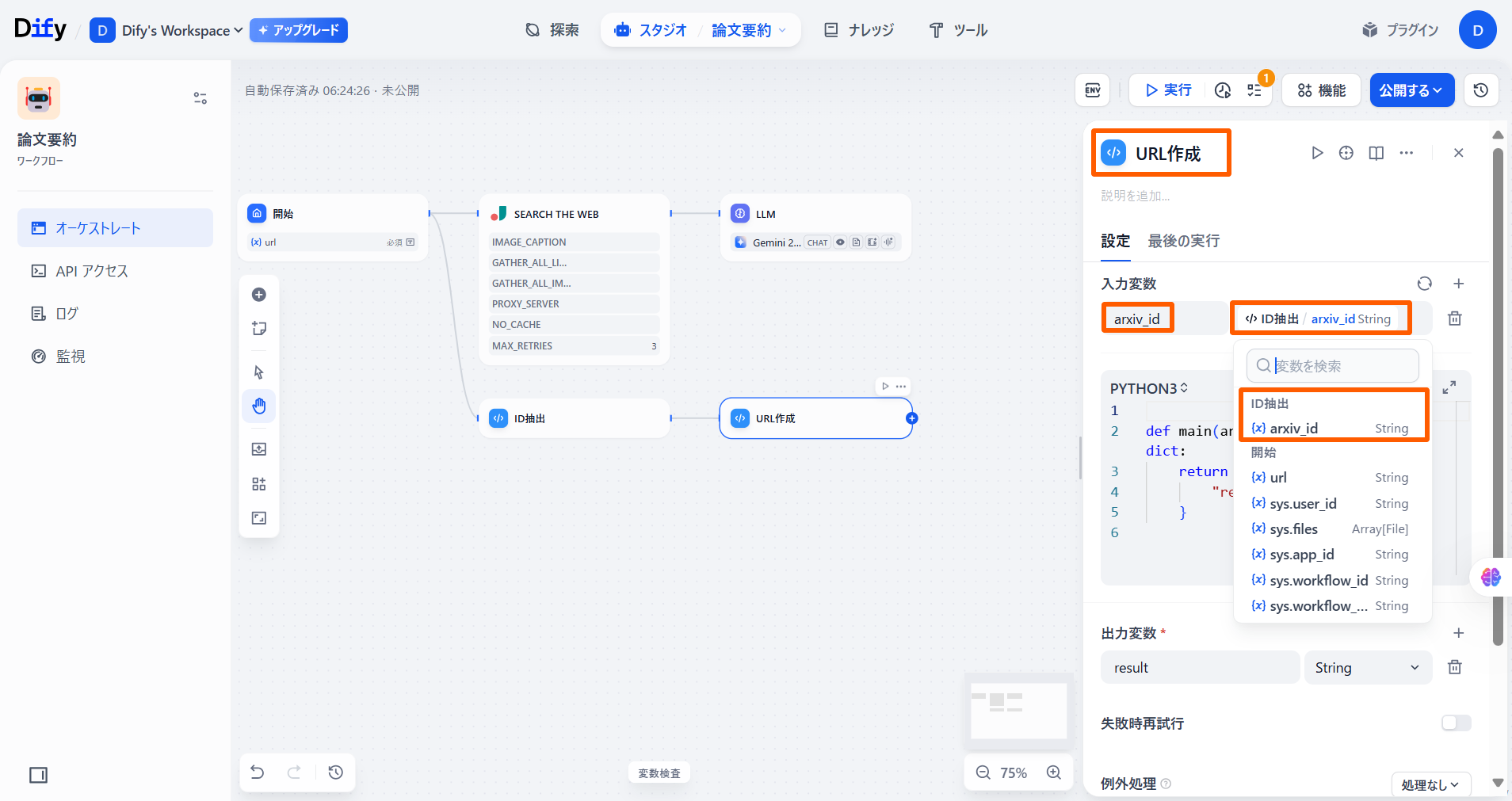 コードブロックに以下のコードを入力します。python
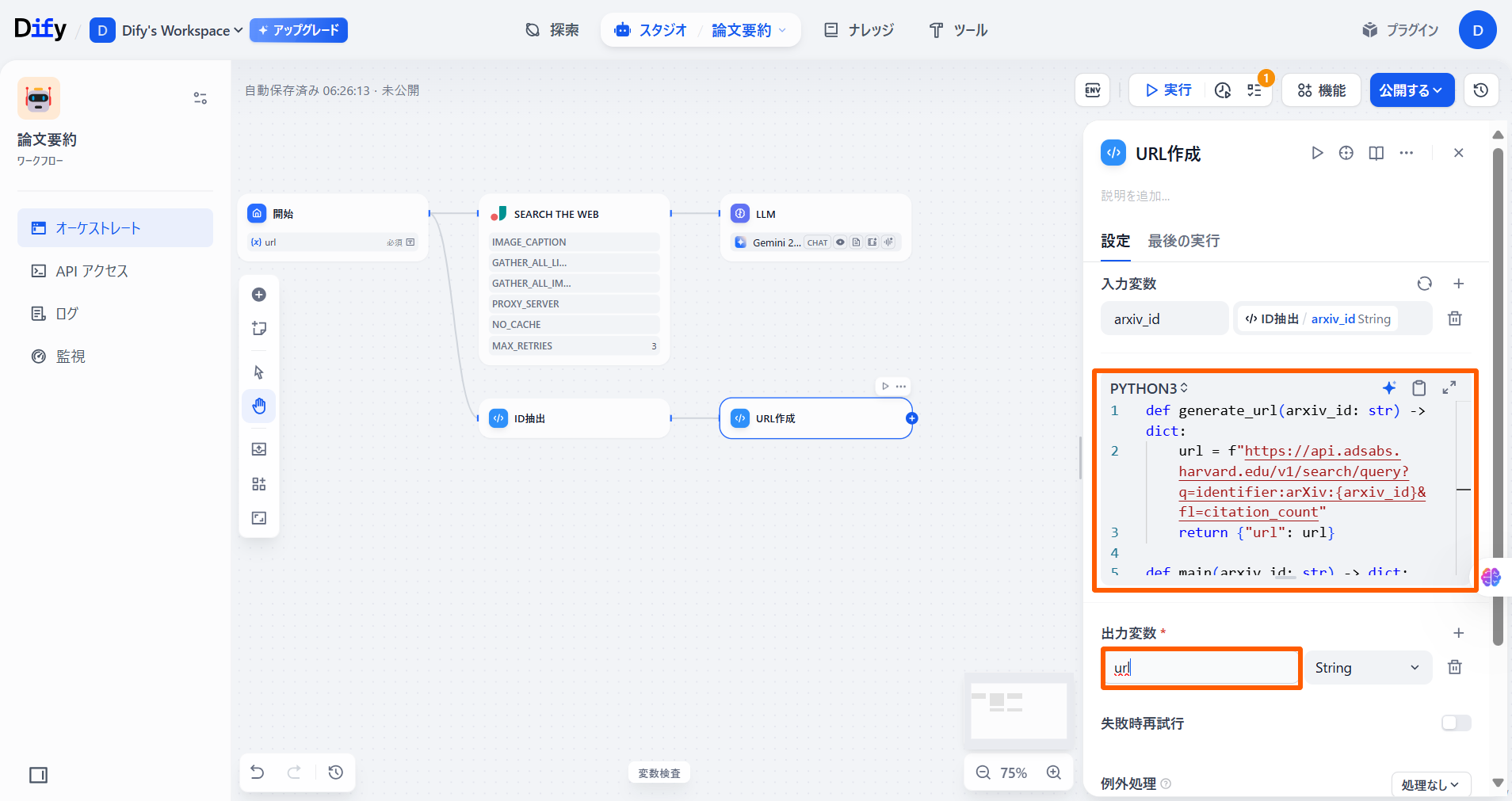
コードブロックに以下のコードを入力します。pythondef generate_url(arxiv_id: str) -> dict: url = f"https://api.semanticscholar.org/graph/v1/paper/arXiv:{arxiv_id}?fields=title,citationCount,publicationDate" return {"url": url} def main(arxiv_id: str) -> dict: return generate_url(arxiv_id)
「出力変数」に「url」と入力します。
-
「コード」ノードの「+」ボタンを押して、**「HTTPリクエスト」**ノードを追加します。
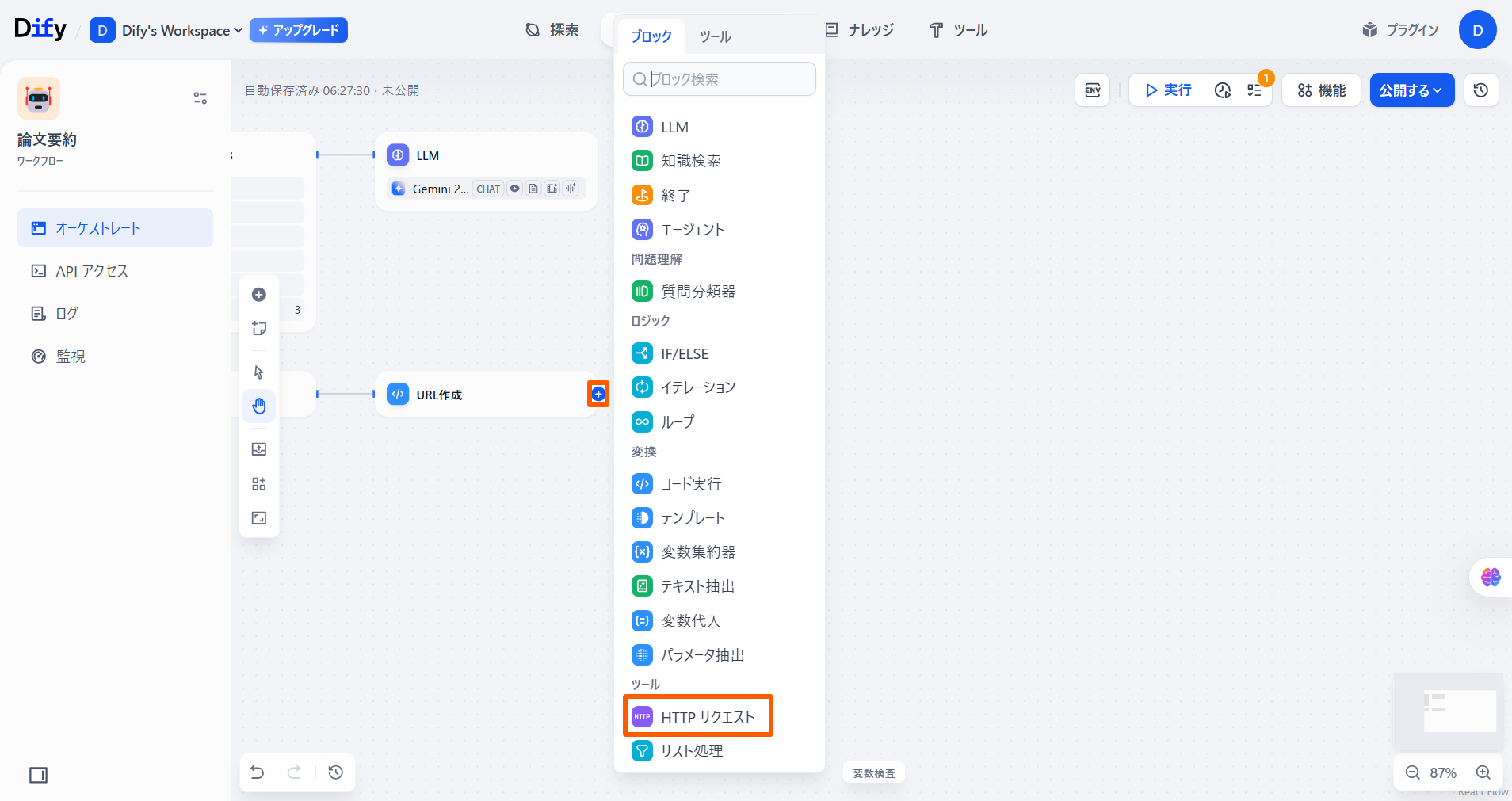 「API」で「GET」を選択します。
右の欄で「/」を入力した後、「URLを作成」の「{X}url」を選択します。
「API」で「GET」を選択します。
右の欄で「/」を入力した後、「URLを作成」の「{X}url」を選択します。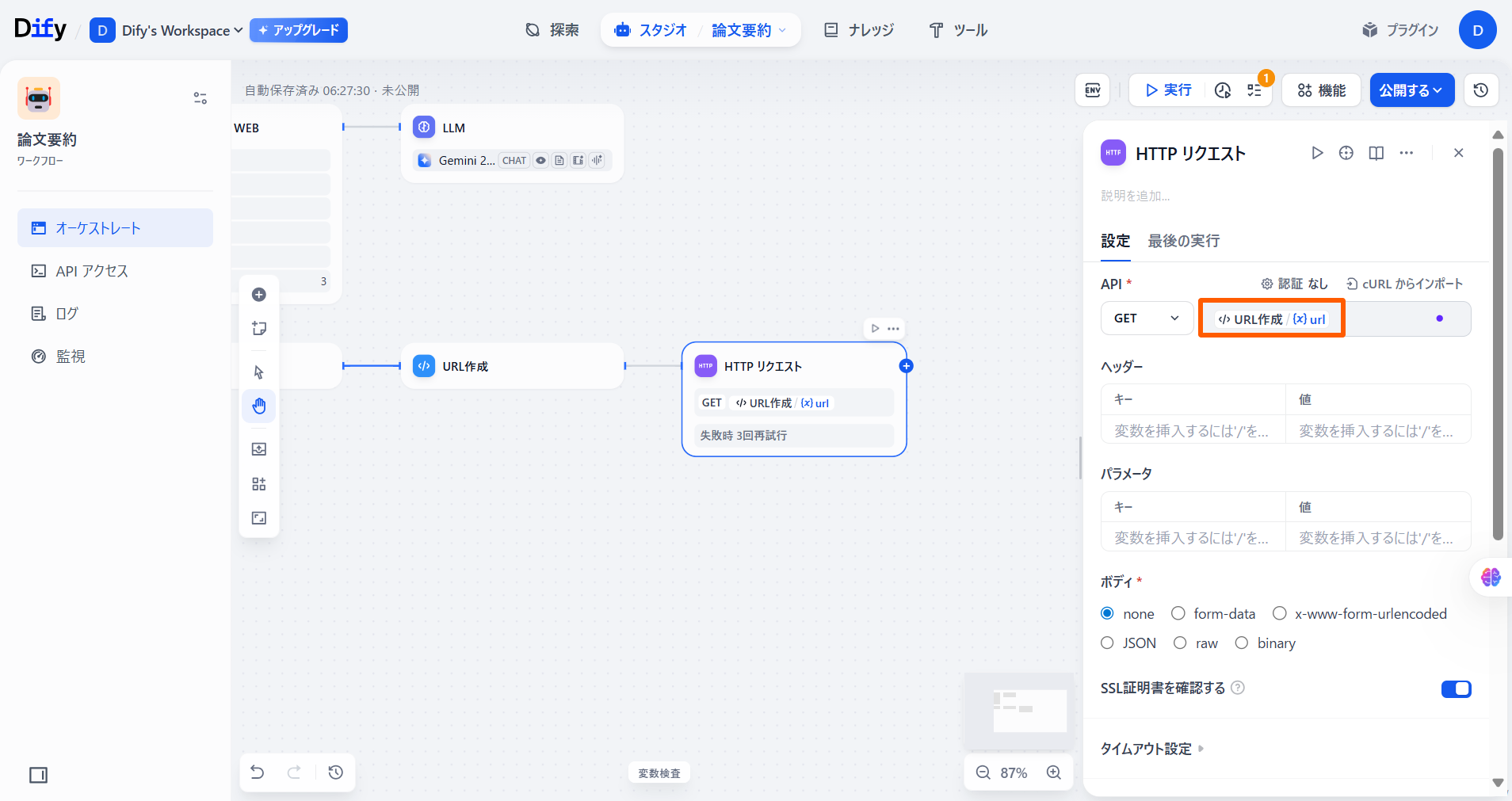 「パラメータ」の値を下記の画像のように設定します。
「パラメータ」の値を下記の画像のように設定します。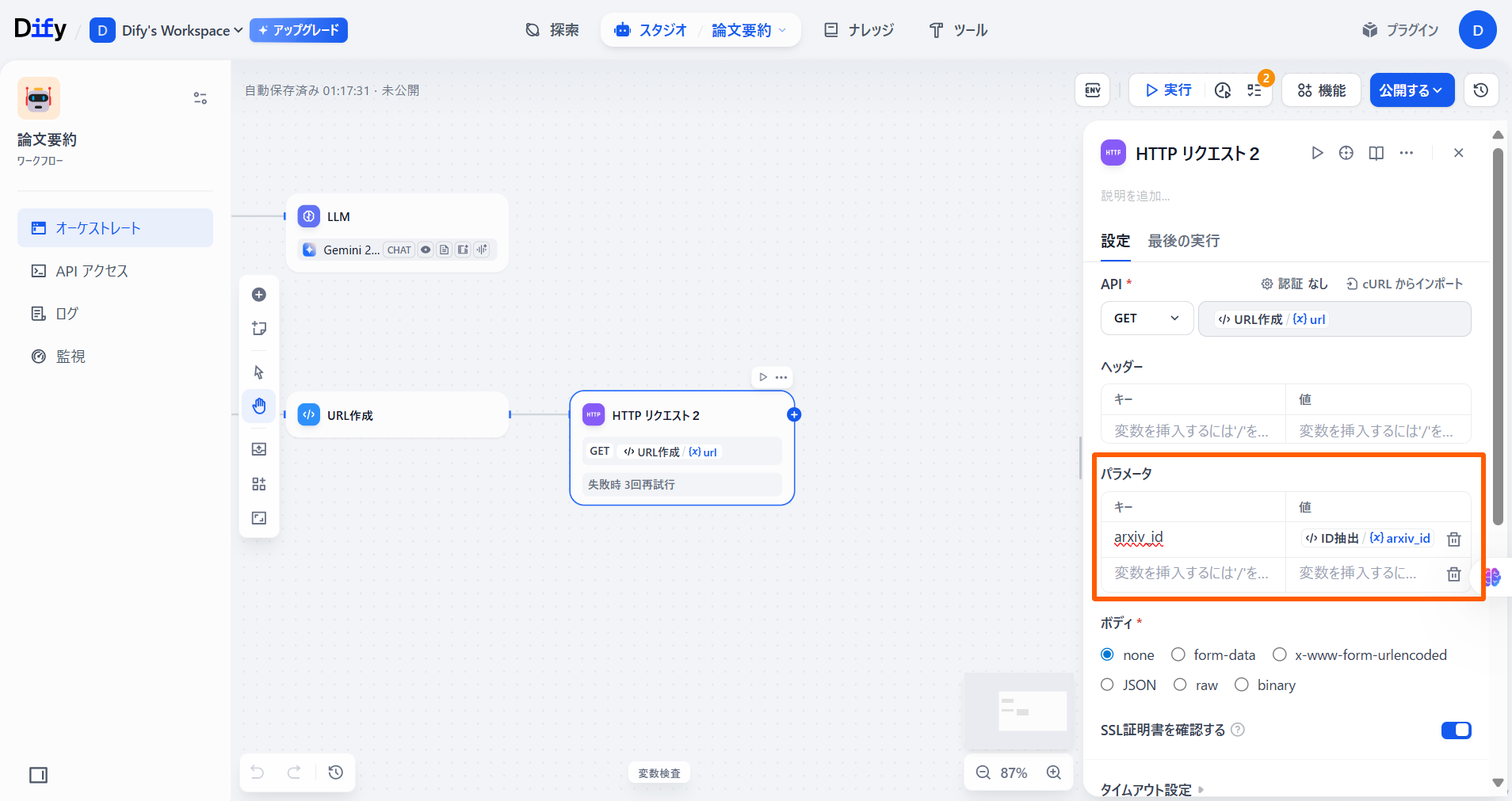 「タイムアウト」の「接続タイムアウト」と「読み取りタイムアウト」にそれぞれ「15」と入力します。
「タイムアウト」の「接続タイムアウト」と「読み取りタイムアウト」にそれぞれ「15」と入力します。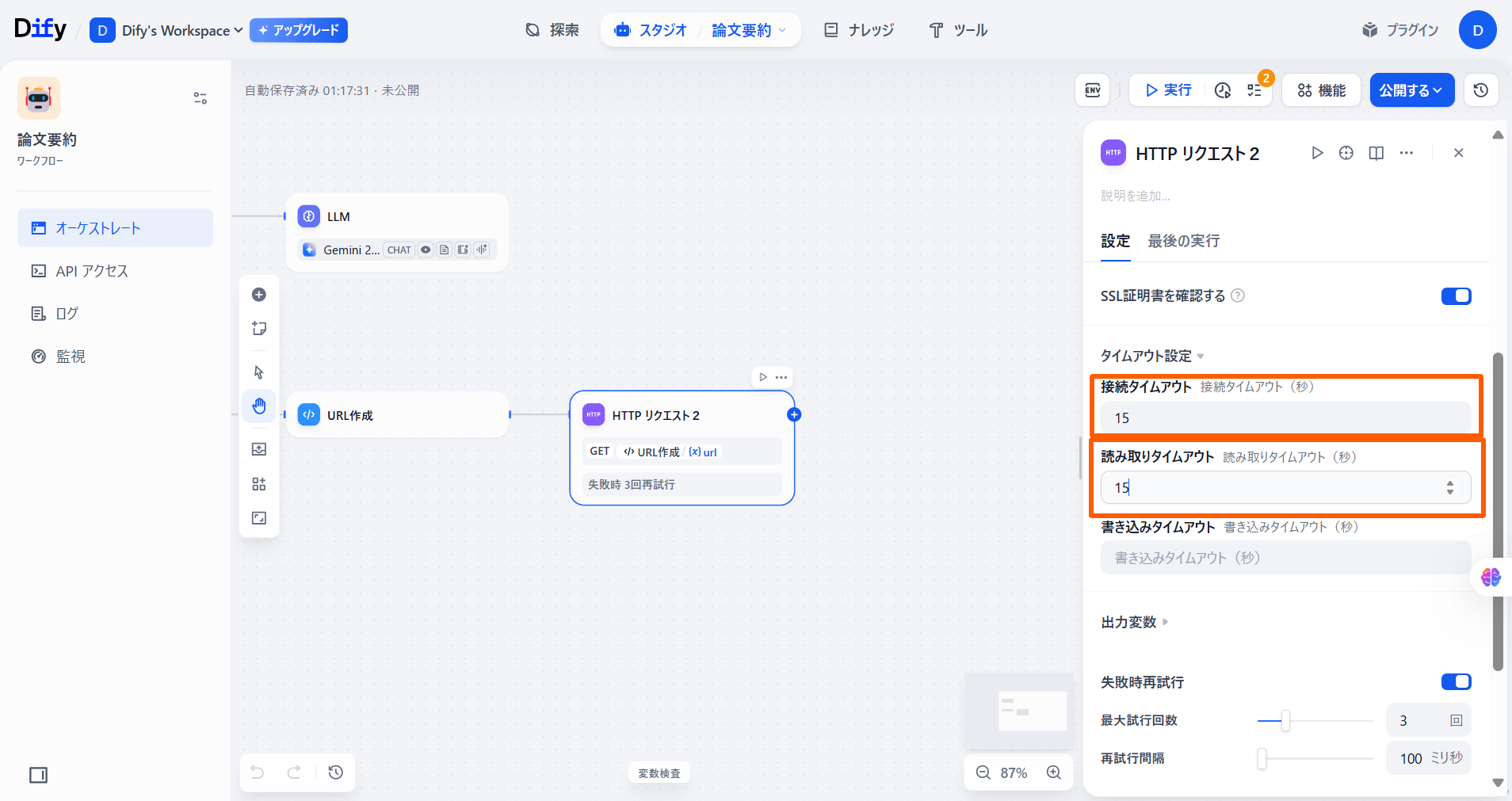
-
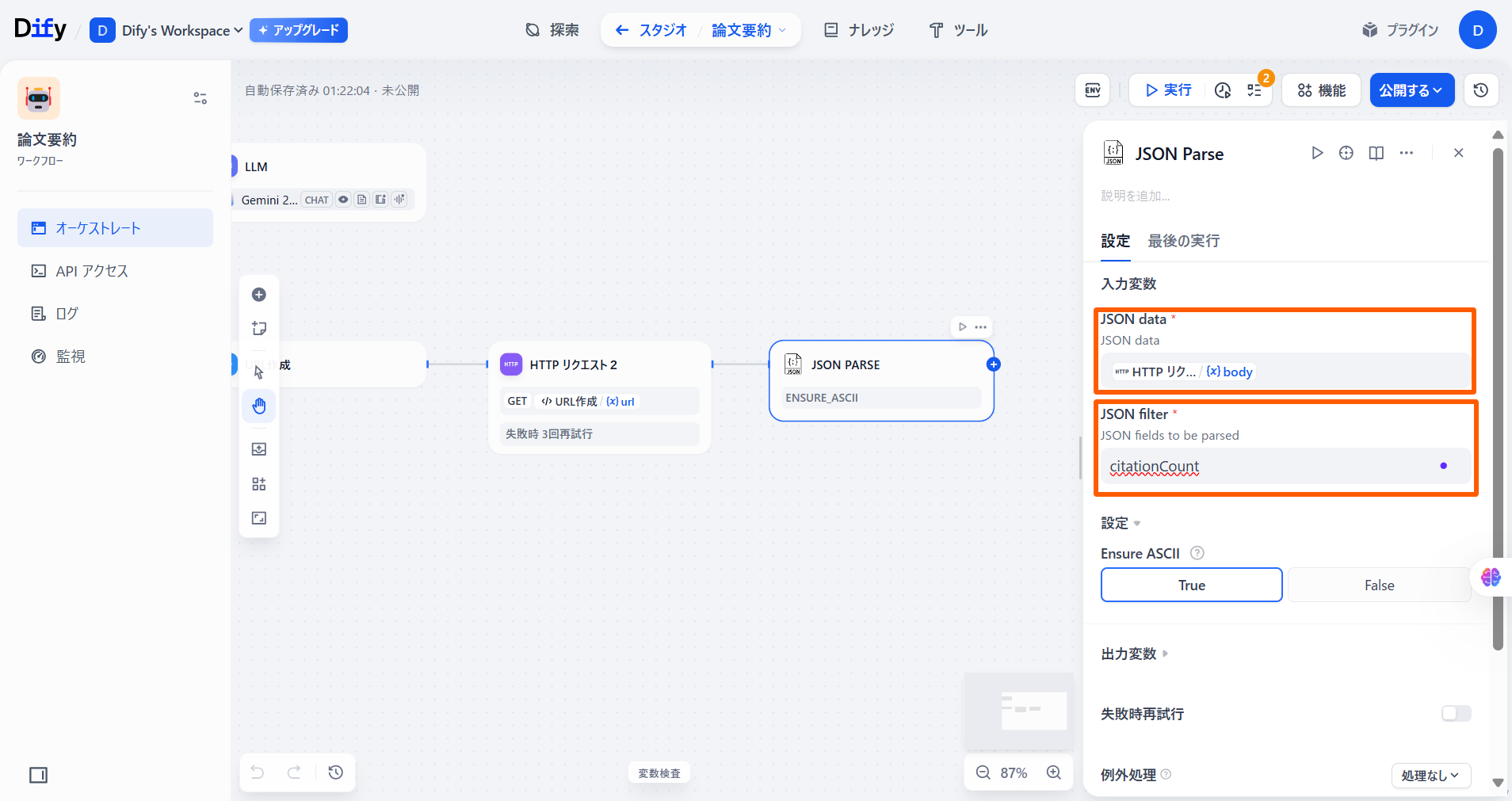
「HTTPリクエスト」ノードを選択し、「+」ボタンを押して「ツール」の**「JSON Parse」**を選択します。
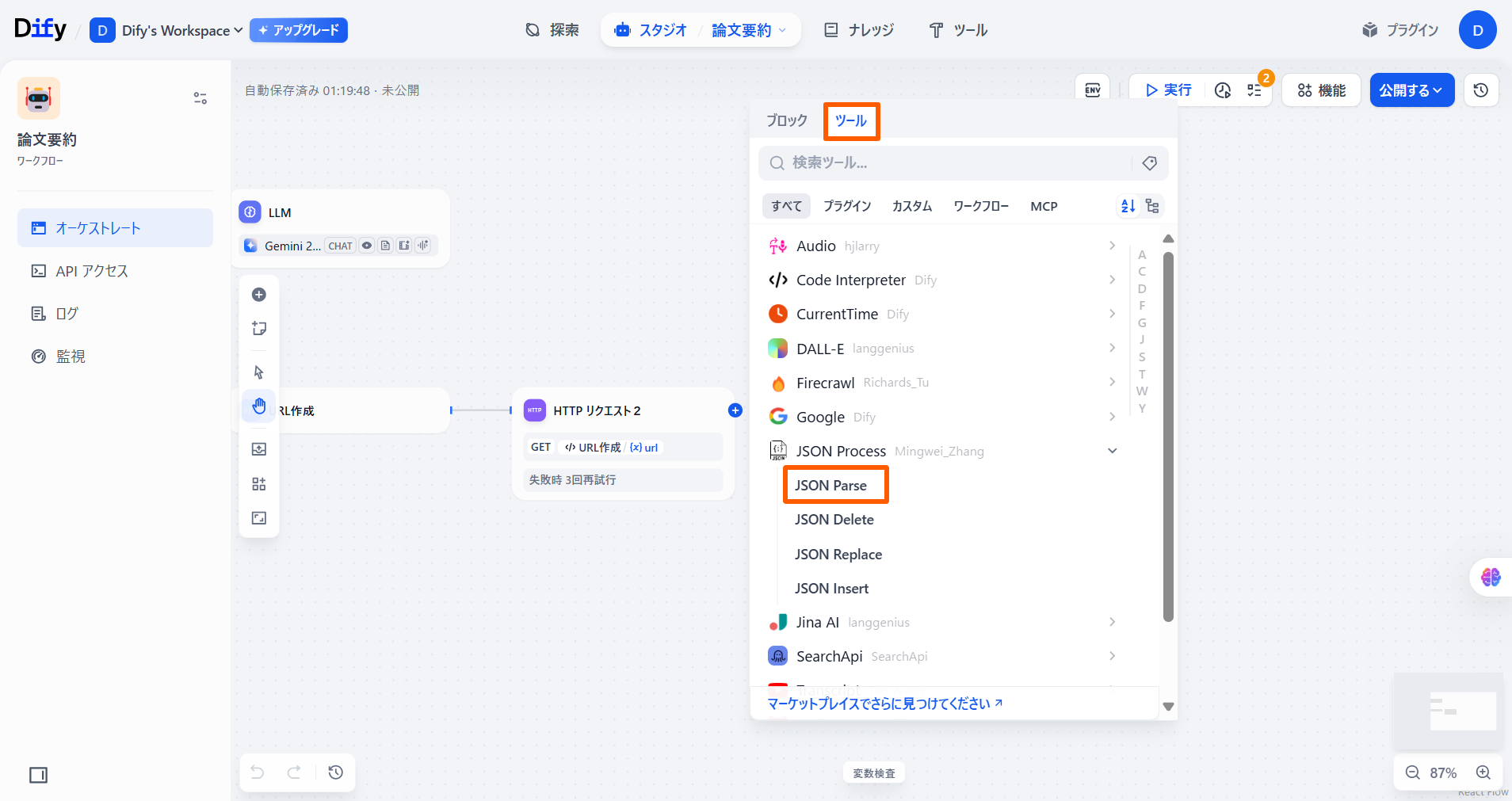 「JSON data」と「JSON filter」の値を下記の表のように設定します。
「JSON data」と「JSON filter」の値を下記の表のように設定します。
| 項目 | 値 | 備考 |
|---|---|---|
| JSON data | {x}body | 「HTTPリクエスト」の「{x}body」を選択 |
| JSON filter | citationCount |
-
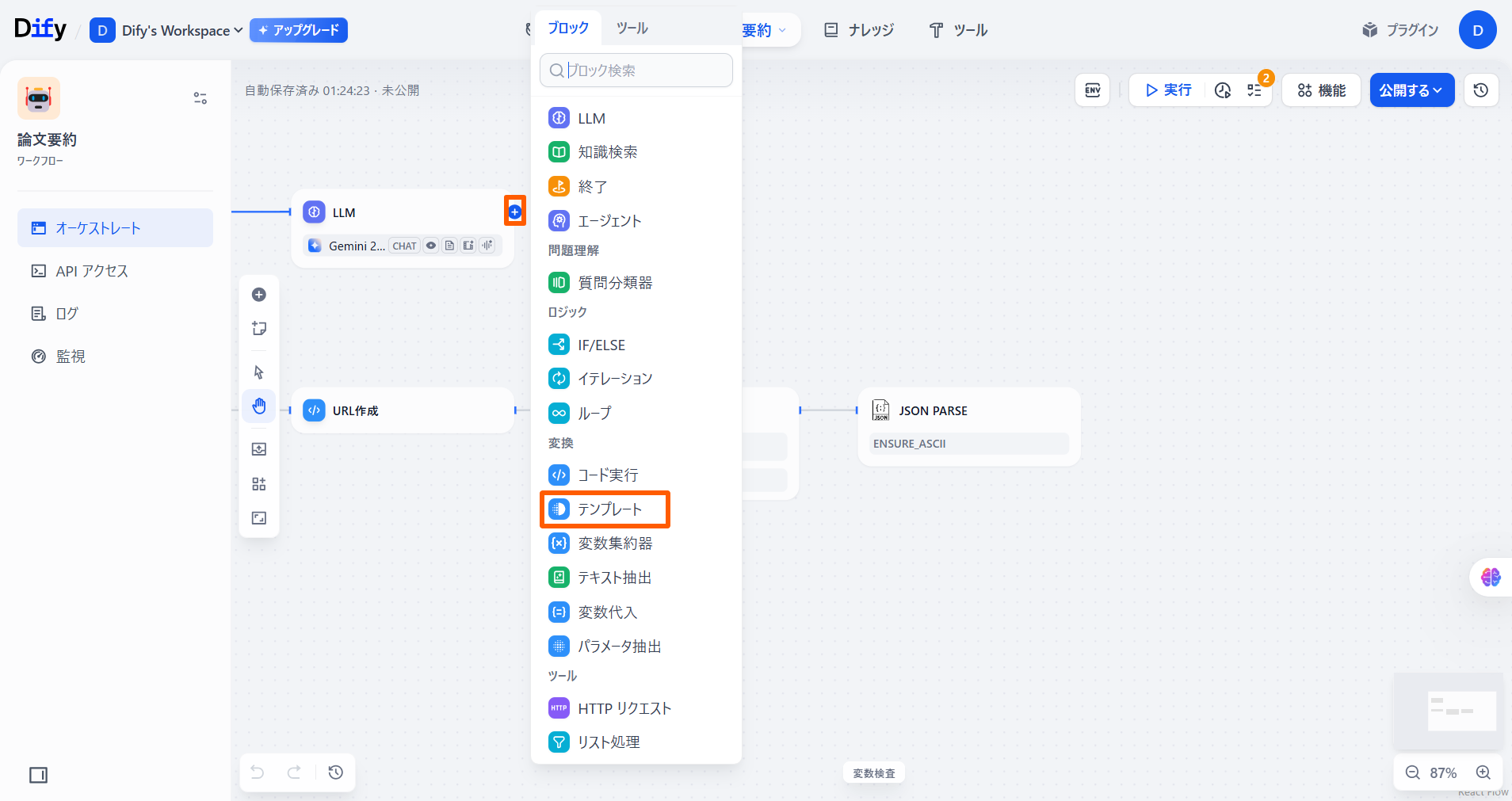
「LLM」ノードの「+」ボタンを押し、**「テンプレート」**を選択します。 「テンプレート」ノードと「JSON Parse」ノードをつなぎます。
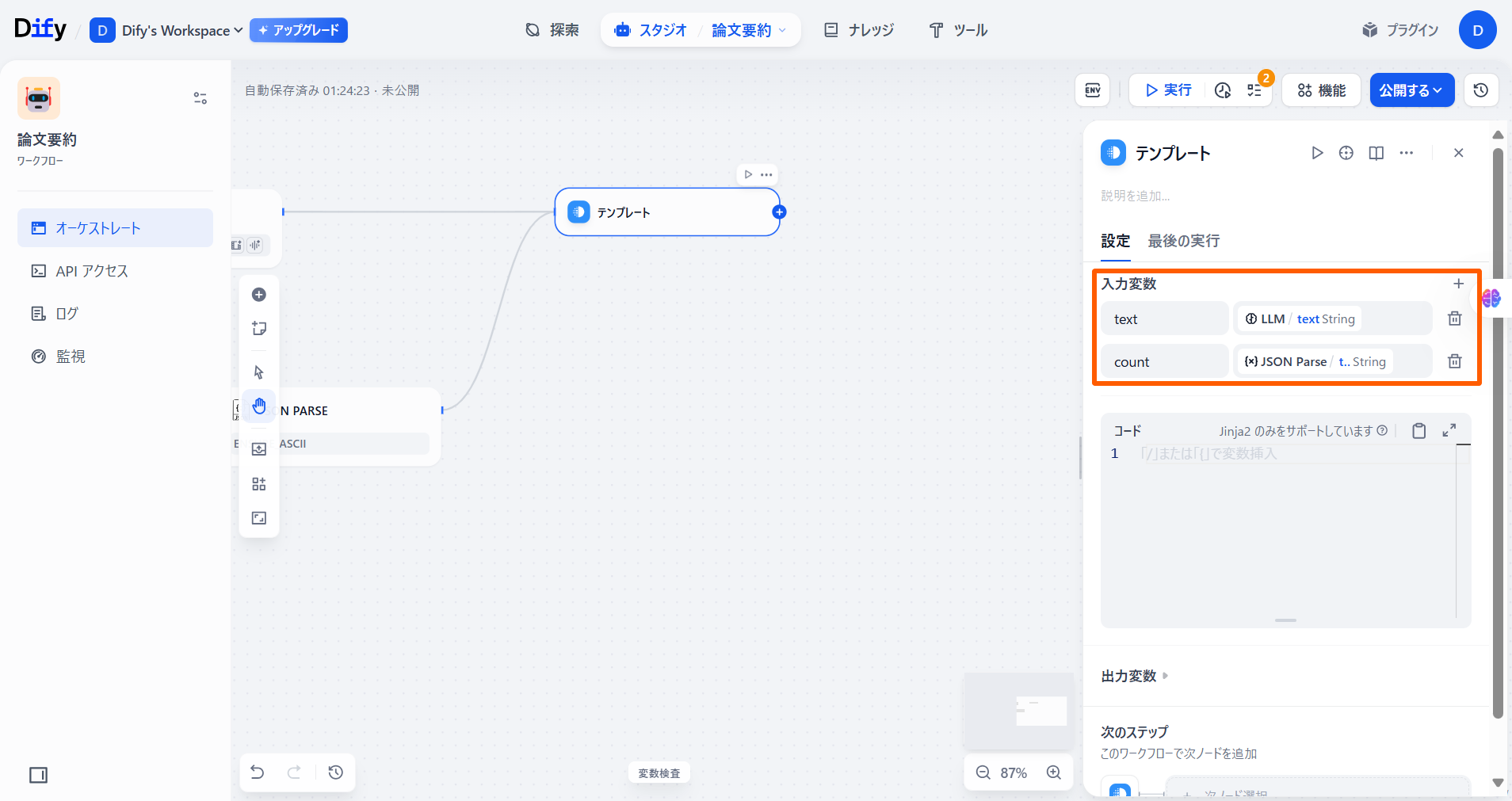
 「入力変数」のフィールドに、下記の表のように変数名と値を設定します。
「入力変数」のフィールドに、下記の表のように変数名と値を設定します。
| 変数名 | 値 | 備考 |
|---|---|---|
| text | {x}text | 「LLM」の「{x}text」を選択 |
| count | {x}text | 「JSON Parse」の「{x}text」を選択 |
 コードブロックに以下のプロンプトを入力します。
コードブロックに以下のプロンプトを入力します。
引用数は{{count}}件です。 要約した内容は以下の通りです。 {{ text }}
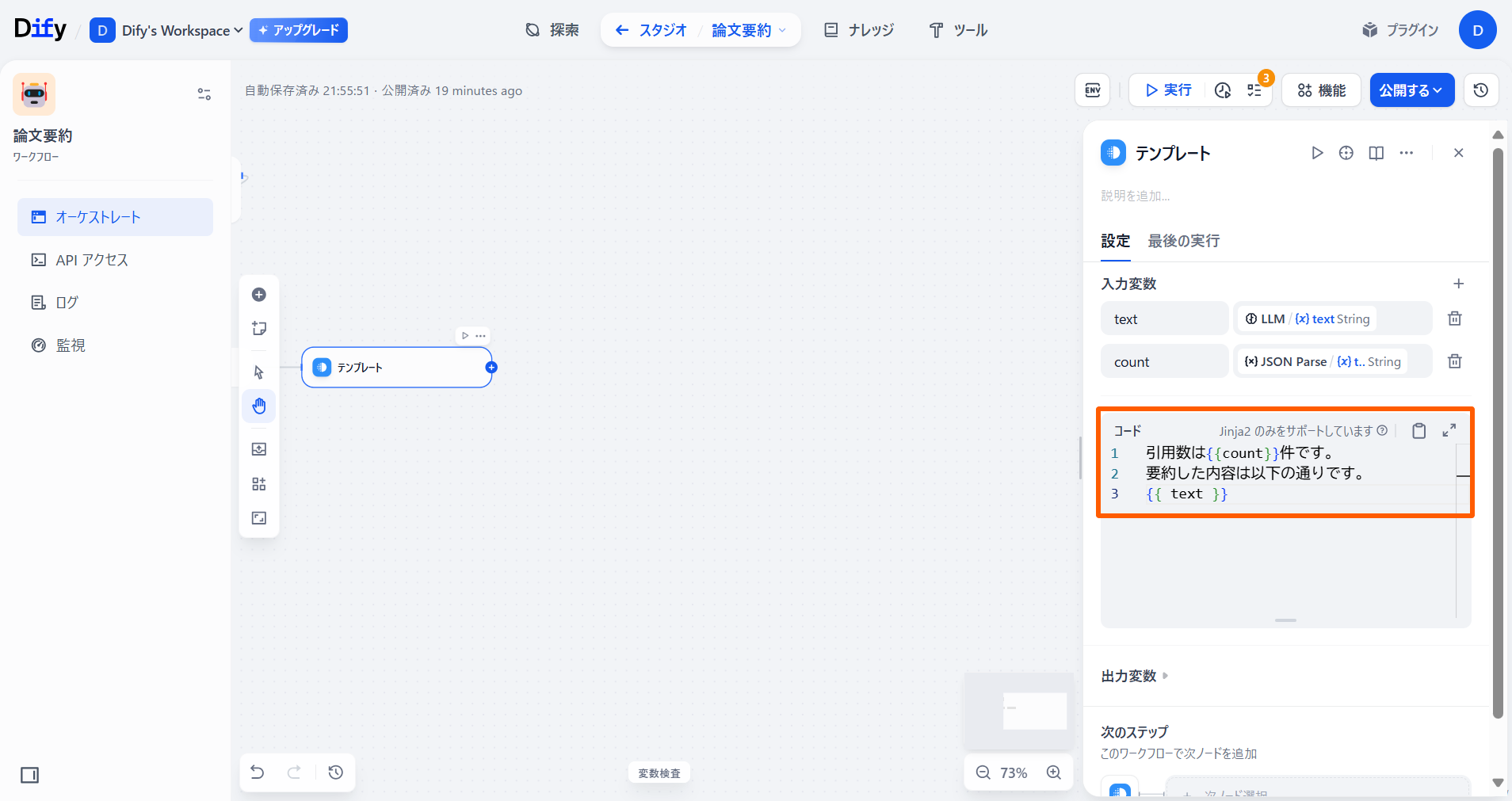
-
「テンプレート」ノードの「+」ボタンを押し、**「終了」**を選択します。
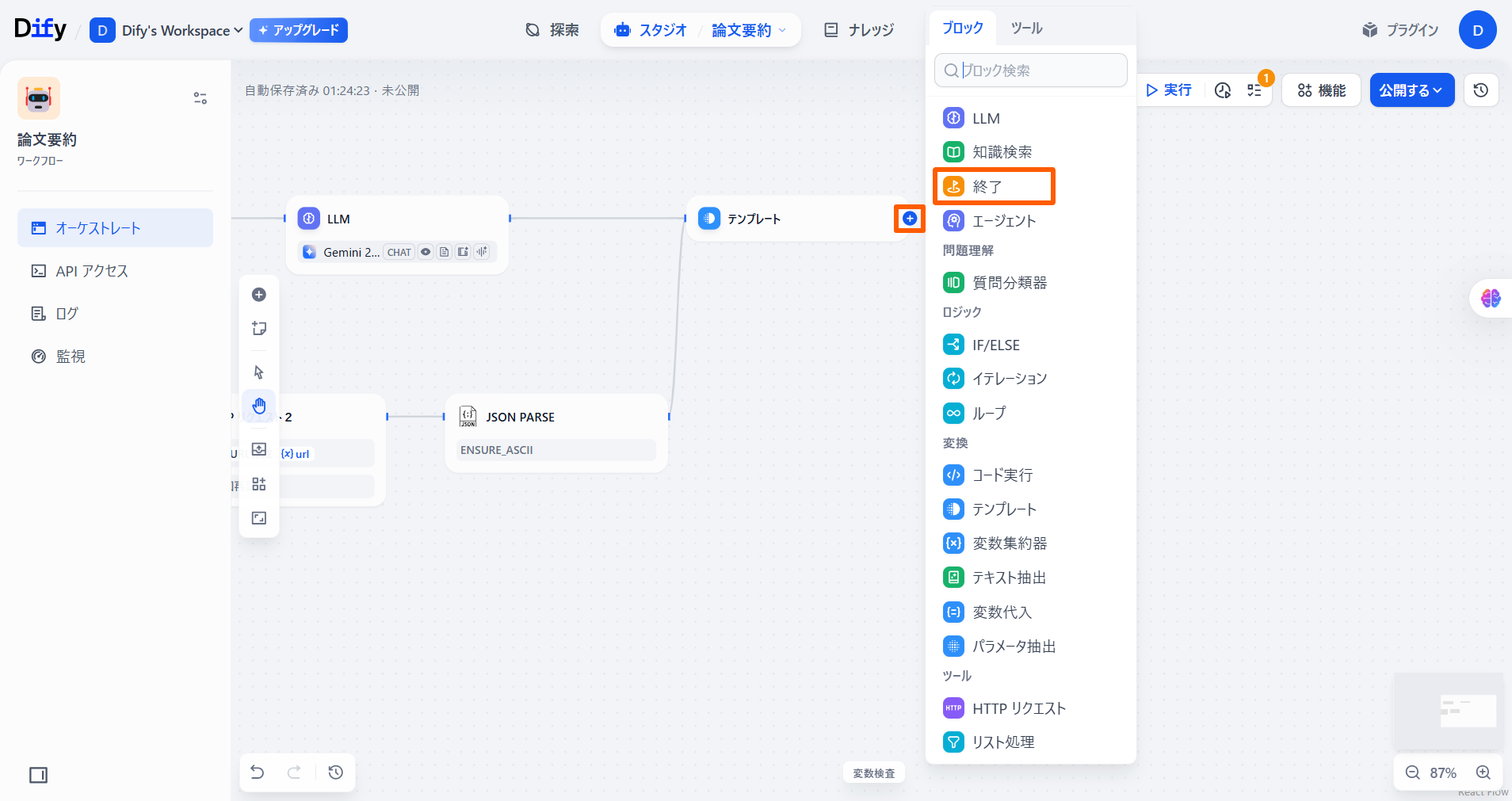 「出力変数」の「変数名」に「output」と入力し、「テンプレート」の「output」を選択します。
「出力変数」の「変数名」に「output」と入力し、「テンプレート」の「output」を選択します。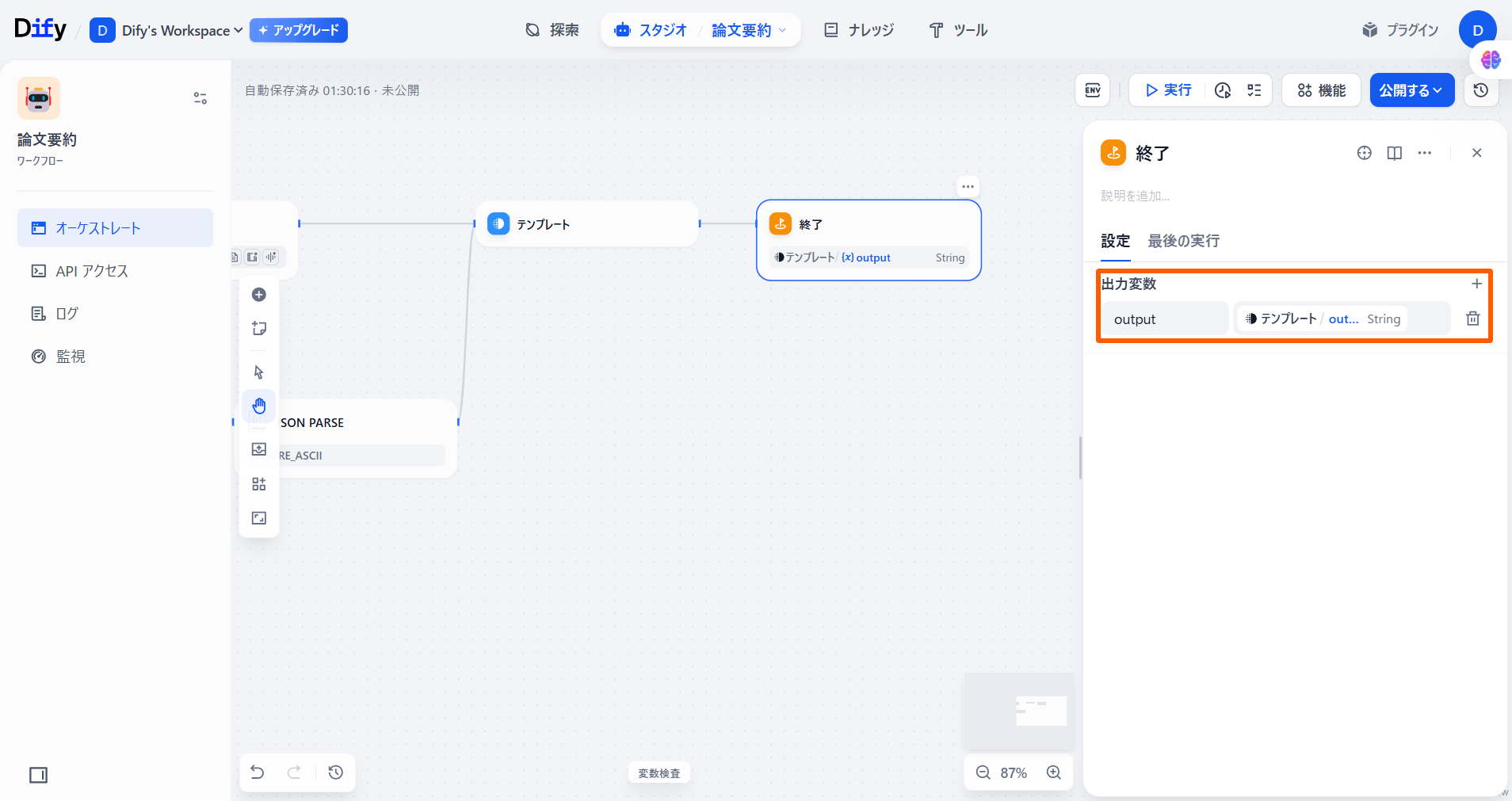 以上でワークフローが完成しました。
以上でワークフローが完成しました。
3. ワークフローの動作確認
-
「公開する」を選択し、「アプリを実行」を選択します。
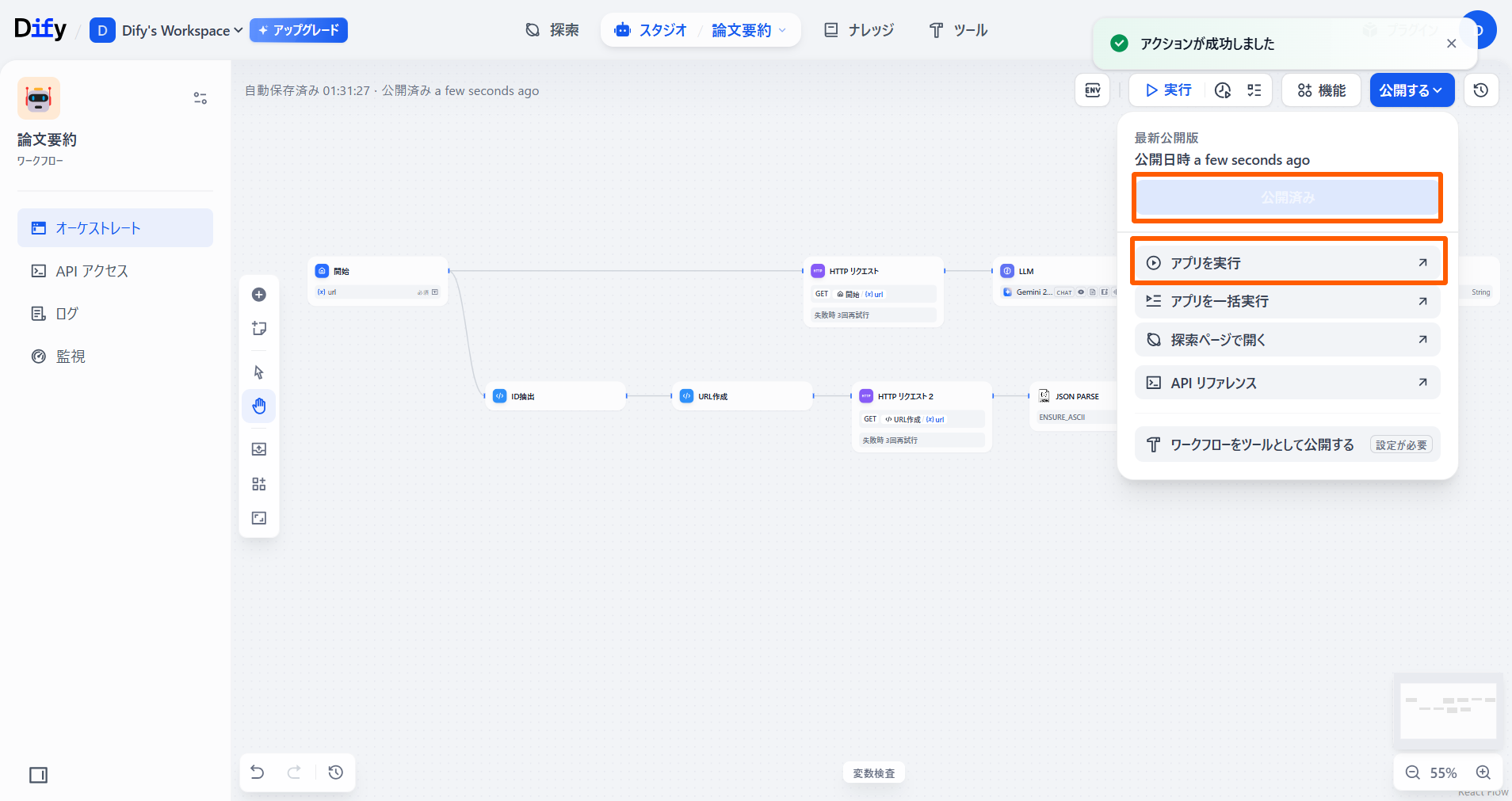 アプリを実行します。
アプリを実行します。 -
右側に論文の引用数と要約が表示されました。 (HTTPリクエストでエラーが起こることがたまにあります。そのような際何回かアプリ実行をやり直してみてください。)
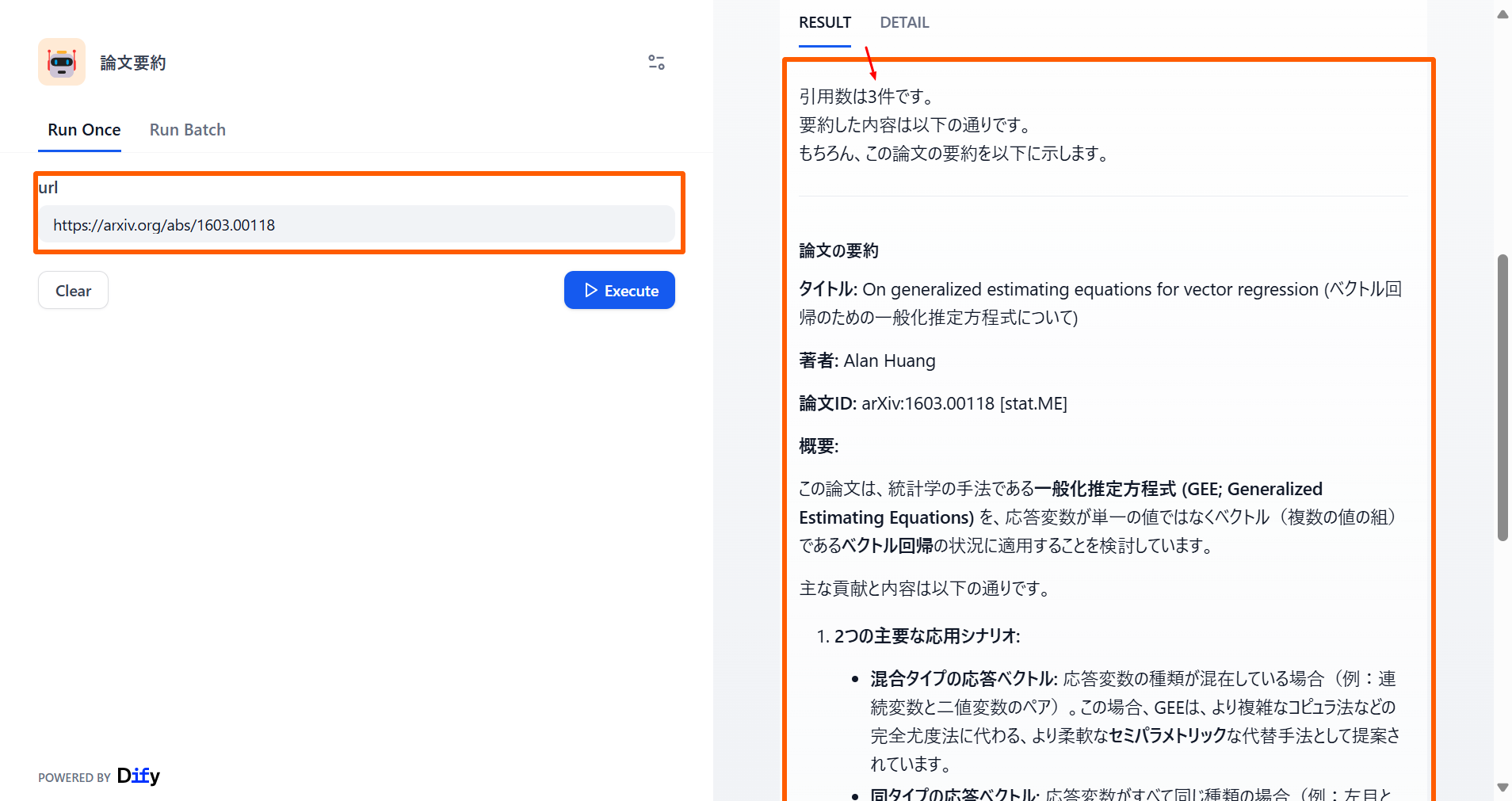
応用
今回は、DifyのUI(画面)上で論文の引用数と要約が返ってくるものを作成しましたが、Slackと連携することで、チャンネルにURLを入力して出力結果を得ることもできます。
おわりに
今回の記事では、arXivから特定の論文を要約しその論文の引用数も取得するワークフローの作成手順を紹介しました。今後もDifyを利用したアプリの作成手順を紹介していきます。ぜひ引き続きご覧下さい。
