はじめに
チャットで「今月の売上を教えて」と入力するだけで、自動的にグラフが出てきたら便利だと思いませんか?
本記事では、**MCP(Model Context Protocol)**と **Claude Desktop **を組み合わせて、mcp-bigquery-server を使い、BigQuery のデータを自然言語で取得・可視化する方法をわかりやすく紹介します。
MCP(Model Context Protocol)とは Claude Desktop と BigQuery を連携する際に、中心的な役割を担うのが MCPサーバー です。 MCPは、アプリケーションと大規模言語モデル(LLM)を標準化された方法でツールやデータソースに接続するためのオープンプロトコルです。 例えると、MCPはAIのためのUSB-Cポートのようなものです。USB-Cが1つの規格でさまざまなデバイスをつなぐように、MCPはLLMをBigQueryやNotion、Slackなどのツールに簡単につなぐことができます。
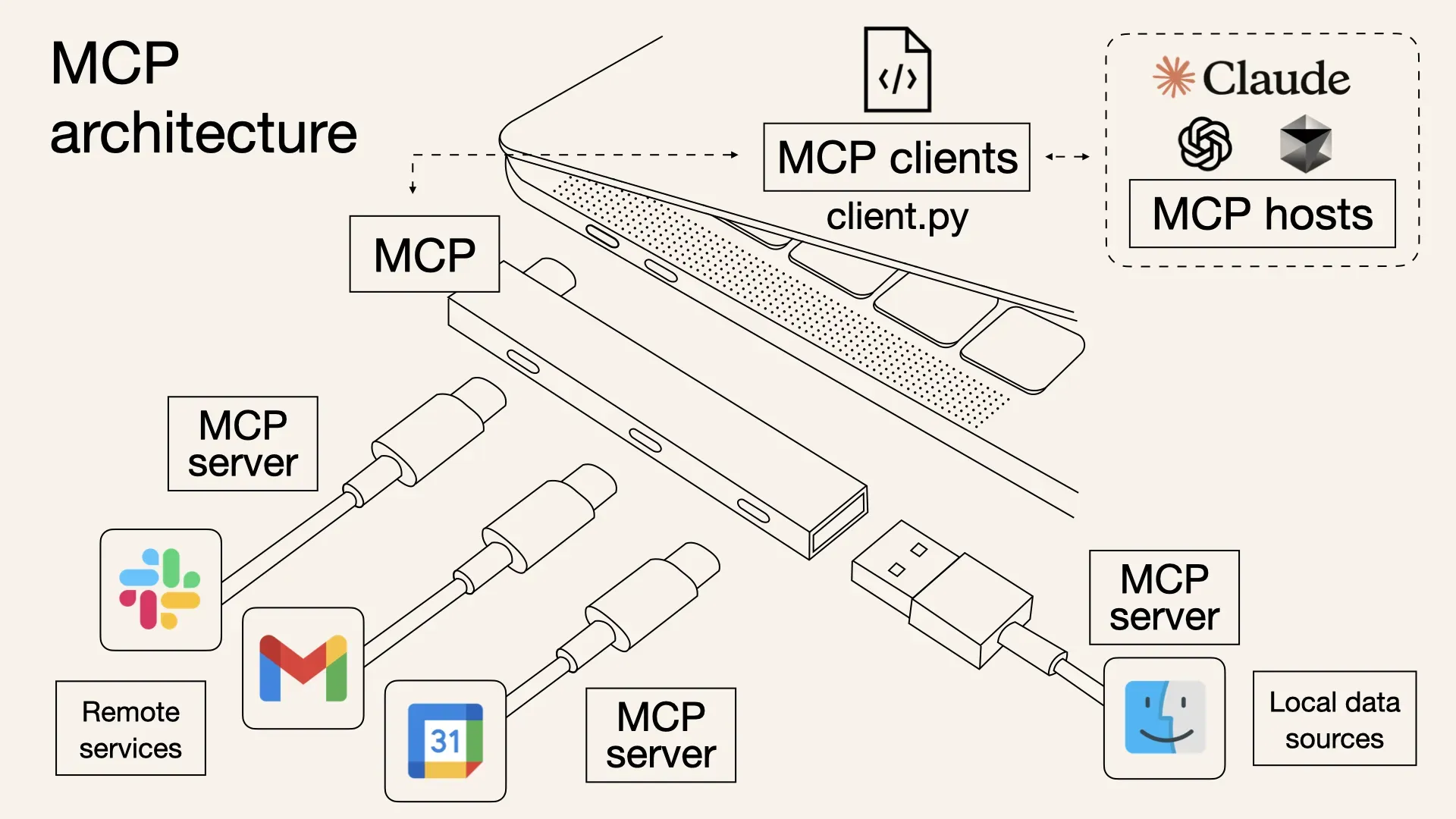
概要
Claude Desktop から BigQuery にクエリを投げて結果を可視化できるようになると、チャットで以下の操作が簡単に行えます。
- 「今月の売上は?」→自動で SQL 実行
- 「グラフで見せて!」→棒グラフ・折れ線グラフに一発切り替え
環境
- macOS 15.5 Sonoma
- Node.js v22.14.0
- Claude Desktop
事前準備
-
Claude Desktop のダウンロード&起動 こちらのサイトからダウンロードしてください。
-
mcp-bigquery-server をクローン 任意のローカルフォルダにmcp-bigquery-serverリポジトリをクローンしてください。
bashgit clone https://github.com/ergut/mcp-bigquery-server.git ~/mcp-bigquery-server cd ~/mcp-bigquery-server npm install npm run build -
Google Cloud サービスアカウントの作成
-
Google Cloudのプロジェクトを作成します。
-
サービスアカウントの作成と、クレデンシャルキーの取得をします。
-
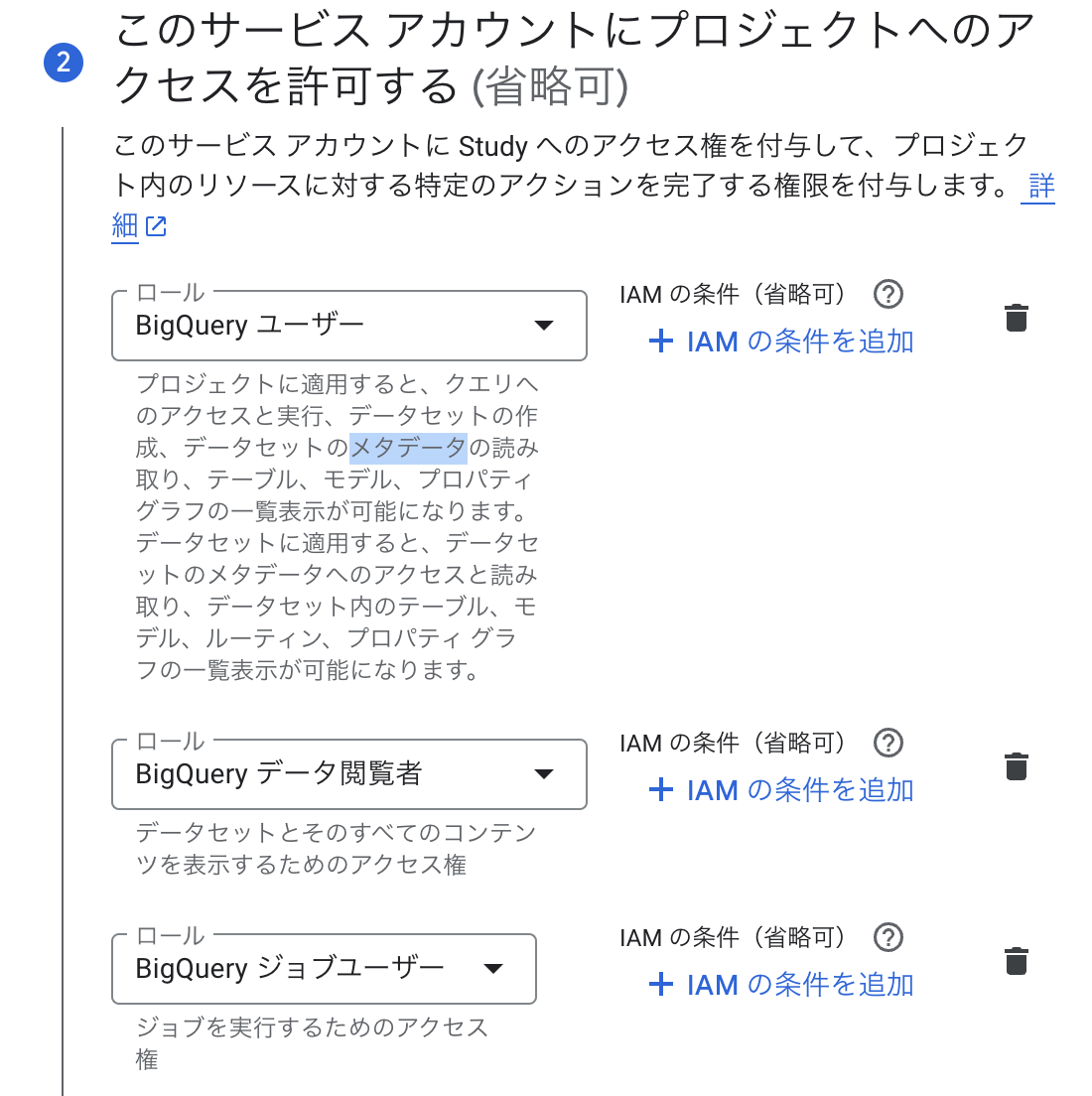
サービスアカウントの作成ページで、以下の権限を持ったサービスアカウントを作成してください。
roles/bigquery.userroles/bigquery.dataViewerroles/bigquery.jobUser
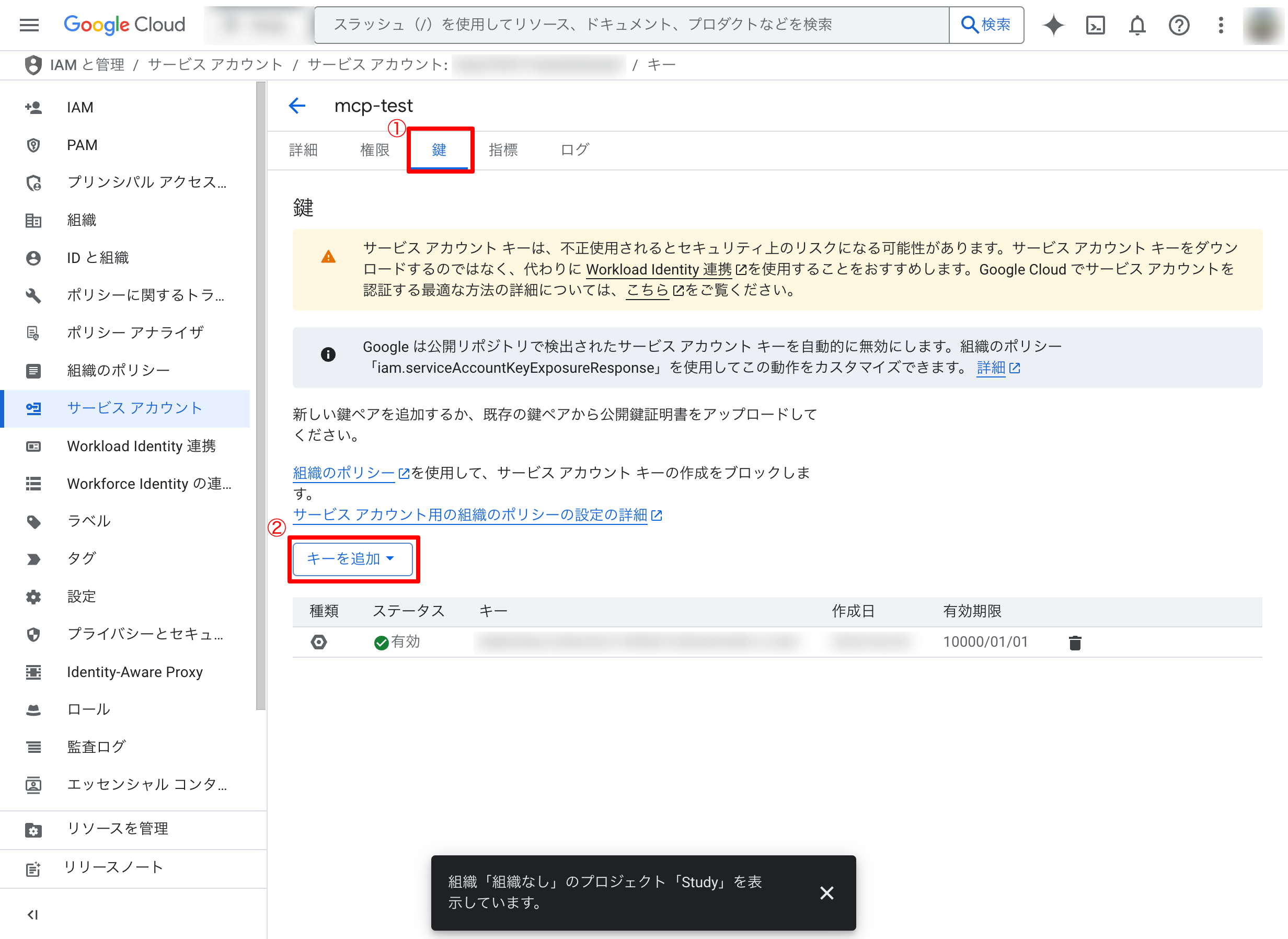
- 作成したサービスアカウントを選択した後、「鍵」の「キーを追加」から「新しい鍵を作成」を選択します。キーのタイプはJSON形式です。作成後、ダウンロードし、先ほどクローンしたリポジトリのルートディレクトリに配置します。
作業手順
ここからは、環境構築と事前準備が整ったところで、下記の手順で実際に手を動かして「BigQueryへのデータ作成」→「Claude Desktop へのMCP登録」→「クエリ実行&可視化」までを順に説明します。
- BigQuery にデータを作成する
- Claude Desktop の設定
- クエリの実行と可視化
1. BigQuery にデータを作成する
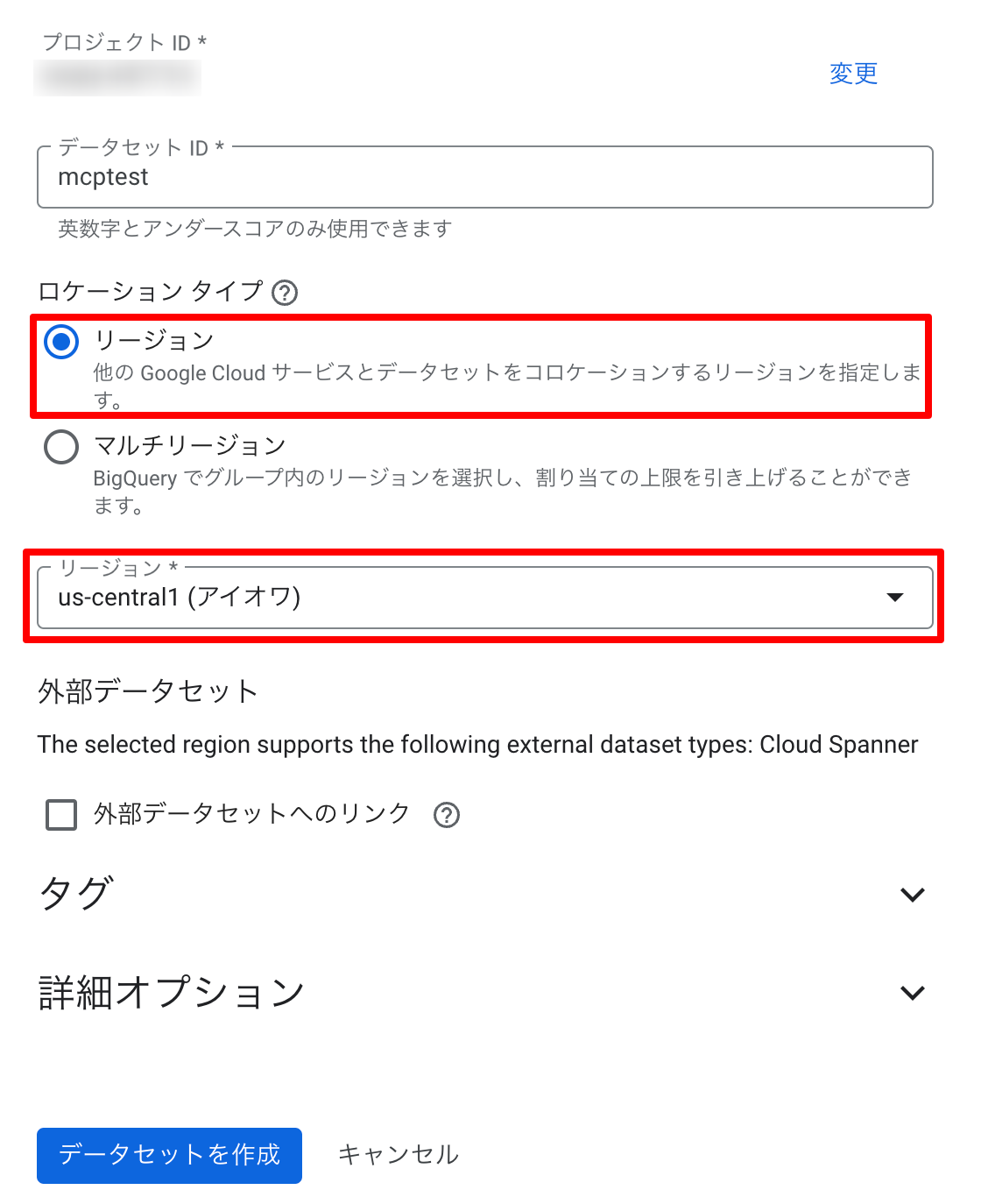
- Google Cloud のコンソールでデータセットを作成します。
- ローケーションタイプ:「リージョン」を選択
- リージョン:「us-central1」を選択
注意
今回使用した mcp-bigquery-server は、現時点では us-central1 リージョンにあるデータセットのみ接続可能でしたが、将来的には US やその他のリージョンへの対応も期待されます。
-
今回MCPで操作するサンプルデータを作ります。 BigQueryで以下のクエリを実行してください。
sql-- テーブル作成(プロジェクトID・データセットIDは適宜置き換えてください) CREATE OR REPLACE TABLE `your-project-id.your_dataset_id.monthly_sales` (
month STRING, sales_amount INT64 );
-- データ挿入
INSERT INTO your-project-id.your_dataset_id.monthly_sales (month, sales_amount)
VALUES
('2024-01', 10000),
('2024-02', 15000),
('2024-03', 12000),
('2024-04', 17000),
('2024-05', 18000),
('2024-06', 16000),
('2024-07', 20000),
('2024-08', 19500),
('2024-09', 21000),
('2024-10', 23000),
('2024-11', 22000),
('2024-12', 25000);
1. 「プレビュー」を選択しテーブルが作成されていることを確認します。
以下のようにデータが作成されてればOKです。

## 2. Claude Desktop の設定
1. Claude Desktop からMCPサーバーとの接続を設定します。
Claude Desktop の設定画面を開き、「開発者」タブの「構成を編集」ボタンを選択したあと、`claude_desktop_config.json` ファイルを開きます。

1. ファイルに以下の内容を追加します。
```json
{
"mcpServers": {
"bigquery": {
"command": "node",
"args": [
"/path/to/your/clone/mcp-bigquery-server/dist/index.js",
"--project-id",
"your-project-id",
"--location",
"us-central1",
"--key-file",
"/path/to/service-account-key.json"
]
}
}
}
| project-id | プロジェクトのID |
|---|---|
| project-id | プロジェクトのID |
| location | デーセットのリージョン |
| key-file | 取得したサービスアカウントのJSONファイルのファイルパス |
-
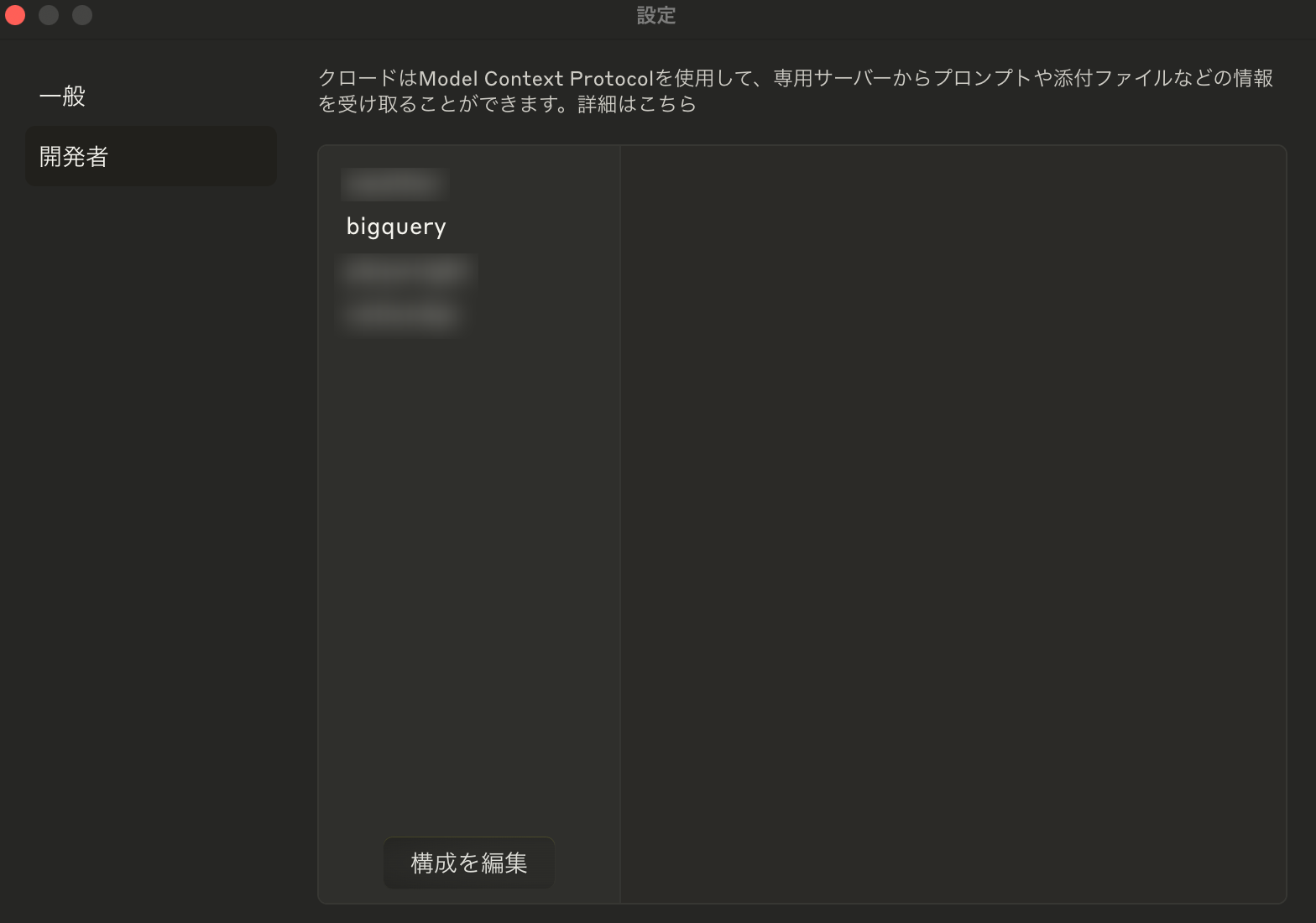
Claude Desktop と BigQuery との接続の確認をします。 Claude Desktop アプリを再起動し、設定画面の「開発者」タブに「bigquery」が追加されているか確認します。
-
Claude Desktop で、「接続されているプロジェクトを教えて」と質問して動作を確認します。
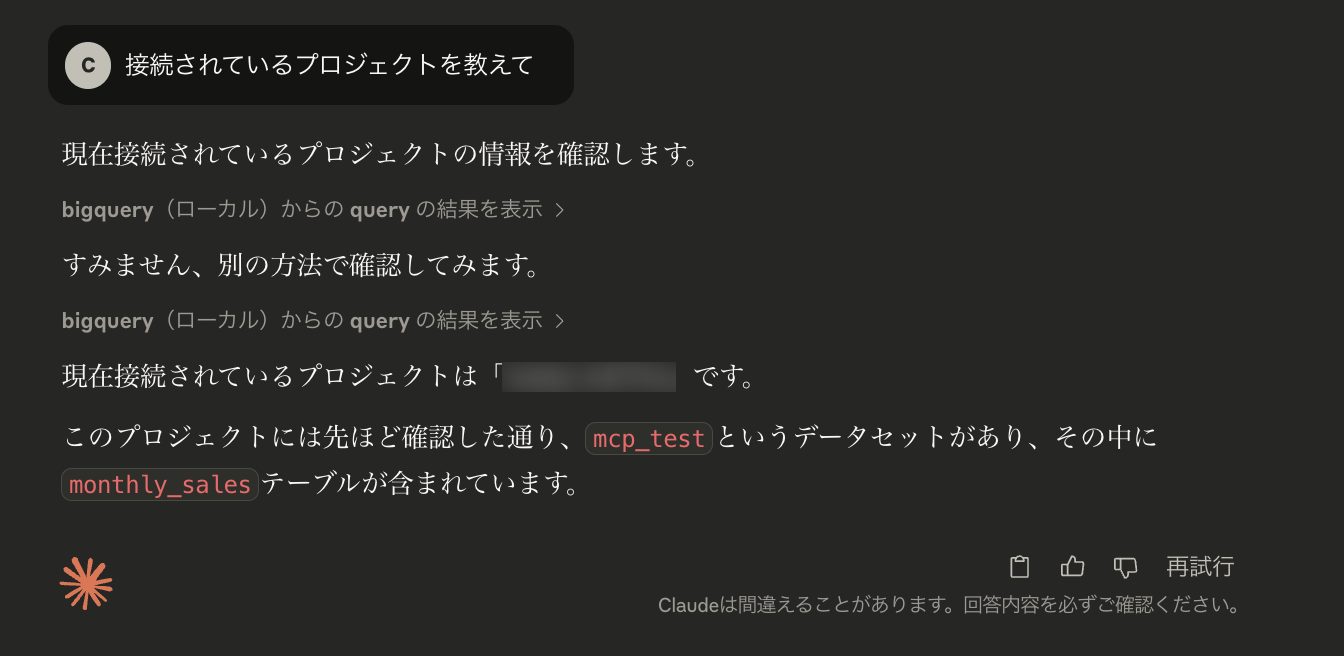 接続されているプロジェクトと、データセットの情報を得ることができ、接続が確認できました。
接続されているプロジェクトと、データセットの情報を得ることができ、接続が確認できました。
3. クエリの実行と可視化
-
まず基本の質問をしてみます。
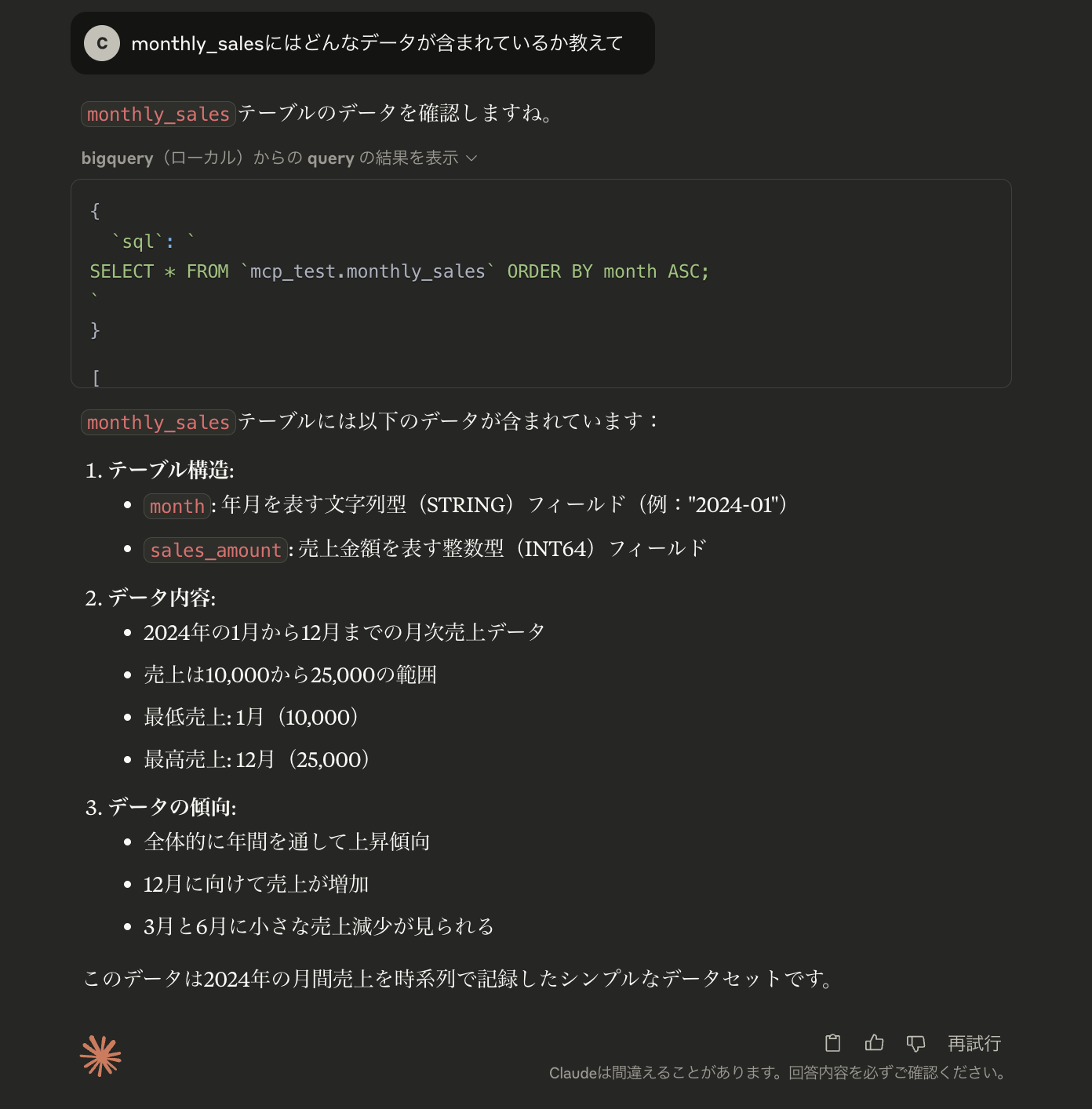
monthly_salesにはどんなデータが含まれているか教えて
と送信すると、SQL文が実行され、monthly_salesテーブルの情報を取得できました。
-
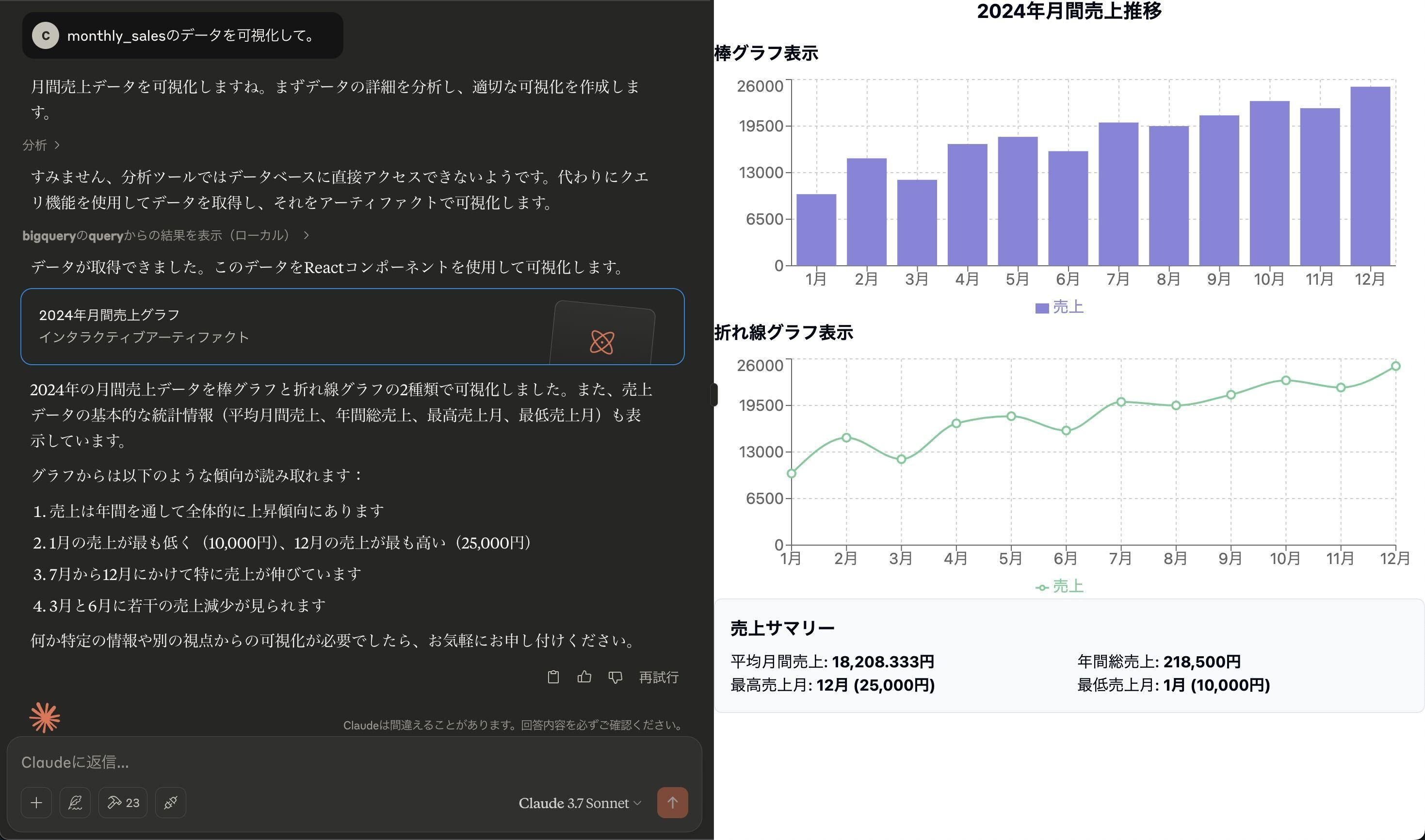
次に、グラフ作成依頼の質問をしてみます。
「monthly_salesのデータを可視化して。」
monthly_sales の情報を棒グラフを折れ線グラフで可視化した結果を得ることができました。
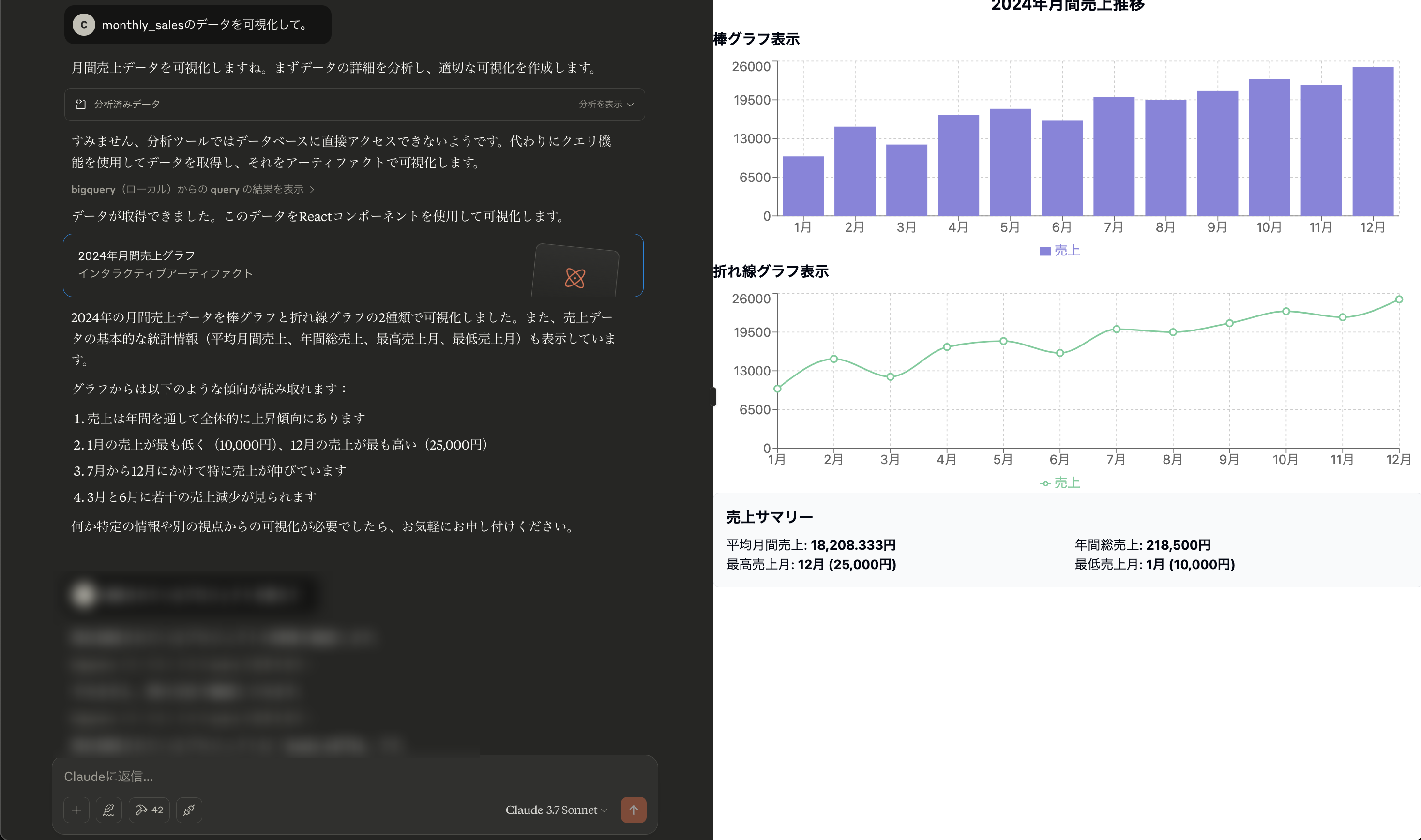 実際にチャットすると、「SQL文作成」→「クエリ」→「グラフ描画」まですべて自動で実行してくれて、非常に便利です。
実際にチャットすると、「SQL文作成」→「クエリ」→「グラフ描画」まですべて自動で実行してくれて、非常に便利です。
おわりに
現状は us-central1 のみ対応で、日本国内や他リージョンのプロジェクトでは使いづらいですし、未検証ですがJOIN はスキーマ情報を手動で渡す必要があるのかと思います。しかし、東京リージョン対応やスキーマ自動取得、JOIN/パーティション対応やスケジュールクエリ連携が強化されれば、自然言語だけで完結するデータ分析が一気に身近になるはずです。今後のアップデートに大いに期待しています。
参考
- mcp-bigquery-server
https://github.com/ergut/mcp-bigquery-server
- Model Context Protocol 公式