はじめに
みなさんは、自社のデータを活用した**RAG(Retrieval-Augmented Generation)**を構築したことはあるでしょうか。社内Wikiやマニュアル、ローカルな知識を含むチャットボットの作成において、RAGは欠かせない技術となっています。 しかし、従来のRAGには大きな課題がありました。それは、「テキスト情報しかナレッジとして格納できない」という点です 。 実際のドキュメントには、テキストだけでなく画像、グラフ、表といったマルチモーダルなコンテンツが含まれています 。これらは従来、ナレッジ化の過程で無視されるか、あるいはOCR(光学文字認識)によって無理やりテキスト情報に変換されていました 。その結果、画像や表が本来持っている視覚的なニュアンスや構造的な情報は失われてしまっていたのです 。 この限界を克服する新たなフレームワークとして登場したのが、「RAG-Anything」です。RAG-Anythingは、画像や表などのマルチモーダルなコンテンツを、その情報を損なうことなく「知識」として統合し、検索可能にします 。 本記事では、このRAG-Anythingについて、以下のステップで解説していきます。
- RAG-Anythingの概要と特徴
- Google Colabを使った導入手順
- 従来のRAGとの比較 これまでのRAGでは取りこぼしていた「非テキスト情報」を活用したいと考えている方にとって、必見の内容です。
この記事の対象者
- 社内情報チャットボットを作成しようと考えている人
- 画像や表などマルチモーダルなコンテンツをRAGに導入したいと考えている人
RAG-Anythingの概要
本セクションでは、RAG-Anythingが従来のRAGと具体的に何が異なるのか、その概要を解説します。なお、より詳細なアーキテクチャや性能評価については、以下の論文紹介記事で詳しく解説していますので、併せてご参照ください。
https://blog.elcamy.com/posts/858f5469/ RAG-Anythingは、テキストだけでなく、画像、表、数式などのマルチモーダルな情報を「知識」として統合的に扱うためのフレームワークです。 従来のRAGがドキュメントを「テキストの羅列」として処理していたのに対し、RAG-Anythingはドキュメントを「相互に関連した知識エンティティの集合」として捉え直します。これにより、例えば「図2と表3の関係」といった、テキスト化すると失われてしまう構造的な文脈を維持したまま検索が可能になります。
従来のRAGとの違い
まずは、従来のテキストベースRAGとRAG-Anythingの決定的な違いを整理します。
| 特徴 | 従来のRAG (Text-Only) | RAG-Anything |
|---|---|---|
| 特徴 | 従来のRAG (Text-Only) | RAG-Anything |
| 対象データ | テキストのみ | テキスト、画像、表、数式 |
| 処理方法 | 画像や表を無視、または単純なテキスト要約に変換(情報の劣化あり) | 各モダリティ専用のプロセッサで解析し、構造を維持したまま統合 |
| 検索手法 | キーワード一致やベクトル類似度のみ | 構造的ナビゲーション(グラフ) + 意味的類似度(ベクトル)のハイブリッド |
| 得意分野 | 単純なテキスト文書 | 学術論文、財務レポート、技術マニュアルなど図表が多い文書 |
コアアルゴリズムと仕組み
RAG-Anythingがどのようにしてマルチモーダルな情報を処理しているのか、その裏側にある3つの主要なステップを解説します。
1. 文書解析:MinerUによる高精度な抽出
最初のステップは、ドキュメント(PDFなど)を機械が理解できる形式に変換するプロセスです。 ここでは「MinerU」というオープンソースのツールが採用されています 。
- マルチモーダルコンテンツの分類と処理: 入力されたファイルから、テキスト、画像、表、数式を自動的に分類し、それぞれの特性に合わせて抽出します。
- **ドキュメント階層の保持: **単に抽出するだけでなく、元のドキュメント内での位置関係(どの章にある図か、どの段落の近くにある表か)や階層構造を保持します 。これにより、情報の「文脈」が失われるのを防ぎます。
2. ナレッジ格納: デュアルグラフ構築 (Dual-Graph Construction)
抽出されたデータは、RAG-Anythingの最大の特徴である「2つの知識グラフ」として構築・統合されます 。
- **クロスモーダル知識グラフ (Cross-Modal KG): **画像や表などの「非テキスト情報」をアンカー(起点)として構築されるグラフです。VLM(大規模視覚言語モデル)を用いて画像や表の詳細な説明(キャプションや分析結果)を生成し、それらをノードとして接続します。
- **テキストベース知識グラフ (Text-Based KG): **従来のGraphRAGと同様に、テキスト部分からエンティティと関係性を抽出して構築します 。
エンティティとは 現実世界のヒト・モノ・コトなどの「実体」や、データベースなどで一意に識別・管理される「情報の単位」のこと。ユーザーの検索意図を正確に理解し、関連情報を提供するために使用されます。
これらを統一の指標によって統合し、さらにすべての要素(グラフのノード、エッジ、元のチャンク)をベクトル化して保存します 。これにより、「意味的な近さ」と「構造的な繋がり」の両方を保持します。
3. 検索アルゴリズム: クロスモーダル・ハイブリッド検索
ユーザーの質問に対して適切な回答を見つけるために、以下の3段階の高度な検索が行われます 。
- **モダリティ認識クエリエンコーディング: **ユーザーの質問(クエリ)を分析し、テキストでの情報を求めているのか、それとも「図や表」の情報を求めているのか(例:「〜の推移を表で教えて」など)を推論します 。
- ハイブリッド検索の実行:
- 構造的ナビゲーション: ナレッジグラフの繋がりを辿り、キーワード検索だけでは見つからない「関連する図表」や「論理的に繋がっているセクション」を芋づる式に探索します 。
- セマンティック検索: ベクトルストアを用いて、クエリと意味的に近いチャンクを抽出します。
- **関連性スコアによる統合: **上記2つのルートで得られた候補に対し、意味的な類似度と構造的な重要度、そしてクエリの意図(モダリティ)を総合的に評価してスコアリングを行い、最適なナレッジを抽出します 。 次のセクションから、実際にRAG-AnythingをGitHubリポジトリを参考にして実装し、それぞれのコードについて解説していきます。
RAG-Anythingコード解説
このセクションでは実際にRAG-Anythingを実装し、それぞれのコードブロックの解説をしていきます。今回は簡単なデモをするため、開発環境には「Google Colaboratory」を使用します。
0. 事前準備(APIキーの設定・環境変数の設定)
事前準備としてOPENAIのAPIキーを取得しておきます。Google Colabの『シークレット』機能を使って、APIキーを以下の表のように設定しておきます。
| APIキー名 | キー |
|---|---|
| APIキー名 | キー |
| OPENAI_API_KEY | 取得したAPIキー |
また、環境変数の設定や必要なライブラリのインストール、Googleドライブへのマウントを行います。該当するコードは以下です。
#Google
from google.colab import drive
drive.mount('/content/drive')
# 必要なパッケージをインストール
!pip install 'raganything[all]'
# MinerUパーサが正常にインストールされているか確認
!python -c "from raganything import RAGAnything; rag = RAGAnything(); print('✅ MinerU installed properly' if rag.check_parser_installation() else '❌ MinerU installation issue')"1. RAG管理クラスの作成
まずは、RAG-Anythingの複雑な設定やモデルの呼び出しを一括管理するためのクラス RAGManager を作成します。
このクラスには、LLMの設定、Embedding(ベクトル化)の設定、そしてRAGエンジンの初期化を集約します。
import asyncio
import os
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
from lightrag.lightrag import LightRAG
from google.colab import userdata
class RAGManager:
def __init__(self, working_dir, api_key_name='OPENAI_API_KEY'):
self.working_dir = working_dir
self.api_key = userdata.get(api_key_name)
self.base_url = "https://api.openai.com/v1"
# RAGエンジンの初期化
self.rag = self._setup_rag()
# テキスト処理用LLM(軽量なgpt-4o-miniを使用)
def _llm_model_func(self, prompt, system_prompt=None, history_messages=[], **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=self.api_key,
base_url=self.base_url,
**kwargs,
)
# 画像解析用LLM(高性能なgpt-4oを使用)
def _vision_model_func(self, prompt, system_prompt=None, history_messages=[], image_data=None, messages=None, **kwargs):
# 画像データが含まれる場合や複雑なメッセージ構造の場合の処理
if messages:
return openai_complete_if_cache(
"gpt-4o", "", system_prompt=None, history_messages=[], messages=messages,
api_key=self.api_key, base_url=self.base_url, **kwargs
)
elif image_data:
# 画像をBase64で受け取りGPT-4oに投げる
return openai_complete_if_cache(
"gpt-4o", "", system_prompt=None, history_messages=[],
messages=[
{"role": "system", "content": system_prompt} if system_prompt else None,
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}},
]} if image_data else {"role": "user", "content": prompt},
],
api_key=self.api_key, base_url=self.base_url, **kwargs
)
else:
return self._llm_model_func(prompt, system_prompt, history_messages, **kwargs)RAG-Anythingでは、通常のテキスト生成には高速で安価な「gpt-4o-mini」を使用し、図表の解析や画像理解が必要な箇所(_vision_model_func)では高性能な「gpt-4o」 を使用するように関数を分けています。これにより、コストを抑えつつ高いマルチモーダル性能を発揮させます。
2. エンジンの初期化設定 (_setup_rag)
次に、_setup_rag メソッド内でRAG-Anythingと、そのコアとなるLightRAGの設定を行います。
def _setup_rag(self):
# RAG-Anythingの設定:MinerUパーサとマルチモーダル処理を有効化
config = RAGAnythingConfig(
working_dir=self.working_dir,
parser="mineru", # PDF解析にMinerUを使用
parse_method="auto",
enable_image_processing=True, # 画像処理をON
enable_table_processing=True, # 表処理をON
enable_equation_processing=True, # 数式処理をON
)
# Embedding関数の定義(text-embedding-3-largeを使用)
embedding_func = EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=self.api_key,
base_url=self.base_url,
),
)
# RAG-Anythingインスタンスの作成
rag_instance = RAGAnything(
config=config,
llm_model_func=self._llm_model_func,
vision_model_func=self._vision_model_func, # 画像用モデル関数を渡す
embedding_func=embedding_func,
)
# 既存のデータがあればロードするためにLightRAGを明示的に初期化
print(f"Initializing LightRAG engine from: {self.working_dir}")
rag_instance.lightrag = LightRAG(
working_dir=self.working_dir,
llm_model_func=self._llm_model_func,
embedding_func=embedding_func,
)
return rag_instanceここでは parser="mineru" を指定することで、PDF内の複雑なレイアウトを構造化データとして抽出します。また、最後に rag_instance.lightrag に LightRAG インスタンスを直接代入することで、以前作成したナレッジベース(working_dir内のデータ)を即座に利用できるようにしています。
3. ナレッジ構築と検索メソッドの実装
最後に、実際にドキュメントを読み込むメソッドと、検索を行うメソッドを追加します。
# --- 公開メソッド ---
# ナレッジベース構築(ファイルの読み込み・解析・インデックス作成)
async def build_knowledge_base(self, file_path, output_dir=None):
if output_dir is None:
# 入力ファイルと同じ階層のoutputフォルダに出力
output_dir = os.path.join(os.path.dirname(self.working_dir), "output")
print(f"Constructing Knowledge Base from: {file_path}...")
# MinerUで解析し、グラフとベクトルインデックスを構築
await self.rag.process_document_complete(
file_path=file_path,
output_dir=output_dir,
parse_method="auto"
)
print("Construction Complete.")
# 検索(ハイブリッド検索)
async def search(self, query_text, mode="hybrid"):
print(f"Searching for: {query_text}...")
# hybridモードで、キーワード、ベクトル、グラフ構造を組み合わせて検索
result = await self.rag.aquery(query_text, mode=mode)
return resultこれでクラス「RAGManager」の実装は完了です。(Google Colabで実装する場合、1. 2. 3. で書かれているコードは同一セクションにしてください。)
4. 実行:ナレッジの構築から検索まで
クラスの準備ができたら、実際に動かしてみましょう。 ここではGoogleドライブ内のPDFファイルを読み込ませ、その内容について質問を行います。
4-1. ナレッジベースの構築(初回のみ)
まずはPDFファイルをRAGに取り込みます。この処理には、MinerUによる解析とOpenAIによるグラフ構築が含まれるため、数分〜数十分かかる場合があります。
# 保存先ディレクトリを指定(Googleドライブ直下など)
working_dir = "/content/drive/MyDrive/Colab_notebooks/rag_storage"
rag_manager = RAGManager(working_dir=working_dir)
# 解析したいPDFのパス(Googleドライブ内のパスを指定)
file_path_in_drive = "/content/drive/MyDrive/Data/paper.pdf" # ※適切なパスに変更してください
# ナレッジ構築を実行
await rag_manager.build_knowledge_base(file_path_in_drive)4-2. 検索の実行
構築が完了したら、実際に質問を投げてみます。ここではRAG-Anythingの強みである「表やグラフ」に関する質問をしてみましょう。
# 検索用に再度マネージャーを初期化(working_dirを指定すれば構築済みデータをロードします)
rag_manager = RAGManager(working_dir="/content/drive/MyDrive/Colab_notebooks/rag_storage")
# 質問の実行
query = "検索したい内容をここに入力してください。"
answer = await rag_manager.search(query)
# 結果の表示
print(answer)従来のRAGとの比較
本セクションでは、実際に「従来のRAG」と「RAG-Anything」それぞれでナレッジベースを構築し、回答の質・構築時間・コストの3点を比較検証します。 検証用のデータセットとして、消費者庁が公開している以下のドキュメント(約10ページ分)を使用しました。図表やグラフが多く含まれており、マルチモーダルRAGの性能差が出やすい資料です。 引用文献(pp.1~10):
先に結論を述べると、RAG-Anythingは「コスト(時間・料金)はかかるが、回答精度と具体性が圧倒的に高い」という結果になりました。
| 比較項目 | 従来のRAG (PyPDFLoader) | RAG-Anything |
|---|---|---|
| 比較項目 | 従来のRAG (PyPDFLoader) | RAG-Anything |
| 回答精度 | 低い テキスト情報のみの抽出となるため、図表内の数値やトレンドを回答に反映できない。 | 高い グラフや表の特徴を抽出し、回答の根拠として具体的な数値を示せている。 |
| 構築時間 (ナレッジベースの構築) | 速い 2分50秒 | 遅い 16分30秒 |
| 検索(回答)時間 | 速い 15秒 | 遅い 1分 |
| 構築料金 | 安い 約 $0.02 | 高い 約 $0.11 |
それぞれの詳細については後述しますが、まずは比較対象となる「従来のRAG」の構築手法について解説します。 検証環境:「従来のRAG」の構築 比較対象である「従来のRAG」には、LangChainの標準的なローダーである PyPDFLoader を使用します。 これはPDFからテキスト情報のみを抽出する一般的な手法であり、表やグラフについては「タイトルなどの文字情報」しか取得できず、視覚的な情報は欠落します。 以下は、Google Colab上で従来のRAGを構築・実行するためのコードです。
従来のRAG構築コード(RAG構築部分)
- 必要なパッケージのインストール・Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')
#必要なパッケージのインストール
!pip install -U langchain langchain-community langchain-core langchain-openai langchain-text-splitters
!pip install chromadb tiktoken pypdf
!pip uninstall -y langchain langchain-core langchain-community langchain-openai langchain-huggingface langchain-text-splitters langsmith
!pip install -U "langchain>=0.3,<0.4" langchain-core langchain-community langchain-openai langchain-huggingface langchain-text-splitters- 環境変数の設定・必要なライブラリのインポート
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
import logging
# LangChain Community & Contrib
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
# LangChain OpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
# LangChain Text Splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
# LangChain Core (推奨されるインポート元)
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
# その他のコア機能
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
import asyncio- PDFの読み込み・ベクトルストアの初期化
#ナレッジを作成したいファイルを入力
loader = PyPDFLoader("/content/drive/MyDrive/your_path/your_file.pdf")#ここにファイルパスを入力
pages = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=128)
split_docs = text_splitter.split_documents(pages)
base_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
llm = base_llm
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Chroma.from_documents(split_docs, embedding=embeddings, persist_directory=".")
vectorstore.persist()- 会話メモリと検索チェーンの作成
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer"
)
template = """あなたは与えられた文書の内容に基づいて質問に答える専門家です。
質問に対して、文書の情報のみを使用して詳細かつ正確に回答してください。
文書に関連する情報がない場合は、「申し訳ありませんが、この文書にはその情報が含まれていません」と答えてください。
文脈情報:
{context}
質問: {question}
回答:"""
PROMPT = PromptTemplate(template=template, input_variables=["context", "question"])
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
memory=memory,
return_source_documents=True,
verbose=True,
combine_docs_chain_kwargs={"prompt": PROMPT},
chain_type="stuff",
return_generated_question=False,
output_key="answer"
)- 回答チャットボットの実行
query = "日本の地球温暖化に対する問題と、その根拠としてどのようなソースがあるか教えてください。"
chat_history = []
# ベクトルストアを直接検索(k=5で上位5件を取得)
retrieved_docs = vectorstore.similarity_search(query, k=5)
# invoke メソッドを使用
result = qa.invoke({"question": query, "chat_history": chat_history})
print("\n最終回答:")
print(result["answer"])
print("--- 取得された上位ドキュメント ---")
for i, doc in enumerate(retrieved_docs):
print(f"\n--- ドキュメント {i+1} ---")
# チャンクの内容を表示
print(f"内容:\n{doc.page_content[:200]}...") # 内容を一部表示
# メタデータ(ファイル名、ページ番号など)を表示
print(f"メタデータ: {doc.metadata}")1. 回答精度の検証
実際に、同じデータソース(消費者白書)を用いて構築した2つのナレッジベースに対し、同一の質問を投げかけて回答の違いを検証しました。 入力クエリ:
日本の地球温暖化に対する問題と、その根拠としてどのようなソースがあるか教えてください。
従来のRAGの回答結果
まずは、PyPDFLoader でテキストのみを抽出した従来のRAGの回答です。
最終回答: 日本の地球温暖化に対する問題は、近年の気温上昇に関連しています。具体的には、日本の年平均気温が長期的に上昇しており、100年当たり1.40℃の割合で上昇していることが示されています。 根拠としては、国際連合のグテーレス事務総長が「地球温暖化の時代は終わり、地球沸騰化の時代が到来した」と表明していることや、IPCCが「人間の影響が大気、海洋及び陸域を温暖化させてきたことには疑う余地がない」と述べていることが挙げられます。 評価: 回答自体は間違っていませんが、内容はテキストとして書かれている「一般的な事実」や「引用文」に留まっています。ドキュメント内に存在するはずのグラフ(気温推移の具体的なトレンド)や、視覚的な根拠については触れられていません。
RAG-Anythingの回答結果 次に、RAG-Anythingの回答を見てみましょう。
地球温暖化の影響 気温の上昇: 日本の年平均気温のデータに基づくと、1898年から2024年にかけて、気温の偏差が明らかです。長期的には、1世紀あたり1.40℃の上昇が観測されています([1])。 極端な猛暑日: 東京における年間猛暑日の数が増加しています。2000年以前は猛暑日が年10日を超える年はほとんどありませんでしたが、2001年以降はその頻度が増加しています(図表I-2-1-2)。 ソースとグラフ • 年平均気温偏差の経年変化(図表I-2-1-1): 日本の年平均気温の偏差を示すグラフ。気温が長期的に上昇していることを視覚的に示しています。 • 東京の年間猛暑日日数の推移(図表I-2-1-2): 近年、猛暑日の頻度が増加していることが明示されています。 画像 [ここに図表I-2-1-1の画像のリンクが表示されます。] [ここに図表I-2-1-2の画像のリンクが表示されます。]
画像のリンク先にアクセスすると回答の根拠となる図と表が表示されました。
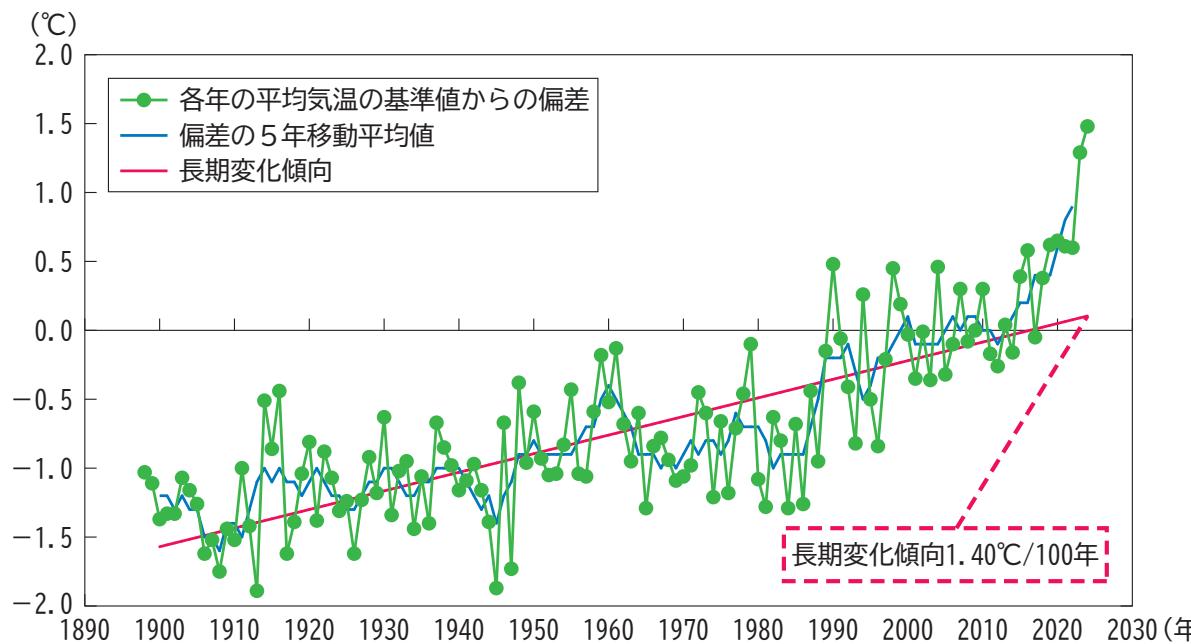 図1: 年平均気温偏差の経年変化
図1: 年平均気温偏差の経年変化
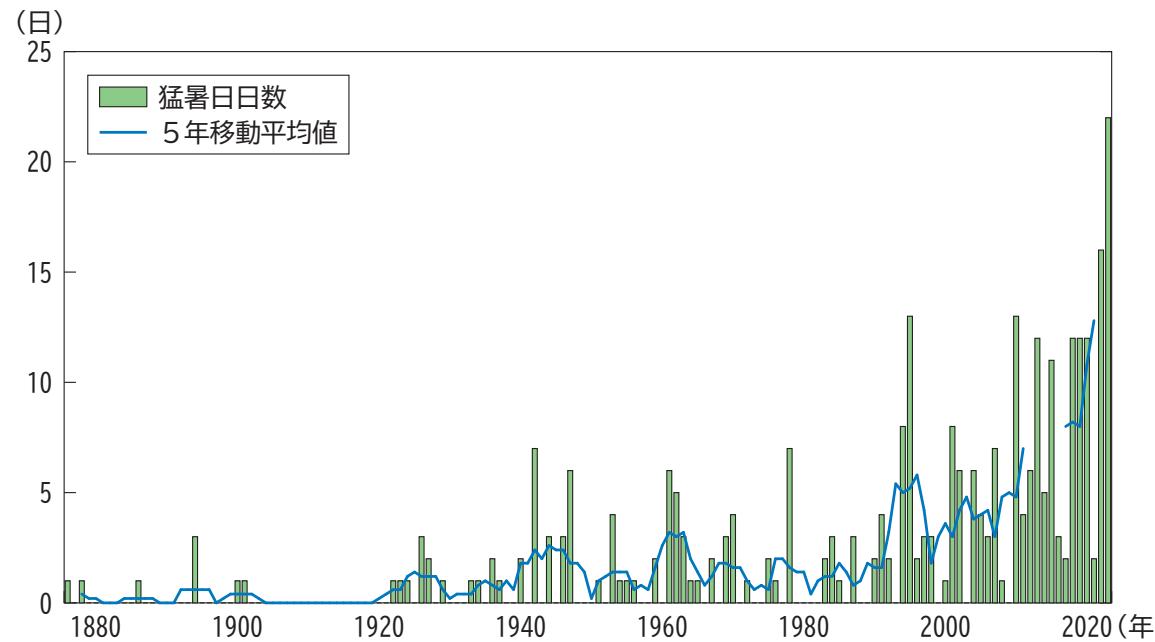 図2: 東京の年間猛暑日日数の推移
明確な違いが出ました。特に注目すべきは以下の2点です。
図2: 東京の年間猛暑日日数の推移
明確な違いが出ました。特に注目すべきは以下の2点です。
- 図表内のトレンドを言語化している: 「2000年以前は〜ほとんどありませんでしたが」といった、グラフを見ないと分からない情報を読み取り、回答に含めています。
- 根拠として「図表」を提示している: テキストだけでなく、具体的な図番号(図表I-2-1-2など)を引用し、さらにその画像を提示することで、回答の説得力が格段に向上しています。
2. 構築・検索にかかる実行時間と料金の比較
RAG-Anythingは高い回答精度を誇りますが、その分リソースを消費します。ここでは、約10ページのPDF(画像・グラフ多数)を処理した際にかかった時間とコストを比較します。
| 比較項目 | 従来のRAG | RAG-Anything | 差分 |
|---|---|---|---|
| 比較項目 | 従来のRAG | RAG-Anything | 差分 |
| 構築時間 (ナレッジベースの構築) | ** **約2分50秒 | 約 16分30秒 | ** 約 5.8倍** |
| 検索(回答)時間 | 約15秒 | 約60秒 | 約4倍 |
| 構築料金 | 約 $0.02 | 約 $0.11 | ** 約 5.5倍** |
※RAG-Anythingの画像処理には高価なモデル(gpt-4oなど)が使用されるため、画像の枚数によってコストは大きく変動します。
結果として、RAG-Anythingは従来のRAGに比べて時間もコストも5倍以上かかることがわかりました。その理由は、内部で行われている処理の複雑さにあります。 1. 画像処理のコスト (VLM Cost): 従来のRAGはテキストを切り出すだけですが、RAG-Anythingはドキュメント内のすべての画像・図表に対してVLM(今回はgpt-4o)による詳細なキャプション生成を行います。これがコストと時間の増加の最大の要因です。 2. デュアルグラフ構築 (Graph Construction): 単にベクトル化するだけでなく、テキストと画像の関係性を解析し、知識グラフ(ノードとエッジ)を構築する処理が入るため、API呼び出し回数が指数関数的に増加します。 3. 検索時のオーバーヘッド: 検索時においても、単純なベクトル検索(0.1秒未満)で終わる従来のRAGに対し、RAG-Anythingは「ベクトル検索 + グラフ探索 + 関連性スコア計算」を行うため、回答生成までの待ち時間(レイテンシ)は数秒〜十数秒長くなる傾向があります。
実務運用に向けた課題と推奨構成
今回ご紹介したデモコードは、Google Colab上で手軽にRAG-Anythingの性能を体験するための構成です。しかし、実際にこのシステムを企業の実務環境で運用しようとした場合、いくつかの課題に直面します。
1. データストアの課題(スケーラビリティ)
今回のデモでは、ベクトルデータやナレッジグラフをローカル環境(Colabのディスクやメモリ上)に簡易的に保存しています。しかし、データ量が数万〜数億件に増えた場合や、複数ユーザーからの同時アクセスが発生する環境では、この構成ではパフォーマンスが維持できません。 実務で運用する場合、データの永続化と高速な検索処理を保証するために、以下のような専門的なデータベースへの移行が推奨されます。
- ベクトルデータベース: Milvus・pgvector など
- 大量のベクトルデータの高速検索とスケーリングに優れています。
- グラフデータベース: Neo4j
- 複雑なナレッジグラフの格納と、高度なグラフ探索クエリ(Cypher)に対応しています。
2. 実装のハードル
RAG-Anything(およびバックエンドのLightRAG)は、非常に高機能な一方で、データの格納から検索までを一気通貫で行う「パッケージ化された」ライブラリです。 そのため、デフォルトのローカルストレージから上記の Milvus や Neo4j といった外部DBに接続先を切り替えるには、ライブラリ内部のクラスを継承して保存ロジックを再実装するなどの高度なカスタマイズが必要となります。 「とりあえず試す」ハードルは低いですが、「実務用にカスタマイズする」ハードルは意外と高いのが現状です。
おわりに
本記事では、マルチモーダルな情報を「知識」として統合できる画期的なフレームワーク「RAG-Anything」について、その概要から導入手順、そして従来のRAGとの比較検証までを行いました。 検証の結果、RAG-Anythingはコストと構築時間はかかるものの、図表を含むドキュメントに対して圧倒的に高い回答精度と具体性を発揮することがわかりました。特に、図面やグラフに重要な情報が詰まっている製造業や金融業界のドキュメント活用において、この「理解力」は強力な武器になるでしょう。 一方で、前述の通りこれを実務システムとして組み込むには、MilvusやNeo4jといった外部DBとの連携など、アーキテクチャ面での工夫が必要です。 今回は「まずは動かしてみる」ことに焦点を当てましたが、次回以降の記事では、これらの外部DBを組み込んだ「実務でも使用することができるRAG-Anything構築」にも挑戦してみたいと思います。 この記事が、皆様の次世代RAG開発のヒントになれば幸いです。