RAGの現在地 そのメリットと評価の難しさ
近年、LLM(大規模言語モデル)の実用化において、**RAG(Retrieval-Augmented Generation)**は標準的なアーキテクチャとしての地位を確立しました。なぜこれほどまでにRAGが注目されているのでしょうか。その理由は主に以下の2点に集約されます。
- ハルシネーション(幻覚)の抑制: LLM単体では防ぎきれない「もっともらしい嘘」を、外部データベースに基づいた回答生成を行うことで大幅に削減できます。
- 学習コストの削減と柔軟性: ファインチューニングのようにモデル自体のパラメータを更新(再学習)する必要がありません。同一のLLMを使い続けたまま、外部データの差し替えだけで専門領域の拡張や情報の更新が可能なため、運用・保守のコストを抑えやすいという利点があります。 しかし、RAGシステムが普及するにつれて、新たな壁が立ちはだかっています。 それが「評価の難しさ」です。 今回紹介するサーベイ論文『Retrieval Augmented Generation Evaluation in the Era of Large Language Models』では、RAGの評価における現状の課題として、以下の4点を指摘しています。
- LLMベース評価のブラックボックス性: 近年、評価自体にLLMを用いる手法が増えていますが、その判定プロセスはブラックボックスになりがちです。LLMの不安定さやセキュリティリスクが、評価の信頼性に影響を与える可能性があります。
- 評価コストの高騰: ツールやデータセットが大規模化しており、徹底的な評価を行おうとすると金銭的・計算的なコストが非常に高くなってしまうのが現状です。
- 統合的な評価指標の欠如: OpenAIのo1モデルのような「深い思考(Deep Thinking)」を行うモデルや、検索・生成が複雑に絡み合うプロセス全体を、機能単位で分解して評価できる統括的な指標がまだ確立されていません。
- 言語的な偏り: 現在の主要な評価フレームワークは、英語や中国語など一部の言語に偏っており、多様な言語をカバーできていないという課題があります。 本記事では、この論文をベースに、現在利用可能なRAGの評価指標を網羅的に紹介し、これらの課題に対してどのように向き合うべきかを解説します。 今回参考にさせていただいた論文はこちらです。
https://arxiv.org/pdf/2504.14891v1
この記事の対象者
- RAG構築を検討・実施しているエンジニア
- 社内チャットボット導入の担当者
- RAGの検証方針に迷っている人
RAG評価指標の全体像 内部評価と外部評価
RAGの評価指標は多岐にわたりますが、闇雲に測定しても意味がありません。この論文では、評価の視点を「内部評価(Internal Evaluation)」と「外部評価(External Evaluation)」の2つに大別して整理しています。 これは、自動車の検査に例えるとわかりやすいでしょう。
- 内部評価: エンジンの回転数やブレーキの効き具合など「部品(コンポーネント)の性能」をチェックすること。
- 外部評価: 実際に公道を走って、乗り心地や燃費、事故を起こさないかなど「完成車としての品質」をチェックすること。
内部評価 (Internal Evaluation)
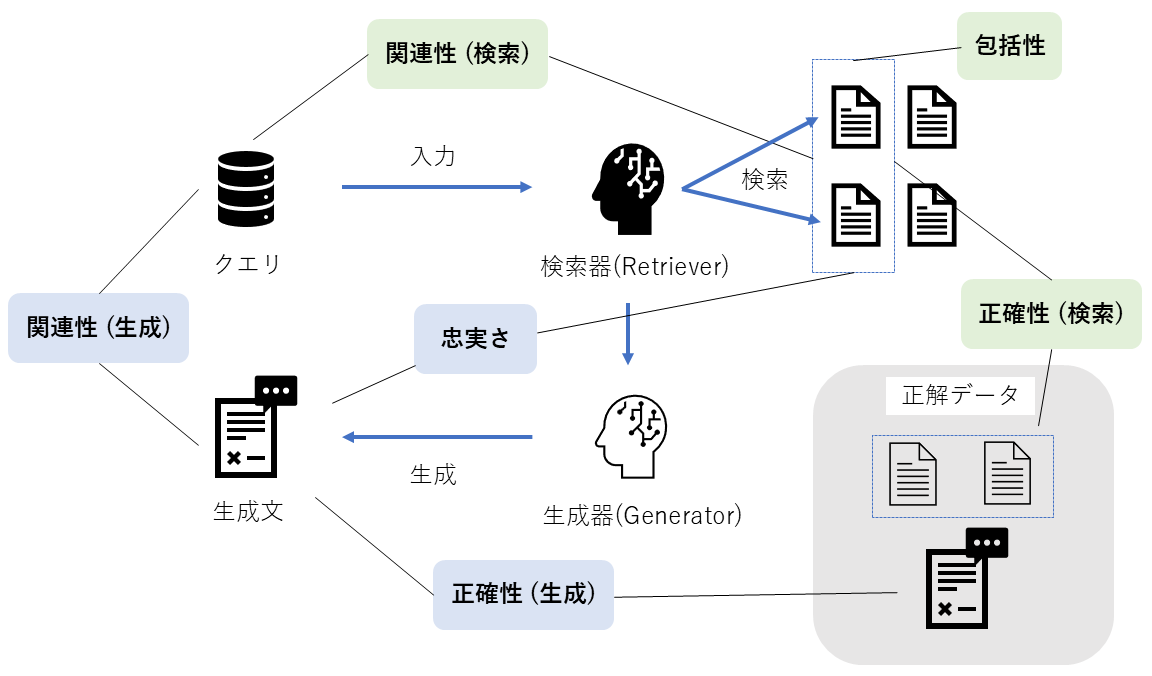
内部評価は、RAGシステムを構成する機能の技術的な性能に焦点を当てます。 RAGは主に「検索(Retrieval)」と「生成(Generation)」という2つのプロセスから成り立っており、それぞれ以下の観点で評価されます。
検索コンポーネント(Retriever)
- 関連性 (Relevance): クエリの意図に合ったドキュメントを取得できているか?
- 包括性 (Comprehensiveness): 必要な情報を漏れなく網羅できているか?
- 正確性 (Correctness): ノイズを含まず、正解となるドキュメントをピンポイントで取得できているか?
生成コンポーネント(Generator)
- 関連性 (Relevance): ユーザーの質問に対して、的を射た回答になっているか?
- 忠実さ (Faithfulness): 検索されたドキュメントの内容に基づいているか?
- 正確性 (Correctness): 回答の内容自体が事実として正しいか?
これらをまとめた概念図が以下になります。
外部評価 (External Evaluation)
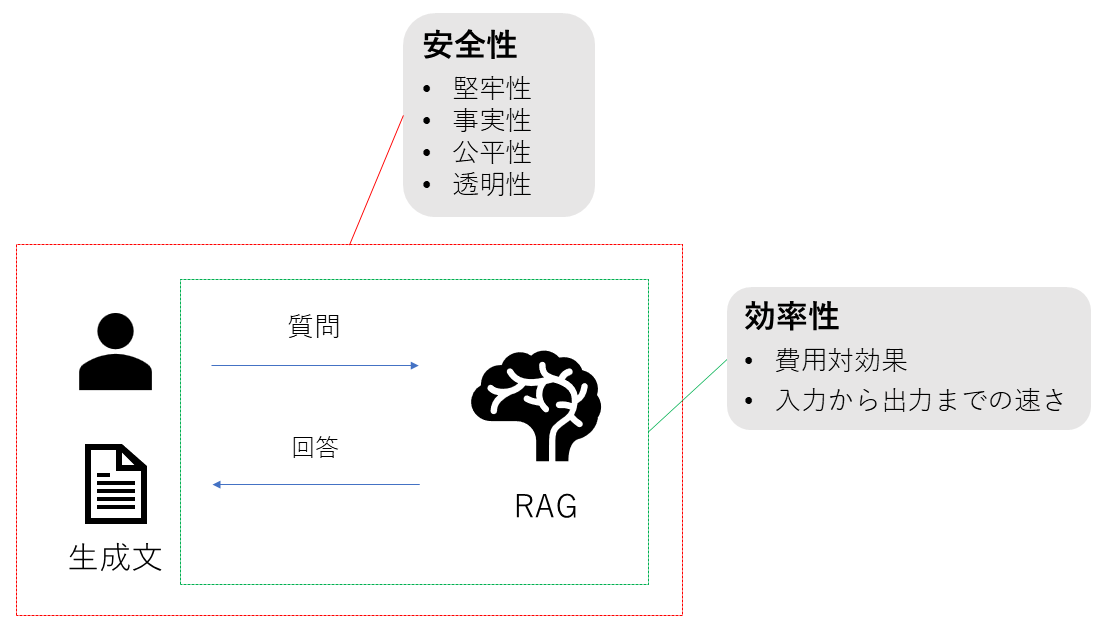
外部評価は、RAGシステム全体を一つの「ブラックボックス」として捉え、実運用における「実用性(Utility)」を測るプロセスです。ここでは、コンポーネントごとの技術的なスコア以上に、ビジネス価値やユーザー体験(UX)に直結する指標が重視されます。
安全性 (Safety)
システムが予期せぬ入力や悪意ある操作に対して、どれだけ安全かつ信頼性を保てるかを評価します。
- 堅牢性 (Robustness) 検索結果にノイズや誤った情報が含まれていた場合でも、それに惑わされず正確な回答を維持する能力。
- 事実性 (Factuality) 正確な事実に基づいた情報を生成し、もっともらしいが誤った記述(ハルシネーション)を回避する性能。
- 公平性 (Fairness) 検索された参照文書にバイアスが含まれている場合であっても、偏りを排除し、中立的で公平な回答を生成する能力。
- 透明性 (Transparency) 回答に至るプロセスや参照元が明確であり、ブラックボックス化せずに説明責任を果たせる状態であるか。
効率性 (Efficiency)
実運用において、システムがどれだけパフォーマンス良く、かつ経済的に動作するかを評価します。
- 速度 (Latency) ユーザー体験を損なわない、ストレスのないレスポンス速度(特にTime to First Token)の確保。
- 費用 (Cost) LLMのトークン課金やインフラ費用などの運用コストが、システムから得られるビジネス価値に見合っているかの経済的妥当性。
評価指標の分類:「従来型」と「LLMベース」
次は**「どうやって測定するか(How)」という具体的な評価指標(Metrics)**の話に移ります。 現在のRAG評価指標は、歴史的背景から大きく2つのグループに分けられます。
- 従来の評価指標 (Traditional Metrics):
- 検索器や翻訳AIの分野で確立された、数理的・統計的な計算に基づく指標です。
- 特徴: 計算が高速で客観的ですが、「正解データ(Ground Truth)」が必要になるケースが多いです。
- LLMベースの評価指標 (LLM-based Metrics):
- LLM自体に「審査員」の役割をさせ、意味や文脈を判定させる新しい手法です。
- 特徴: 「正解データ」がなくても評価可能ですが、コストがかかり、判定がブラックボックスになりがちです。 次のセクションからは、これらの指標を「検索」と「生成」のコンポーネントごとに詳しく解説していきます
内部評価における評価指標
従来型の評価指標:検索コンポーネント
検索器が「正しいドキュメント」を取得できたかを評価する、IR(Information Retrieval)分野の伝統的な指標です。
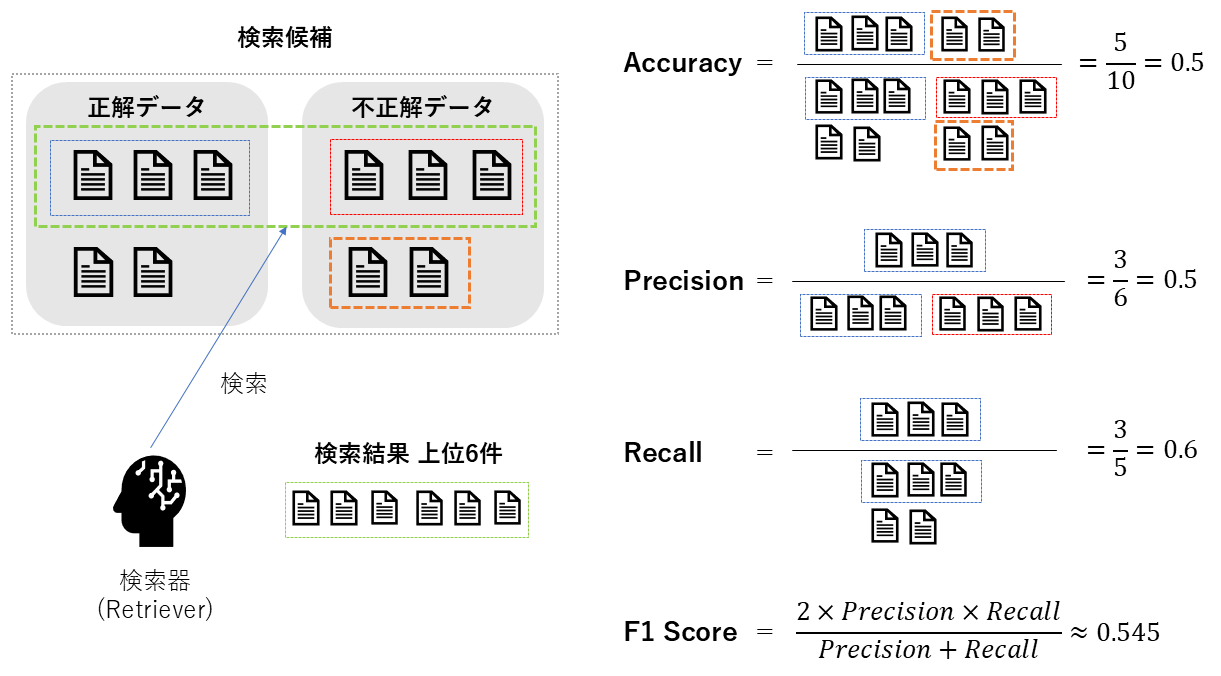
Accuracy@K・Precision@K・Recall@K・F1 Score@K
| 項目 | Accuracy@K | Precision@K | Recall@K | F1 Score@K |
|---|---|---|---|---|
| 概要 | 上位K件に正解が1つでも含まれる割合(Hit率)。 | 上位K件のうち、正解が含まれる割合(質の高さ)。 | 全正解データのうち、上位K件で拾えた割合(網羅性)。 | PrecisionとRecallの調和平均(バランス)。 |
| 必要なデータ | ・検索結果(Top-K) ・正解文書リスト | 同左 | 同左 | 同左 |
| 指標の見方 | 0~1 とりあえず1つ見つかればOKならこれを見る。 | **0~1 **ノイズ(ハズレ)の少なさを重視する場合に見る。 | **0~1 **取りこぼしの少なさを重視する場合に見る。 | **0~1 **質と網羅性のバランスを見たい場合に見る。 |
| 前提 | 順位の「並び順」までは考慮しない指標。 | 同左 | 同左 | 同左 |
数式
TP: 真陽性数 TN: 真陰性数 FP: 偽陽性数 FN: 偽陰性数
$$ Accuracy = \frac{TP + TN}{Total} \ $$
$$ Precision = \frac{TP}{TP + FP} $$
$$ Recall = \frac{TP}{TP + FN} $$
$$ F1 = \frac{2 \cdot Precision \cdot Recall}{Precision + Recall} $$
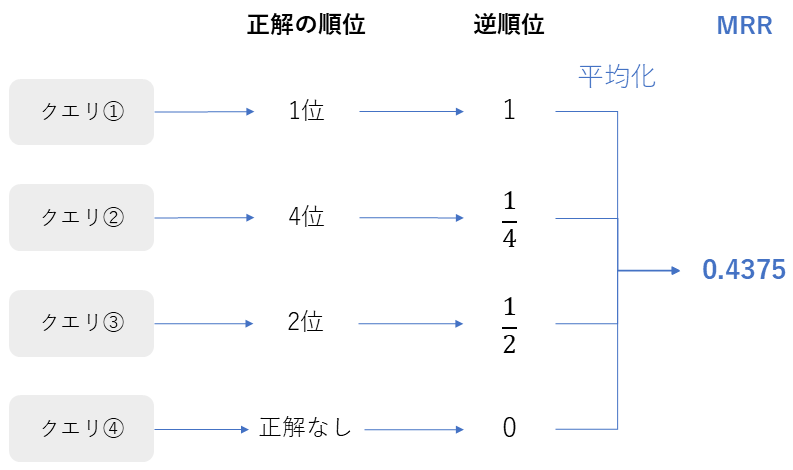
MRR (Mean Reciprocal Rank)
| 項目 | 内容 |
|---|---|
| 評価指標名 | MRR (Mean Reciprocal Rank) |
| 概要 | クエリごとの「最初の正解文書が何番目に出てくるか?」の逆数を、クエリ全体で平均した指標 |
| 必要なデータ | ・クエリ ・正解文書の順位情報 |
| 指標の見方 | **0~1 **1に近いほど、正解がトップ(1位)に表示されている。 順位が下がるとスコアが急激に下がる(1位=1.0, 2位=0.5, 3位=0.33...)。 |
| 前提 | ユーザーが「最初の正解」だけに関心がある場合(Factoid型Q&Aなど)に適している。 |
数式
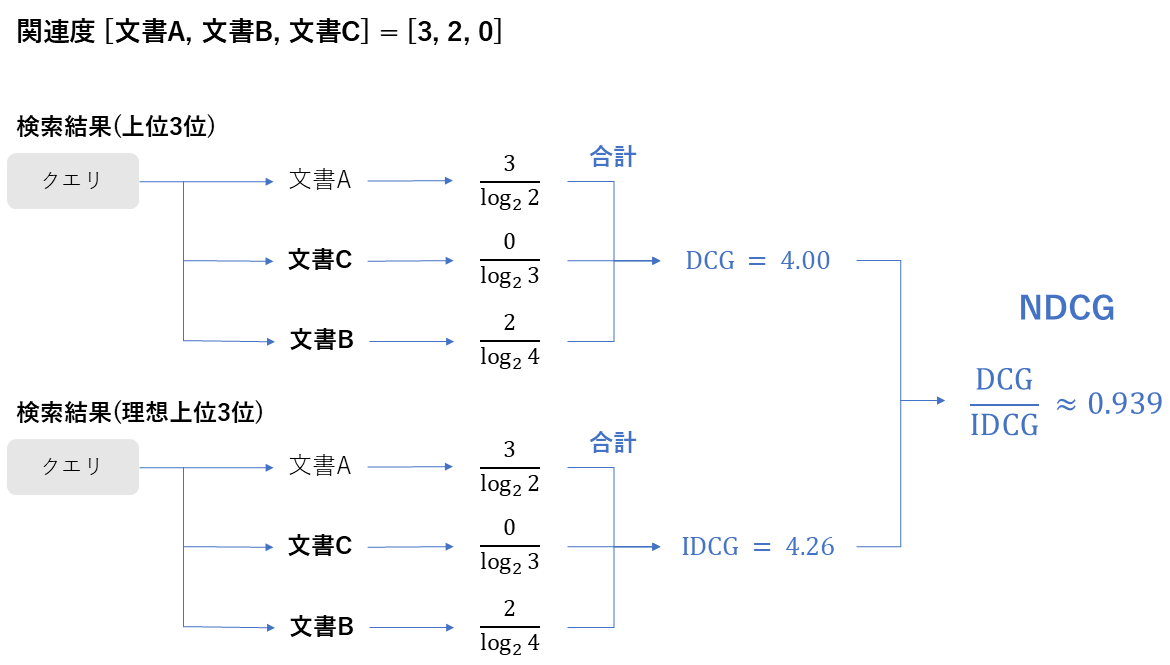
|Q|:クエリの総数 \mathrm{rank}i:クエリ i に対して最初に正解文書が出現した順位 $$ MRR = \frac{1}{|Q|} \sum{i=1}^{|Q|} \frac{1}{\mathrm{rank}_i} $$ ::: --- ### NDCG@K (Normalized Discounted Cumulative Gain) | 項目 | 内容 | | --- | --- | | 評価指標名 | NDCG@K | | 概要 | 文書の「関連度(3段階など)」と「表示順位」の両方を考慮した指標。正解が上位にあるほど高得点になる。 | | 必要なデータ | ・各文書の関連度スコア(例:3=高, 1=低, 0=無) ・検索結果の順位 | | 指標の見方 | **0~1 **1に近いほど、関連度の高い文書が理想的な順序(上位)で並んでいることを示す。 | | 前提 | MRRよりも厳密に「ランキングの質」を評価したい場合に使用する。 |
:::details 数式
\mathrm{rel}_i: 順位 i における文書の関連度 \mathrm{DCG@k}: 実際の検索結果の割引累積利益 \mathrm{IDCG@k}: 理想的な検索結果の場合の割引累積利益
$$ \mathrm{NDCG@k} = \frac{DCG@k}{IDCG@k} $$
$$ DCG@k = \sum_{i=1}^{k} \frac{2^{\mathrm{rel}_i} - 1}{\log_2(i+1)} $$
MAP (Mean Average Precision)
| 項目 | 内容 |
|---|---|
| 評価指標名 | MAP (Mean Average Precision) |
| 概要 | 正解文書が複数ある場合に、正解が出るたびのPrecision(適合率)を平均し、さらに全クエリで平均した指標。 |
| 必要なデータ | ・クエリごとの正解文書リスト(複数可) ・検索順位 |
| 指標の見方 | **0~1 **検索順位全体を通して、精度が安定して高いかを示す。 |
| 前提 | 正解が1つではなく複数存在するタスクでの総合力評価に適している。 |

数式
P(k): 上位 k 件におけるPrecision(適合率) \mathrm{rel(k)}: 順位 k における文書の決定変数。正解なら1、不正解なら0を出力する。 \mathrm{|relevant_documents_q|}: クエリ q に対する、データベース内に存在する正解文書の総数 |Q|: クエリの総数 $$ MAP=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\frac{\sum_{k=1}^{n}{(P(k)×rel(k))}}{|\mathrm{relevant_documents_q}|} $$ ::: --- ### Coverage | 項目 | 内容 | | --- | --- | | 評価指標名 | Coverage | | 概要 | 知識ベース全体に存在する「正解ドキュメント」のうち、システムが検索できた(アクセスできた)割合 | | 必要なデータ | ・検索された文書集合 ・知識ベース内の全正解文書集合 | | 指標の見方 | **0~1 **システムが知識ベースの情報をどれだけ広くカバーできているかを示す。 | | 前提 | クエリ単位ではなく、トピックやカテゴリ単位で測定されることが多い。 |
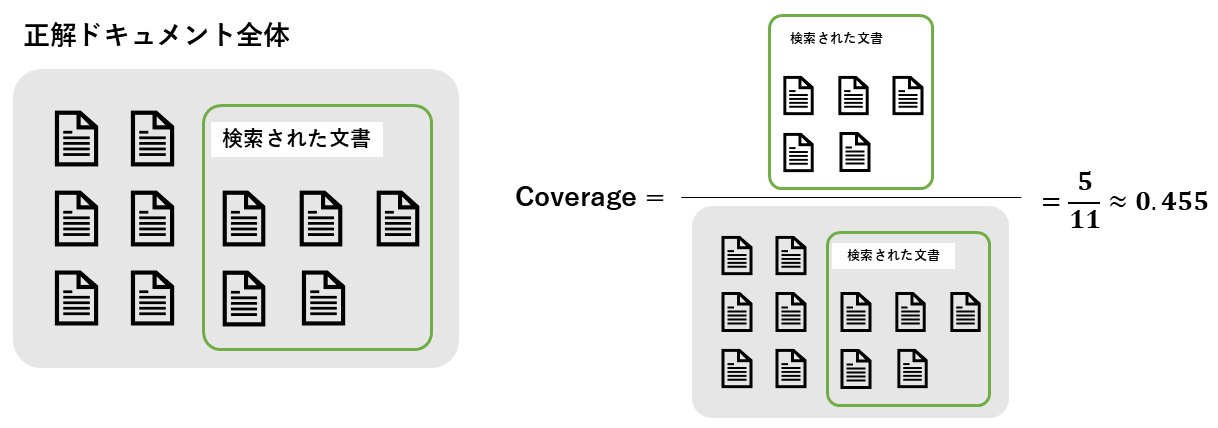
:::details 数式
\mathrm{Retrieved}: 検索された文書集合 \mathrm{RD}: 全正解文書集合
$$ \mathrm{Coverage} = \frac{|RD \cap Retrieved|}{|RD|} $$
Textual Similarity
| 項目 | 内容 |
|---|---|
| 評価指標名 | Textual Similarity |
| 概要 | 検索された文書同士が「テキストの内容(単語や意味)」としてどれくらい似ているかを測定する指標。 |
| 必要なデータ | 検索された文書のテキスト |
| 指標の見方 | 0~1 低いほど良い。1に近いほど、内容が酷似している。 内容的に関連する文書を幅広く取得できているかを評価できる点が強み。 |
| 前提 | 類似度の計算方法には、Jaccard係数(単語の一致)やコサイン類似度(ベクトルの近さ)が使われる。 |
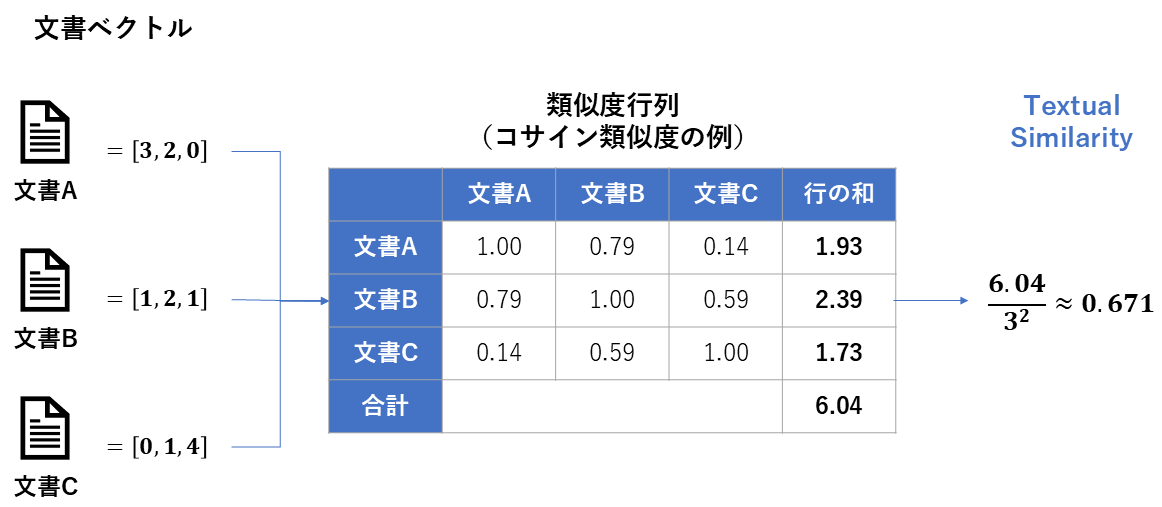
数式
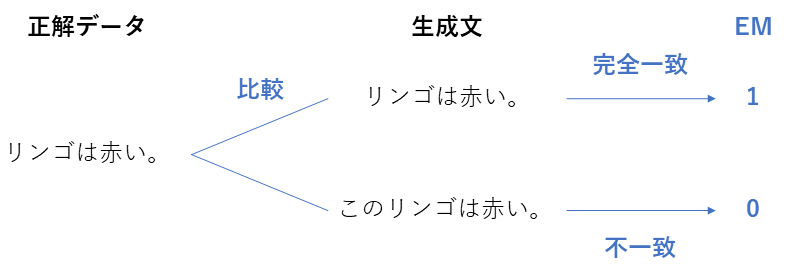
|D|: 検索文書の総数 sim(d_i, d_j): 二つの文書の意味的類似度 $$ \mathrm{Similarity} = \frac{1}{|D|^2} \sum_{i=1}^{|D|}\sum_{j=1}^{|D|}{sim(d_i, d_j)} $$ ::: ## 従来型の評価指標:生成コンポーネント LLMが生成したテキストの品質を、正解データ(Ground Truth)と比較して評価します。 ### EM (Exact Match) | 項目 | 内容 | | --- | --- | | 評価指標名 | EM (Exact Match) | | 概要 | 生成された回答が、正解と一字一句完全に一致しているかを判定する指標 | | 必要なデータ | ・生成回答 ・正解回答 | | 指標の見方 | 0 or 1 完全一致なら1。少しでも違えば0。 | | 前提 | 非常に厳しいため、通常は正規化(小文字化など)を行ってから比較する。 |
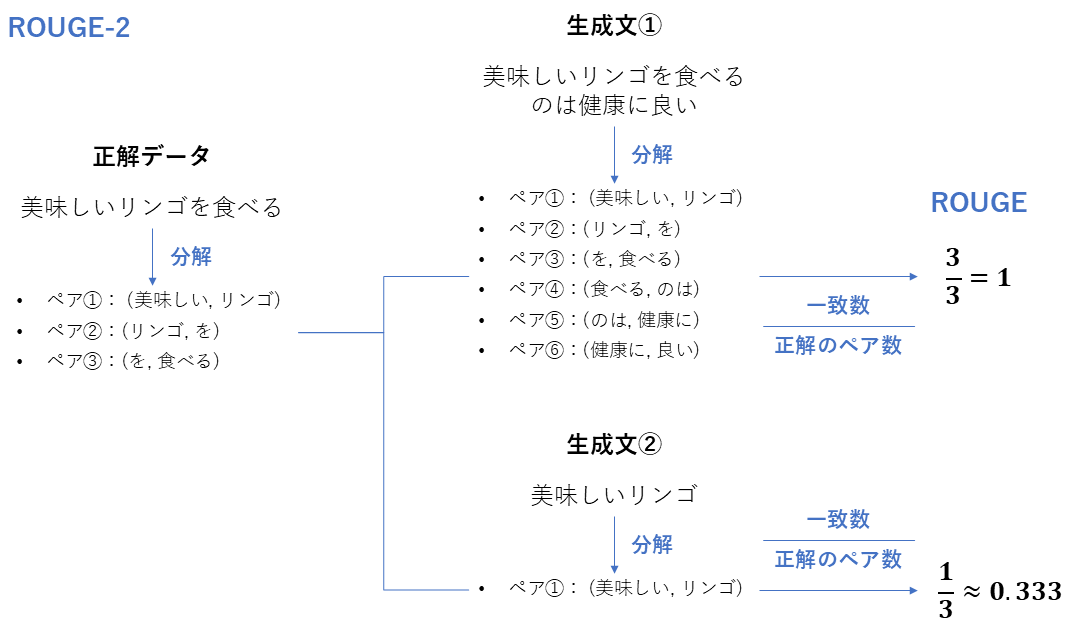
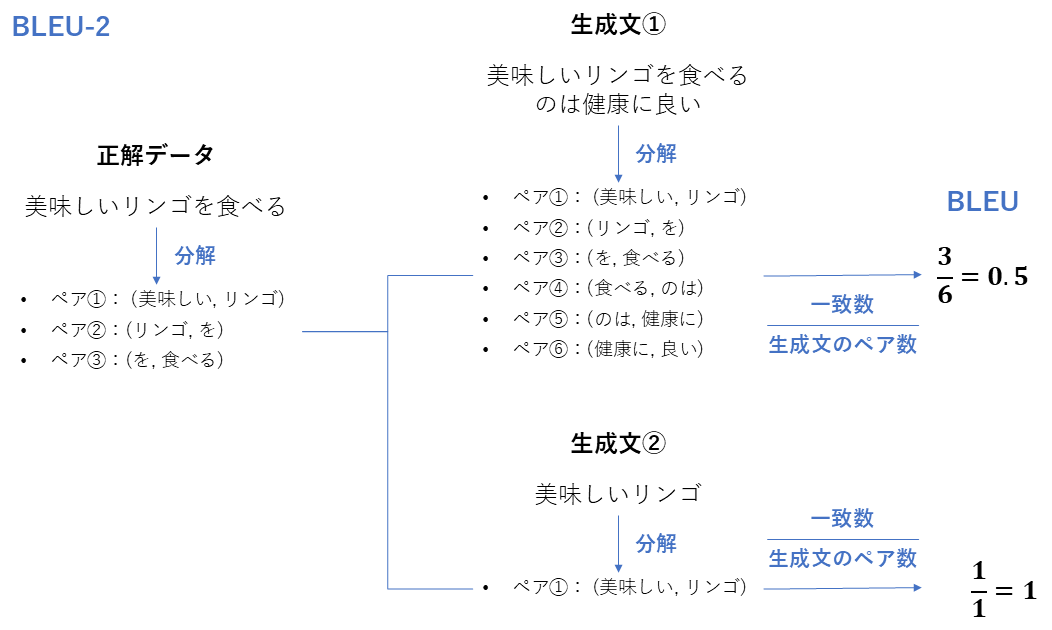
ROUGE・BLEU
| 項目 | ROUGE | BLEU |
|---|---|---|
| 評価指標名 | ROUGE (Recall-Oriented Understudy for Gisting Evaluation) | BLEU (Bilingual Evaluation Understudy) |
| 概要 | 正解文の内容を、生成文がどれだけ網羅しているか(Recall重視) | 生成文に含まれる単語(N-gram)が正解文にどれだけあるか(Precision重視) |
| 必要なデータ | ・生成回答 ・正解回答(参照文) | 同左 |
| 指標の見方 | **0~1 **正解の要素を取りこぼしていないか 要約タスク由来 | **0~1 **余計な単語を含まず、正解のフレーズを含んでいるか翻訳タスク由来 |
| 前提 | 「意味」ではなく「単語の並び」を見るため、類義語は評価されない。 | 同左 |
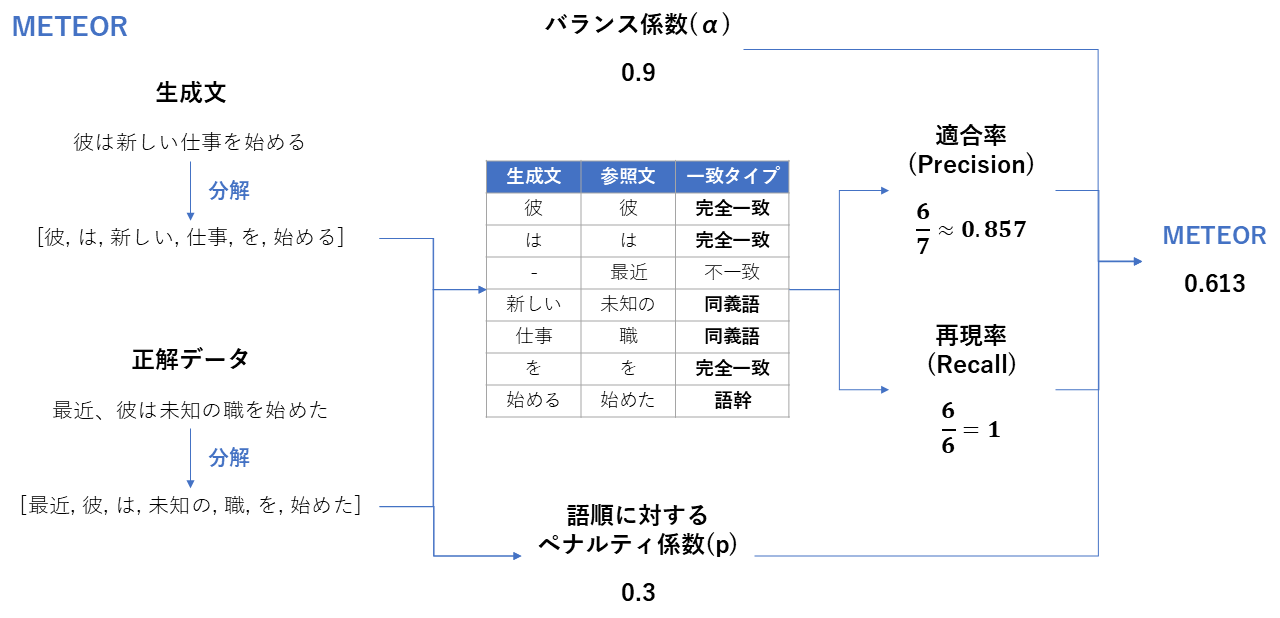
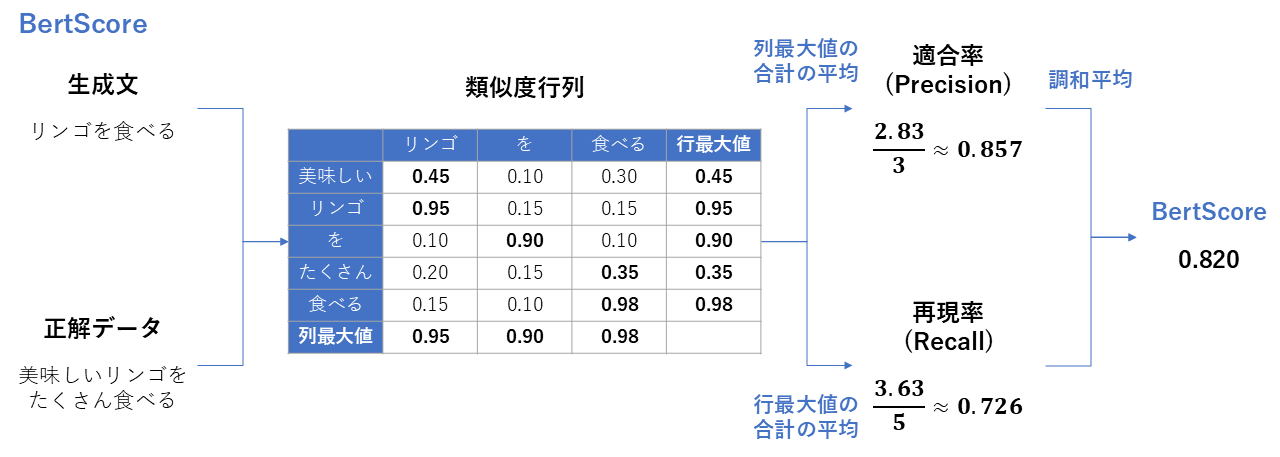
METEOR・BertScore
| 項目 | METEOR | BertScore |
|---|---|---|
| 概要 | BLEUを改良し、同義語や語幹の一致も考慮した指標 | 単語ではなく、埋め込みベクトルを使って「意味の類似度」を計算する指標 |
| 必要なデータ | ・生成回答 ・正解回答 ・辞書データ | ・生成回答 ・正解回答 ・埋め込みモデル |
| 指標の見方 | **0~1 **単語が違っても(同義語なら)評価される。 | **0~1 **文脈的に意味が近ければ高スコアになる。 |
| 前提 | 言語ごとの辞書が必要。 | 計算コストがかかる。 |
:::details 数式
\alpha: バランス係数(Precision(適合率)とRecall(再現率)のどちらを重視するかを決める重み付けパラメータ) p : ペナルティ係数(生成された文の「語順」がどれだけ正しいか(あるいは乱れているか)を表すペナルティ値)
$$ METEOR = (1-p) \frac{(\alpha^2+1)\mathrm{Precision} × \mathrm{Recall}}{\mathrm{Recall} + \alpha \mathrm{Precision}} $$ (BertScoreはコサイン類似度に基づく計算)
Perplexity (PPL)
| 項目 | 内容 |
|---|---|
| 評価指標名 | Perplexity (PPL) |
| 概要 | 生成された文章の「流暢さ」や「自然さ」を測る指標。モデル予測の不確実性を示す。 |
| 必要なデータ | ・生成テキスト ・言語モデルの確率分布 |
| 指標の見方 | 低いほど良い。 値が小さいほど、モデルが迷いなくスムーズに生成できている。 |
| 前提 | 事実の正確さ(Factuality)とは無関係である点に注意。 |

数式
N: 生成文に含まれる全トークン数 \omega_i: 生成文の先頭から数えて i 番目にあるトークン
$$ \mathrm{Perplexity} = \exp\left(-\frac{1}{N} \sum_{i=1}^{N} \log p(\omega_i | \omega_1, \omega_2, ..., \omega_{i-1})\right) $$
LLMベースの評価指標
LLM自体を審査員(Judge)として利用し意味や文脈、ハルシネーションを評価する新しい手法です。
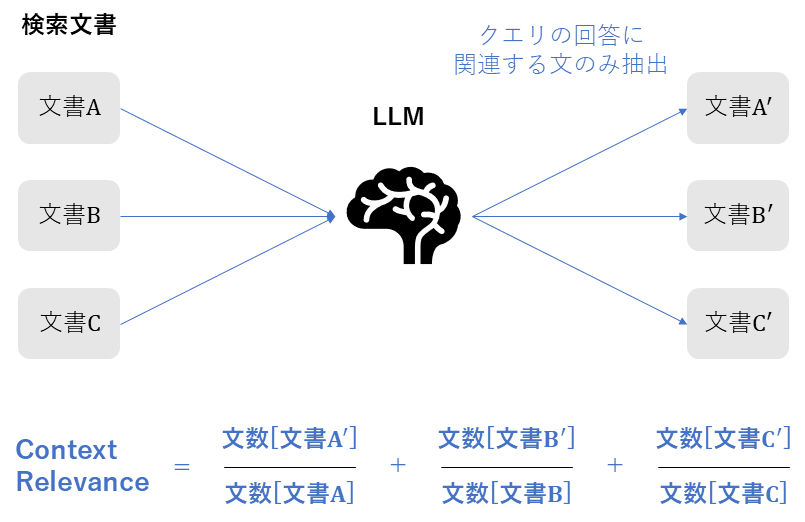
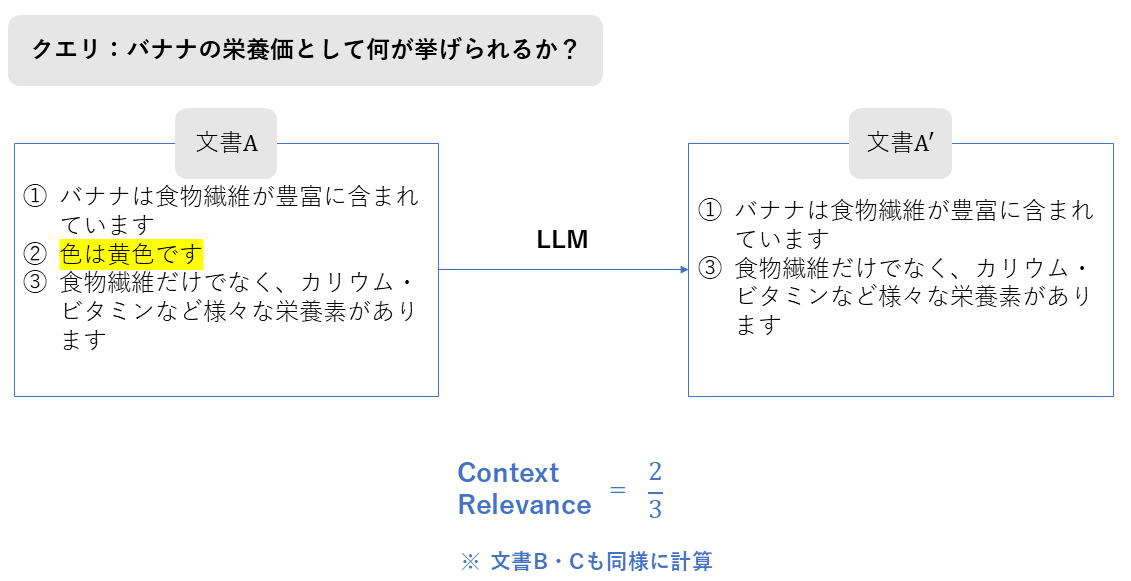
Context Relevance
本論文では「Context Relevance」という名称で個別に紹介されてはいませんが、プロンプトエンジニアリングを用いた評価の代表的なアプローチとして紹介されています。
| 項目 | 内容 |
|---|---|
| 評価指標名 | Context Relevance |
| 概要 | 検索されたコンテキスト(ドキュメント)の中に、クエリに答えるために必要な情報が含まれているかをLLMに判定させる指標(RAGAS等で採用) |
| 必要なデータ | ・クエリ ・検索されたコンテキスト |
| 指標の見方 | **0~1 **高いほど、無駄なノイズが少なく、クエリに直結する情報が含まれている。 |
| 前提 | 正解ドキュメント(Ground Truth)がなくても評価可能。 |
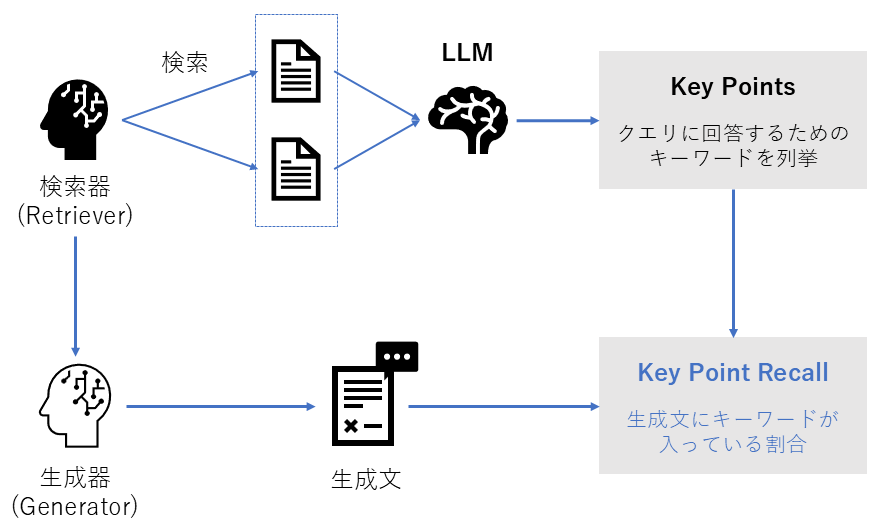
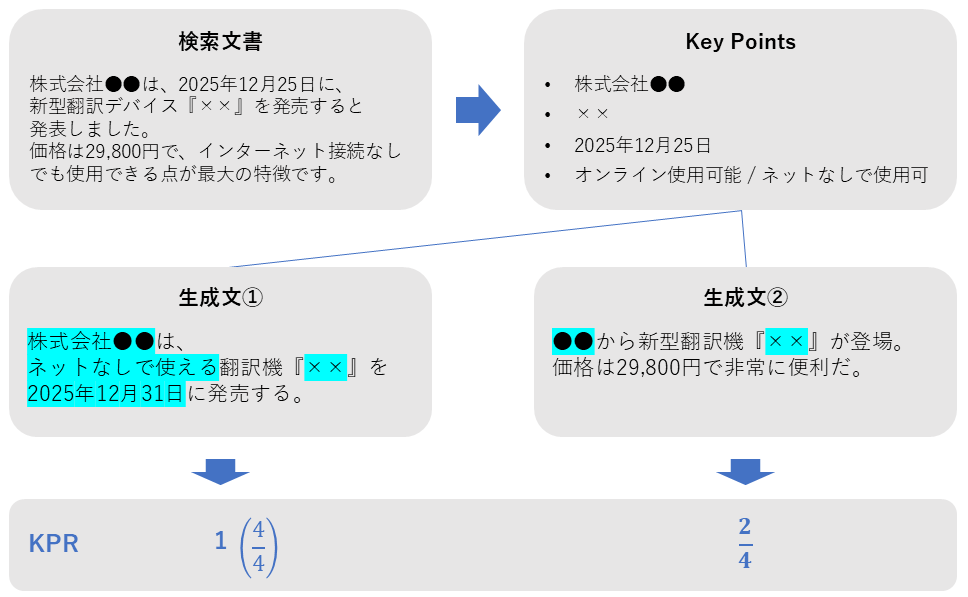
Key Point Recall (KPR)
| 項目 | 内容 |
|---|---|
| 評価指標名 | KPR (Key Point Recall) |
| 概要 | 検索されたドキュメント内の「重要なポイント(Key Points)」が、生成された回答にどれだけ含まれているかを測定する。 |
| 必要なデータ | ・検索ドキュメントから抽出したキーポイント ・生成回答 |
| 指標の見方 | **0~1 高いほど良い。**情報の利用率を示す。 |
| 前提 | 事前にキーポイント抽出の処理が必要。 |
数式
|Q|: クエリの総数 \mathbf{x}^q: クエリ q に対して事前に定義されたキーポイント(要点)の集合。 |\mathbf{x}^q|: キーポイントの総数。 \mathcal{M}(q | d^q): クエリ q と検索された文書 d^q に基づいてLLMが出力したシーケンス(回答)。 I(x, \dots): 判定関数(Indicator function)。単一のLLM出力が、事前定義されたキーポイント x を含んでいるかを判定する。 $$ \mathrm{KPR}(\cdot) = \frac{1}{|Q|} \sum_{q \in Q} \frac{\sum_{x \in \mathbf{x}^q} I(x, \mathcal{M}(q | d^q))}{|\mathbf{x}^q|} $$ ::: --- ### FactScore (FS) | 項目 | 内容 | | --- | --- | | 評価指標名 | FactScore (FS) | | 概要 | 生成文を「原子的な事実(短い文)」に分解し、それぞれが知識源に基づいているかをチェックする。 | | 必要なデータ | ・生成回答 ・知識源(Wikipedia等) | | 指標の見方 | **0~1 高いほど良い。**ハルシネーション(嘘)のなさを定量化する。 | | 前提 | 事実確認(ファクトチェック)に特化した指標。 |

:::details 数式
y: 生成されたテキスト。 |\mathcal{A}_y|: 抽出された事実の総数。 a: 集合 \mathcal{A}_y に含まれる個々の事実。 C: 外部知識源(Knowledge Base / Context)。 \mathbb{I}[\cdot]: 指示関数(Indicator function)。事実 a が知識源 C によって支持されている場合に 1、そうでない場合に 0 を返す。 $$ FS(y) = \frac{1}{|\mathcal{A}y|} \sum{a \in \mathcal{A}_y} \mathbb{I}[a \text{ is supported by } C] $$ ::: --- ### SePer (Semantic Perplexity) | 項目 | 内容 | | --- | --- | | 評価指標名 | SePer (Semantic Perplexity) | | 概要 | 生成された回答が、意味的に「正解のグループ」に分類される確信度を、LLMの確率分布を使って測定する。 | | 必要なデータ | ・生成回答 ・LLMの内部確率分布 ・クエリに対する正解回答 | | 指標の見方 | **高いほど良い **意味的なブレが少ないことを示す。 | | 前提 | LLMの内部状態へのアクセスが必要。 |
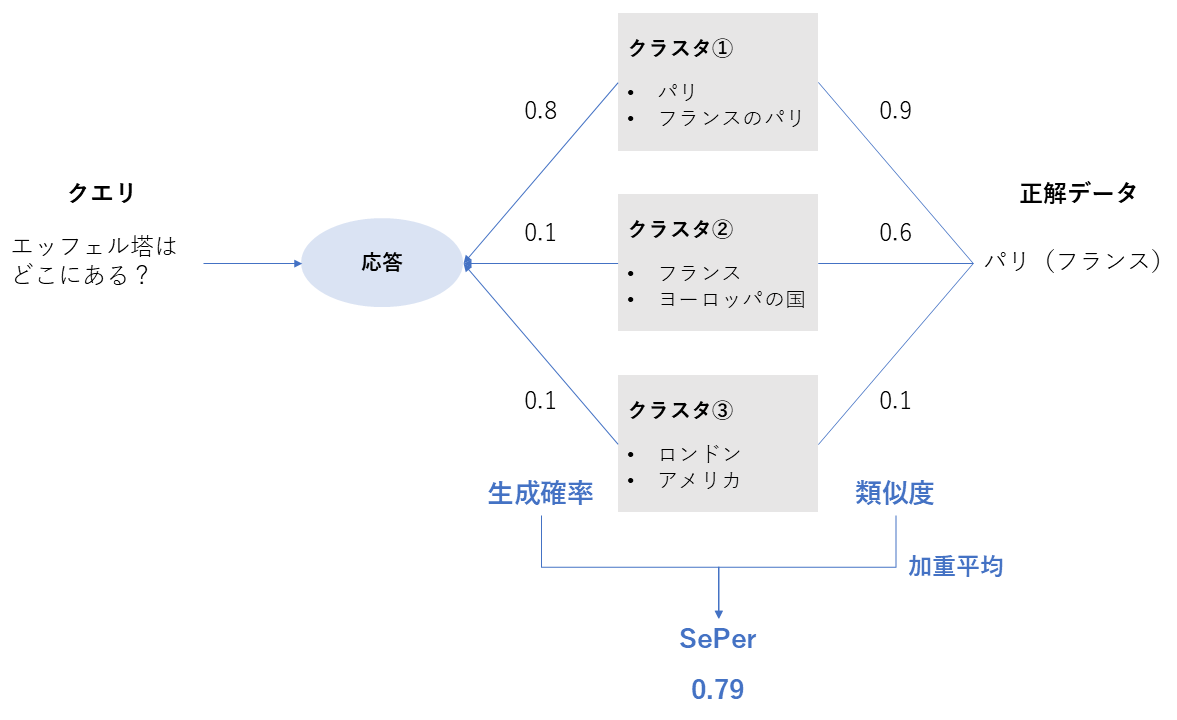
:::details 数式
M: 対象となる特定のLLM(Large Language Model)。 q: 入力クエリ。 a^: 参照回答(Reference answer)。 C_i: クラスタ集合 C に含まれる i 番目のクラスタ。 p_M(C_i|q): モデル M によって生成された回答が、クラスタ C_i にマッピングされる確率。 **k(C_i, a^): ** 意味的なクラスタ C_i と参照回答 a^* の間の距離(意味的な近さ)を測定するカーネル関数。
$$ SePer_M(q, a^) = P_M(a^ | q) \approx \sum_{C_i \in C} k(C_i, a^*) p_M(C_i | q) $$
Four Risk-aware Metrics
RAGシステムが「答えられない質問」に対して適切に振る舞えるか(リスク管理)を評価する4つの指標です。以下の4象限マトリクスに基づいて計算されます。
| システムの挙動 \ 質問の性質 | **Answerable (A) **答えられる質問 | **Unanswerable (U) **答えられない質問 |
|---|---|---|
| **Keep (K) **回答した | AK (正解) | UK (リスク/幻覚) |
| **Discard (D) **拒否した | AD (機会損失) | UD (正解) |
評価指標まとめ表
| 指標名 | 概要 | 数式 | 理想 |
|---|---|---|---|
| **Risk **(リスク) | 回答したもののうち、間違っている(幻覚)割合。 | Risk = \frac{UK}{AK+UK} | 低い |
| **Carefulness **(慎重さ) | 答えられない質問を、どれだけ適切に拒否できたか。 | Carefulness = \frac{UD}{UK+UD} | 高い |
| **Alignment **(整合性) | システムの判断(回答/拒否)が、人間の意図と一致した割合。 | Alignment = \frac{AK+UD}{Total} | 高い |
| **Coverage **(回答率) | 全質問のうち、システムが回答を生成(Keep)した割合。 | Coverage = \frac{AK+UK}{Total} | バランス |
論文中には Thrust(内部ベクトルの確信度)、Information Bottleneck(情報量の変化)、MRWR/MRLR(検索器の勝率比較)、GECE(生成文のロングテール性)、 External Context Score(外部知識の活用度)といった指標も紹介されています。 これらはLLMの内部表現(Representation)の詳細な解析や、特殊な最適化を目的とした指標であり、一般的なRAGシステムのパフォーマンス計測とは性質が異なるため、本記事での解説は省略しています。
外部評価における評価指標
内部評価が「技術的な性能」を測定するのに対し、外部評価はシステム全体の「実用的な品質」を評価します**。**論文では、主に「安全性(Safety)」と「効率性(Efficiency)」の2つの観点から評価が行われます。
安全性評価 (Safety Evaluation)
RAGシステムが、ノイズや攻撃、偏見に対してどれだけ安全に振る舞えるかを評価します。評価対象は多岐にわたりますが、論文では以下の6つの観点が重要視されています。
| 評価対象 | 概要・チェックポイント | 代表的な指標 |
|---|---|---|
| **堅牢性 **(Robustness) | 検索結果に誤った情報やノイズが混ざっていても、それに惑わされずに正解を維持できるか。 | **Resilience Rate **(ノイズ下での正解維持率) |
| **事実性 **(Factuality) | 生成された回答が事実に基づいているか。ハルシネーション(もっともらしい嘘)を含んでいないか。 | Hallucination Rate Citation Accuracy |
| **敵対的攻撃 **(Adversarial Defense) | 悪意のあるプロンプト(脱獄)や、検索DBへの「毒入れ」攻撃に対して防御できるか。 | Attack Success Rate (ASR)(攻撃成功率) |
| **プライバシー **(Privacy) | 個人情報(PII)の漏洩がないか。特定のプロンプトで機密情報を引き出せないか。 | PII Leakage Rate Extraction Success Rate |
| **公平性 **(Fairness) | 特定の性別、人種、属性に対する偏見(バイアス)を含む回答を生成していないか。 | Bias Metrics Stereotype Detection |
| **透明性 **(Transparency) | 回答の根拠(出典)が明確か。なぜその回答に至ったのかを説明できるか。 | Explanation Quality Traceability |
効率性評価 (Efficiency Evaluation)
システムが「どれだけ速く、安く動くか」というパフォーマンスとコストを評価します。実運用においては、精度以上に重視されることもあります。
| 評価対象 | 概要・チェックポイント | 代表的な指標 |
|---|---|---|
| **レイテンシ **(Latency) | ユーザーが質問してから回答が表示されるまでの待ち時間。特に対話型AIでは 「最初の1文字目が出る速さ」が重要。 | TTFT (Time to First Token) Total Latency |
| **コスト **(Cost) | システムの運用にかかる金銭的な費用。LLMのトークン課金や、ベクトルDBの維持費などが 含まれる。 | **Token Cost Cost-Effectiveness Ratio **(費用対効果比) |
データで見るRAG評価の「現在地」と「不完全性」
本記事の締めくくりとして、このサーベイ論文が580本以上の関連論文を調査して明らかにした「RAG評価のリアルな実態」について議論します。 LLMの進化に伴い、評価指標は多様化していますが、統計データを見ると「理想と現実のギャップ(不完全性)」が浮き彫りになってきました。
評価対象の偏り: 安全性に関する評価指標の不足
まず、研究者がRAGの「どの部分」を評価しているかの分布を見てみましょう。
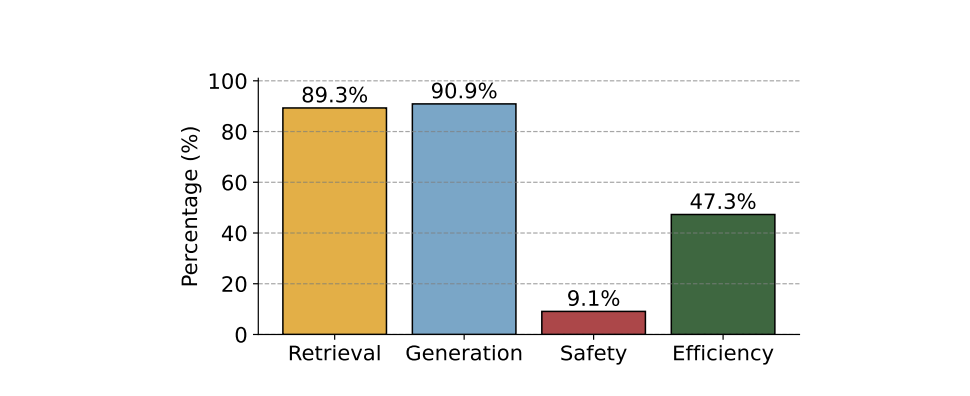 評価手法の包括性
評価手法の包括性
- 内部評価(検索・生成):約90%の論文がカバーしており、技術的な性能向上に関心が集中しています。
- 外部評価(安全性):一方で、安全性(Safety)に関する評価はわずか9.1%に留まっています。 実運用ではハルシネーションやポイズニング攻撃への対策が急務ですが、研究分野ではまだ「性能(精度)」の追求が優先されており、安全性の評価手法確立は発展途上であることがわかります。
評価指標のトレンド: なぜ「従来手法」が好まれるのか
次に、具体的にどのような「評価指標(メトリクス)」が使われているかの頻度です。大きくなっている評価指標ほど、論文で使われている評価指標であることを表しています。
 RAG研究における評価指標の頻度統計ワードクラウド
ワードクラウドを見ると、Accuracy, F1-Score, Exact Match, Recall といった「従来の評価指標」が圧倒的に大きく、支配的であることがわかります。
一方で、LLMによる評価の手法は、話題性の割にまだ研究者の間で標準的な地位を確立しきれていません。
その理由は、LLMベース評価が抱える以下の「3つのコスト」にあります。
RAG研究における評価指標の頻度統計ワードクラウド
ワードクラウドを見ると、Accuracy, F1-Score, Exact Match, Recall といった「従来の評価指標」が圧倒的に大きく、支配的であることがわかります。
一方で、LLMによる評価の手法は、話題性の割にまだ研究者の間で標準的な地位を確立しきれていません。
その理由は、LLMベース評価が抱える以下の「3つのコスト」にあります。
- 実装の労力: 評価用プロンプトの設計や調整が難しい。
- 再現性の低さ: 同じプロンプトでも、モデルのバージョンや温度(Temperature)パラメータで結果が変わってしまう。
- コスト: 評価するたびにAPI利用料や計算リソースがかかる。
今後の展望:それでもLLM評価は増えていく
しかし時系列でのトレンドを見ると、課題がありつつもLLMベースの評価手法の採用数は増加しています。
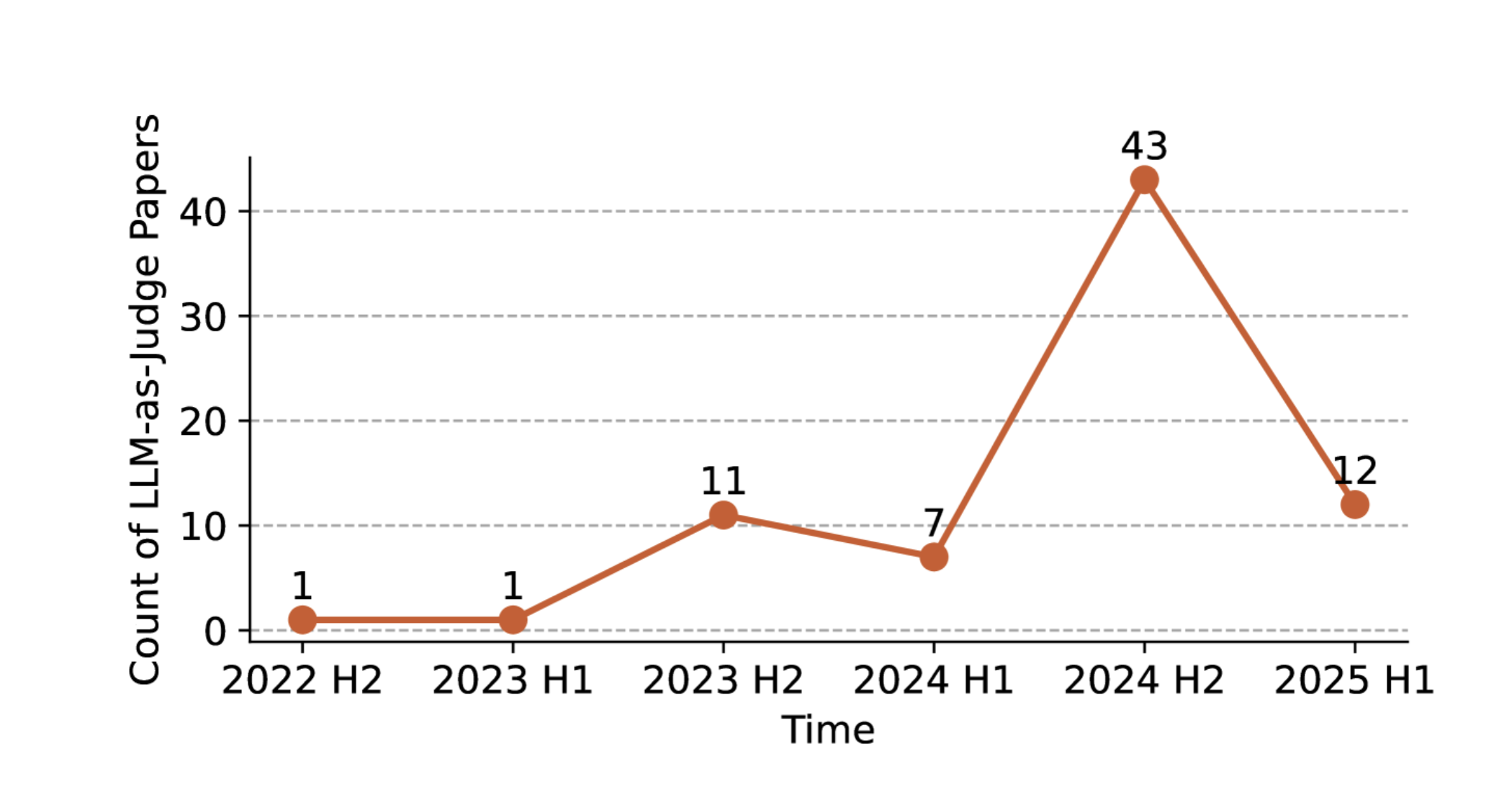 RAGにおけるLLMベースの評価を明示的に言及した論文の数
これは、LLM自体の性能向上に加え、RAGシステムが複雑化し、もはや単純な単語一致(BLEU等)では測れない「高度な推論能力」や「実世界での有用性」を評価する必要に迫られているためです。今後は、LLM評価の「ブラックボックス性」や「不安定さ」を克服するための、より堅牢なフレームワーク(RAGASの進化版など)が登場することが期待されます。
RAGにおけるLLMベースの評価を明示的に言及した論文の数
これは、LLM自体の性能向上に加え、RAGシステムが複雑化し、もはや単純な単語一致(BLEU等)では測れない「高度な推論能力」や「実世界での有用性」を評価する必要に迫られているためです。今後は、LLM評価の「ブラックボックス性」や「不安定さ」を克服するための、より堅牢なフレームワーク(RAGASの進化版など)が登場することが期待されます。
課題と今後の方向性
冒頭で述べた「4つの課題」について、本記事での解説を踏まえて改めて整理します。これらは、私たちがこれからRAGを開発・評価する上で向き合うべきテーマです。
- 評価自体の信頼性(脱ブラックボックス): LLMに評価させる場合、「なぜその点数なのか?」の説明責任や、評価者としてのLLMのバイアスをどう取り除くかが課題となります。
- コストと効果のバランス: すべての指標を測定するのは現実的ではありません。「開発時はRecallとRAGAS」「リリース前は人手評価と安全性チェック」のように、フェーズに応じた評価戦略が必要です。
- 「思考プロセス」の評価: 単に回答が合っているかだけでなく、「正しい手順で推論できたか」を評価する指標が必須になります。
- 多言語対応: 現在のフレームワークは英語中心です。日本語特有のニュアンスを正しく評価できるデータセットや指標の整備が待たれます。
おわりに
本記事では、サーベイ論文をベースに、RAG評価の全貌を「内部/外部」「従来/最新」の視点から解説しました。RAGの開発において、「評価」はゴールではなく、改善のための「羅針盤」です。 Recallが高くてもユーザーが満足するとは限りませんし、RAGASのスコアが良くても安全とは限りません。 重要なのは、一つの指標に固執するのではなく、「自分のRAGシステムにとって、今一番守るべき品質は何か?(精度か、速度か、安全性か)」を見極め、適切な指標を組み合わせて継続的にモニタリングすることです。 まだ「完全な評価手法」が存在しないこの過渡期において、本記事が皆さまのRAG開発における羅針盤選びの一助となれば幸いです。
