1. はじめに
大規模言語モデル(LLM)の進化によって、ビジネスでも様々な場面でAIの活用が広がっています。しかし、LLMは優れた推論能力を持つ一方で、最新情報や学習で使われなかったデータを知識として活用できないという限界があります。 この限界を克服するため、LLMの推論時に外部の知識ソースを検索・統合する仕組みとしてRetrieval-Augmented Generation(RAG)が台頭しています。しかしながら、RAGはテキストのみの知識に焦点を当てており、現実世界の文書に含まれるマルチモーダルな視覚情報(画像、表、数式など)を無視しています。
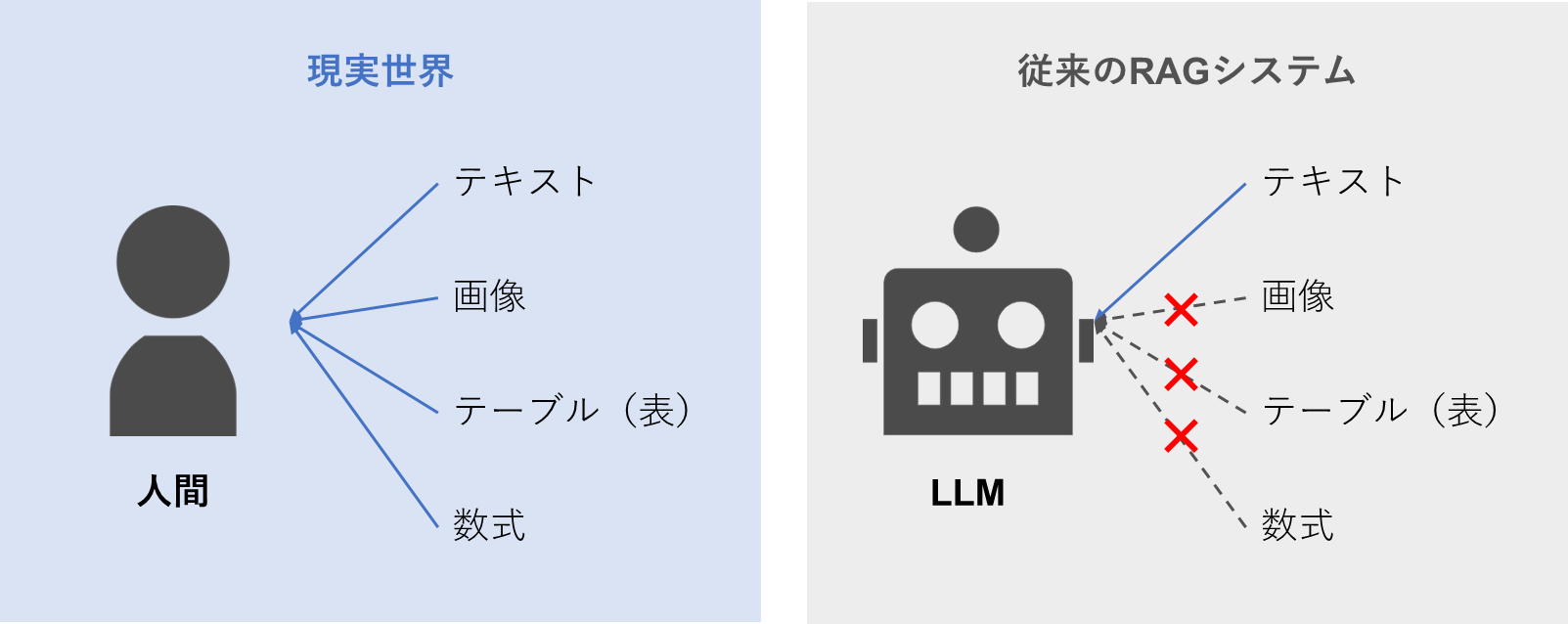 現実世界と従来のRAGシステムとの視覚情報の活用の違い(筆者作成)
現実世界と従来のRAGシステムとの視覚情報の活用の違い(筆者作成)
この記事では、PDFの文書からあらゆる形式の情報を知識として包括的に検索可能にするフレームワーク「RAG-Anything」を提唱する論文(2025年10月14日公開)を紹介します。
https://arxiv.org/html/2510.12323v1
対象者 下記のような課題を抱えている方を対象にしています。
- テキスト以外の情報をRAGに使う方法が分からない
- RAGシステムを導入しているが、LLMの回答に知識として上手く活用されていない
- 最新のRAGの技術動向を把握しておきたい
本記事の構成
| セクション | 概要 |
|---|---|
| 2. RAG-Anythingのフレームワーク | RAG-Anythingのフレームワークを3つの主要なコンポーネントに分けて説明します。 ・インデックス構築(2.1) ・検索(2.2) ・回答生成(2.3) |
| 3. 評価 | RAG-Anythingの性能のベースラインモデルとの比較結果を説明します。結果として、ドメイン汎化能力と長文コンテキストにおける高い性能があることが明らかになりました。 |
2. RAG-Anythingのフレームワーク
既存のテキスト中心のRAGの限界を克服して、効果的なマルチモーダルなRAGを実現するためには下記のような新しい要件が生じます。
- 異なるデータ型を扱える統一的なインデックス構築
- マルチモーダルなデータ間の意味的対応関係を保持するクロスモーダル検索
- マルチモーダルな情報を統合した高度な知識生成
RAG-Anything(RAGA)は3つの主要なコンポーネントで構成されます。マルチモーダルな情報から生成された知識を検索・利用できるようにする統一的なアプローチを導入します。
-
ユニバーサル・インデックシング(Universal Indexing for Multimodal Knowledge)
-
クロスモーダル適応型検索(Cross-Modal Adaptive Retrieval)
-
知識強化型応答生成(Knowledge-Enhanced Response Generation)
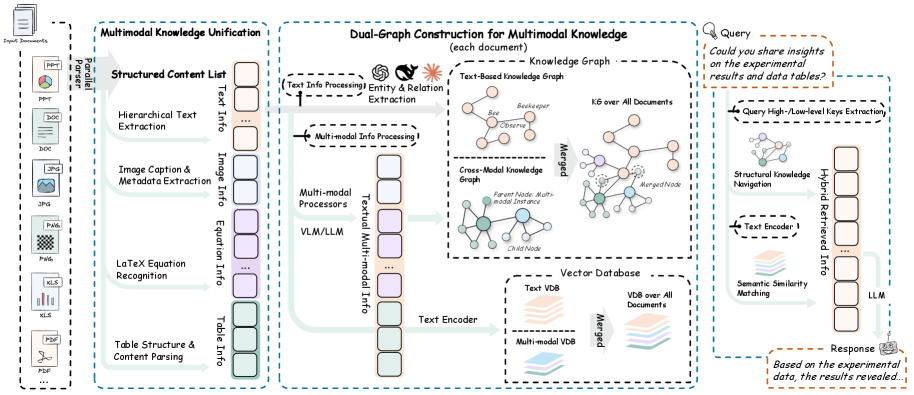 RAG-Anythingのフレームワーク図
RAG-Anythingのフレームワーク図
2.1 マルチモーダル知識の統一表現
RAGAはマルチモーダルなコンテンツを統一的かつ検索に適した形式で表現するために「マルチモーダル知識の統一化(Multimodal Knowledge Unification)」というプロセスを導入しています。 このプロセスでは、生データの構造と意味を保持したまま「原始的な知識単位(Atomic Knowledge Units)」に分解します。生データのモダリティごとに特化した解析器(パーサ)を利用して高度な知識抽出を行います。
| モダリティ | 抽出方法 |
|---|---|
| テキスト | 段落やリスト単位で分割 |
| 画像 | キャプションや参照関係(図と本文部分を結ぶ情報)のようなメタデータを抽出 |
| 表(テーブル) | 見出しと値を含む構造的なセルに分解 |
| 数式 | 記号表現に変換 |
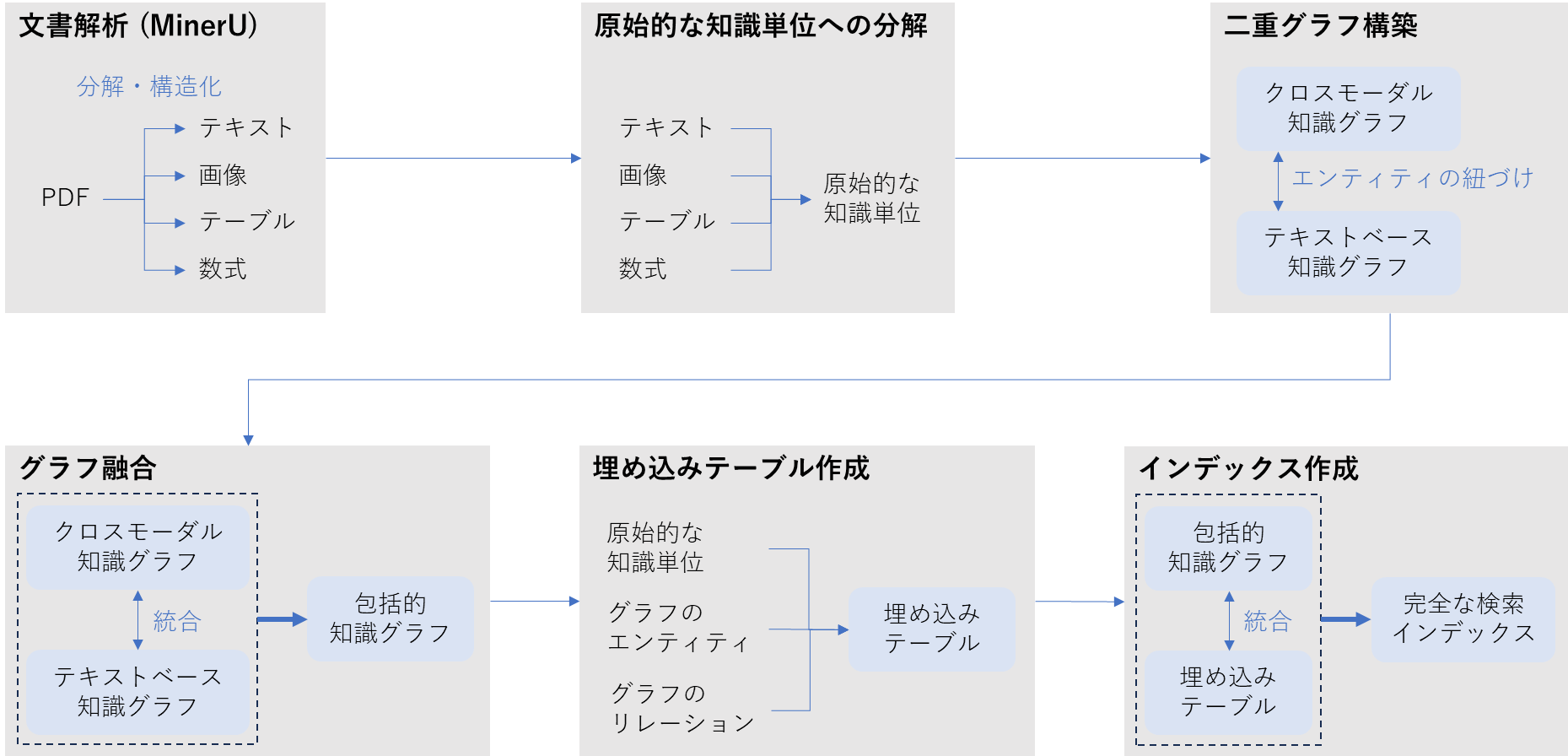 RAGAのインデックス構築の流れ(筆者作成)
RAGAのインデックス構築の流れ(筆者作成)
原始的な知識単位 文書を構成する最小の意味的に独立した情報片のこと。 = RAGAがインデックス化の最初に切り出す最小のコンテンツ要素。
MinerU PDF形式の文書を「テキスト+画像+表+数式」の部品ごとに分解して構造化する文書分解エンジン(Document Parsing Engine)
2.1.1 マルチモーダル知識の二重グラフ構築
「マルチモーダル知識の統一化」によって、マルチモーダルな情報を統一的に扱えるようになりますが、単一のグラフを構築するとモダリティ固有の構造的な意味が失われる恐れがあります。 RAGAはこの問題を解決するため、以下のような「二重グラフ構築戦略」を導入しています。
-
非テキスト情報の「クロスモーダル知識グラフ」を構築する
-
テキスト情報の「テキストベース知識グラフ」を構築する
-
「エンティティの紐づけ」を通じて、両者のグラフを統合する
クロスモーダル知識グラフ(Cross-Modal Knowledge Graph) 非テキスト情報(画像・表・数式)から文書の文脈を考慮したうえで2種類のテキスト表現を生成し、グラフを構築します。
- 詳細な記述:クロスモーダル検索に最適化された説明文
- エンティティ要約:エンティティの名称・データ型・説明などの主要属性
テキストベース知識グラフ(Text-Based Knowledge Graph) テキスト情報に対して固有表現抽出(NER)と関係抽出(RE)を実行し、エンティティとそれらの意味関係を特定します(従来型の知識グラフ構築手法)。
エンティティの紐づけ(Entity Alignment) 2つのグラフ間で、同一のエンティティを紐づけます。
2.1.2 グラフ融合とインデックス作成
クロスモーダル知識グラフとテキストベース知識グラフは、文書における意味を相互に補完する関係にあります。両者を統合することで、視覚的意味と言語的意味の関連性を活用できます。
エンティティの紐づけとグラフ融合(Entity Alignment and Graph Fusion) エンティティ名を主キーとして両グラフを統合した「包括的知識グラフ(Comprehensive Knowledge Graph)」を生成します。
密ベクトル表現の生成(Dense Representation Generation) 効率的な類似度検索を可能にするため、インデックス構築過程で生成された全てのコンポーネントから埋め込みテーブルを構築します。 各グラフのエンティティ・リレーション・チャンク(原始的な知識単位)に対して適切なエンコーダを用いてベクトル化を行います。 最終的には、包括的知識グラフと埋め込みテーブルが「完全な検索インデックス(Complete Retrieval Index)」を構成し、視覚的・構造的意味と言語的意味を踏まえたクロスモーダル検索を可能にします。
2.2 クロスモーダル・ハイブリッド検索
RAGAの検索段階では「完全な検索インデックス」を用いて、ユーザのクエリに関連する知識コンポーネントを特定します。 従来のRAGでは、テキストの類似度のみを手掛かりとして、画像・テーブル・数式などのマルチモーダルな情報を扱うことはできません。その課題を克服するため、「クロスモーダル・ハイブリッド検索」を用います。
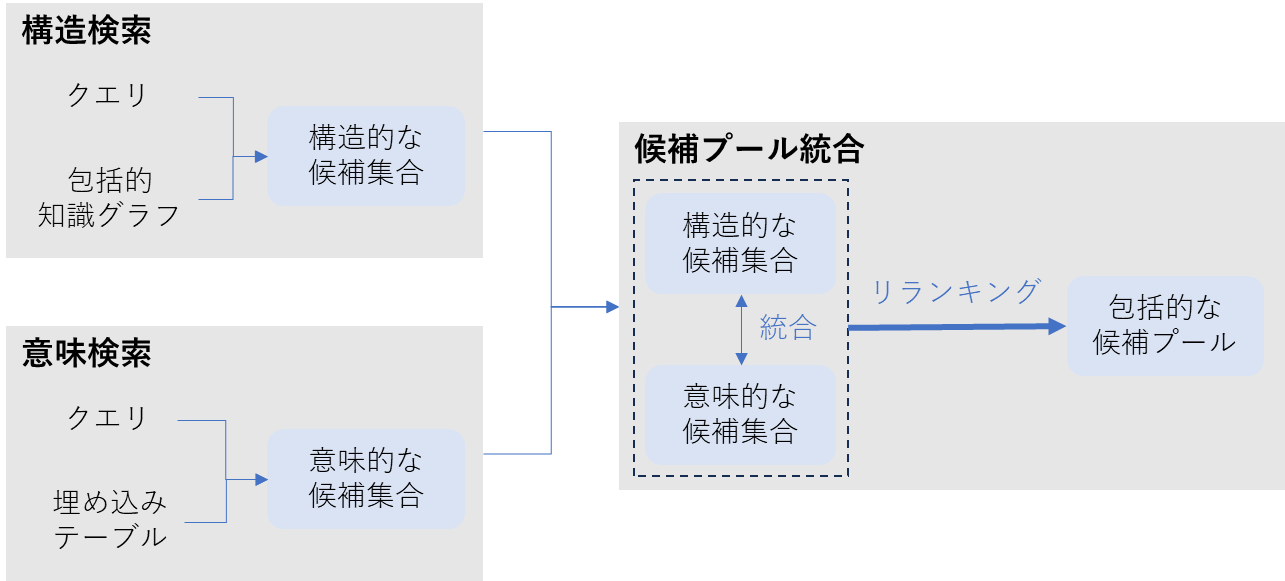 RAGAの検索の流れ(筆者作成)
RAGAの検索の流れ(筆者作成)
2.2.1 モダリティ対応クエリエンコーディング(Modality-Aware Query Encoding)
ユーザのテキストクエリを使って、マルチモーダルコンテンツである「完全な検索インデックス」にアクセスし、検索できるようにクエリをエンコーディングします。
- ユーザのクエリに対してモダリティ対応解析を行い、モダリティ指示語(例:「figure」「chart」「table」「equation」など)を抽出
- インデックス作成時と同一のエンコーダを用いて、クエリをテキスト埋め込みに変換
2.2.2 ハイブリッド知識検索アーキテクチャ(Hybrid Knowledge Retrieval Architecture)
ユーザのクエリとインデックスとの関連性は、「明示的な構造的関係」と「暗黙的な意味的関係」の両方に現れるため、RAGAでは二重の検索メカニズムを採用しています。
- 構造的知識ナビゲーション(Structural Knowledge Navigation) エンティティやモーダル関係をまたぐ多段階の推論を行います。 キーワード照合とエンティティ認識を用いてグラフ内の関連要素を特定し、周辺のノードやリレーションを含める(近傍拡張)ことによって、構造的な候補集合を生成します。
- 意味的類似度マッチング(Semantic Similarity Matching) グラフ内では接続していないが、意味的に関連するコンポーネントを発見するために、クエリ埋め込みと埋め込みテーブルとの間で密ベクトル類似度検索を行います。 これによって、明示的な構造関係が存在しない場合でも、意味的に関連するコンテンツを発見し、上位k件を意味的な候補集合を抽出します。
2.2.3 候補プール統合(Candidate Pool Unification)
構造的な候補集合と意味的な候補集合を統合して、包括的な候補プールを作成します。 単純な統合では、それぞれの検索経路が持つ証拠としての強さ(重要性)を反映できないという課題があります。そのため、下記の複数の要素を考慮したスコアをランキングに使用します。
- グラフトポロジーに基づく構造的な重要度
- 埋め込み空間での意味的な類似度
- クエリから推定されるモーダリティの優先度
2.3 検索から統合
マルチモーダルな情報を使って効果的にクエリに回答するためには、視覚コンテンツ(画像・テーブル・数式)の意味を維持しつつ、テキスト情報との整合性を維持して統合し、回答を生成することが求められます。 統合プロセスでは、ユーザのクエリ、テキストコンテキスト、オリジナルの視覚データを視覚言語モデル(Vision-Language Model)に入力して回答を生成します。
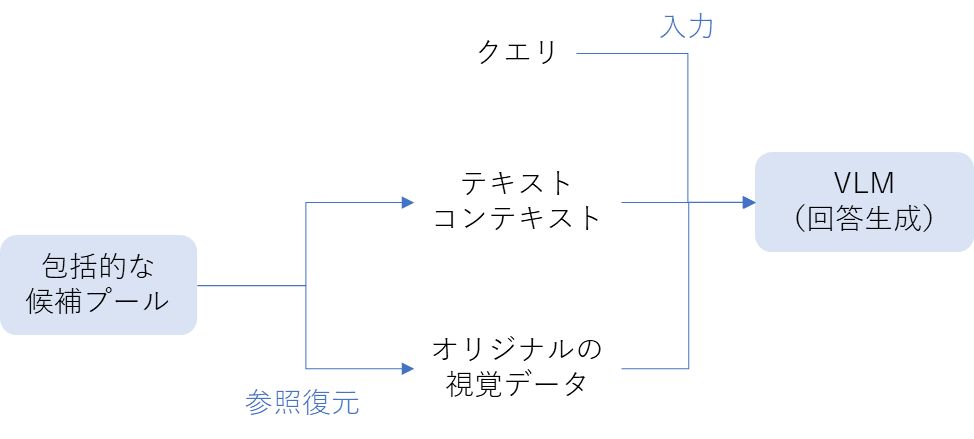 RAGAの回答生成の流れ(筆者作成)
RAGAの回答生成の流れ(筆者作成)
- テキストコンテキストの構築(Building Textual Context) 上位ランキングの候補プールから下記の内容を含む構造化テキストコンテキストを構築します。
- エンティティの要約(Entity summary)
- リレーションシップの記述(Relationship descriptions)
- チャンクの内容(Chunk contents) モダリティや階層構造を示す区切り記号を用いて連結することで、LLMがマルチモーダルな情報を効果的に解析・推論することができます。
- 視覚コンテンツの復元(Recovering Visual Content) 視覚コンテンツに対応するチャンクについては、オリジナルの視覚データを参照復元(Dereferencing)して取得します。
3. 評価
RAGAの性能を評価するために、下記のデータセットとベースラインモデルが用いられました。 ベースラインと比較して、ドメイン汎化能力と長文コンテキストにおける高い性能が明らかになりました。
データセット 現実世界の複雑さと多様さを反映するため、2つの高難度のマルチモーダルDQA(Document Question Answering)ベンチマークを採用しました。単なるテキストだけでなく、画像・テーブル・数式などの視覚情報を踏まえた質問と回答のペアを備えていることが特徴です。
- DocBench (Zou et al., 2024)
5つのドメインを対象とする229件のPDF文書
- 学術(Academia)
- 金融(Finance)
- 政府(Government)
- 法律(Laws)
- ニュース(News)
- MMLongBench (Ma et al., 2024)
特に長文コンテキストに焦点を当てた、7つのドメインを対象とする135件のPDF文書
- 研究レポート・研究紹介(Research Reports/Introductions)
- チュートリアル・ワークショップ資料(Tutorials/Workshops)
- 学術論文(Academic Papers)
- ガイドブック(Guidebooks)
- パンフレット・紹介資料(Brochures)
- 行政・産業文書(Administration/Industry Files)
- 金融レポート(Financial Reports)
ベースラインモデル RAGAとの比較対象として、3つのモデルを採用しました。
| モデル | 特徴 |
|---|---|
| GPT-4o-mini | テキストと画像を理解できるマルチモーダルな言語モデル。 128kトークンのコンテキスト・ウィンドウを持ち、文書全体を直接処理可能。 |
| LightRAG (Guo et al., 2024) | グラフベースの検索とベクトルベースの検索の2段階の検索機構を備えたグラフ強化型RAG。ただし、テキストのみに処理が制限されている。 |
| MMGraphRAG (Wan & Yu, 2025) | テキストと画像を同時に統合したグラフを構築するマルチモーダルRAGフレームワーク。ただし、テーブルや数式は単なるテキストとして用いる。 |
3.1 ベースラインとの性能比較
モデルの性能は、モデルが生成した回答の正答率において比較されています。なお、モデルが生成した回答が正答であるか(文書の回答と同じ意味であるか)はLLM(GPT-4o-mini)を使って判断しています。
3.1.1 ドメイン汎化能力
RAGAは文書のドメインに関わらず、質問に対する正答率が高いことが明らかになりました。
- DocBenchを使った場合の正答率比較
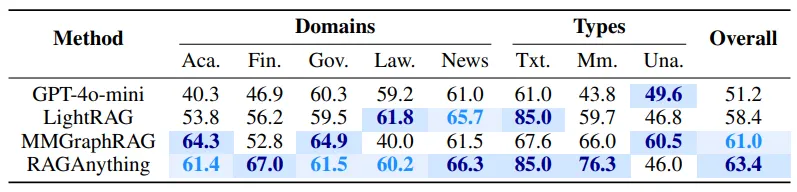
Typesの見方
- Txt.:テキストのみの文書
- Mm.:マルチモーダルの文書
- Una.:質問の回答が文書中に含まれていない文書
- MMLongBenchを使った場合の正答率比較
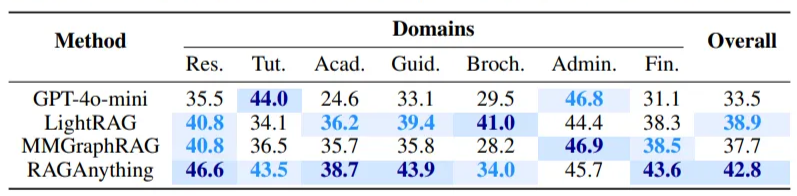
3.1.2 長文コンテキストにおける高い性能
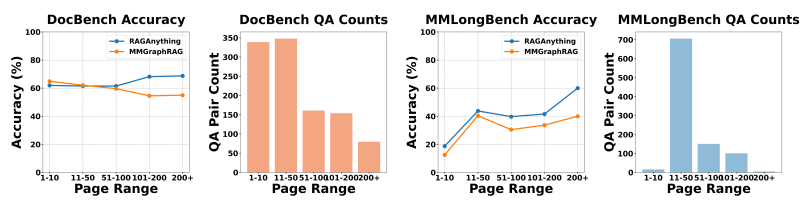
RAGAは文書のコンテキストが増加するにつれて、他のモデルよりも高い正答率を達成しています。質問に関連する情報が複数のモーダリティやセクションにまたがるケースにおいて優れています。
- MMGraphRAGとの正答率比較 文書のページ数(X軸)が増加するにつれて、MMGraphRAGとの正答率(Y軸)の差が拡大しています。
3.2 アーキテクチャの構成要素の寄与度
RAGAアーキテクチャの主要な構成要素を定量的に評価したところ、グラフ構築が性能向上の主な要因になったことが示唆されています。 具体的には、下記2つのケースを用いたアブレーション・スタディを実施しています。
- Chunk-only:グラフ構築を省略して、従来のチャンクベースの検索のみに依存
- w/o Reranker:リランキングを省略して、グラフ構造は保持
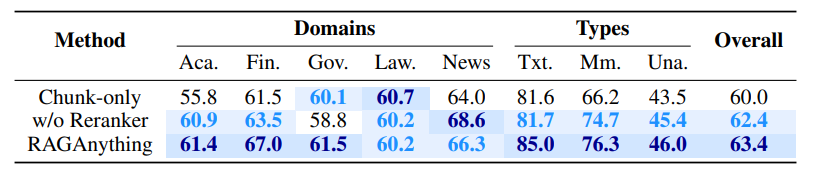 DocBenchを用いたアブレーション・スタディの正答率比較結果
DocBenchを用いたアブレーション・スタディの正答率比較結果
アブレーション・スタディ モデルやシステムの構成要素を意図的に取り除いたり変更したりして、各要素が性能にどれだけ貢献しているかを調べる手法
おわりに
本記事では、従来のRAGが抱えていたテキスト中心であるがゆえの限界を克服する新しいフレームワーク「RAG-Anything」を紹介しました。 RAG-Anything は、PDF文書に含まれるテキスト・画像・表・数式といったあらゆる視覚情報を統合的に知識として扱える点が大きな特徴です。その結果、従来のRAGでは困難だったマルチモーダルな情報検索と回答生成を実現し、ベースライン比較でも高い性能を示しました。 RAGシステムにおいて 「テキスト以外の視覚情報をどう取り込むか」 は避けて通れない課題であり、RAG-Anything はその問題に対する有力な解決策のひとつになる可能性があります。 なお、「RAG-Anythingを実際に構築し、従来のRAGと具体的に何が違うのか」を検証した記事も公開しています。より実践的な内容に興味のある方は、ぜひ併せてご覧ください。
https://blog.elcamy.com/posts/ccdeca6b/
参考
https://arxiv.org/html/2510.12323v1