はじめに
9月23日、Difyの新機能「ナレッジパイプライン(Knowledge Pipeline)」がリリースされました。煩雑な企業データを大規模言語モデル(LLM)向けの高品質なコンテキストへと変換する、RAG(Retrieval-Augmented Generation)データ処理パイプラインです。 従来のRAGシステムの課題の1つとして「処理プロセスのブラックボックス化」が挙げられます。このナレッジパイプラインでは、元データからコンテキストへの変換プロセス全体を可視化・コントロールすることができるようになっています。
この記事では、予め用意されたパイプラインのテンプレートについて紹介します。
RAGの精度向上でお悩みの方へ 「自社のデータ形式に合わせた最適なRAG基盤を作りたい」「データクレンジングからプロに任せたい」という企業様向けに、Dify導入ソリューションをご用意しています。RAGの精度向上でお悩みの際は、まずはお気軽に無料相談をご活用ください!
環境
- Dify クラウド版 v1.9.1
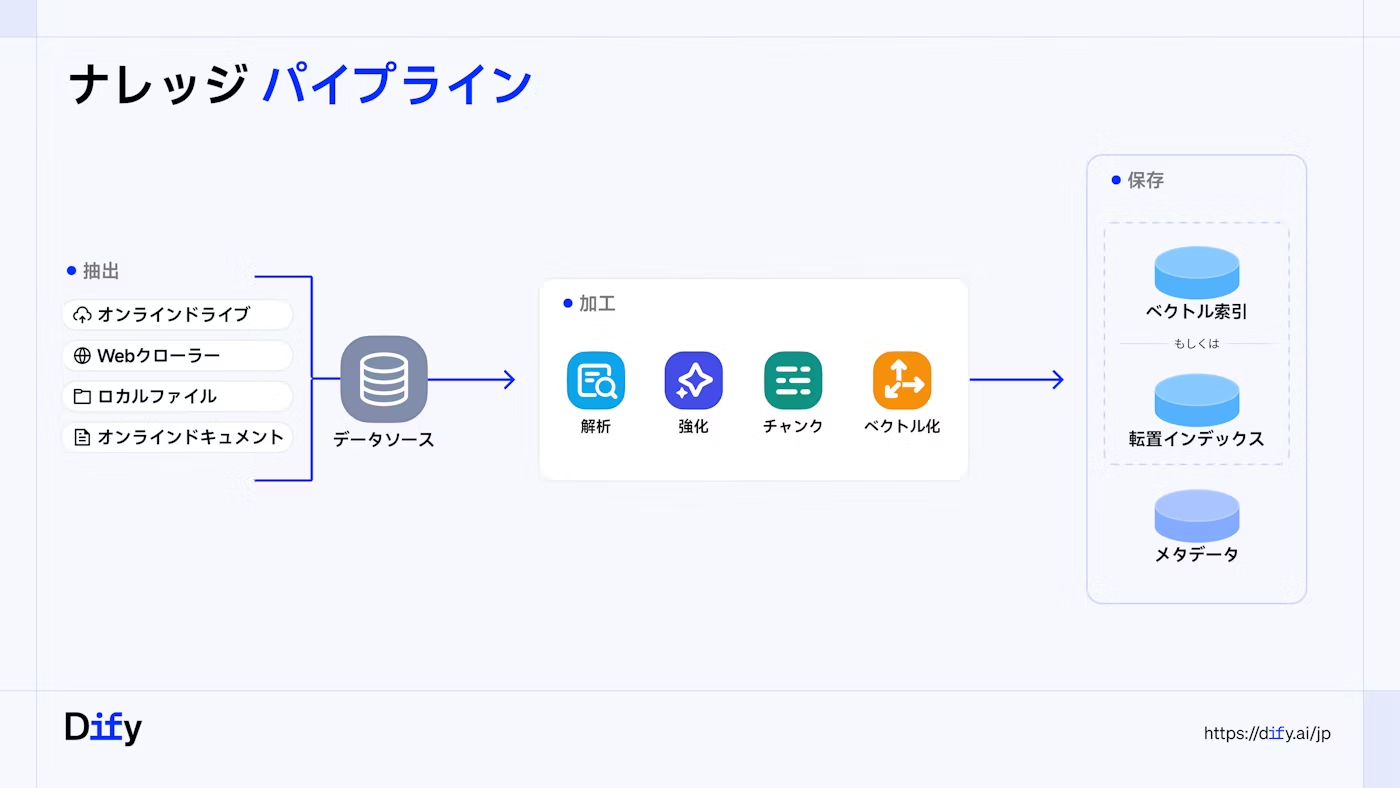
ナレッジパイプラインの概観
ナレッジパイプラインの大まかなプロセスは以下の3つで構成されています。
1. Extract(データ抽出)
多様なデータソースからデータを収集・取り込みます。
- 概要: ローカルファイル、クラウドストレージ、オンラインドキュメント、Webクローリングなど、多様なデータソースから並行してデータを取り込むことができます。
- 特徴: テキストだけでなく、画像、音声、動画といったマルチモーダルコンテンツの統一処理を可能にします。
2. Transform(データ加工)
抽出したデータをLLMでの利用に適した形に変換します。このプロセスは複数のステップに分かれます。
- 解析(Parse): ファイルタイプ別に最適なパーサー(解析器)を選択し、ドキュメントの論理構造を維持しながら情報を抽出します。
- 強化(Enrich): LLMを活用し、エンティティ抽出、要約生成、タグ分類などを行い、コンテキストの質を向上させます。
- チャンキング(Chunking): データを適切な大きさの「チャンク(断片)」に分割します。一般的な分割方法(General)に加え、親と子の階層構造を維持する(Parent-Child)や、質問応答ペアを生成する(Q&A戦略)など、コンテンツの特性に応じた最適な戦略を選択できます。
- ベクトル化(Embedding): 加工されたデータを、検索に適したベクトル形式に変換します。
3. Load(インデックス保存)
加工・ベクトル化した知識を、LLMが検索・利用できるようにインデックスとして保存します。
- 概要: 高品質なベクトルインデックスと経済的な転置インデックスを保存します。
- 特徴: メタデータタグによる正確なフィルタリングや、権限制御を行うことができ、検索時の精度とセキュリティを高めます。
**ベクトルインデックス **「意味の近さ」によってナレッジを検索できるようにする保存方法。チャンクを数値ベクトルに変換し、類似度(ベクトル距離)による検索を可能にします。 **転置インデックス **キーワードによってナレッジを検索できるようにする保存方法。チャンクごとに指定した数の重要キーワードを抽出して、キーワードによる検索を可能にします。
テンプレート
v1.9.1では5種類のテンプレートが提供されています。
| パイプライン | チャンク戦略 | 概要 |
|---|---|---|
| 一般文書処理 | 汎用 | ドキュメントを汎用段落ブロックに分割し、経済的なインデックスを採用。大量のドキュメントの高速処理に適しています。 |
| 長文書処理 | 親子 | 具体的なコンテンツを正確に特定しながら、完全なコンテキストを保持。技術文書や研究レポートなどの長編資料に最適です。 |
| 文書形式変換 | 親子 | このテンプレートはDOCX・XLSX・PPTXなどのOffice形式のファイルをMarkdownに変換し、処理効率と互換性を向上させます。 |
| インテリジェントQ&A生成 | Q&A | ドキュメントから重要情報を自動抽出して質問応答ペアを生成し、長文ドキュメントを正確な知識ポイントに変換します。 |
| Q&A表データ抽出 | Q&A | 表から指定列を抽出して構造化された質問応答ペアを生成。自然言語でのデータ検索を可能にします。 |
1. 一般文書処理
データソース(インプット)
- ファイルアップロード(PDF、XLSX、DOCXなど)
- クラウドストレージ(Google Drive)
- オンラインドキュメント(Notion)
- Webクローラ(Jina Reader、Firecrawl)
プロセス
プロセスの全体像
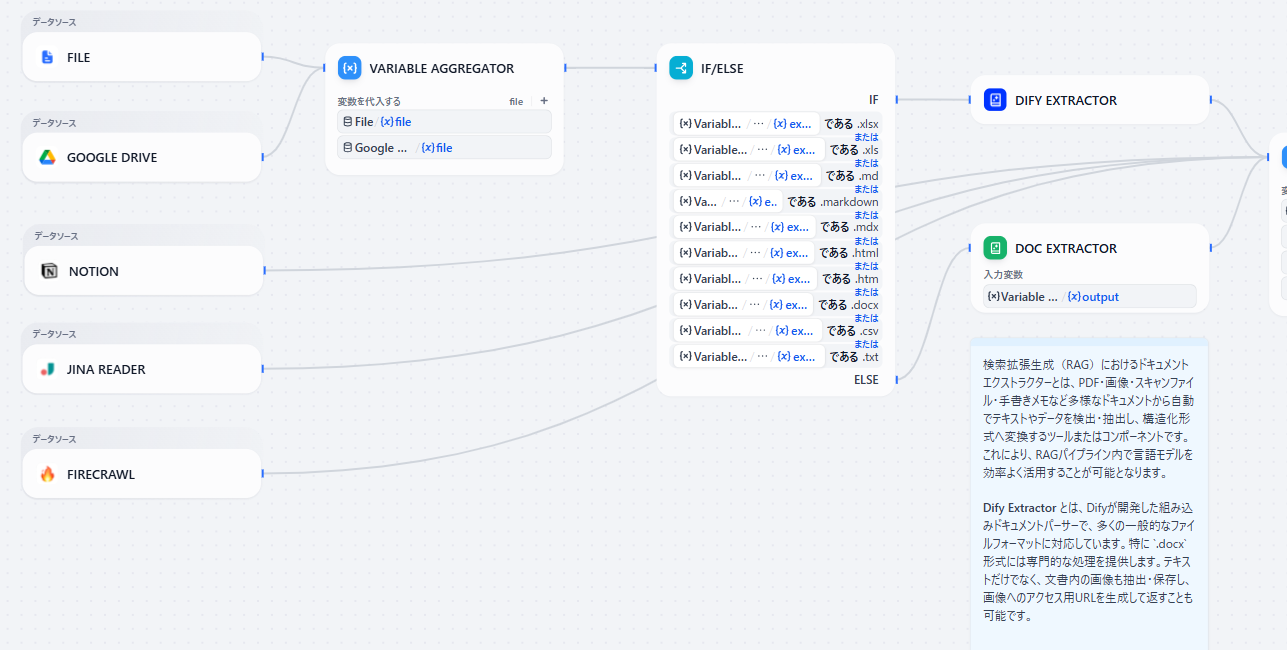
- データソース: パイプラインの起点としてデータソースを取り込みます。
- データソースが **FILE **または **GOOGLE DRIVE **の場合
- VARIABLE AGGREGATOR: 同一処理をするために変数代入
- **IF/ELSEブロック: **ファイルの拡張子によって分岐
- **Extractor(抽出器): **ドキュメントの解析・構造化
- DIFY EXTRACTOR: Excel(
.xlsx,.xls)、マークダウン(.md,.markdown,.mdx)、HTML(.html,.htm)、Word(.docx)、テキスト(.csv,.txt)に対応 - DOC EXTRACTOR: 上記以外のファイル形式に対応
- DIFY EXTRACTOR: Excel(
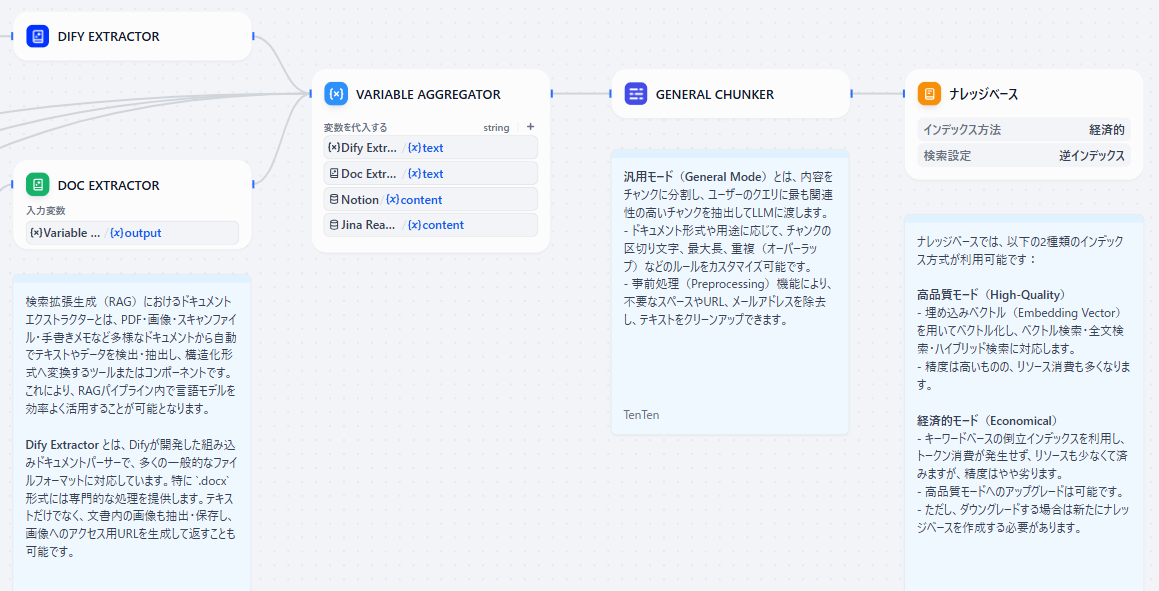
- **VARIABLE AGGREGATOR: **すべてのデータソースにその後同一処理をするために変数代入
- **GENERAL CHUNKER: **抽出したテキストをチャンク構造が「汎用モード」になるように構造化します。この際、事前処理として、テキストをクリーンアップ(不要なスペースやURLなどを除去)します。
- KNOWLEDGE BASE: パイプラインで処理・変換されたデータをナレッジベースに保存します。
準備
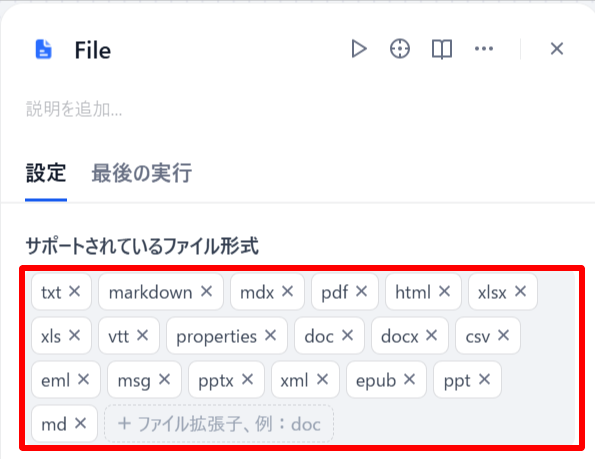
-
FILEブロックでアップロードするファイル形式を指定します。赤枠内のファイル形式が使用可能です。
-
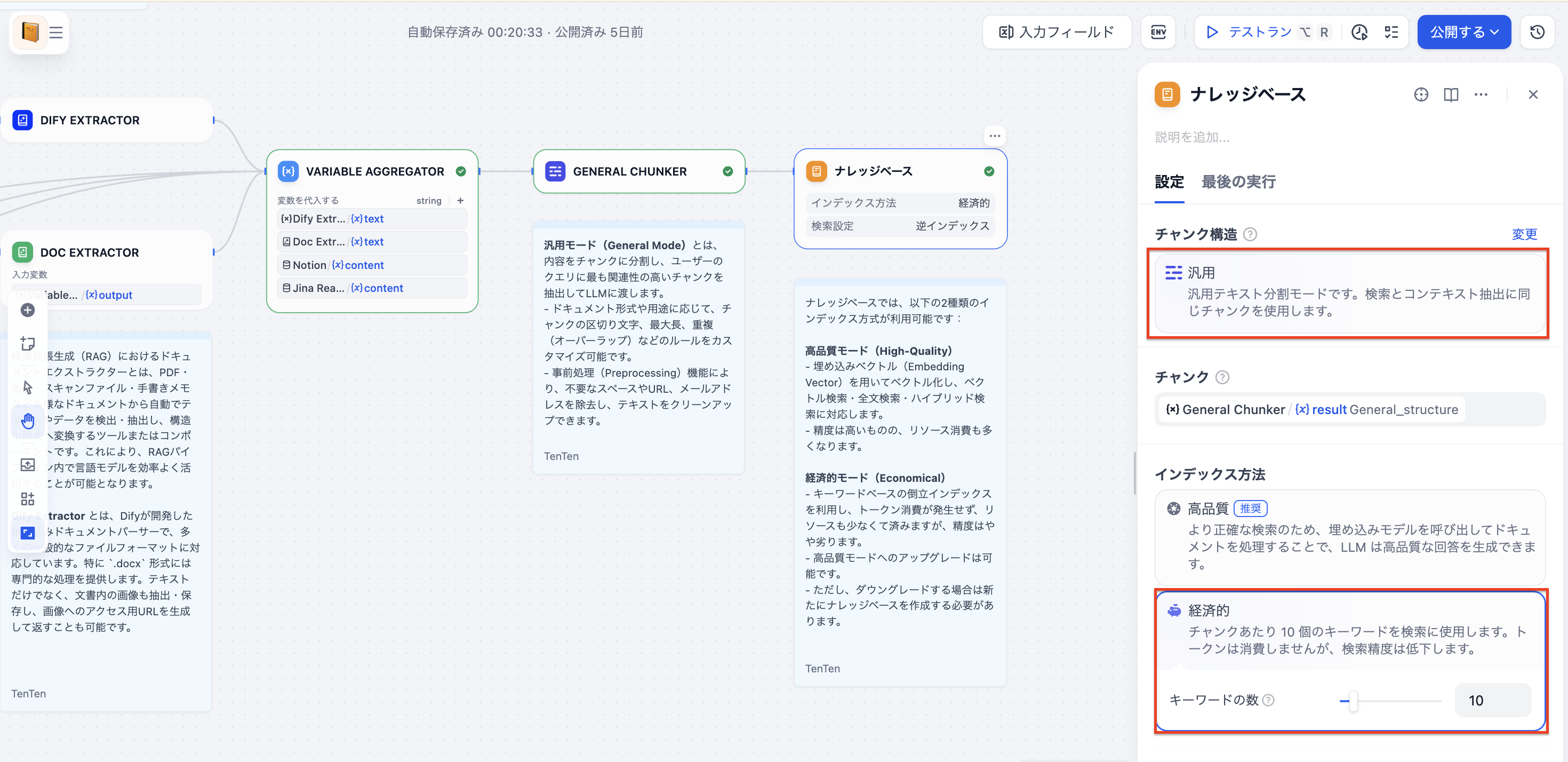
KNOWLEDGE BASEブロックでチャンク構造を「汎用」に設定し、インデックス方法を指定します。今回は「経済的」を指定します。
:::message
「汎用チャンク」とは 文書やテキストデータを、一定のルールに基づいて機械的に分割する基本的な手法。 一般的には「文字数」や「段落数」などの基準をもとに、文書を均等な長さのチャンクに区切ります。 この方式はシンプルかつ自動化しやすい一方で、文脈や意味のつながりが途切れやすいという課題があります。
:::
-
アプリを公開します。
実行手順 「一般文書処理」では、整理されていない膨大なデータを迅速に効率よくナレッジベースに処理することに適しています。 今回はWebクローリングを利用して、Elcamyの公式サイトをクローリングしナレッジベースに保存します。
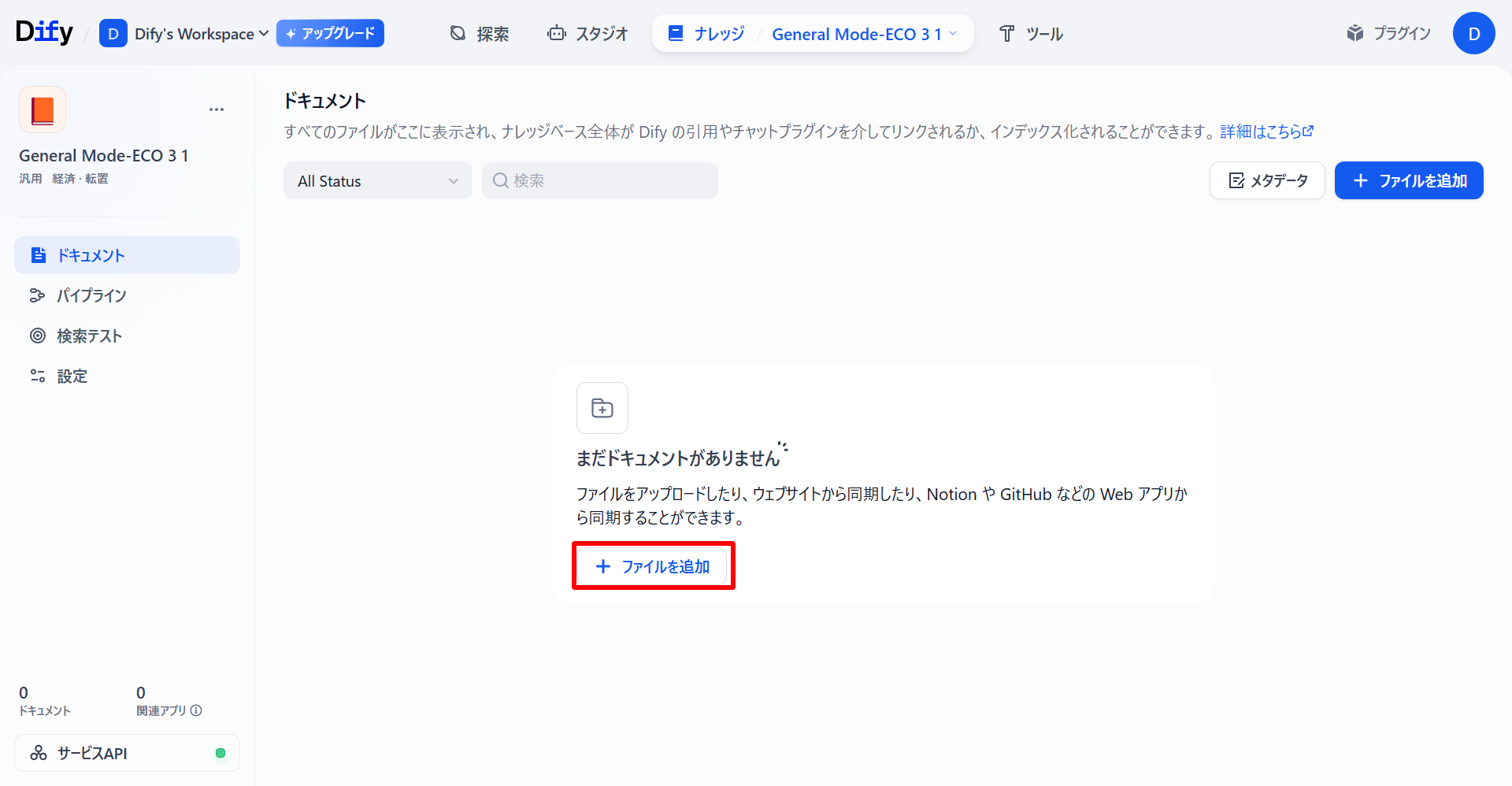
-
「ドキュメント」タブからファイルを追加します。
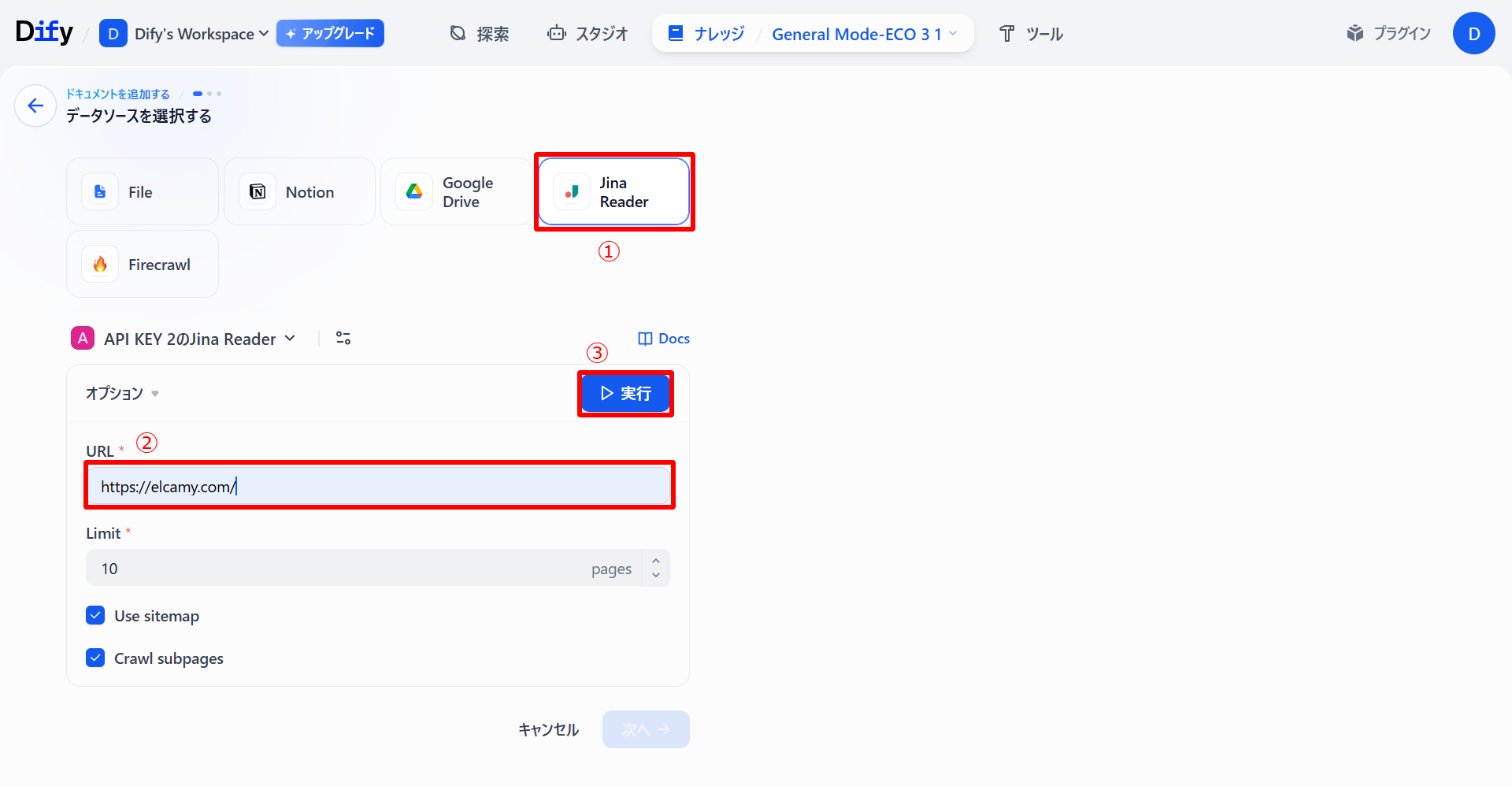
-
データソースから「Jina Reader」を選択し、クローリングしたいサイトのURLを画像のように貼り付けます(クローリングページ数の上限「Limits」は10に設定)。
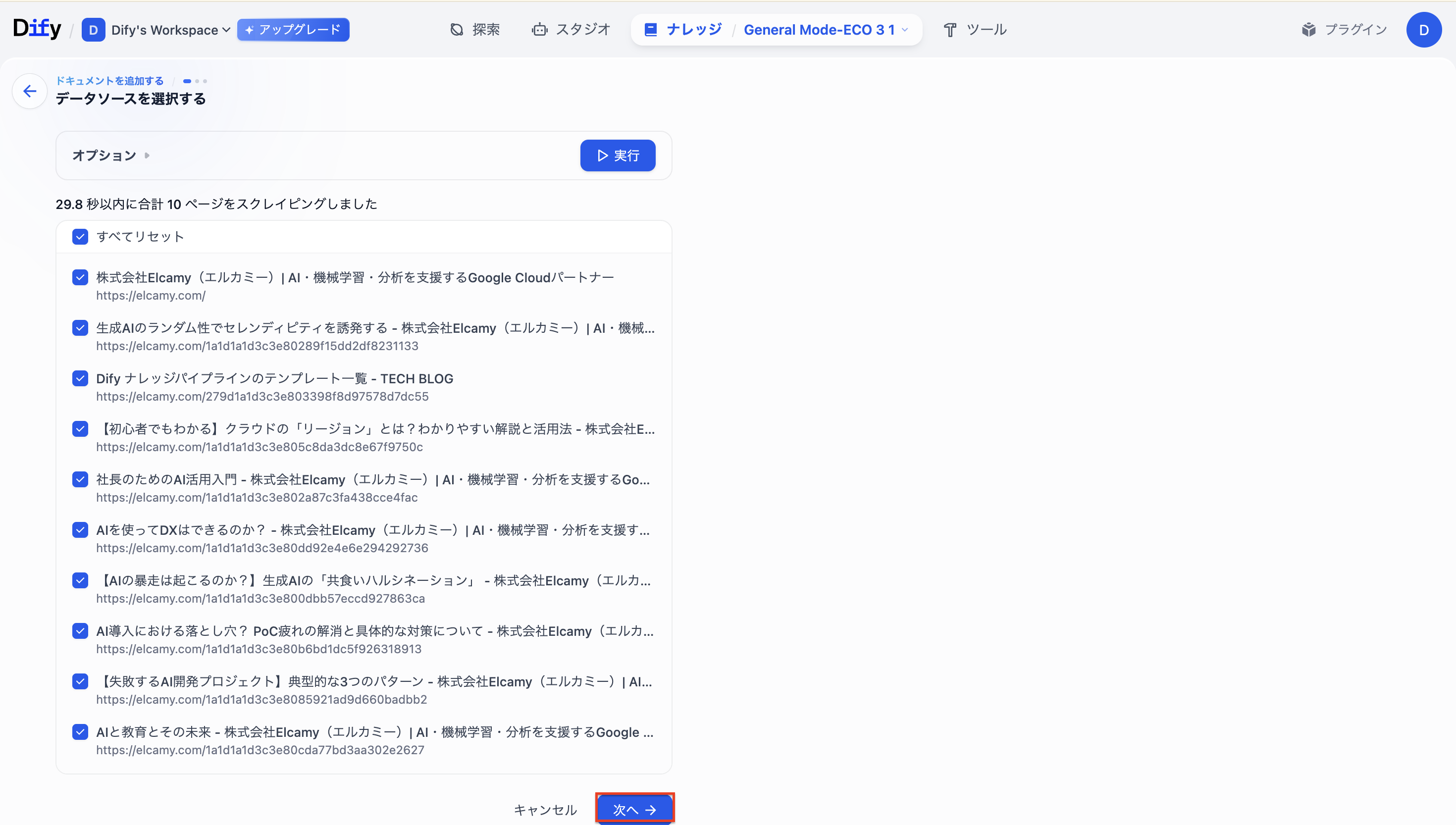
-
クローリングが完了したら「次へ」を選択します。
-
「プレビューチャンク」より、構造化されたチャンクを確認し、問題なければ「保存して処理」を選択します。
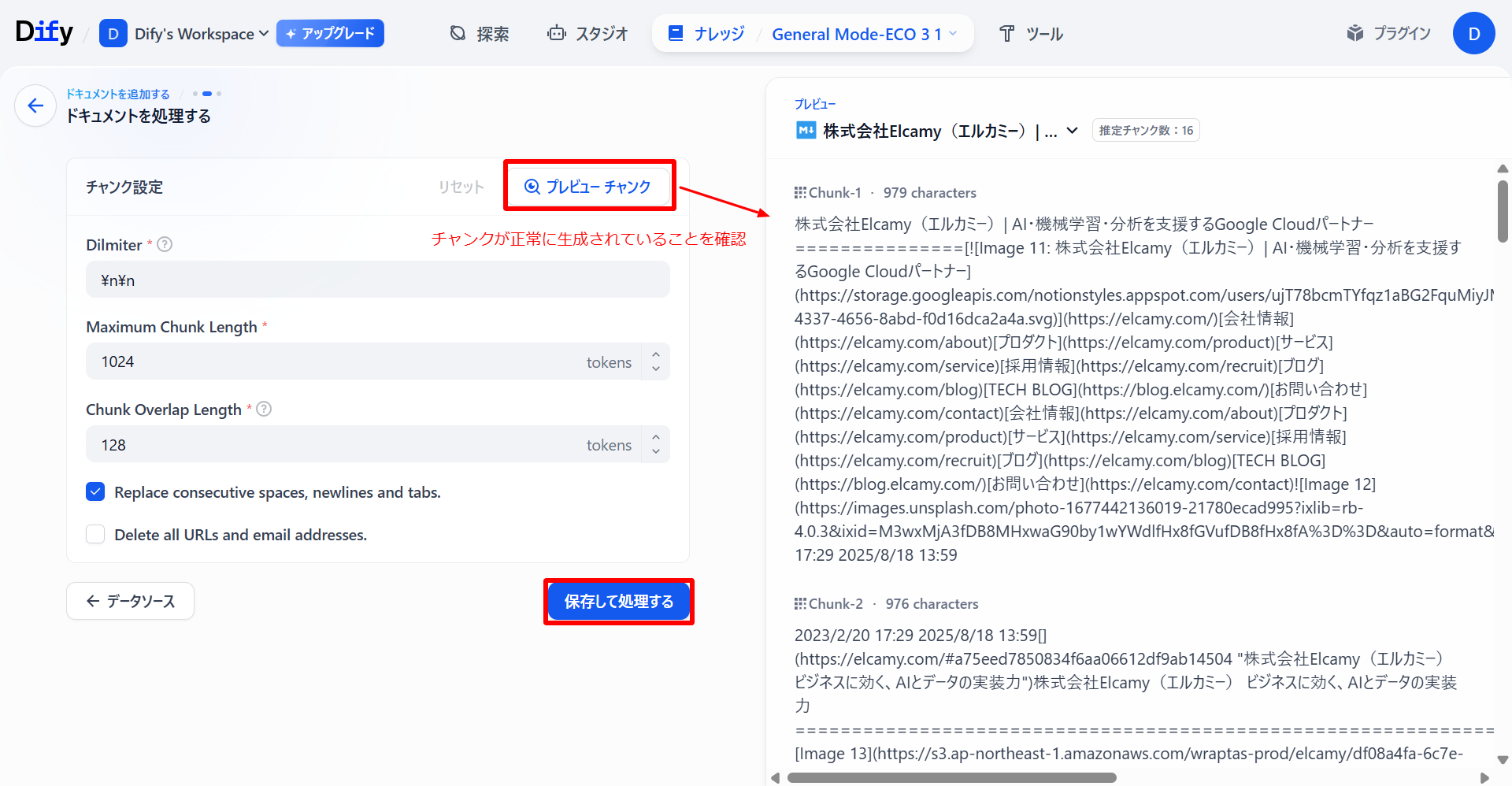 ページによってはいつまで経ってもステータスが「キューイング中」となり、処理が完了しない場合があります。3分ほど待っても処理が完了しない場合「チャンク設定」を選択し、「保存して処理」をもう一度選択します。
ページによってはいつまで経ってもステータスが「キューイング中」となり、処理が完了しない場合があります。3分ほど待っても処理が完了しない場合「チャンク設定」を選択し、「保存して処理」をもう一度選択します。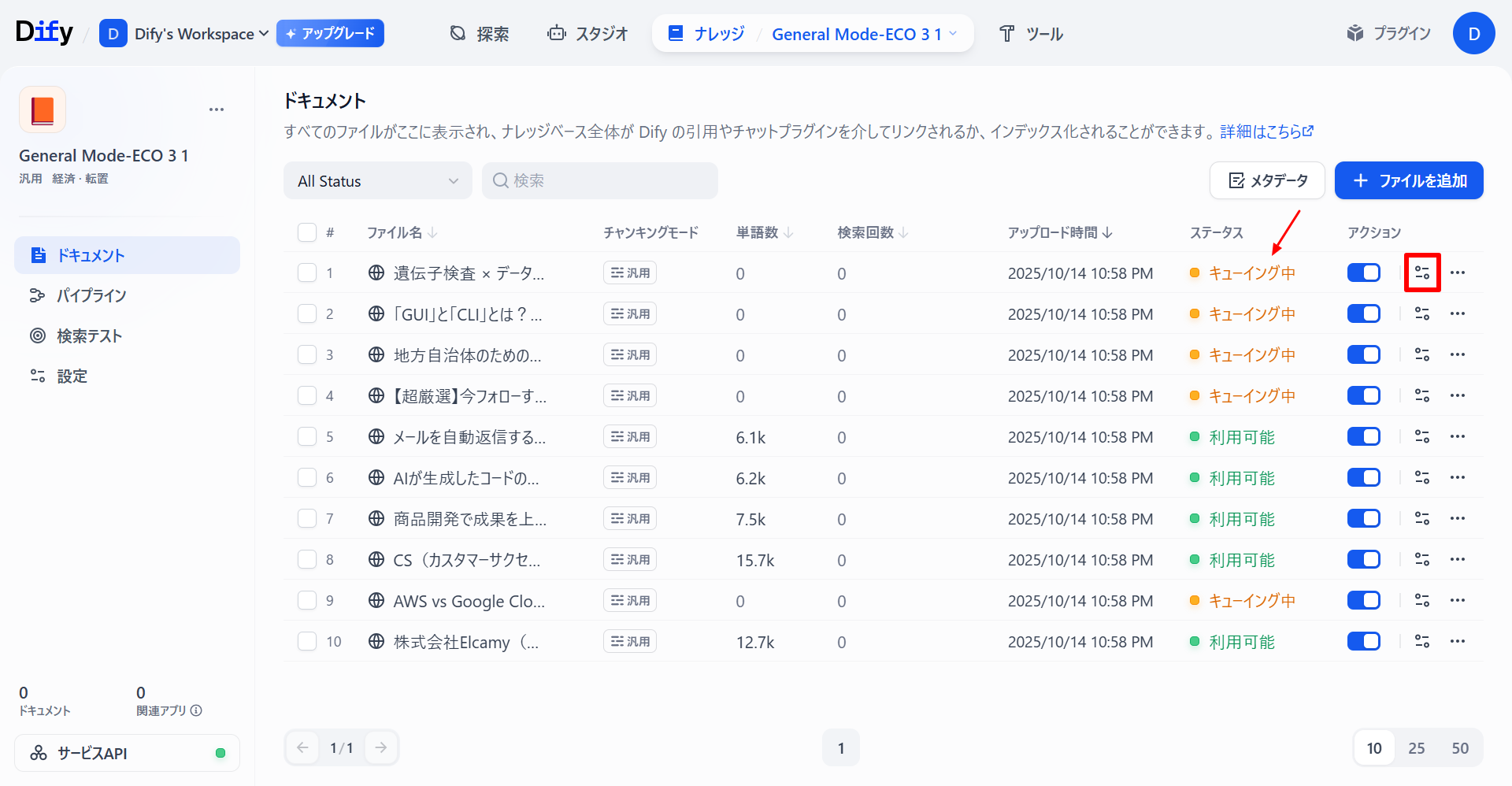
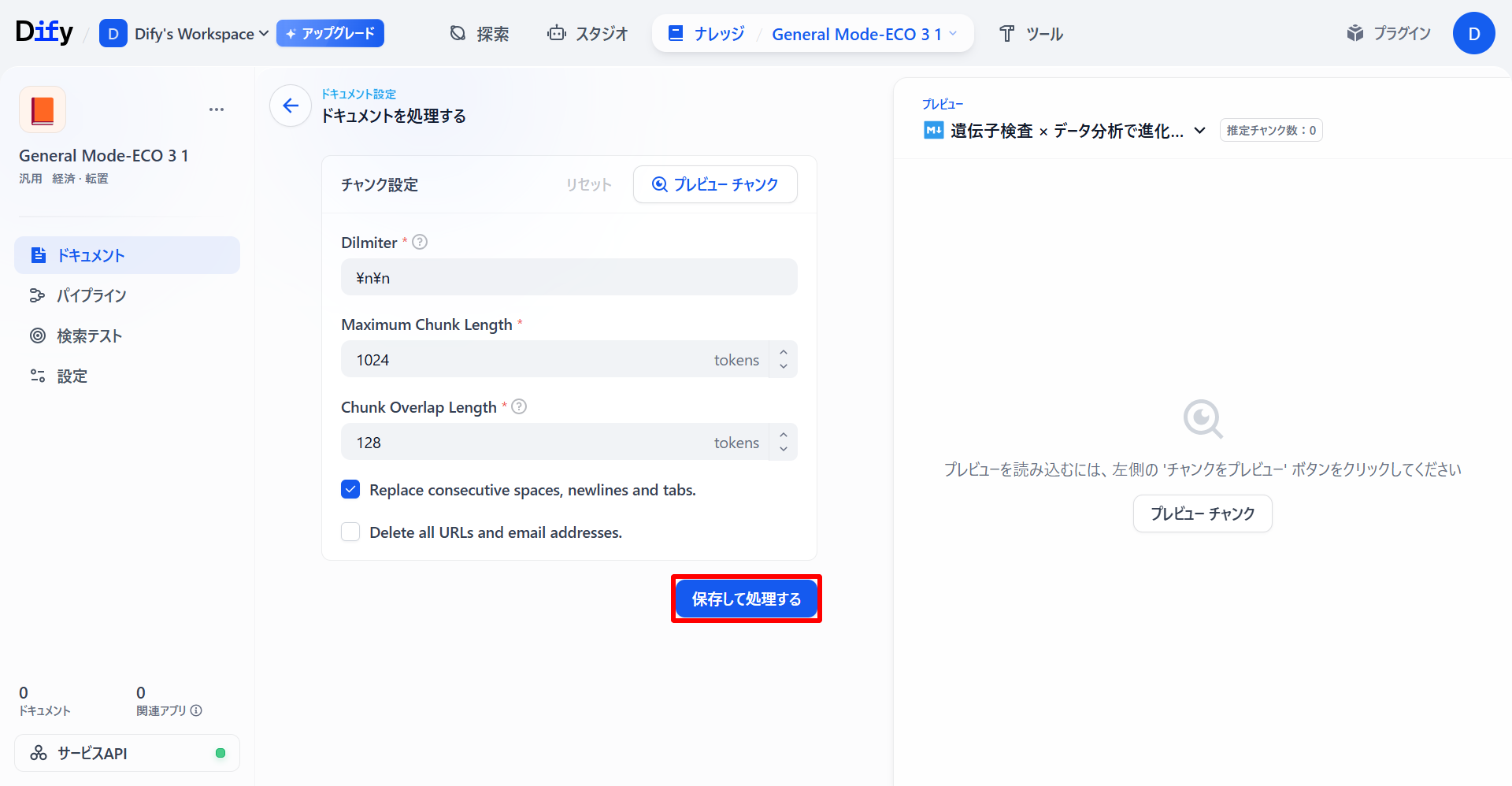 該当のナレッジのステータスが「利用可能」になっていれば処理は完了しています。すべての「キューイング中」であるナレッジベースについて同じ処理をします。
該当のナレッジのステータスが「利用可能」になっていれば処理は完了しています。すべての「キューイング中」であるナレッジベースについて同じ処理をします。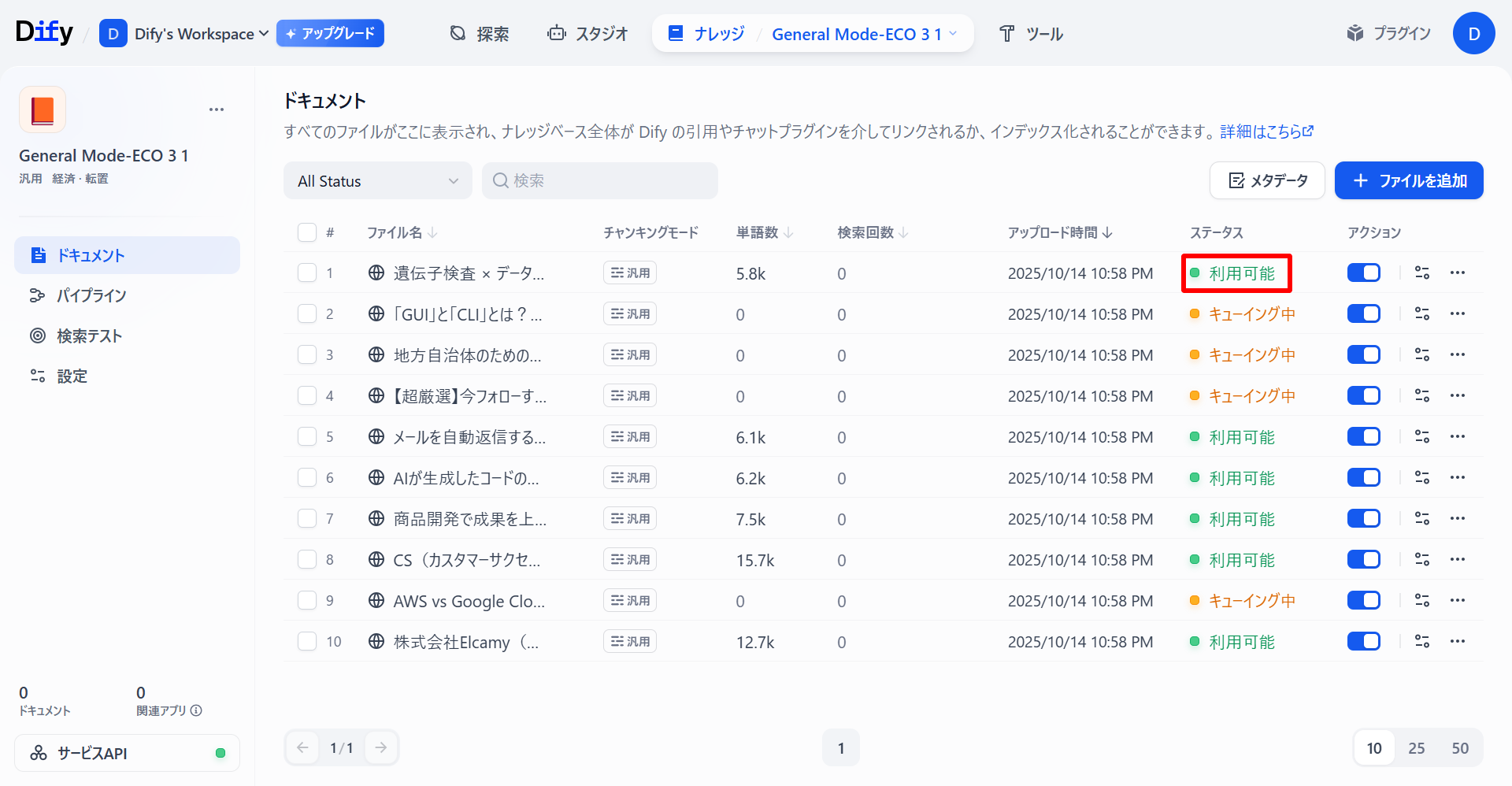
ナレッジベース(アウトプット)
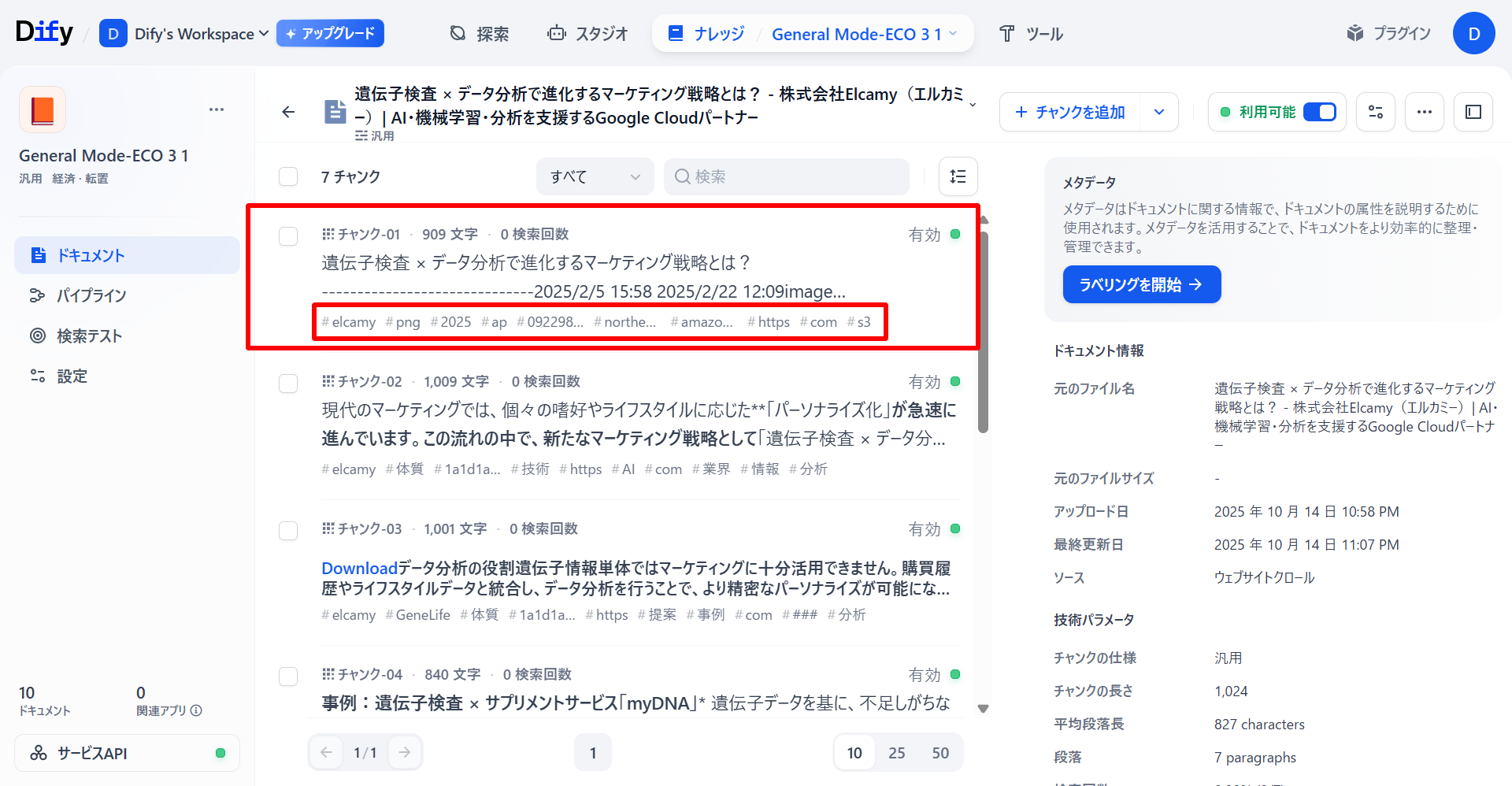
ナレッジの中を見てみると、「汎用チャンク」として正常に生成されていることが確認できました。具体的には、チャンクごとにキーワードがタグ付けされているため、検索クエリとチャンクのキーワードの類似度を評価することで、適切な検索を可能にしています。
2. 長文書処理
データソース(インプット)
- ファイルアップロード(PDF、XLSX、DOCXなど)
- クラウドストレージ(Google Drive)
- オンラインドキュメント(Notion)
- Webクローラ(Jina Reader、Firecrawl)
プロセス
プロセスの全体像
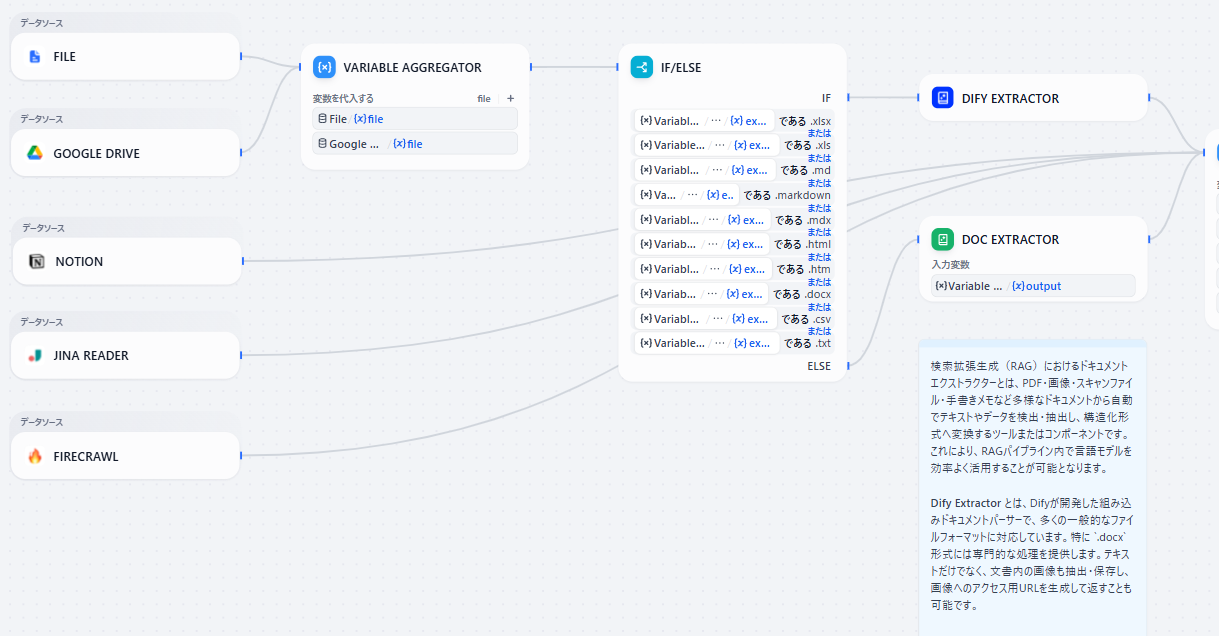
- データソース: パイプラインの起点としてデータソースを取り込みます。
- データソースが **FILE **または **GOOGLE DRIVE **の場合
- VARIABLE AGGREGATOR: 同一処理をするために変数代入
- **IF/ELSEブロック: **ファイルの拡張子によって分岐
- **Extractor(抽出器): **ドキュメントの解析・構造化
- DIFY EXTRACTOR: Excel(
.xlsx,.xls)、マークダウン(.md,.markdown,.mdx)、HTML(.html,.htm)、Word(.docx)、テキスト(.csv,.txt)に対応 - DOC EXTRACTOR: 上記以外のファイル形式に対応
- DIFY EXTRACTOR: Excel(
- **VARIABLE AGGREGATOR: **すべてのデータソースにその後同一処理をするために変数代入
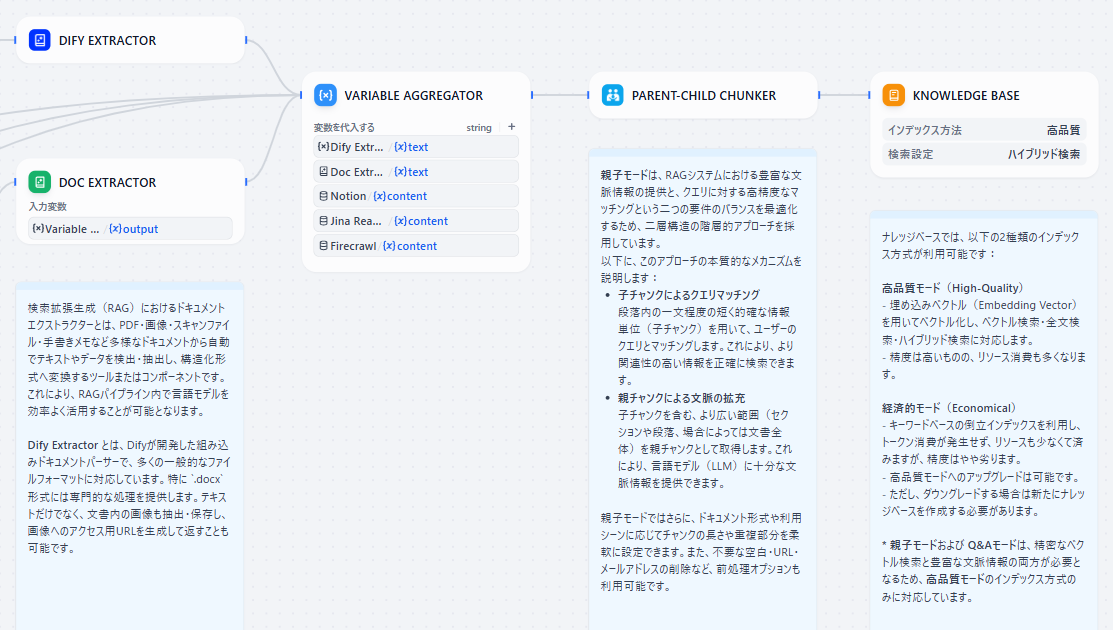
- PARENT-CHILD CHUNKER: 構造化されたデータを「親子チャンク」としてチャンクを形成します。
- KNOWLEDGE BASE: パイプラインで処理・変換されたデータをナレッジベースに保存します。
「親子チャンク」とは チャンクを「親チャンク」と「子チャンク」に分け、親子構造にすることによってAIがより文脈に即した精度の高い検索ができるようになったチャンク構造 子チャンク:ドキュメントの情報を、焦点を絞り小さく分割したもの。情報を小さく分割することで、ユーザーのクエリにマッチングする際の精度が高まり、正確で関連性の高い初期取得が可能になります。 親チャンク:子チャンクを含む、段落やセクション、またはドキュメント全体などの、より大きく包括的な情報。LLMにコンテキストを提供することで、重要な詳細の見落としを防ぎます。
準備
-
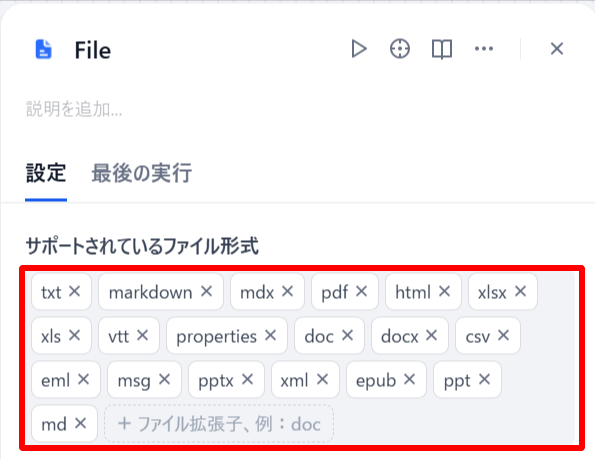
FILEブロックでアップロードするファイル形式を指定します。赤枠内のファイル形式が使用可能です。
-
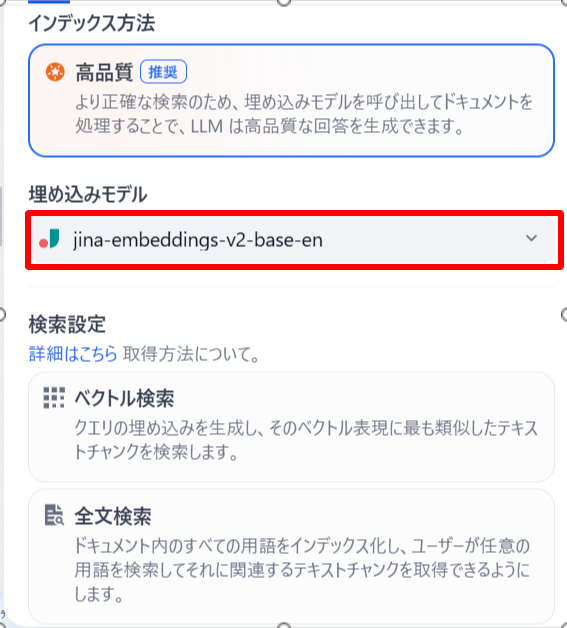
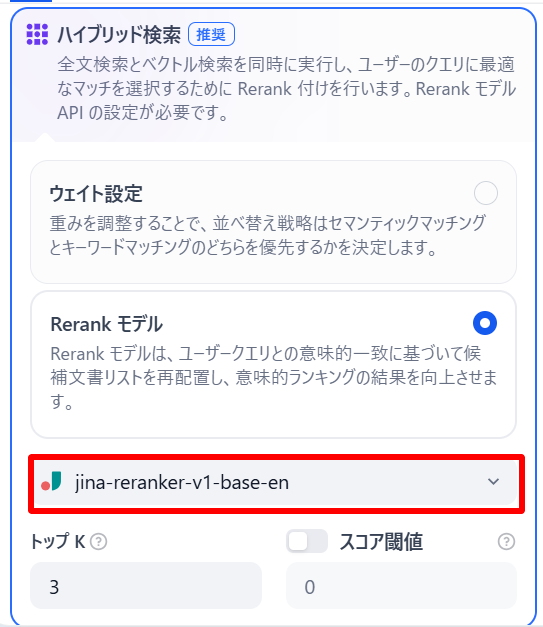
KNOWLEDGE BASEブロックに埋め込みモデルとRerankモデルを設定します。
-
アプリを公開します。
実行手順 親子チャンクの効果を発揮するため、今回はこちらの論文をデータソースに使用します。
-
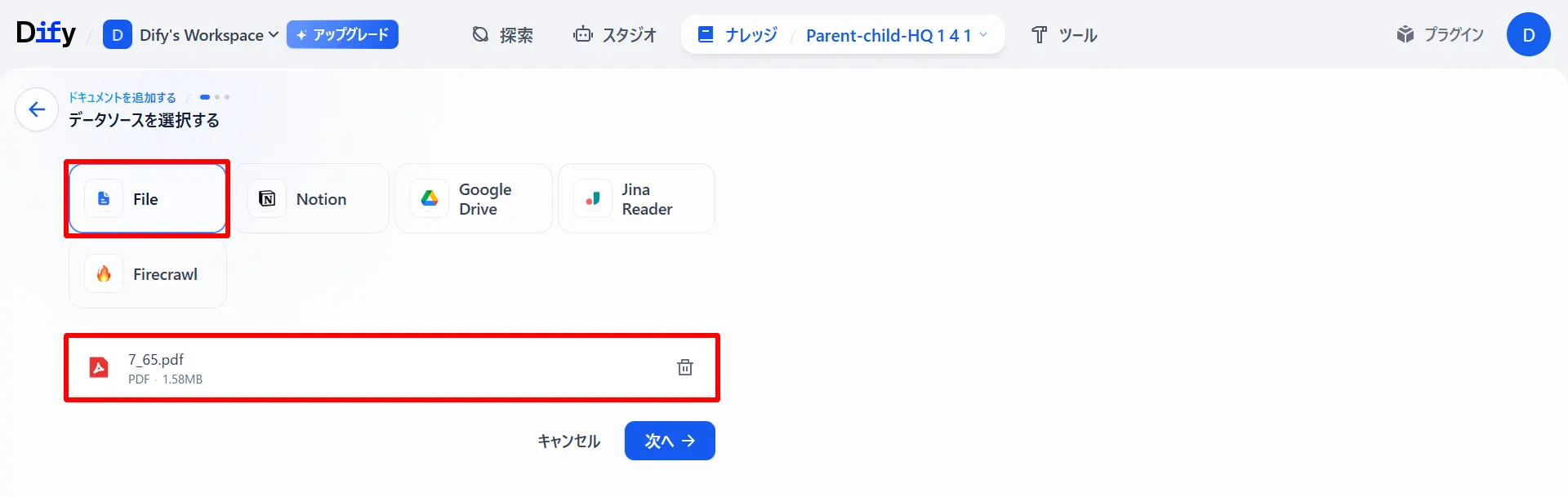
「ドキュメント」タブから「ファイルを追加」を選択し、データソースを入力します。
-
「プレビューチャンク」を確認し、問題なければ「保存して処理」を選択します。
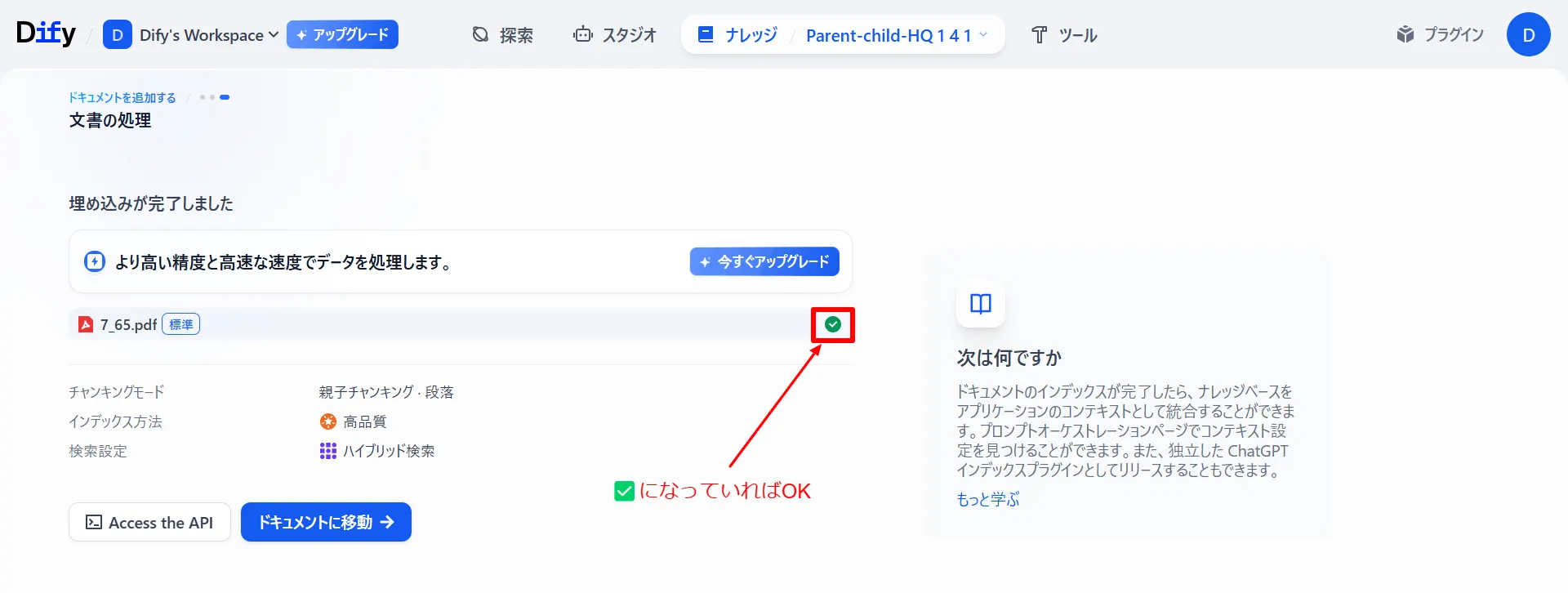
ナレッジベース(アウトプット)
処理が正常に完了したナレッジベースを見てみると「親子チャンク」が正常に生成されていることがわかります。
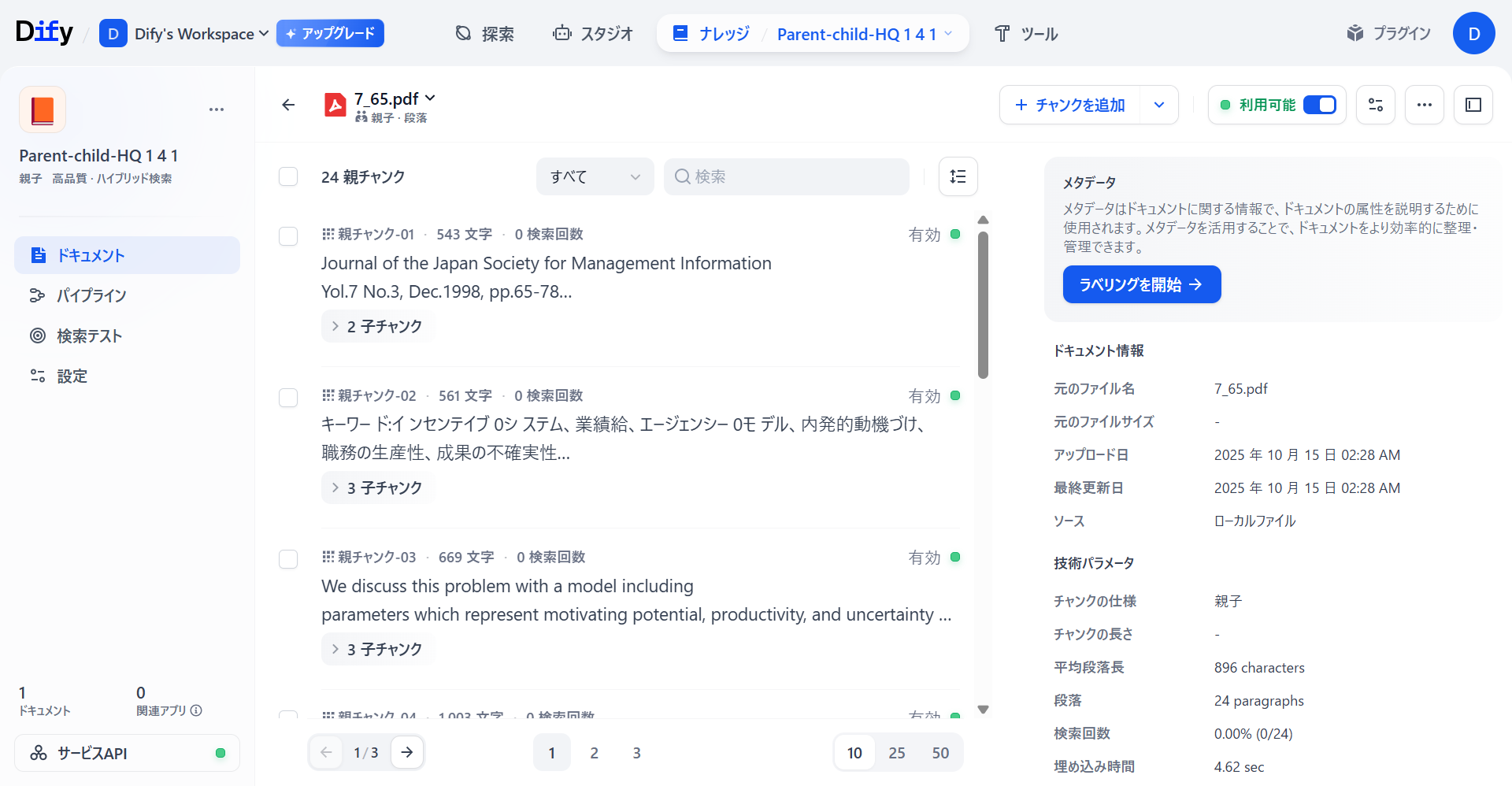 ただし、PDFをデータソースとしてナレッジベースを作成しようとすると、日本語が変になってしまったり、フォントによってはチャンクが生成されないことが確認できています。実行履歴を確認すると、(Doc Extractoが日本語を上手く処理できていないことが分かります。
ただし、PDFをデータソースとしてナレッジベースを作成しようとすると、日本語が変になってしまったり、フォントによってはチャンクが生成されないことが確認できています。実行履歴を確認すると、(Doc Extractoが日本語を上手く処理できていないことが分かります。
日本語PDFの解析精度にお困りの方へ Dify標準のパーサーでは日本語のレイアウト崩れや表の読み飛ばしが発生しやすくなります。「PDFデータを正確に読み込ませたい」という場合は、外部のOCR連携などを組み込んだ専用の処理フローを構築可能です。解決策をお探しの方はお気軽にご相談ください。
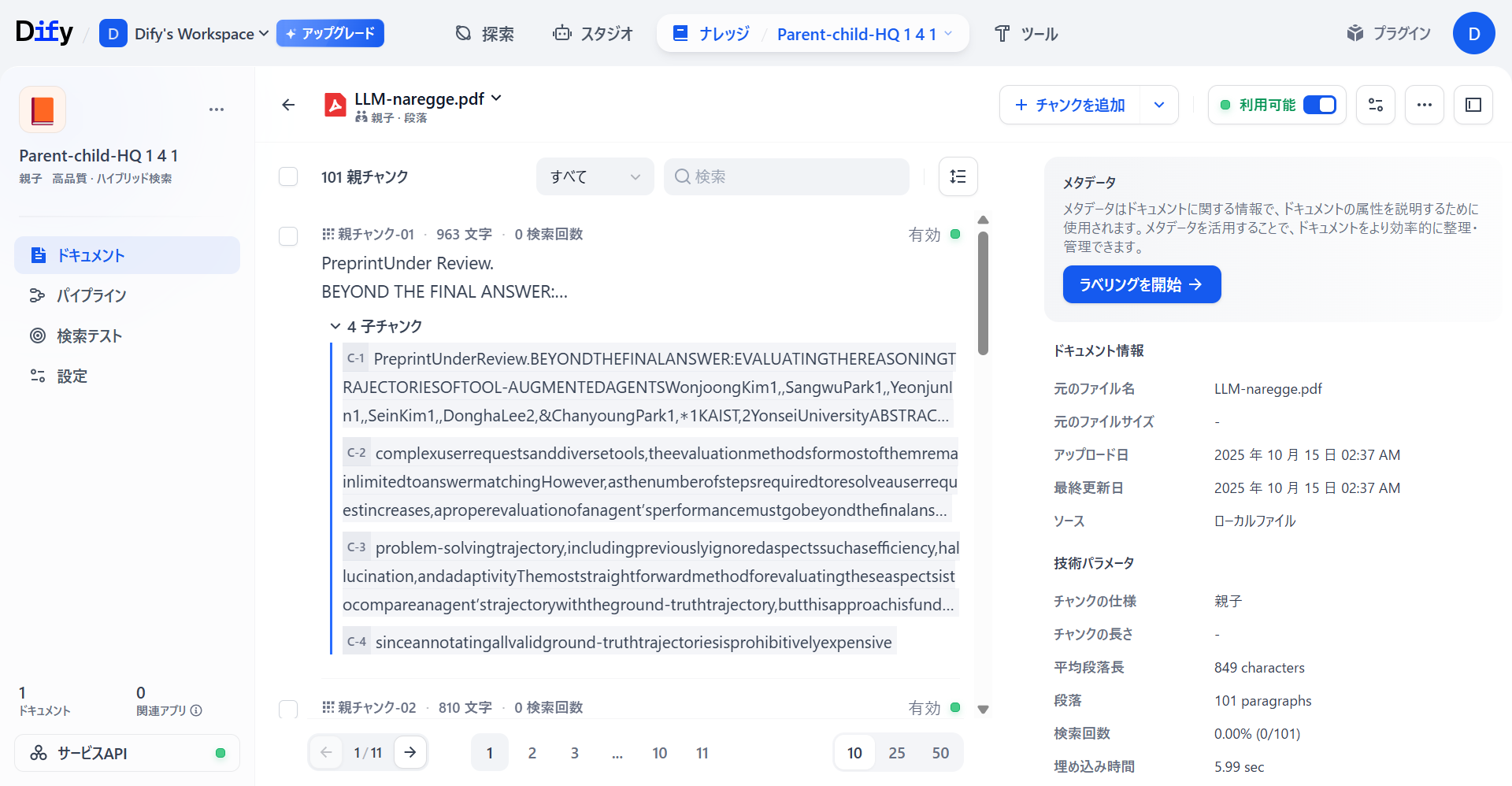
また、同じPDF形式でも英語で記述された論文に関しては正常にナレッジベースが作成されていることが確認できました。
3. 文書形式変換
データソース(インプット)
Excel(.xlsx 、.xls)、Word(.docx, .doc)、PowerPoint(.pptx, .ppt)などOffice形式のファイル形式に適しています。
以下のファイル形式が使用可能です。
プロセス
プロセスの全体像

- FILE: データソースとしてファイルをアップロード
- MARKITDOWN: データソースをナレッジとして取り込むためにテキストやデータをMarkdown形式に変換します。
- PARENT-CHILD CHUNKER: 構造化されたデータを「親子チャンク」としてチャンクを形成します。
- KNOWLEDGE BASE: パイプラインで処理・変換されたデータをナレッジベースに保存します。
準備
-
「FILE」ブロックでデータソースとして使用できるファイル形式を確認します。(現時点では以下のファイル形式が使用可能です。)
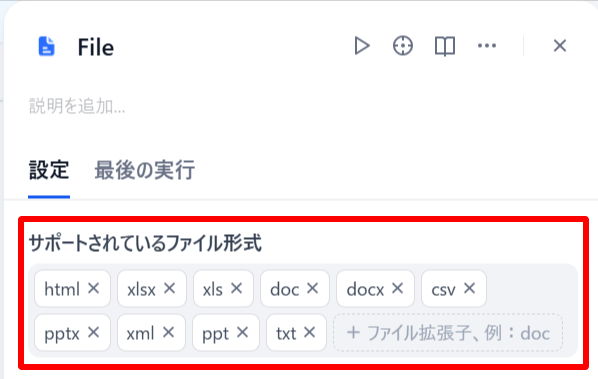
-
「KNOWLEDGE BASE」ブロックにチャンク構造が「親子」になっていることを確認し、埋め込みモデルを設定します。
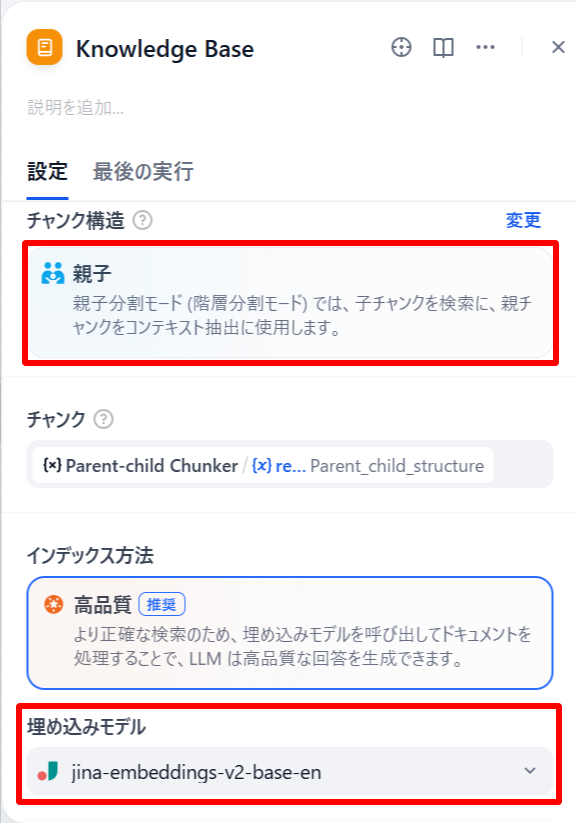
-
アプリを公開します
実行手順 このテンプレートはOffice形式のデータソースに特化しているため、PowerPoint資料(
.pptx)をデータソースに使用します。今回は内閣官房が公開している地方創生に関する資料を使用します。 -
「ドキュメント」タブから「ファイルを追加」を選択します。
-
「FILE」からデータソースを入力し、「次へ」を選択します。
-
「プレビュー」からチャンクの構造を確認し、問題がなければ「保存して処理」を選択します。
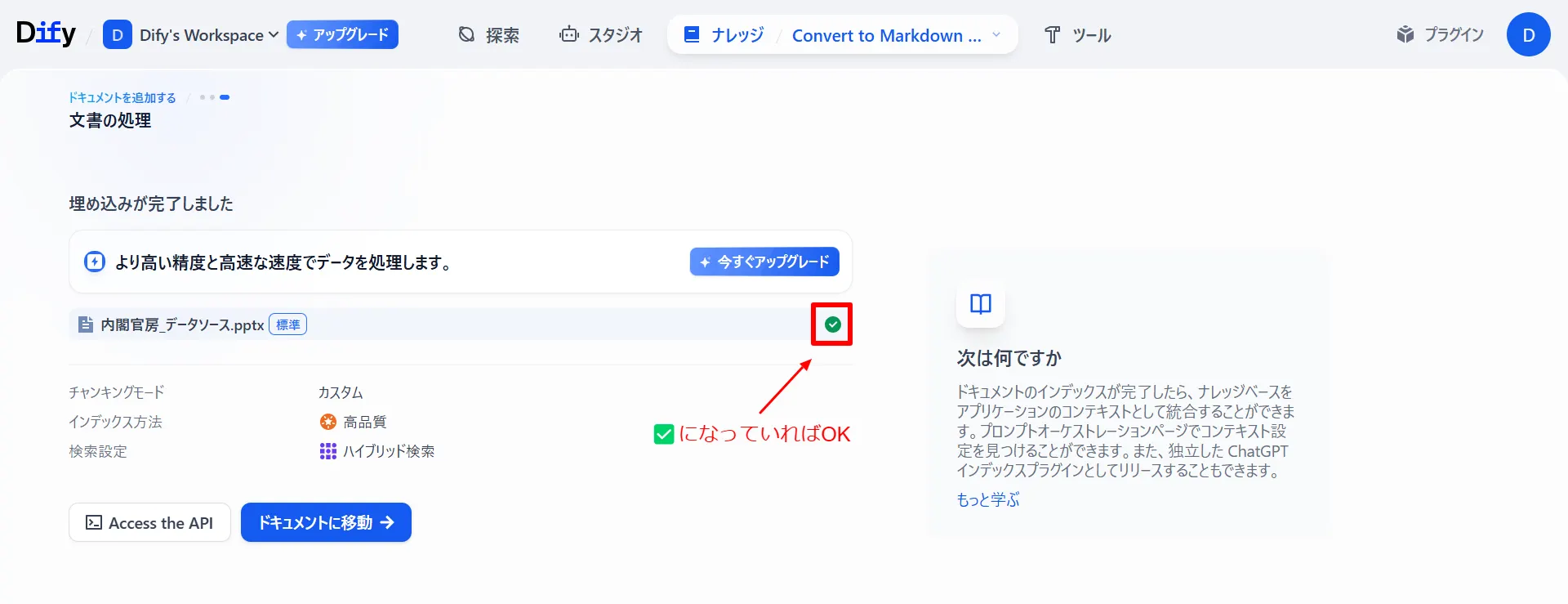
ナレッジベース(アウトプット)
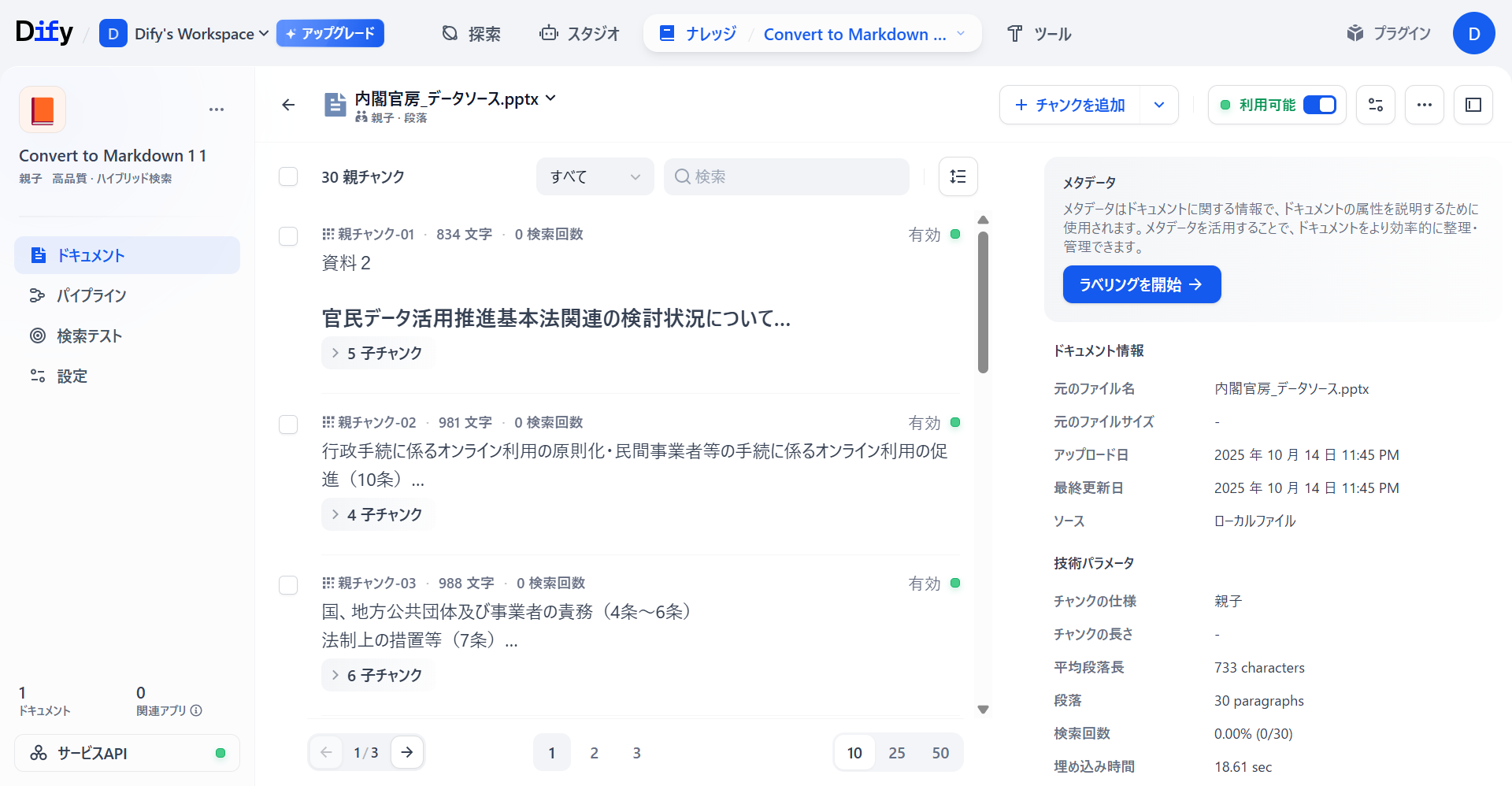
以下のようにOffice形式のデータソースから「親子チャンク」が生成されていることが確認できます。
 「長文書処理」を使用することによっても「親子チャンク」を生成することができるのですが、Office形式のデータソースでは、生成のされ方が少し変わってきます。同じデータソースで生成されたナレッジベースを以下の画像で比較してみます(上: 「長文書処理」下: 「文書形式変換」)。
「長文書処理」を使用することによっても「親子チャンク」を生成することができるのですが、Office形式のデータソースでは、生成のされ方が少し変わってきます。同じデータソースで生成されたナレッジベースを以下の画像で比較してみます(上: 「長文書処理」下: 「文書形式変換」)。
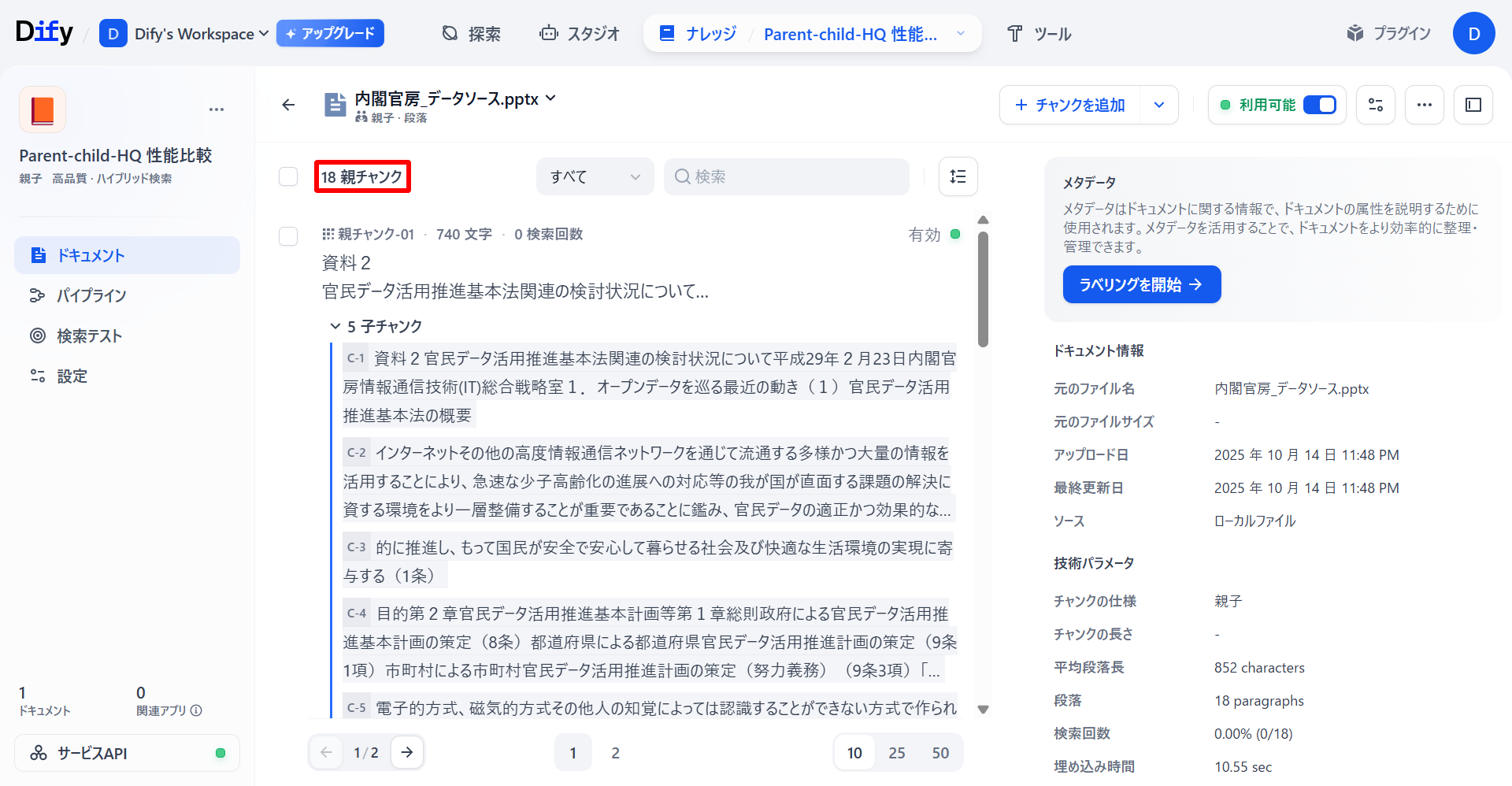 「長文書処理」によるナレッジベース
「長文書処理」によるナレッジベース
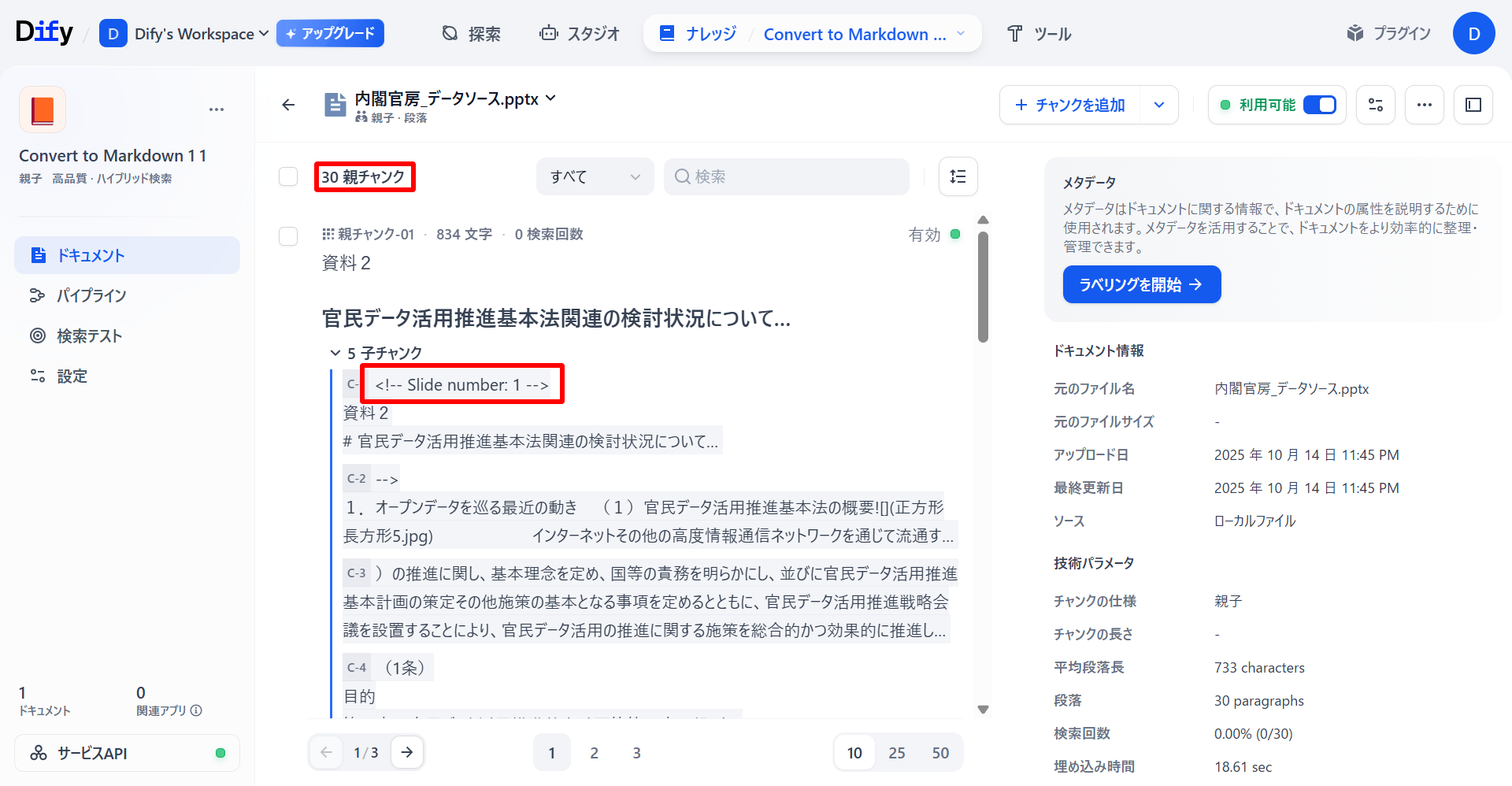 「文書形式変換」によるナレッジベース
親チャンクについてはさほど違いは見られません。しかし、「子チャンク」について「長文書処理」では、親チャンクに関連する文章を紐づけているだけなのに対し「文書形式変換」では、文章での類似度だけではなくデータソースのスライド番号による関連性など、スライド全体の流れから子チャンクを生成していることがわかります。また、親チャンク数が「文書形式変換」のほうが多く生成されていることがわかります。
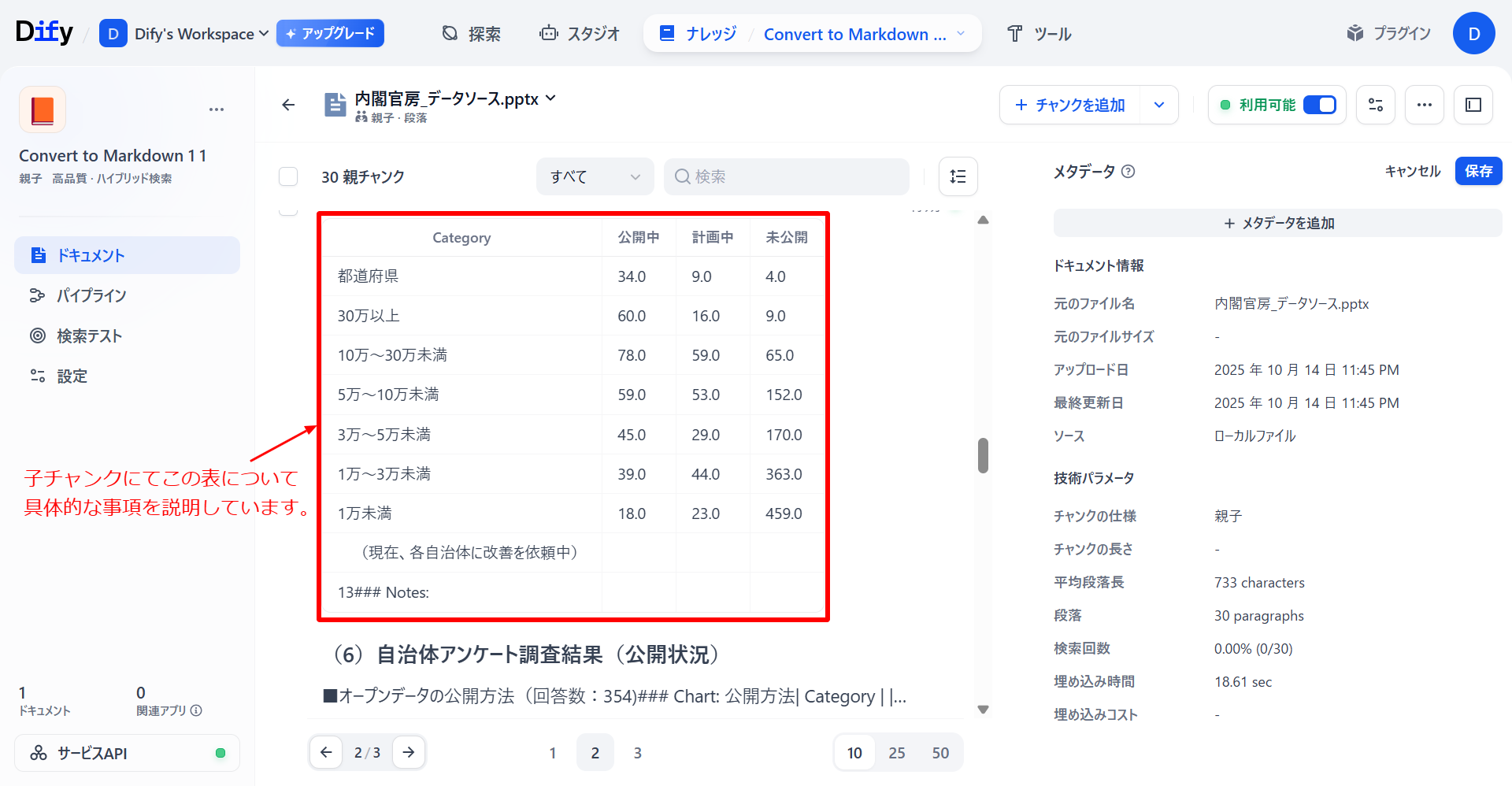
「文書形式変換」によるナレッジベースでは文章だけではなく、表や図形などの情報もナレッジベースとして親子チャンクが生成されています。
「文書形式変換」によるナレッジベース
親チャンクについてはさほど違いは見られません。しかし、「子チャンク」について「長文書処理」では、親チャンクに関連する文章を紐づけているだけなのに対し「文書形式変換」では、文章での類似度だけではなくデータソースのスライド番号による関連性など、スライド全体の流れから子チャンクを生成していることがわかります。また、親チャンク数が「文書形式変換」のほうが多く生成されていることがわかります。
「文書形式変換」によるナレッジベースでは文章だけではなく、表や図形などの情報もナレッジベースとして親子チャンクが生成されています。
 この違いが生まれる理由として、「文書形式変換」のワークフローの中にあるMicrossoftのプラグインである「Markitdown」にあります。
通常のナレッジパイプラインでは、データソースを処理する段階でデータソースをテキスト情報にしてからナレッジベースを作成するため、テキスト情報の類似度や構造から親子チャンクを作成します。
一方で、「Markitdown」では、Office形式の文書を一度 **HTML **に変換し、不要な情報を削除し整理たうえで、Markdown形式に変換します。スライドの情報を極力欠落せずデータソース全体の構造や類似度を評価できるため、より具体的で精度の高いナレッジベースを作成することができます。
この違いが生まれる理由として、「文書形式変換」のワークフローの中にあるMicrossoftのプラグインである「Markitdown」にあります。
通常のナレッジパイプラインでは、データソースを処理する段階でデータソースをテキスト情報にしてからナレッジベースを作成するため、テキスト情報の類似度や構造から親子チャンクを作成します。
一方で、「Markitdown」では、Office形式の文書を一度 **HTML **に変換し、不要な情報を削除し整理たうえで、Markdown形式に変換します。スライドの情報を極力欠落せずデータソース全体の構造や類似度を評価できるため、より具体的で精度の高いナレッジベースを作成することができます。
4. インテリジェントQ&A生成
データソース(インプット)
- Fileアップロード(PDF、XLSX、DOCXなど)
- クラウドストレージ(Google Drive)
- オンラインドキュメント(Notion)
- Webクローラ(Jina Reader、Firecrawl)
プロセス
プロセスの全体像
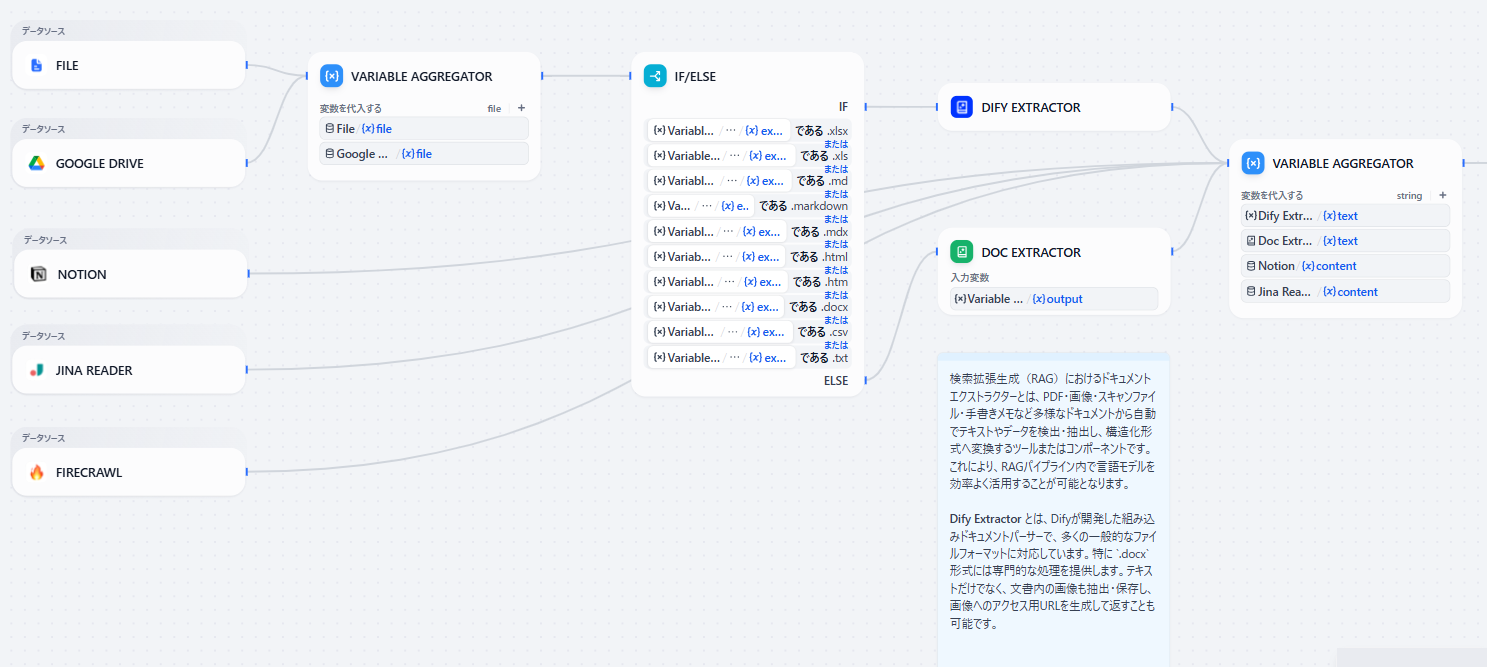
- データソース: パイプラインの起点としてデータソースを取り込みます。
- データソースが **FILE **または **GOOGLE DRIVE **の場合
- VARIABLE AGGREGATOR: 同一処理をするために変数代入
- **IF/ELSEブロック: **ファイルの拡張子によって分岐
- **Extractor(抽出器): **ドキュメントの解析・構造化
- DIFY EXTRACTOR: Excel(
.xlsx,.xls)、マークダウン(.md,.markdown,.mdx)、HTML(.html,.htm)、Word(.docx)、テキスト(.csv,.txt)に対応 - DOC EXTRACTOR: 上記以外のファイル形式に対応
- DIFY EXTRACTOR: Excel(
- **VARIABLE AGGREGATOR: **すべてのデータソースにその後同一処理をするために変数代入
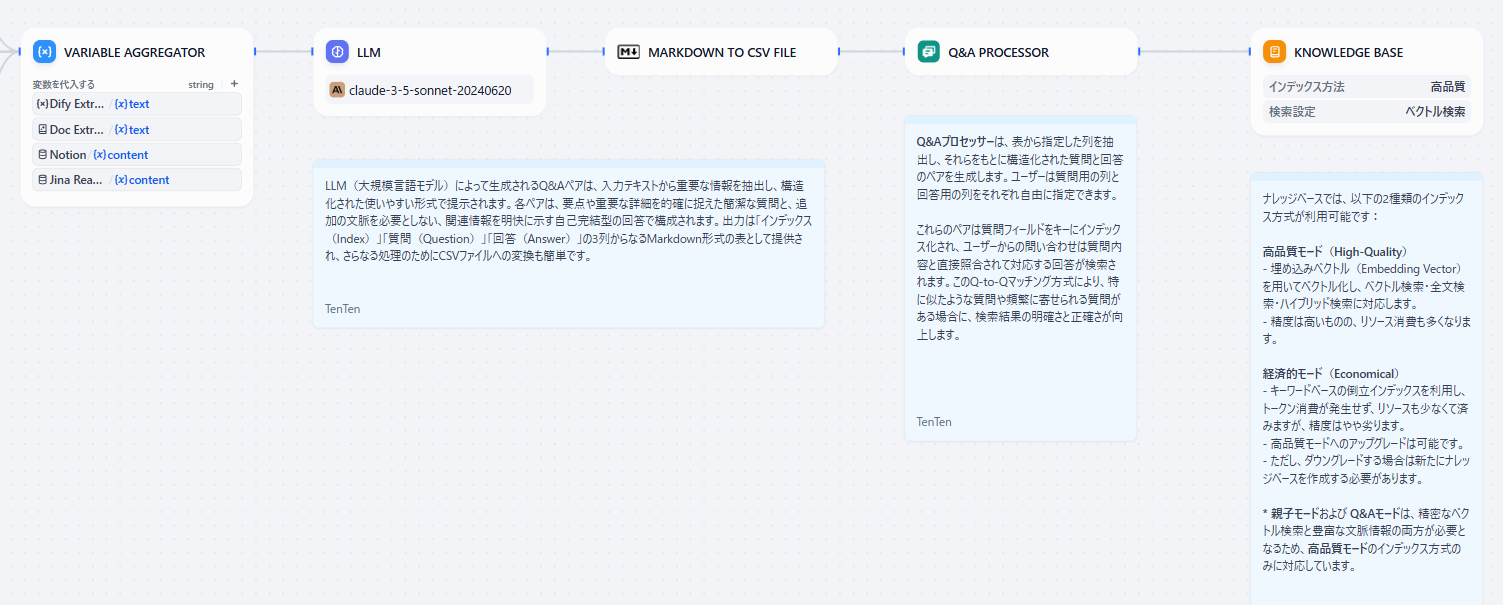
- LLM: 与えられたデータをQ&Aペアに変換し、Markdown形式の表として出力
- MARKDOWN TO CSV FILE: Markdown形式の表からCSVファイルへ変換
- **Q&Aプロセッサ: **Q&A形式のデータ(質問と回答のペア)をナレッジに取り込む専用の変換器
- **KNOWLEDGE BASE: **パイプラインで処理・変換されたデータを最終的にナレッジベースに保存
準備
-
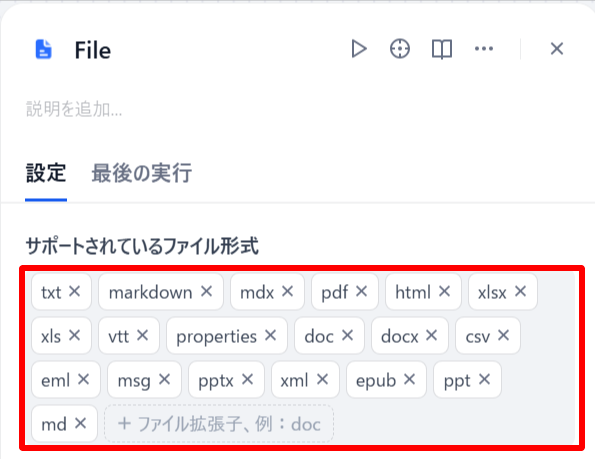
FILEブロックでアップロードするファイル形式を指定します(以下のファイル形式が使用可能です)。
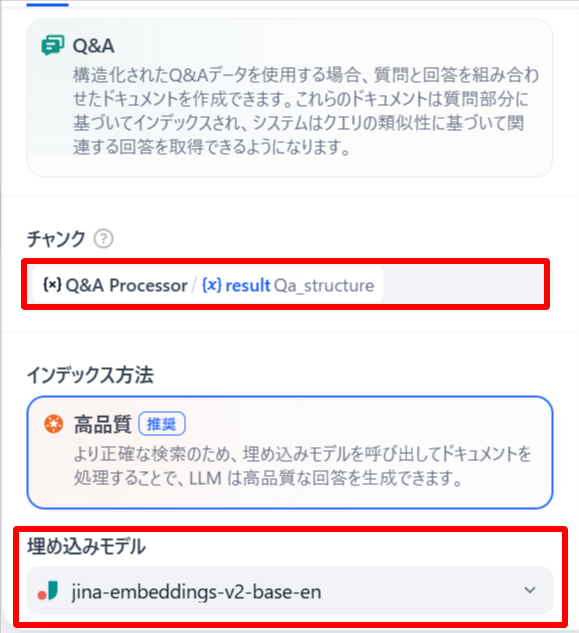
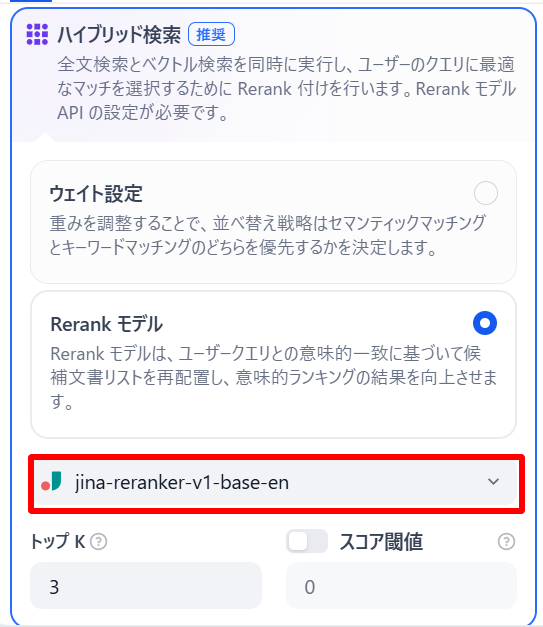
-
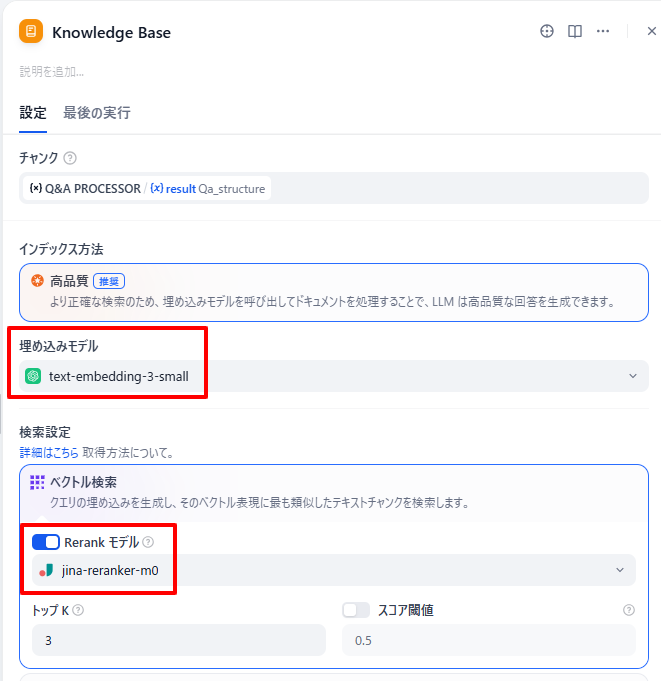
KNOWLEDGE BASEブロックに埋め込みモデルとRerankモデルを設定します。
-
アプリを公開します。
実行手順 今回はこちら就業規則のテンプレートを使用します。
-
「ドキュメント」タブから「ファイルを追加」を選択し、「FILE」からデータソースを入力します。
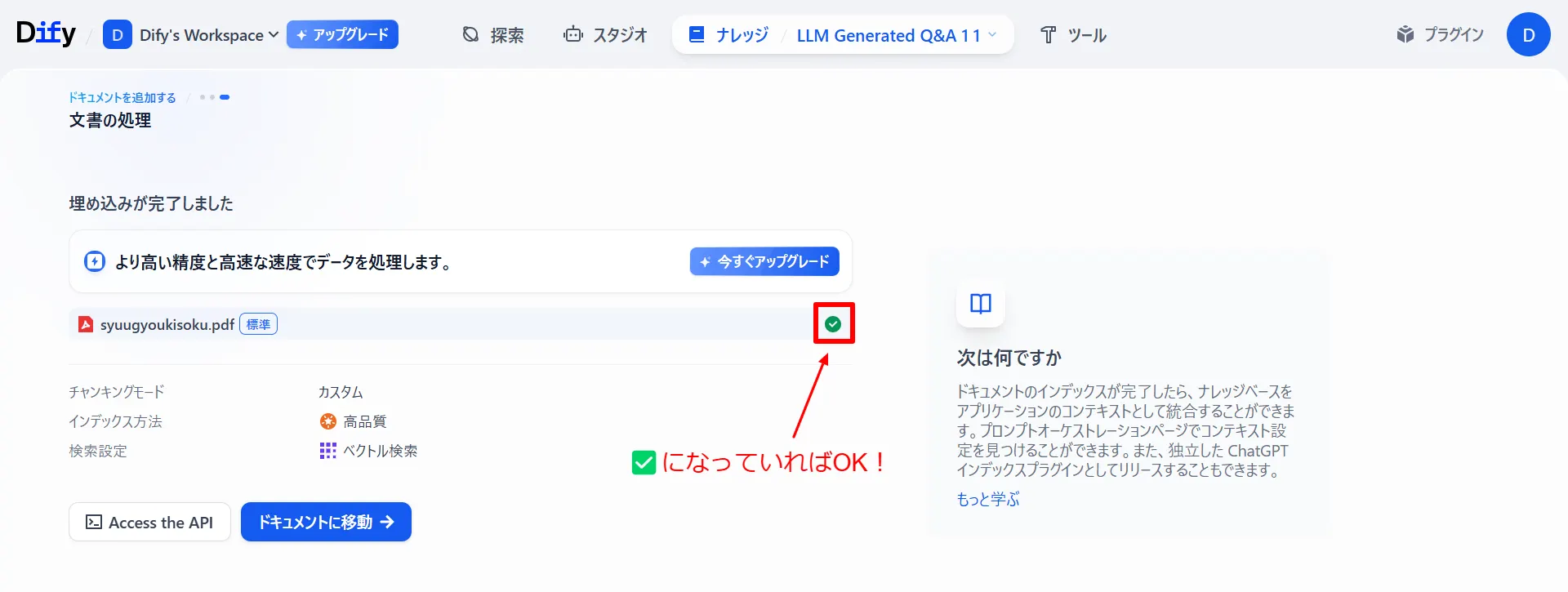
-
「保存して処理」を選択し、ナレッジベースを作成します。下記のようになっていれば成功です。
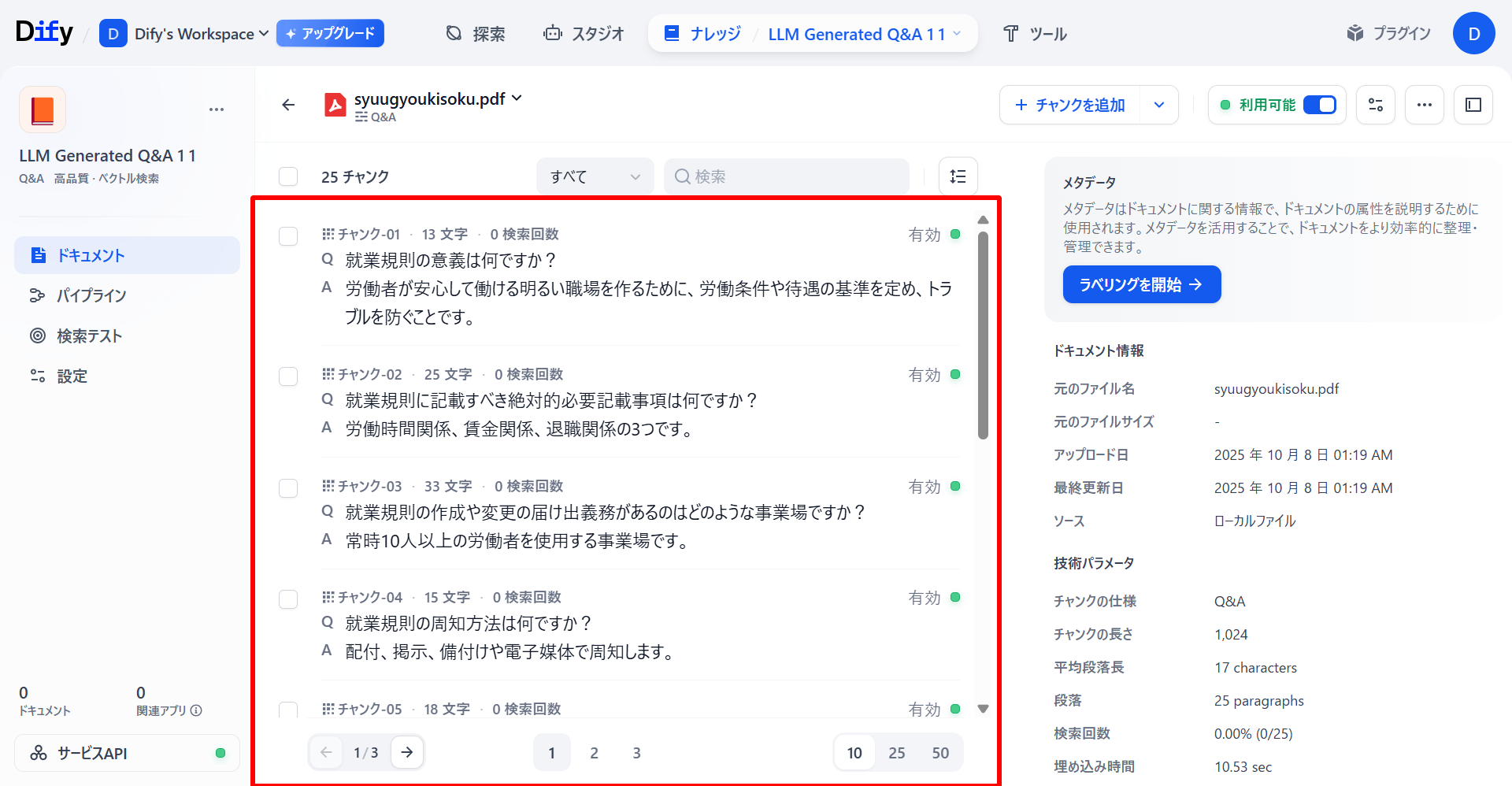
ナレッジベース(アウトプット)
以下のように、LLMがデータソースをもとにQ&Aペアを作成し、質問と回答をペアとしてナレッジに格納されています。
5. Q&A表データ抽出
データソース(インプット)
Excel(.xlsx 、.xls)およびCSVファイル(.csv)のみ利用可能
プロセス
プロセスの全体像
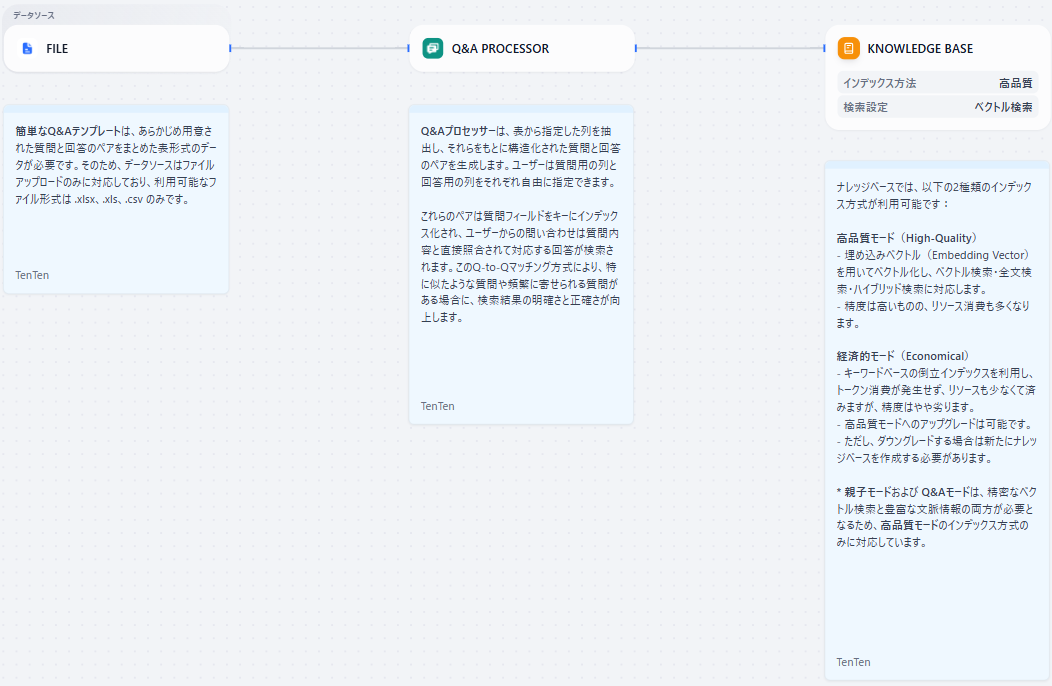
- FILE: データソースとしてファイルをアップロード
- Q&A PROCESSOR: Q&A形式のデータ(質問と回答のペア)をナレッジに取り込む専用の変換器
- KNOWLEDGE BASE: パイプラインで処理・変換されたデータをナレッジベースに保存
準備
-
FILEブロックでアップロードするファイル形式(拡張子)に
.csv,.xlsx,.xlsを指定します。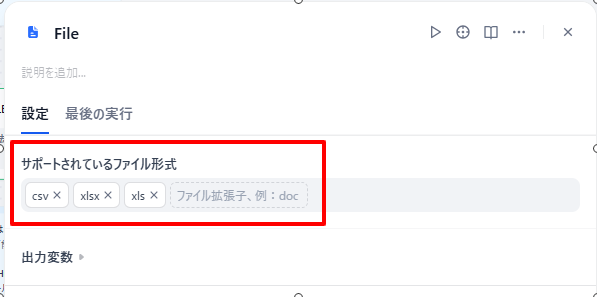
-
KNOWLEDGE BASEブロックに埋め込みモデルとRerankモデルを設定します。
-
アプリを公開します。
実行手順 今回は以下のようなCSVファイルを使います。1列目に質問、2列目に回答を記載しています。
質問,回答 Difyのナレッジパイプラインとは何ですか?,アップロードした文書やデータを処理し、チャンク化や埋め込み生成などを自動で行い、LLMが活用できる知識ベースを構築する仕組みです。 ナレッジパイプラインの主な役割は何ですか?,生の文書をLLMが使いやすい形式に変換し、検索性と回答精度を高めることです。 ナレッジパイプラインで使えるチャンク化の方法には何がありますか?,General、Parent-Child、Q&Aの3種類のチャンク戦略があります。 Generalチャンク化の特徴は何ですか?,文書を段落や文字数単位でシンプルに分割する方式で、汎用性が高く、設定も容易です。 Parent-Childチャンク化のメリットは何ですか?,子チャンクで精度の高い検索を行い、親チャンクで文脈を補うため、正確さと一貫性を両立できます。 Q&Aチャンク化はどのようなケースで使いますか?,FAQや表形式のQ&Aデータのように、質問と回答が明確に対応している場合に適しています。 ナレッジパイプラインで埋め込みを生成する目的は何ですか?,テキストをベクトル化し、意味検索を可能にすることで、ユーザーの質問に関連性の高い情報を返せるようにするためです。 ナレッジパイプラインを利用する利点は何ですか?,知識の整理と検索効率の向上により、LLMの回答精度が改善され、業務知識の活用がスムーズになります。 ナレッジパイプラインの課題や注意点は何ですか?,チャンクサイズの設定を誤ると文脈が途切れたり、検索効率が落ちたりする可能性があります。 どのようなシーンでナレッジパイプラインが有効ですか?,社内マニュアル検索、FAQ対応、自社データを活用したカスタマーサポートなど、ドキュメント知識をAI活用したい場面で有効です。 -
「ドキュメント」タブからファイルを追加します。
-
質問列と回答列の番号を指定し、ナレッジベースへの保存を開始します。
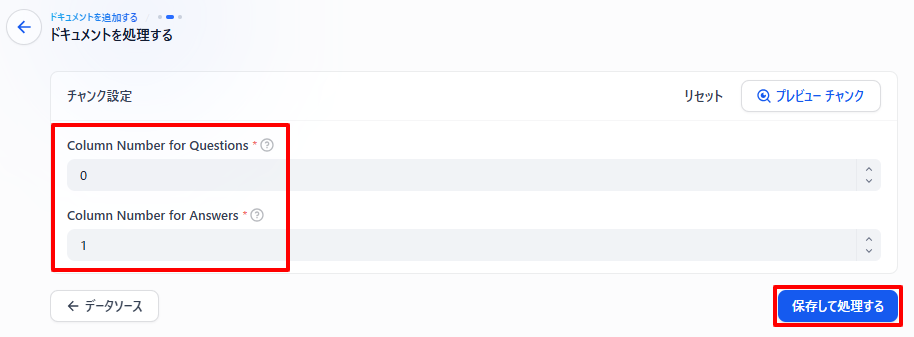
:::message alert
Dify上での列番号「0」は、ファイルの「1」列目を指します。
:::
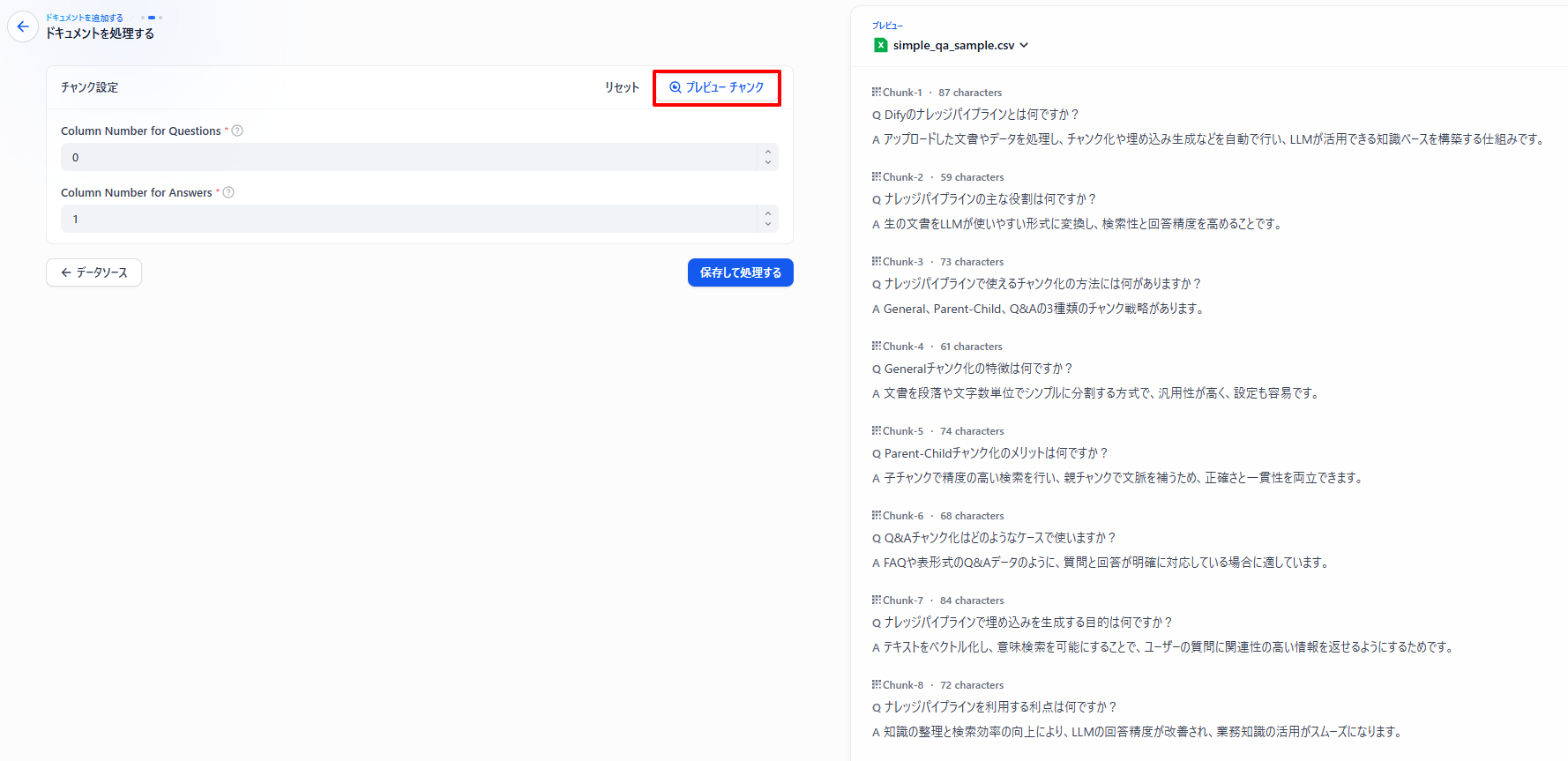
「プレビューチャンク」を押すと事前にどのようにナレッジに登録されるか確認できます。
-
ナレッジベースへの保存が完了しました。
ナレッジベース(アウトプット)
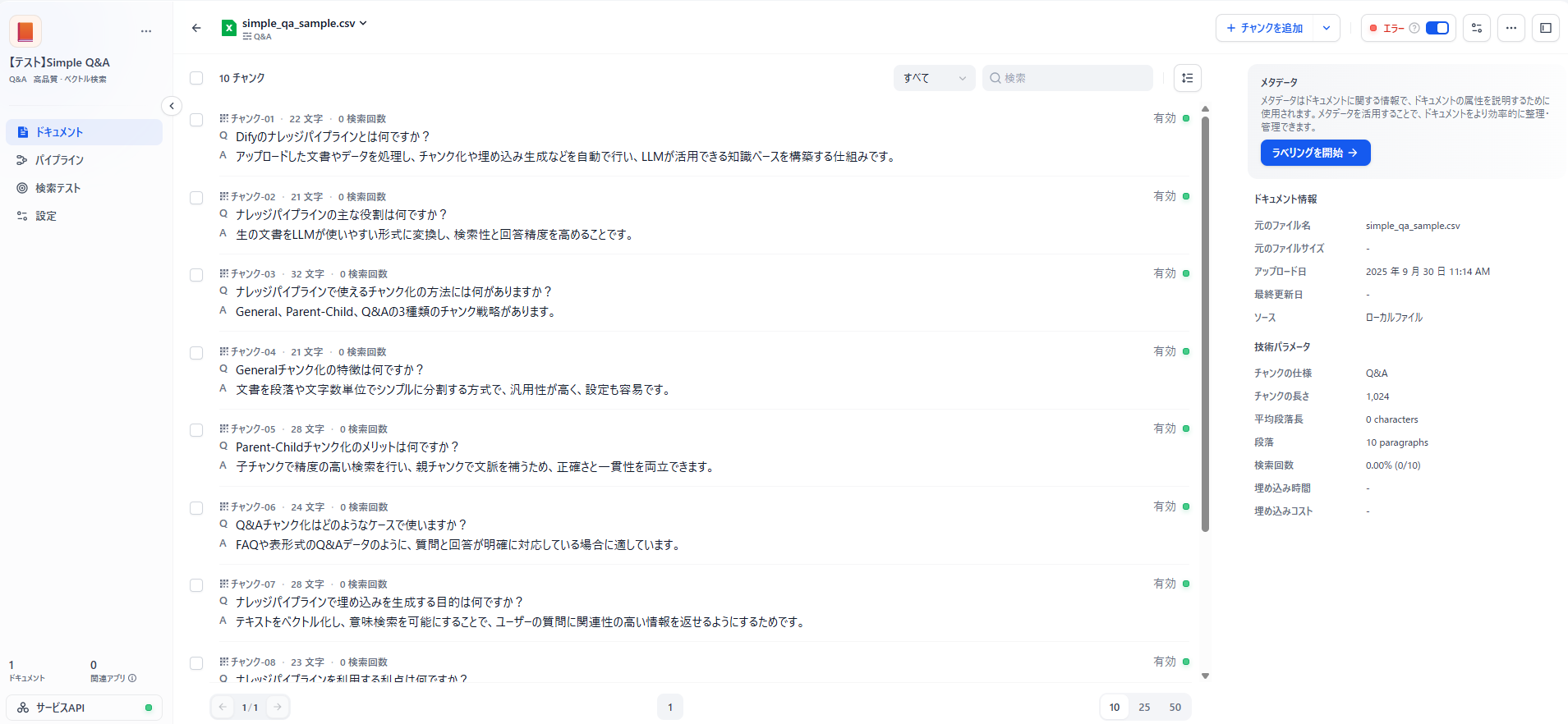
以下のように、チャンクごとに質問と回答がセットになったQ&A形式で保存されます。
サマリー
ファイル形式、ユースケースごとにパイプラインの使い分けをまとめます。
ファイル形式ごとの使い分け
| ファイル形式 | インテリジェントQ&A生成 | 文書形式変換 | 一般文書処理 | 長文書処理 | Q&A表データ抽出 |
|---|---|---|---|---|---|
| .xlsx、.xls、.csv | 〇 | 〇 | 〇 | 〇 | 〇 |
| .pptx | 〇 | 〇 | 〇 | 〇 | × |
| .txt | 〇 | 〇 | 〇 | 〇 | × |
| .docx | 〇 | 〇 | 〇 | 〇 | × |
| 〇 | 〇 | 〇 | 〇 | × | |
| Webクローリング | 〇 | 〇 | 〇 | 〇 | × |
○: 使用可能 ×: 使用不可
ユースケースごとの使い分け
| ユースケース | インテリジェントQ&A生成 | 文書形式変換 | 一般文書処理 | 長文書処理 | Q&A表データ抽出 |
|---|---|---|---|---|---|
| 社内情報Q&Aチャットボット | ○ | ○(EXCELや表にまとまっている場合のみ) | |||
| 製品カタログに関するチャットボット | ○ | ○ | |||
| Webクロールなどによる膨大なデータソース | ○ | × | |||
| 論文など章立てて構成されている文書のデータソース | ○ | ○ | × | ||
| ファイル形式がOffice形式の場合のデータソース | ○ | × |
○: オススメ ×: 使用不可
おわりに
Dify v1.9.0から追加された新機能「ナレッジパイプライン」について、デフォルトで提供されている5種類のテンプレートの挙動と性能を比較検証しました。 クラウド版のv1.9.0では、下記の画像のように「複雑なPDF解析」と「マルチモーダルコンテンツ強化」というテンプレートも存在していました。しかし、v1.9.1ではこれらは消えていたため、5種類のテンプレートのみ紹介しました。今後のアップデートで復活した際には改めて使ってみたいと考えています。
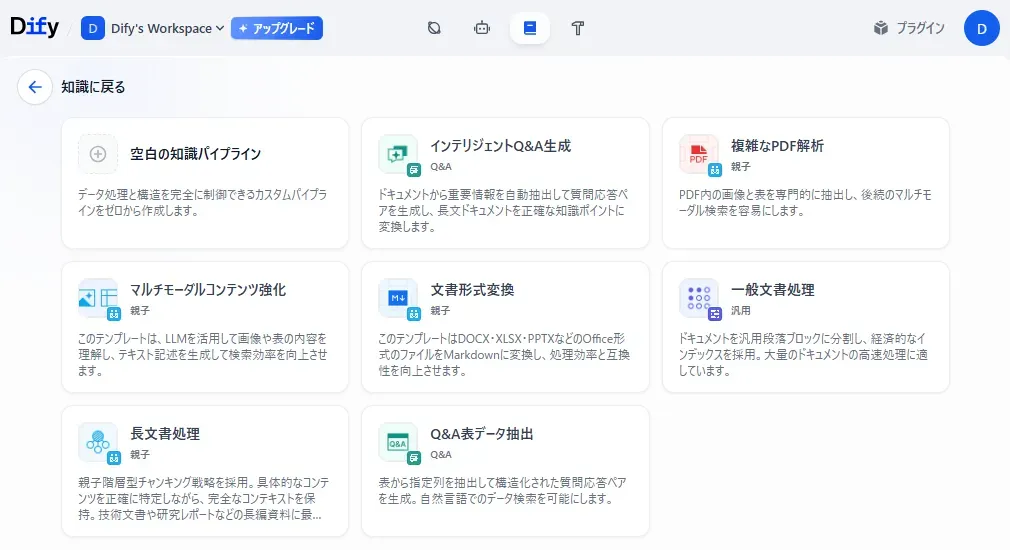 また、今回は試しませんでしたが、ワークフローにOCR機能などを組み込むことで、画像データもナレッジベースの対象として活用できます。
本記事でご紹介したテンプレートは、あくまで出発点です。この記事が、皆さまがご自身のデータに最適なナレッジパイプラインを構築する上での一助となれば幸いです
また、今回は試しませんでしたが、ワークフローにOCR機能などを組み込むことで、画像データもナレッジベースの対象として活用できます。
本記事でご紹介したテンプレートは、あくまで出発点です。この記事が、皆さまがご自身のデータに最適なナレッジパイプラインを構築する上での一助となれば幸いです
記事を読んで「自社環境に落とし込むのは難しそう…」と感じたら? ナレッジパイプラインの構築は、データ形式や業務内容によって最適な設定が異なります。「自社データで試したけどうまくいかない」「ハルシネーション(AIの嘘)のない実用的な社内AIを早く立ち上げたい」という時は、一人で悩まず弊社へご相談ください! RAG構築のノウハウを持つプロが、貴社専用のパイプライン設計から運用まで伴走するDify導入ソリューションでサポートいたします。まずは「こんなことできる?」とお気軽にご相談ください。