はじめに
この記事について
この記事では、生成AIのプロンプト技術についてのサーベイ論文(The Prompt Report: A Systematic Survey of Prompting Techniques)をもとに大規模言語モデル(LLM)を効果的に活用するためのプロンプト技術について解説します。プロンプトは、AIモデルに対する指示として機能し、回答の質を大きく左右します。プロンプト技術の基本的な概念から、具体的なテクニックまでを解説します。
対象者
- プロンプトエンジニアリングのテクニックを知りたい人
- 論文を読む時間がない人
- 辞書的に使いたい人
これを読むと何が嬉しいか?
- LLMの回答精度を上げるためにプロンプトのテクニックが重要であることを理解できる
- プロンプトの定石とテクニックについて知ることができる
プロンプト技術の解説
この記事は、論文 (The Prompt Report: A Systematic Survey of Prompting Techniques) の2章のテキストベースのプロンプト技術について紹介します。論文の2章のテキストベースのプロンプト技術は大まかに6つに分けることができます。
-
フューショット (Few-shot)
-
ゼロショット (Zero-shot)
-
思考生成 (Thought Generation)
-
分解 (Decomposition)
-
アンサンブル (Ensembling)
-
自己批判 (Self-Criticism) 次からは、プロンプト技術の詳細を説明します。
 The Prompt Report: A Systematic Survey of Prompting Techniquesより作成
The Prompt Report: A Systematic Survey of Prompting Techniquesより作成
1. フューショットプロンプト (Few-Shot Prompting)
フューショットプロンプトとはプロントで例を与えることで出力を学習させる方法です。複雑な質問の場合プロンプトで複数の例文を示すことで精度の高い出力が期待されます。
プロンプト:
これは素晴らしい! // ネガティブ
これは酷い! // ポジティブ
あの映画は最高だった! // ポジティブ
なんてひどい番組なんだ! //
結果:
ネガティブ
フューショット学習とは (Few-Shot Learning / FSL)
**フューショット学習 (FSL) **はよくフューショットプロンプトと間違われますが、FSLは少数の例で生成AIのパラメーター調整を行う学習の方法です。一方で、フューショットプロンプトはプロンプトそのものでモデルの生成AIのパラメーターの更新を行いません。
フューショットプロンプトの設計 (Few-Shot Prompting Design Decisions)
プロンプトの例文を作成するのは困難な作業であり、精度は例文の様々な要因に大きく依存します。また、コンテキストウィンドウに収まる例文の数は限られています。出力の品質に決定的な影響を与える模範的な選択と順序など、6つの設計方法を紹介します。
- 例文の量 (Exemplar Quantity) プロンプトの複数の例文を増やすと、一般的に、特に大規模なモデルで精度が向上します。ただし、場合によっては、例文の数が20を超えた場合効果が減少する可能性があります。
- 例文の順番 (Exemplar Ordering) 例文の順序はモデルの動作に影響します。一部のタスクでは、例文の順序により精度が50%未満から90%まで変動する可能性が示唆されています。
- 例文の分布 (Exemplar Label Distribution) 従来の教師あり機械学習と同様に、プロンプト内の例文ラベルの分布は精度に影響します。たとえば、あるクラスから10個の例文、別のクラスの2個の例文が含まれている場合、モデルが最初のクラスに偏る可能性があります。
- 例文のラベル (Exemplar Label Quality) ラベルの精度は無関係であり、モデルに誤ったラベルを持つ例文を与えることで、精度がマイナスに低下しない可能性があります。 ただし、特定の設定では、精度に大きな影響を与えます。多くの場合、大きなLLMでは、正しくないラベルや無関係なラベルの処理に適しています。 不正確さが含まれている可能性のある大規模なデータセットからプロンプトを自動的に作成している場合は、ラベルの品質が結果にどのように影響するかを調査する必要があるため、この要素について議論が必要です。
- 例文の形式 (Exemplar Format) 例文のの形式も精度に影響します。最も一般的な形式の1つは "Q: {input}, A: {label}" ですが、最適な形式はタスクによって異なる場合があります。複数の形式を試して、どの形式が最も効果的かを確認した方が良いでしょう。学習データで一般的に出現する形式が精度の向上につながる報告がいくつかあります。
- 例文の類似性 (Exemplar Similarity) 想定質問に類似した例文を選択することは、一般的に有益です。ただし、場合によっては、より多様な例文を選択することで、精度を向上させることができます。
フューショットプロンプトのテクニック (Few-Shot Prompting Techniques)
フューショットプロンプトを効果的に実装することは非常に難しい場合があります。教師あり設定でのフューショットプロンプトの手法を解説します。
- k近傍法 (K-Nearest Neighbor /KNN) 類似した例文を選択するアルゴリズムです。精度を向上させることが可能です。プロンプト生成中に KNN を使用すると効果的ですが、多くの時間とリソースが必要になる場合があります。
- 投票-K (Vote-K) テストサンプルに類似した例文を選択する別の方法です。最初の段階では、モデルはアノテーターがラベルを付けるための有用なラベル付けされていない候補の例文を提案します。第2段階ではラベル付けされたプールがフューショットプロンプトに使用されます。また、投票-Kは新たに追加された例文が既存の例文と十分に異なることを確認し、多様性と代表性を高めることが可能です。
- 自己生成型文脈内学習 (Self-Generated In-Context Learning /SG-ICL) 生成AIを活用して例文を自動的に生成します。トレーニング データが利用できない場合、ゼロショットシナリオよりも優れていますが、生成されたサンプルは実際のデータほど効果的ではありません。
- プロンプトマイニング (Prompt Mining) 大規模なコーパス分析を通じて、プロンプト(効果的にプロンプトテンプレート)内の最適な「中間語」を発見します。たとえば、フューショットプロンプトに使われる一般的な "Q: A:" 形式の代わりに、コーパスでより頻繁に出現する類似のものが存在する可能性があります。コーパスでより頻繁に出現するフォーマットは、迅速な精度の向上につながる可能性があります。
より複雑なテクニック (More Complicated Techniques)
反復フィルタリング、埋め込みと検索、強化学習を活用する方法があります。
2. ゼロショット (Zero-Shot)
ゼロショットプロンプトは、フューショットプロンプトとは対照的に例文を使用しません。よく知られた単体でのゼロショット技術や後で説明する別の概念(思考連鎖など)と組み合わせたゼロショット技術がいくつかあります。
プロンプト:
テキストを中立、否定的、または肯定的に分類してください。
テキスト: 休暇はまずまずでした。
所感:
結果:
中立
ロールプロンプト (Role Prompting)
ペルソナプロンプトとも呼ばれます。プロンプトで 生成AI に特定のロールを割り当てます。たとえば、ユーザーは「マドンナ」や「旅行作家」のように設定します。これにより、オープンエンドのタスクに対してより望ましい出力を作成できます。ベンチマークの精度を向上させる可能性があります。
スタイルプロンプト (Style Prompting)
プロンプトで目的のスタイル、トーン、またはジャンルを指定して、生成AIの出力を形作ります。ロール プロンプトを使用しても同様の効果を実現できます。
感情プロンプト (Emotion Prompting)
人間に心理的な関連性のあるフレーズ(例:「これは私のキャリアにとって重要です」)をプロンプトに組みこむことでベンチマークでのLLM精度の向上や自由形式のテキスト生成につながる可能性があります。
システム2アテンション (System 2 Attention / S2A)
LLM にプロンプトを書き換え、その中の質問に関係のない情報を削除するように依頼します。次に、この新しいプロンプトを LLM に渡して、最終的な出力を取得します。
SimToM
複数の人や物が関与する複雑な問題を扱います。質問が与えられたとき、それは一人の人が知っている一連の事実を確立しようと試み、それからそれらの事実のみに基づいて質問に答えます。これは2つのプロンプトプロセスであり、プロンプト内の無関係な情報の影響を排除するのに役立ちます。
言い換えと応答 (Rephrase and Respond RaR)
最終的な回答を生成する前に、質問を言い換えて出力するように LLM に指示します。たとえば、質問に「質問を言い換えて出力する」というフレーズを追加するなどです。これはすべて 1 回のパスで行うことも、新しい質問を LLM に個別に渡すこともできます。RaRは、複数のベンチマークで改善が実証されています。
再読 (Re-reading RE2)
質問を繰り返すだけでなく、「質問をもう一度読んでください」というフレーズをプロンプトに追加します。これは非常に単純な手法ですが、特に複雑な質問の場合、推論ベンチマークの改善が示されています。
自己質問 (Self-Ask)
LLM に対して、特定のプロンプトに対してフォローアップの質問をする必要があるかどうかを最初に決定するように促します。その場合、LLM はこれらの質問を生成し、次にそれらに回答し、最終的に元の質問に回答します。
3. 思考生成 (Thought Generation)
思考生成には、LLMが問題を解決しながらその推論を明確にするように促すさまざまな手法が含まれます。
思考連鎖プロンプト (Chain-of-Thought (CoT) Prompting)
フューショットプロンプトを活用して、LLM が最終的な回答を出す前に思考プロセスを表現するように促します。この手法は、思考連鎖と呼ばれることもあります。これは、数学および推論タスクにおけるLLMの精度を大幅に向上させることが実証されています。プロンプトには、質問、推論パス、および正解を特徴とする例文が含まれます。
プロンプト:
このグループの奇数を合計すると偶数になります。: 4、8、9、15、12、2、1。
A: 奇数を全て加えると(9, 15, 1)25になります。答えはFalseです。
このグループの奇数を合計すると偶数になります。: 17、10、19、4、8、12、24。
A: 奇数を全て加えると(17, 19)36になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 16、11、14、4、8、13、24。
A: 奇数を全て加えると(11, 13)24になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 17、9、10、12、13、4、2。
A: 奇数を全て加えると(17, 9, 13)39になります。答えはFalseです。
このグループの奇数を合計すると偶数になります。: 15、32、5、13、82、7、1。
A:
結果:
奇数を全て加えると(15, 5, 13, 7, 1)41になります。答えはFalseです。ゼロショットCoT (Zero-Shot-CoT)
CoT の最も単純なバージョンは例文がありません。これには、「ステップバイステップで (step-by-step)」のような思考を誘発するフレーズを追加することが含まれます。他にも、「正しい答えがあることを確認するために、段階的に解決しましょう」など、思考を生み出すフレーズが提案されています。そして「まず、これを論理的に考えよう」のような最適な思考誘導を探します。ゼロショットCoTアプローチは、例文を必要とせず、一般的にタスクに依存しません。
ステップバックプロンプト (Step-Back Prompting)
CoT の修正版であり、聞きたい質問をする前に、質問に関連する概念や事実についての質問をします。このアプローチにより、PaLM-2LとGPT-4の両方の複数の推論ベンチマークで精度が大幅に向上しました。
類推的プロンプト (Analogical Prompting)
SG-ICL に似ており、CoT を含む例文を自動的に生成します。数学的推論とコード生成タスクの改善が実証されています。
思考の糸プロンプト (Thread-of-Thought (ThoT) Prompting)
CoT推論のための改良された思考誘導で構成されています。「ステップバイステップで (step-by-step)」ではなく、「この文脈を扱いやすい部分で段階的に説明し、進めながら要約して分析する」というものを使用します。この思考誘導は、特に大規模で複雑なコンテキストを扱う場合に、質問応答や検索の設定でうまく機能します。
表形式の思考連鎖 (Tabular Chain-of-Thought /Tab-CoT)
LLM 出力推論をマークダウンテーブルとするゼロショットCoTプロンプトで構成されます。この表形式のデザインにより、LLMは構造を改善し、その結果、その出力の推論を向上させることができます。
フューショットCoT ( Few-Shot CoT)
この一連の手法は、思考連鎖を含む複数の例示をLLMに提示します。これにより、精度が大幅に向上します。この手法は、Manual-CoTまたはゴールデンCoTデルと呼ばれることもあります。
対照的なCoTプロンプト (Contrastive CoT Prompting)
不正確な説明と正しい説明を持つ両方の例をCoTプロンプトに追加して、LLMに推論しない方法を示します。この方法は、算術推論や事実QAなどの分野で大幅な改善を示しています。
不確実性によるCoTプロンプト (Uncertainty-Routed CoT Prompting)
複数の CoT 推論パスをサンプリングし、特定のしきい値 (検証データに基づいて計算) を超えている場合は多数派を選択します。そうでない場合は、サンプリングし、その応答を選択します。この方法は、GPT4モデルとGemini Ultraモデルの両方でMMLUベンチマークの改善を示しています。
複雑性に基づくプロンプト (Complexity-based Prompting)
CoTには2つの主要な変更が含まれます。まず、質問の長さや必要な推論手順などの要素に基づいて、注釈を付けてプロンプトに含めるための複雑な例を選択します。次に、推論中に、複数の回答をサンプリングし、特定の長さのしきい値を超える回答で多数決を使用します。これは、推論が長いほど回答の品質が高いことを示すという前提です。この手法は、3つの数学的推論データセットで改善を示しています。
アクティブプロンプト (Active Prompting)
いくつかのトレーニング問題/例文から始め、LLMにそれらを解くように依頼し、次に不確実性を計算し、人間のアノテーターに不確実性が最も高い例文を書き直すように依頼します。
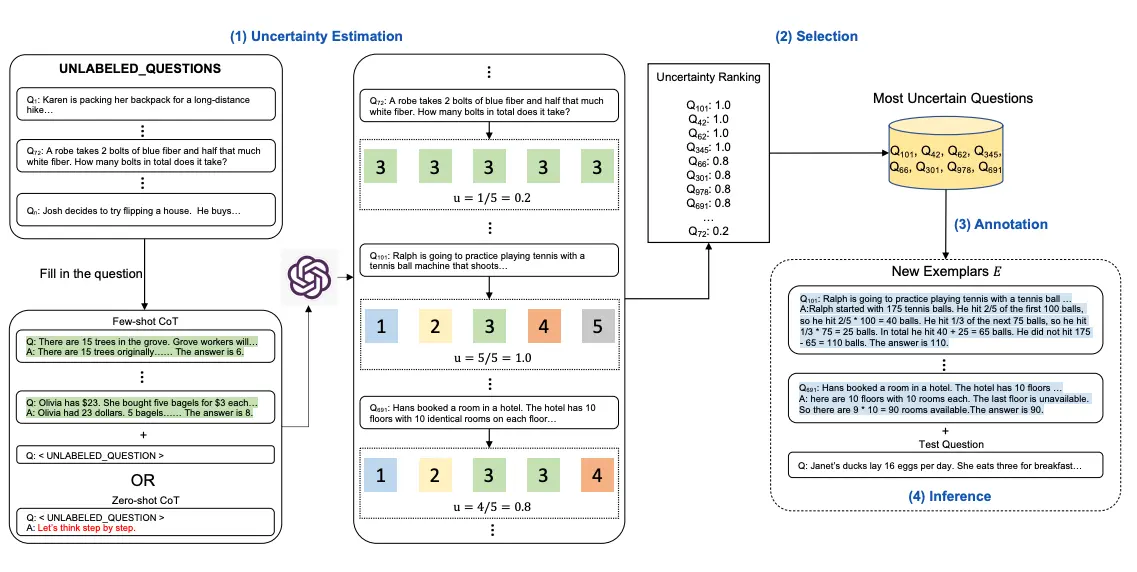
思考の記憶プロンプト (Memory-of-Thought Prompting)
ラベルのないトレーニングの例文を活用して、テスト時にフューショットCoT プロンプトを作成します。テストの前に、CoT を使用してラベルなしトレーニングの 例文に対して推論を実行します。テスト時には、テスト・サンプルと同様のインスタンスが取得されます。この手法は、算術、常識、事実推論などのベンチマークで大幅な改善を示しています。
自動思考連鎖プロンプト (Automatic Chain-of-Thought (Auto-CoT) Prompting)
ゼロショットプロンプトで思考連鎖を自動的に生成します。その後、これらを使用して、テスト サンプルのフューショット CoT プロンプトを作成します。
4. 分解 (Decomposition)
複雑な問題を単純なサブ質問に分解することは問題解決に有効です。これは、人間にとっても生成AIにとっても効果的です。一部の分解手法はCoTなどの手法に似ており、多くの場合、問題をより単純なコンポーネントに分解します。問題を分解することで、LLMの問題解決能力をさらに向上させることができます。
最小から最大プロンプト (Least-to-Most Prompting)
LLM に特定の問題を解決せずにサブ問題に分割するように促します。次に、それらを順番に解決し、最終結果に到達するまで、毎回モデルの応答をプロンプトに追加します。この方法は、記号操作、構成の一般化、および数学的推論を含むタスクで大幅な改善を示しています。
分解されたプロンプト (Decomposed Prompting / DECOMP)
フューショット はLLM に特定の関数の使用方法を示すように促します。これには文字列の分割やインターネット検索などが含まれる場合があります。これらは多くの場合、個別の LLM 呼び出しとして実装されます。LLM は元の問題をサブ問題に分割し、それをさまざまな関数に送信します。一部のタスクでは、最小から最大 プロンプトよりも精度が向上しています。
計画と解決 (Plan-and-Solve Prompting)
改良されたゼロショット CoT プロンプト「まず問題を理解し、それを解決するための計画を考案しましょう。そして、計画を実行し、問題を一歩一歩解決していきましょう」を使用する方法では、複数の推論データセットでゼロショット CoT よりも堅牢な推論プロセスが生成されます。
思考の木 (Tree-of-Thought / ToT)
思考の木とも呼ばれ、最初の問題から始めて、思考の形で複数の可能なステップを生成することによりツリーのような探索問題を作成します 。それは、(プロンプトを通じて)問題を解決するための各ステップの進行状況を評価し、どのステップを続行するかを決定し、その後、さらに思考を生み出し続けます。ToTは、検索と計画が必要なタスクに特に効果的です。
思考の再帰 (Recursion-of-Thought)
通常のCoTと似ています。ただし、推論チェーンの途中で複雑な問題が発生するたびに、この問題を別のプロンプト/LLM 呼び出しに送信します。これが完了すると、回答が元のプロンプトに挿入されます。このようにして、その最大コンテキスト長を超える可能性のある問題を含む複雑な問題を再帰的に解決できます。この方法は、算術タスクとアルゴリズムタスクの改善を示しています。サブ問題を別のプロンプトに送信する特別なトークンを出力するために実装されますが、プロンプトを通じてのみ実行することもできます。
思考プログラム (Program-of-Thoughts)
Codex のような LLM を使用して、推論ステップとしてプログラミング コードを生成します。コードインタープリターはこれらの手順を実行して最終的な答えを取得します。数学およびプログラミング関連のタスクには優れていますが、意味推論タスクにはあまり効果的ではありません。
忠実な思考連鎖 (Faithful Chain-of-Thought)
思考プログラムと同様に、自然言語と記号言語(Pythonなど)の両方の推論を持つCoTを生成します。ただし、タスクに依存する方法でさまざまな種類の記号言語も利用します。
思考のスケルトン (Skeleton-of-Thought)
並列化による応答速度の高速化に焦点を当てています。問題が与えられると、LLM は解決すべきサブ問題を作成するように促されます。次に並行して、これらの質問を LLM に送信し、すべての出力を連結して最終的な応答を取得します。
5. アンサンブル (Ensembling)
生成AI でのアンサンブルとは複数のプロンプトを使用して同じ問題を解決し、これらの応答を集約して最終出力を生成するプロセスです。多くの場合、最終出力を生成するために多数決が使用されます。アンサンブル手法はLLM 出力の分散を減らし、多くの場合精度を向上させますが、最終的な答えに到達するのに必要なモデル数を増やす可能性があります。。
デモンストレーションアンサンブル (Demonstration Ensembling /DENSE)
トレーニング セットからの個別のサンプル サブセットを含む複数のフューショットプロンプトを作成します。次にそれらの出力を集約して最終的な応答を生成します。
推論の専門家の混合 (Mixture of Reasoning Experts /MoRE)
さまざまな推論タイプ (事実推論の検索拡張プロンプト、マルチホップおよび数学推論の思考連鎖推論、常識推論の生成知識プロンプトなど) に異なる専門プロンプトを使用して、多様な推論エキスパートのセットを作成します。すべてのエキスパートからの最適な回答は合意スコアに基づいて選択されます。
最大相互情報量法 (Max Mutual Information Method)
さまざまなスタイルと例を持つ複数のプロンプト テンプレートを作成し、プロンプトと LLM の出力間の相互情報量を最大化する最適なテンプレートを選択します。
自己一貫性 (Self-Consistency)
複数の異なる推論パスが同じ答えにつながる可能性があるという直感に基づいています。この方法ではまず LLM に複数回 CoT を実行させますが、重要なのは多様な推論パスを引き出すために温度をゼロ以外にすることです。次に、生成されたすべての応答に対して多数決を使用して最終的な応答を選択します。自己一貫性は、算術、常識、記号推論のタスクで改善を示しています。
普遍的な自己一貫性 (Universal Self-Consistency)
自己一貫性に似ていますが、プログラムで発生頻度をカウントして多数決の回答を選択するのではなく、すべての出力を多数決の回答を選択するプロンプト テンプレートに挿入する点が異なります。これは自由形式のテキスト生成や同じ回答が異なるプロンプトによってわずかに異なる形で出力される場合に役立ちます。
複数の CoT でのメタ推論 (Meta-Reasoning over Multiple CoTs)
普遍的な自己一貫性に似ています。まず、与えられた問題に対して複数の推論チェーン を生成します。次に、これらすべてのチェーンを 1 つのプロンプト テンプレートに挿入し、そこから最終的な答えを生成します。
DiVeRSe
特定の問題に対して複数のプロンプトを作成し、それぞれに対して自己一貫性を実行して、複数の推論パスを生成します。推論パスの各ステップに基づいてスコアを付け、最終的な応答を選択します。
一貫性に基づく自己適応型プロンプト (Consistency-based Self-adaptive Prompting / COSP)
一連の例に対して自己一貫性を備えたゼロショット CoT を実行し、最終プロンプトに例として含める出力の一致度の高いサブセットを選択して、フューショット CoT プロンプトを構築します。この最終プロンプトで再び自己一貫性を実行します。
ユニバーサル自己適応プロンプト (Universal Self-Adaptive Prompting / USP)
COSP の成功を基にして、すべてのタスクに一般化できるようにすることを目的としています。USP はラベルなしデータを使用してサンプルを生成し、より複雑なスコアリング関数を使用してサンプルを選択します。また、USP は自己一貫性を使用しません。
プロンプトパラフレーズ (Prompt Paraphrasing)
全体的な意味を維持しながら、一部の文言を変更することで元のプロンプトを変換します。これはアンサンブルのプロンプトを生成するために使用できる事実上のデータ拡張技術です。
6. 自己批判 (Self-Criticism)
生成AIシステムを作成する場合、LLMに自身の出力を批判させることは有用です 。これは単純に判断である場合もあれば、LLM にフィードバックを提供するよう促して、それを使用して回答を改善することもできます。自己批判を生成し、統合するための多くのアプローチが開発されてきました。 論文: Large Language Models Can Self-Improve
セルフキャリブレーション (Self-Calibration)
まず 、LLM に質問に答えるよう促します。次に、質問、LLM の回答、回答が正しいかどうかを尋ねる追加の指示を含む新しいプロンプトを作成します。これは、元の回答を受け入れるか修正するかを決定する際に LLM を適用する際の信頼度を測定するのに役立ちます。
自己改善について (Self-Refine)
反復的なフレームワークであり、LLM からの最初の回答が与えられると、同じ LLM に回答に関するフィードバックを提供するよう促します。次に、 LLM にフィードバックに基づいて回答を改善するよう促します。この反復プロセスは停止条件が満たされるまで (たとえば、最大ステップ数に達するまで) 継続されます。自己改善 は推論、コーディング、および生成のさまざまなタスクにわたって改善を実証しています。 論文: Self-Refine: Iterative Refinement with Self-Feedback
思考連鎖の逆転 (Reversing Chain-of-Thought /RCoT)
まず、 LLM に生成された回答に基づいて問題を再構築するように指示します。次に、元の問題と再構築された問題の間で細かい比較を生成し、矛盾がないか確認します。これらの矛盾は生成された回答を修正するための LLM へのフィードバックに変換されます。
自己検証 (Self-Verification)
思考連鎖(CoT) を使用して複数の候補ソリューションを生成します。次に、元の質問の特定の部分を隠し、残りの質問と生成されたソリューションに基づいて LLM に予測させることで、各ソリューションにスコアを付けます。この方法は8 つの推論データセットで改善を示しました。
検証チェーン (Chain-of-Verification / COVE)
まず 、LLM を使用して、与えられた質問に対する回答を生成します。次に、回答の正確さを検証するのに役立つ関連質問のリストを作成します。各質問は LLM によって回答され、その後、すべての情報が LLM に渡されて、最終的な修正回答が生成されます。この方法はさまざまな質問応答タスクとテキスト生成タスクで改善が見られました。
累積推論 (Cumulative Reasoning)
まず、質問に答えるためのいくつかの潜在的なステップを生成します。次に、LLM にそれらを評価させて、これらのステップを受け入れるか拒否するかを決定します。最後に、最終的な答えに到達したかどうかを確認します。到達した場合はプロセスを終了しますが、そうでない場合は繰り返します。この方法は論理的推論タスクと数学の問題で改善が実証されています。
まとめ
この記事では、生成AIのプロンプト技術についてのサーベイ論文(The Prompt Report: A Systematic Survey of Prompting Techniques)をもとに生成AIモデル、特に大規模言語モデル(LLM)を効果的に活用するためのテキストベースのプロンプト技術について解説しました。プロンプトは、AIモデルに対する指示として機能し、その応答の質を大きく左右します。今後業務や実際のシステム開発に役立てられたら幸いです。
