関連記事
https://blog.elcamy.com/posts/136913a3/
https://blog.elcamy.com/posts/ed655d0a/
https://blog.elcamy.com/posts/54294ff0
https://blog.elcamy.com/posts/a5744c61/
はじめに
LangGraphを知らない方、わからない方は、まず「LangGraphとは」をご覧ください。 この記事ではLangGraphを初めて使う方に向けて、LangGraphの公式ページに用意されているチュートリアルを解説します。今回解説するチュートリアルは「Self-RAG」です。
記事の対象者
- LangGraph初学者
- LangChain初学者
Self-RAGとは
Self-RAG(Self-Retrieval-Augmented Generation) とは、LLMが質問に対して回答を生成する際に、関連情報を検索し、自己評価しながら回答の精度を高める仕組みです。 具体的には、次のような流れで動きます:
- 質問を受け取る
- 関連する情報(ドキュメント)を検索する
- 検索結果が質問に関連しているか評価し、不適切なら質問を改善して再検索
- 検索結果を基に回答を生成する
- 回答が事実に基づいているか、質問に対して適切か自己評価する このように、LLM自身が情報検索と回答生成、評価を繰り返し行うことで、より正確で信頼性の高い回答を提供できるのが Self-RAG の特徴です。
チュートリアルの概要
まず、ユーザーから質問を取得して、関連するドキュメントを検索します。それから、検索結果と質問との関連性を評価します。関連性のあるドキュメントを基に回答を生成し、さらに回答に誤りや不足がないかをチェックしてから、最終的な回答を出力します。 今回作成するシステムは以下の通りです。
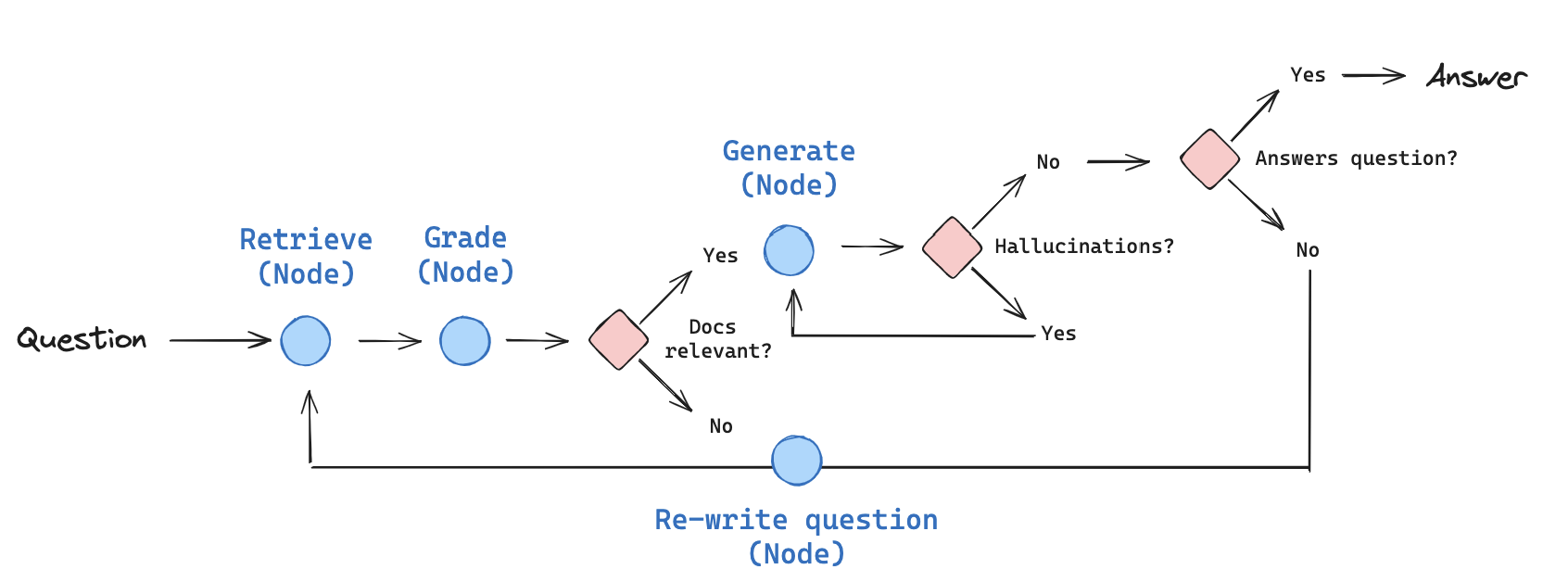 なお、このチュートリアルはSelf-RAGの基本的な仕組みを学ぶために簡略化されており、実際のSelf-RAGシステムの完全な再現ではありません。実際のSelf-RAGでは、より高度な評価基準やアルゴリズムが使用されている場合がありますが、チュートリアルでは概念の理解と実装の基礎に重点を置いています。
なお、このチュートリアルはSelf-RAGの基本的な仕組みを学ぶために簡略化されており、実際のSelf-RAGシステムの完全な再現ではありません。実際のSelf-RAGでは、より高度な評価基準やアルゴリズムが使用されている場合がありますが、チュートリアルでは概念の理解と実装の基礎に重点を置いています。
チュートリアルの解説
✅ステップ
- 準備
- 質問に基づき関連するドキュメントを検索
- 検索結果の評価
- ユーザーの質問に対する回答を生成
- 事実に基づいているかを評価
- ユーザーの質問に応答しているかを評価
- 質問を検索に適した形に整形
- グラフ状態を管理するデータ構造の定義
- ノードとエッジの定義
- ワークフローをグラフとして構築する
1.準備
今回のチュートリアルに必要なライブラリのインストール、APIキーの設定をします。 ライブラリのインストールは以下のコマンドを実行してください。
! pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph次にOpenAIのAPIキーを環境変数に設定します。チュートリアルに以下のコードを追加してください。
import getpass
import os
def _set_env(key: str):
if key not in os.environ:
os.environ[key] = getpass.getpass(f"{key}:")
_set_env("OPENAI_API_KEY")2.質問に基づき関連するドキュメントを検索
ここでは、ウェブページから取得したデータをベクトル化し、効率的に検索可能なデータベースとして利用できるようにします。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()コード解説
WebBaseLoader を使用して、指定した urls リストに含まれるウェブページの内容を取得します。取得したデータは docs に格納され、リスト docs_list に展開されます。
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]RecursiveCharacterTextSplitter を使い、取得したウェブページの内容を一定のサイズ(chunk_size=250)で分割します。この際、テキストの重複を避けるために chunk_overlap=0 を設定します。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)分割されたテキスト(doc_splits)を、Chromaというベクトルデータベースに保存します。この際、OpenAIEmbeddings を使って各テキストをベクトル表現に変換します。
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)vectorstore.as_retriever() を使って、ベクトルデータベースを検索可能な状態にします。これにより、クエリを入力すると類似する内容を持つテキストが返されるようになります。
retriever = vectorstore.as_retriever()3.検索結果の評価
ここでは、検索したドキュメントとユーザーの質問の関連性を、LLMを使って評価する仕組みを実装します。
### Retrieval Grader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))コード解説
GradeDocuments クラスを定義し、検索されたドキュメントが質問に関連しているかどうかを評価するためのデータ構造を作成しています。評価結果は、binary_score フィールドに「yes」または「no」の形式で格納されます。
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)OpenAIの言語モデルを初期化します。
さらに、with_structured_output を使用して、GradeDocuments の形式で出力を生成するようモデルを拡張します。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)AIがドキュメントの関連性を判定するためのプロンプトを作成します。
- **
system**はAIに与える役割とタスクの説明です。以下の内容を指定しています。-
ドキュメントが質問に関連しているかを評価します。
-
キーワードや質問に関連する意味が一致していれば「yes」、そうでなければ「no」を返します。
-
エラーのある検索結果をフィルタリングします。
pythonsystem = """You are a grader assessing relevance of a retrieved document to a user question. \n It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""プロンプトを構造化し、質問(
question)とドキュメント(document)を入力できるようにテンプレート化します。pythongrade_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Retrieved document: \n\n {document} \n\n User question: {question}"), ] )プロンプトと構造化されたLLMをチェーンで接続し、AIが質問とドキュメントを基に評価を行えるようにします。
pythonretrieval_grader = grade_prompt | structured_llm_graderユーザーからの質問をリトリーバーに渡して関連するドキュメントを取得し、その中の特定のドキュメント(
docs[1])を評価します。評価の結果、「yes」または「no」が返されます。pythonquestion = "agent memory" docs = retriever.invoke(question) doc_txt = docs[1].page_content print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
-
4.ユーザーの質問に対する回答を生成
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)コード解説
プロンプトテンプレートを外部から取得します。ここでは hub.pull を使い、rlm/rag-prompt という指定されたプロンプトを取得しています。このプロンプトは、LLMが回答を生成する際の指示を含むテンプレートです。
prompt = hub.pull("rlm/rag-prompt")format_docs 関数を定義し、取得した複数のドキュメントを結合して1つのテキストとして整形します。各ドキュメントの内容(page_content)を改行(\n\n)で区切って結合します。
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)プロンプト(prompt)、LLM(llm)、および出力パーサー(StrOutputParser)をチェーンで接続します。
StrOutputParser()を使用すると出力を文字列として整形できます。
rag_chain = prompt | llm | StrOutputParser()rag_chain.invoke を使い、質問(question)と整形済みのドキュメント(docs)を入力として渡し、回答を生成します。その結果を generation に格納し、コンソールに出力します。
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)5.事実に基づいているかを評価
ここでは、生成された回答が事実に基づいているかどうかを評価するためのシステムを構築します。
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})GradeHallucinations クラスを定義し、生成された回答(generation)が事実(documents)に基づいているかどうかを判定するためのデータ構造を作成します。評価結果は、binary_score に「yes」または「no」で格納されます。
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)OpenAIの言語モデルを初期化し、GradeHallucinations の形式で出力を生成するようにします。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)生成された回答が検索した事実に基づいているかを評価するためのプロンプトを作成します。
- 目的:AIが生成した回答が検索した事実と一致しているかを評価します。
- ルール:一致していれば「yes」、していなければ「no」を返します。
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""このプロンプトを構造化し、入力で事実(documents)と回答(generation)を渡せるようにします。
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)プロンプトとLLMをチェーンで接続し、生成された回答と事実を評価できるようにします。
hallucination_grader = hallucination_prompt | structured_llm_graderhallucination_grader.invoke を使い、事実(docs)と生成された回答(generation)を入力として渡します。これにより、回答が事実に基づいているかどうかの評価が実行されます。
hallucination_grader.invoke({"documents": docs, "generation": generation})6.ユーザーの質問に応答しているかを評価
ここでは、生成した回答がユーザーの質問に適切に応答しているかを評価します。
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})コード解説
GradeAnswer クラスを定義し、生成された回答(generation)がユーザーの質問(question)に適切に答えているかどうかを判定するデータ構造を作成します。
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)OpenAIの言語モデルを初期化し、GradeAnswerの形式で出力を生成するようにします。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)生成された回答がユーザーの質問に応答しているかを評価するための指示をプロンプトとして作成します。
- 目的: AIが生成した回答が、ユーザーの質問を解決しているかを評価します。
- ルール: 質問に答えていれば「yes」、そうでなければ「no」を返します。
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""プロンプトを構造化し、入力で質問(question)と回答(generation)を渡せるようにします。
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)プロンプトとLLMをチェーンで接続し、質問と回答を基に評価できるようにします。
answer_grader = answer_prompt | structured_llm_graderanswer_grader.invoke を使い、質問(question)と生成された回答(generation)を入力として渡します。これにより、回答が質問に適切に応答しているかどうかの評価が実行されます。
answer_grader.invoke({"question": question, "generation": generation})7.質問を検索に適した形に整形
ここでは、検索結果の精度を向上させるために、質問をより具体的で意味が伝わりやすい形に改善します。
### Question Re-writer
# LLM
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
# Prompt
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})コード解説
OpenAIの言語モデルを初期化します。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)質問を改善するためのプロンプトを作成します。ベクトル検索で最適な結果を得られるような形式に書き直すようAIに指示します。
- 目的:質問の意味を考慮し、検索に最適化された形に変換します。
- 強調点: 質問の「セマンティックな意図」や「意味」に基づいて改善します。
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""このプロンプトを構造化し、入力で元の質問(question)を渡せるようにします。
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)プロンプトとLLM、文字列形式で出力を整形するパーサー(StrOutputParser)を連結し、質問を書き直すためのパイプラインを作成します。
question_rewriter = re_write_prompt | llm | StrOutputParser()question_rewriter.invoke を使用して、ユーザーが入力した質問を改善した形式に書き直します。ここでは、入力された質問(question)を渡し、結果を生成しています。
question_rewriter.invoke({"question": question})8.グラフ状態を管理するデータ構造の定義
ここでは、質問の応答における「グラフの状態」を表現するためのデータ構造を定義します。このデータ構造は、質問、生成された回答、関連するドキュメントのリストを1つの状態として保持します。
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]question: ユーザーからの質問(文字列)。generation: LLMが生成した回答(文字列)。documents: 質問や回答に関連する複数のドキュメント(文字列のリスト)。
9.ノードとエッジの定義
ここでは、質問の応答を処理するための一連の関数(ノード)と、それらの処理間の条件分岐(エッジ)を定義します。
### Nodes
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Nodes: 質問応答プロセスのタスクを定義する関数
-
retrieve:質問に基づいて関連するドキュメントを検索します。pythondef retrieve(state): """ Retrieve documents Args: state (dict): The current graph state Returns: state (dict): New key added to state, documents, that contains retrieved documents """ print("---RETRIEVE---") question = state["question"] # Retrieval documents = retriever.invoke(question) return {"documents": documents, "question": question} -
generate: ドキュメントを基に質問に対する回答を生成します。pythondef generate(state): """ Generate answer Args: state (dict): The current graph state Returns: state (dict): New key added to state, generation, that contains LLM generation """ print("---GENERATE---") question = state["question"] documents = state["documents"] # RAG generation generation = rag_chain.invoke({"context": documents, "question": question}) return {"documents": documents, "question": question, "generation": generation} -
grade_documents:取得したドキュメントが質問に関連しているかを評価します。pythondef grade_documents(state): """ Determines whether the retrieved documents are relevant to the question. Args: state (dict): The current graph state Returns: state (dict): Updates documents key with only filtered relevant documents """ print("---CHECK DOCUMENT RELEVANCE TO QUESTION---") question = state["question"] documents = state["documents"] # Score each doc filtered_docs = [] for d in documents: score = retrieval_grader.invoke( {"question": question, "document": d.page_content} ) grade = score.binary_score if grade == "yes": print("---GRADE: DOCUMENT RELEVANT---") filtered_docs.append(d) else: print("---GRADE: DOCUMENT NOT RELEVANT---") continue return {"documents": filtered_docs, "question": question} -
transform_query:質問をより適切な形に書き直します。pythondef transform_query(state): """ Transform the query to produce a better question. Args: state (dict): The current graph state Returns: state (dict): Updates question key with a re-phrased question """ print("---TRANSFORM QUERY---") question = state["question"] documents = state["documents"] # Re-write question better_question = question_rewriter.invoke({"question": question}) return {"documents": documents, "question": better_question}
Edges: ノード間の条件分岐を定義する関数
-
decide_to_generate: ドキュメントが適切か判断し、回答生成または質問の再生成を選択します。pythondef decide_to_generate(state): """ Determines whether to generate an answer, or re-generate a question. Args: state (dict): The current graph state Returns: str: Binary decision for next node to call """ print("---ASSESS GRADED DOCUMENTS---") state["question"] filtered_documents = state["documents"] if not filtered_documents: # All documents have been filtered check_relevance # We will re-generate a new query print( "---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---" ) return "transform_query" else: # We have relevant documents, so generate answer print("---DECISION: GENERATE---") return "generate"2.
grade_generation_v_documents_and_question:生成された回答がドキュメントに基づいているか、質問に答えているかを評価します。pythondef grade_generation_v_documents_and_question(state): """ Determines whether the generation is grounded in the document and answers question. Args: state (dict): The current graph state Returns: str: Decision for next node to call """ print("---CHECK HALLUCINATIONS---") question = state["question"] documents = state["documents"] generation = state["generation"] score = hallucination_grader.invoke( {"documents": documents, "generation": generation} ) grade = score.binary_score # Check hallucination if grade == "yes": print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---") # Check question-answering print("---GRADE GENERATION vs QUESTION---") score = answer_grader.invoke({"question": question, "generation": generation}) grade = score.binary_score if grade == "yes": print("---DECISION: GENERATION ADDRESSES QUESTION---") return "useful" else: print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---") return "not useful" else: pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---") return "not supported"
10.ワークフローをグラフとして構築する
ここでは、質問の応答を表現する一連のノードとエッジを定義し、それらをグラフとして構築します。
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()コード解説
StateGraph を使用して、GraphState 型の状態管理を行うワークフローを初期化します。
workflow = StateGraph(GraphState)workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_queryまず、START から retrieve ノードへの遷移を定義します。
workflow.add_edge(START, "retrieve")retrieve が実行された後、grade_documents に進みます。
workflow.add_edge("retrieve", "grade_documents")grade_documents の後、decide_to_generate を使って次のステップを条件分岐します。
・decide_to_generate:ドキュメントが質問に関連しているかを判定し、次のノードを選択します。
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query", # ドキュメントが不適切な場合、質問を改善します。
"generate": "generate", # 適切なドキュメントがある場合、回答を生成します。
},
)transform_query の後、再び retrieve に戻り、新たなドキュメントを取得します。
workflow.add_edge("transform_query", "retrieve")generate の後、grade_generation_v_documents_and_question を使って次のステップを条件分岐します。
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate", # 回答がドキュメントに基づいていない場合、生成し直します。
"useful": END, # 回答が適切な場合、終了します。
"not useful": "transform_query", # 回答が不適切な場合、質問を改善します。
},
)ワークフローをコンパイルし、実行可能な形式に変換します。
app = workflow.compile()全体の流れ
- START:ワークフローの開始。
- retrieve:ドキュメントを取得。
- grade_documents:ドキュメントの関連性を評価。
- 関連性がない場合:質問を改善(
transform_query)。 - 関連性がある場合:回答を生成(
generate)。
- 関連性がない場合:質問を改善(
- generate:回答を生成。
- 回答が不適切な場合:質問を改善(
transform_query)。 - 回答が適切な場合:終了(
END)。
- 回答が不適切な場合:質問を改善(
- END:ワークフローの終了。
実際に使ってみる
出力の構造
- RETRIEVE
- 質問に関連する文書を検索します。
- CHECK DOCUMENT RELEVANCE TO QUESTION
- 検索結果の各文書が質問に関連するかを評価します。
- 「関連性あり」「関連性なし」の結果が出力されます。
- GENERATE
- 関連性ありの文書に基づいて回答を生成します。
- CHECK HALLUCINATIONS
- 生成された回答が文書に基づいているか確認します。
- GRADE GENERATION vs QUESTION
- 質問に適切に答えているか評価します。
例1
質問を入力して実行
from pprint import pprint
# Run
inputs = {"question": "異なる種類のエージェントメモリがどのように機能するのか説明してください。"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])出力結果
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('異なる種類のエージェントメモリは、短期記憶と長期記憶から構成されます。短期記憶はモデルの学習に使用され、長期記憶は無限の情報を保持し、必要に応じて取り出す能力を提供します。エージェントは外部APIを呼び出して、モデルの重みにない追加情報を取得することも学習します。')
詳細
- 質問:異なる種類のエージェントメモリがどのように機能するのか説明してください。
- 結果:
- 関連性の評価
- 関連性あり:1件
- 関連性なし:3件
- 生成された回答
異なる種類のエージェントメモリは、短期記憶と長期記憶から構成されます。短期記憶はモデルの学習に使用され、長期記憶は無限の情報を保持し、必要に応じて取り出す能力を提供します。エージェントは外部APIを呼び出して、モデルの重みにない追加情報を取得することも学習します。
例2
質問を入力して実行
inputs = {"question": "チェーン・オブ・ソート・プロンプティングがどのように機能するのか説明してください。"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])出力結果
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('チェーン・オブ・ソート・プロンプティングは、Shum et '
'al.によって提案された3段階のプロセスで構成されています。最初に、Augmentでは、質問を使用して複数の疑似的な思考チェーンを生成します。次に、Pruneでは、生成された回答が正しいかどうかに基づいて疑似チェーンを削除します。最後に、Selectでは、選択された例に対する確率分布を学習するために、分散が低減したポリシーグラディエント戦略が適用されます。')
詳細
- 質問:チェーン・オブ・ソート・プロンプティングがどのように機能するのか説明してください。
- 結果
- 関連性の評価
- 関連性あり:1件
- 関連性なし:3件
- 生成された回答
チェーン・オブ・ソート・プロンプティングは、Shum et al.によって提案された3段階のプロセスで構成されています。最初に、Augmentでは、質問を使用して複数の疑似的な思考チェーンを生成します。次に、Pruneでは、生成された回答が正しいかどうかに基づいて疑似チェーンを削除します。最後に、Selectでは、選択された例に対する確率分布を学習するために、分散が低減したポリシーグラディエント戦略が適用されます。
まとめ
この記事では、LangGraphを使用して質問に基づいた応答生成システム「Self-RAG」を構築する方法を解説しました。 チュートリアルを通じて、ユーザーからの質問を元に関連するドキュメントを検索し、その評価や回答生成、そして生成内容の妥当性を確認する流れを学びました。また、ワークフローをグラフとして構築し、動的な状態遷移による柔軟なプロセス管理の実現方法についても説明しました。 ぜひSelf-RAGを活用して、単純な質問応答システムから、より高度で信頼性のある情報検索・生成ツールを開発してみてください。
参考文献
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_self_rag/