はじめに
本記事では、AIコーディングエディタ「Cursor」で、Claudeの長文コンテキスト処理能力を強化する「Claude Context MCP」を導入・活用する方法をご紹介します。 この仕組みを使うと、コードの意味やファイル間のつながりをClaudeが的確に把握できるため、従来よりも無駄のないコード探索や分析が可能になります。さらに、必要な部分だけを取り出して処理するので、トークン使用量(=コスト)の削減にもつながります。 記事の後半では、このMCPを実際に試してみた結果を示しています。
Claude Anthropic社が開発した大規模言語モデル(LLM)。長いテキストや大量のコードを一度に扱うのが得意。
MCP (Model Context Protocol) ChatGPTやClaudeなどの生成AIが外部のツールやデータと連携するための仕組み。
この記事の対象者
- Cursorを日常的に利用しており、そのポテンシャルをさらに引き出したい方
- 大規模なプロジェクトや、初めて触れるコードベースの全体像を効率的に把握したい方
前提
- Cursorをインストール済み
- GitHubアカウントを発行済み
Claude Context MCPとは
「Claude Context」は、プロジェクト全体のコードを検索可能な形で管理し、Claudeに必要な部分だけを効率よく渡す仕組みです。これにより、処理の効率とコストを大幅に改善します。
主なアーキテクチャの構成要素
このシステムは、以下の3つの主要な層で構成されています。
- ユーザーインターフェース(UI) 開発者が直接システムと対話するための入り口です。
- VSCode Extension: 開発者が使い慣れたVS Code (Visual Studio Code)内で直接コード検索ができます。
- Chrome Extension: 現在開発中の拡張機能で、GitHub のリポジトリをブラウザ上でセマンティックコード検索(意味ベースのコード検索)できるようにする予定です。
- MCP Server: Claude Codeを含むAIエージェントと連携するためのサーバです。
- コアシステム システムの中心であり、各プロセスを統括する役割を担います。
- テキスト処理: コードを意味のあるブロックに分解します。
- エンベディングサービス: 分解されたコードを、AIが理解できるベクトル(数値データ)に変換します。
- ベクトルデータベース: 生成されたベクトルを効率的に保存・検索します。
- 外部サービス コアシステムの機能を支える外部のプロバイダやデータベースです。
- エンベディングプロバイダ: 「OpenAI」や「VoyageAI」などの外部APIを利用して、コードをベクトルに変換します。
- ベクトルデータベース: MilvusやZilliz Cloudを利用し、大規模なコードベースでもスケーラブルな検索を実現します。
Milvus Zilliz社(中国発のAI企業)が開発したAIアプリケーションのためのオープンソースのベクトルDB。
Zilliz Cloud Milvusを基盤としたクラウドサービス。
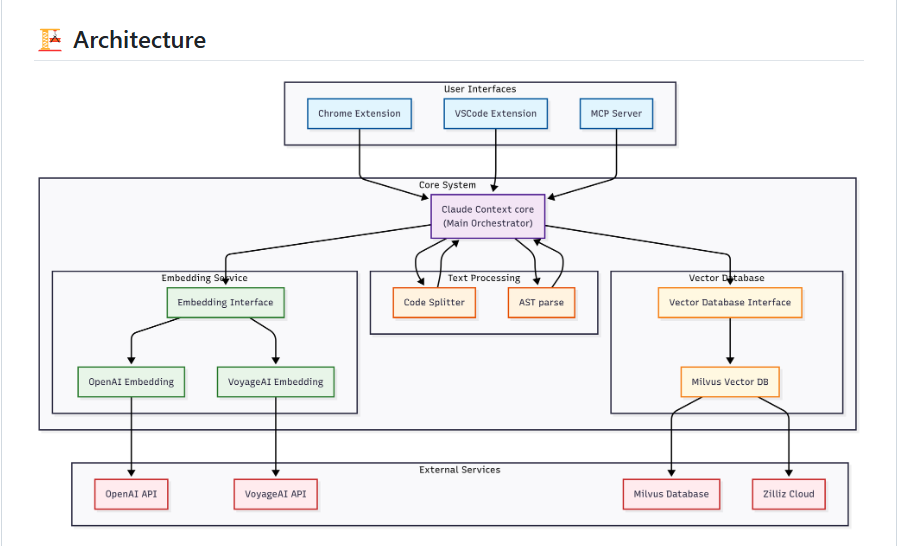 Claude Contextのアーキテクチャ
Claude Contextのアーキテクチャ
このアーキテクチャにより、Claude Contextは、不要なコードを読み込むことなく、必要な情報だけを効率的にエージェントに提供し、コストと時間の両方を節約します。 特に「ベクトル検索」と「BM25(文書の関連度をスコアリング)」を組み合わせたハイブリッド検索によって、エージェントが不要なコードを検索対象に含まなくなり、トークンの使用量の減少やツールの呼び出し回数の削減につながっています。
ベクトル検索 コードの「意味」が似ているものを探す方法。「ユーザ認証に関する処理」といった曖昧な検索でも、関連するコードを見つけ出します。
BM25 従来の検索エンジンのように、キーワード(関数名や変数名など)が一致するものを探す方法。特定の用語に完全一致するコードを探すのに優れています。
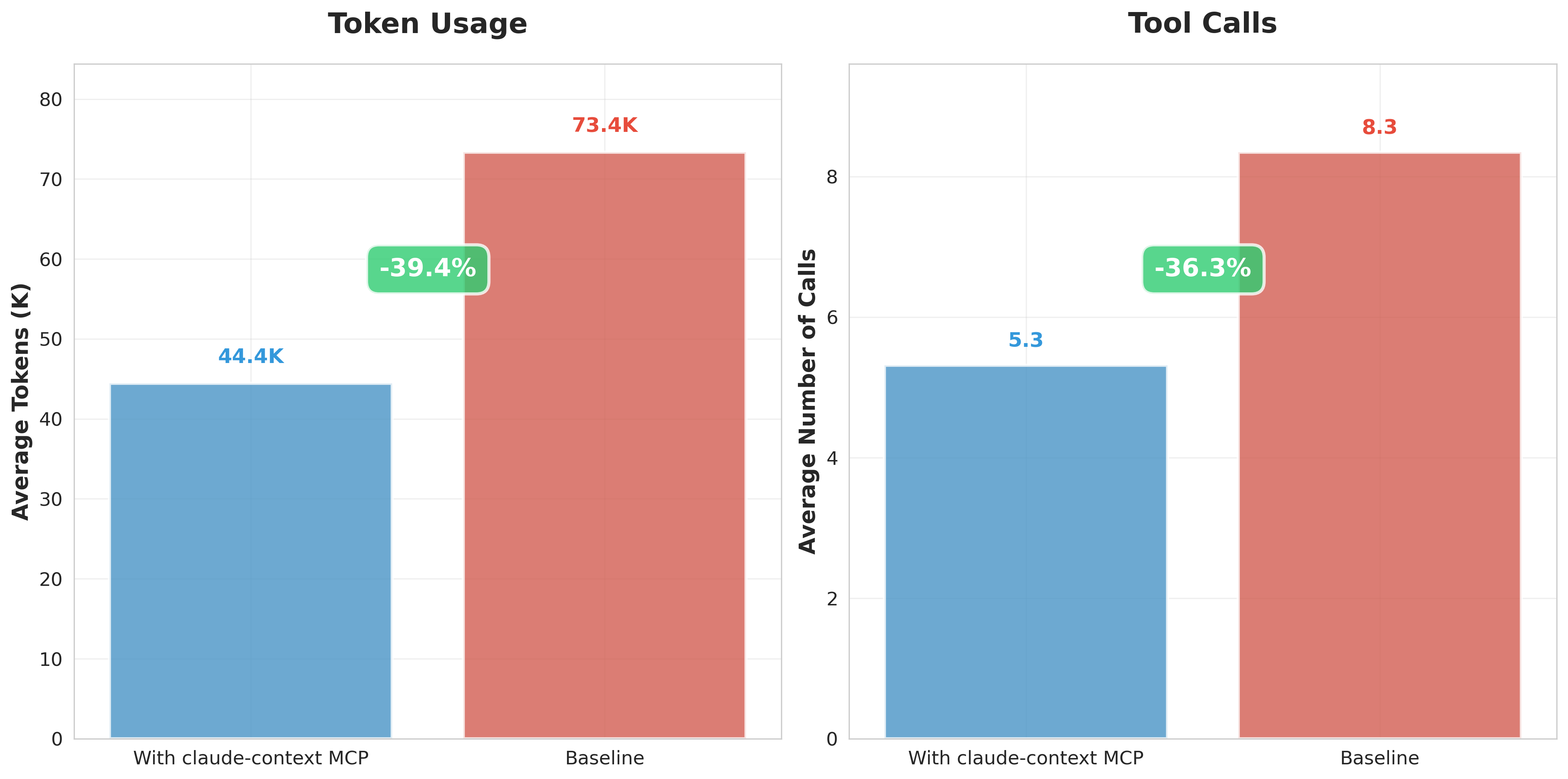 トークン使用量とツール呼び出し回数の比較
トークン使用量とツール呼び出し回数の比較
Claude Context MCPの4つのツール
このMCPには4つのツールが用意されています。主に使われるのは検索を担うsearch_codeです。
index_codebase | コードベースをハイブリッド検索用にインデックス化 |
|---|---|
index_codebase | コードベースをハイブリッド検索用にインデックス化 |
search_code | 自然文クエリで、インデックス済みコードをハイブリッド検索 |
clear_index | 指定したコードベースの検索インデックスを削除 |
get_indexing_status | インデックス化の進捗や完了状況を取得 |
導入手順
ここからはCursorに「Claude Context MCP」を導入する手順を解説します。
手順
- ベクトルDB「Zilliz Cloud」のセットアップ: コードの情報を保存するデータベースを用意します。
- OpenAI APIキーの取得: コードをAIが理解できる形式に変換するために必要なキーを取得します。
- CursorでMCPサーバのセットアップ: Cursorに上記2つの情報を設定し、連携させます。
1. ベクトルDB「Zilliz Cloud」のセットアップ
最初に、コードのベクトルデータを保存するためのデータベースを用意します。今回はZilliz Cloudの無料プランを使用します。
ベクトルDB データを数値ベクトルとして保存・管理するデータベースです。ベクトルとは、方向と大きさを持つ数値の集合であり、データの特徴や関係性を表現します。
-
こちらにアクセスし「無料で始める」をクリックします。
-
サインアップ画面に移ります。今回は「Google認証」を選択します。
-
ワンタイムパスワードの案内メールが送信されます。それを入力してメールアドレスを認証します。
-
アカウント情報の入力画面に移ります。必要事項を記入します。
-
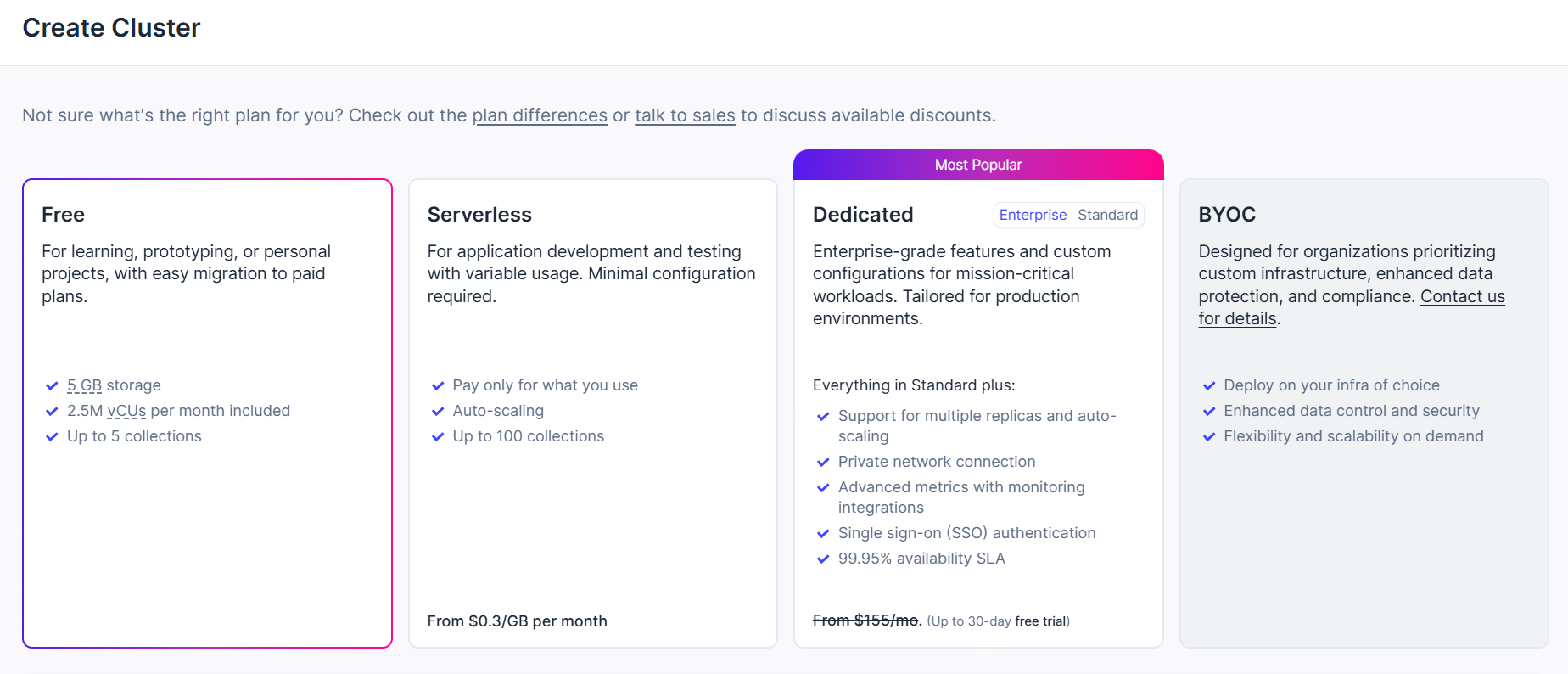
以下のような画面が出てきたら「Create Cluster」を選択します。
-
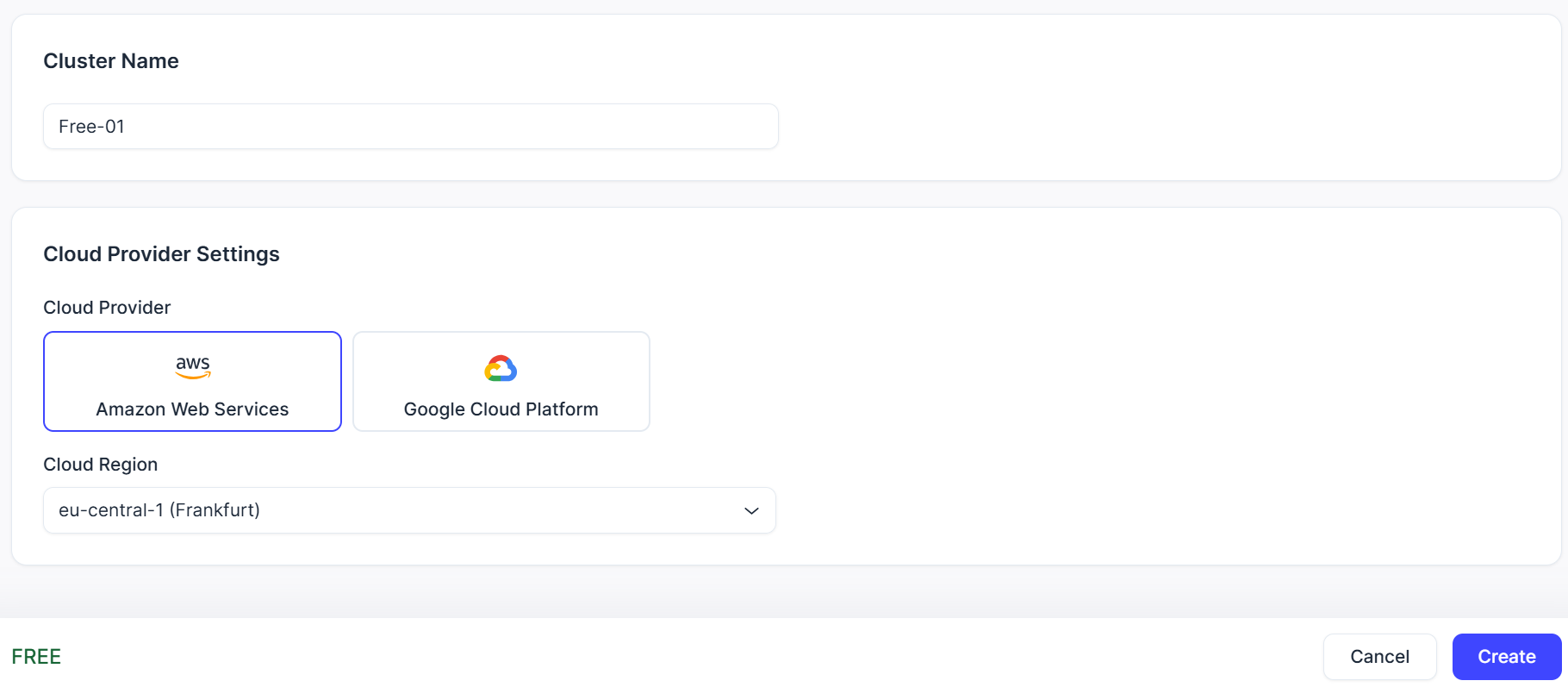
Cluster(クラスター)の設定画面に移ります。今回は「Free」を選択し、その他の設定はデフォルトのままにします。クラスター作成時に一度だけユーザ名とパスワードが表示されるため、控えておきます。
:::message
クラスターは7日間使われていないと自動的に停止してしまうことに注意しましょう。
:::
これでZilliz Cloudのセットアップは完了です。
2. OpenAI APIキーの取得
テキストデータを「Embedding」するためにOpenAI APIキーを取得します。
Embedding(エンベディング) テキストを効率的に検索・比較可能な数値データ(ベクトル)に変換します。 この技術を使って、大量のテキストデータから質問に関連する部分だけを高速に見つけ出すことができます。
-
こちらからOpenAIプラットフォームにアクセスし「Sign up」を選択します。
-
アカウントを作成します。今回は「Google認証」を選択します。
-
OpenAI APIキーを使用するには、事前に支払情報の入力が必要になります。以下のステップで支払情報の選択画面に移ります。
-
画面右上の⚙アイコン(Settings)を選択
-
「Billing」を選択
-
「Payment methods」を選択
-
下の画面で「Add payment method」を選択し、支払情報を追加します。
-
同じ画面から以下のステップでAPIキーを生成します。
-
「API keys」を選択
-
「Create new secret key」を選択
-
「Name」と「Project」を入力
-
「Create secret key」を選択
 続けて次の画面でAPIキーが表示されるため、「Copy」を選択し、控えておきます。
続けて次の画面でAPIキーが表示されるため、「Copy」を選択し、控えておきます。
 これでOpenAI APIキーの取得は完了です。
これでOpenAI APIキーの取得は完了です。
3. CursorでMCPサーバのセットアップ
-
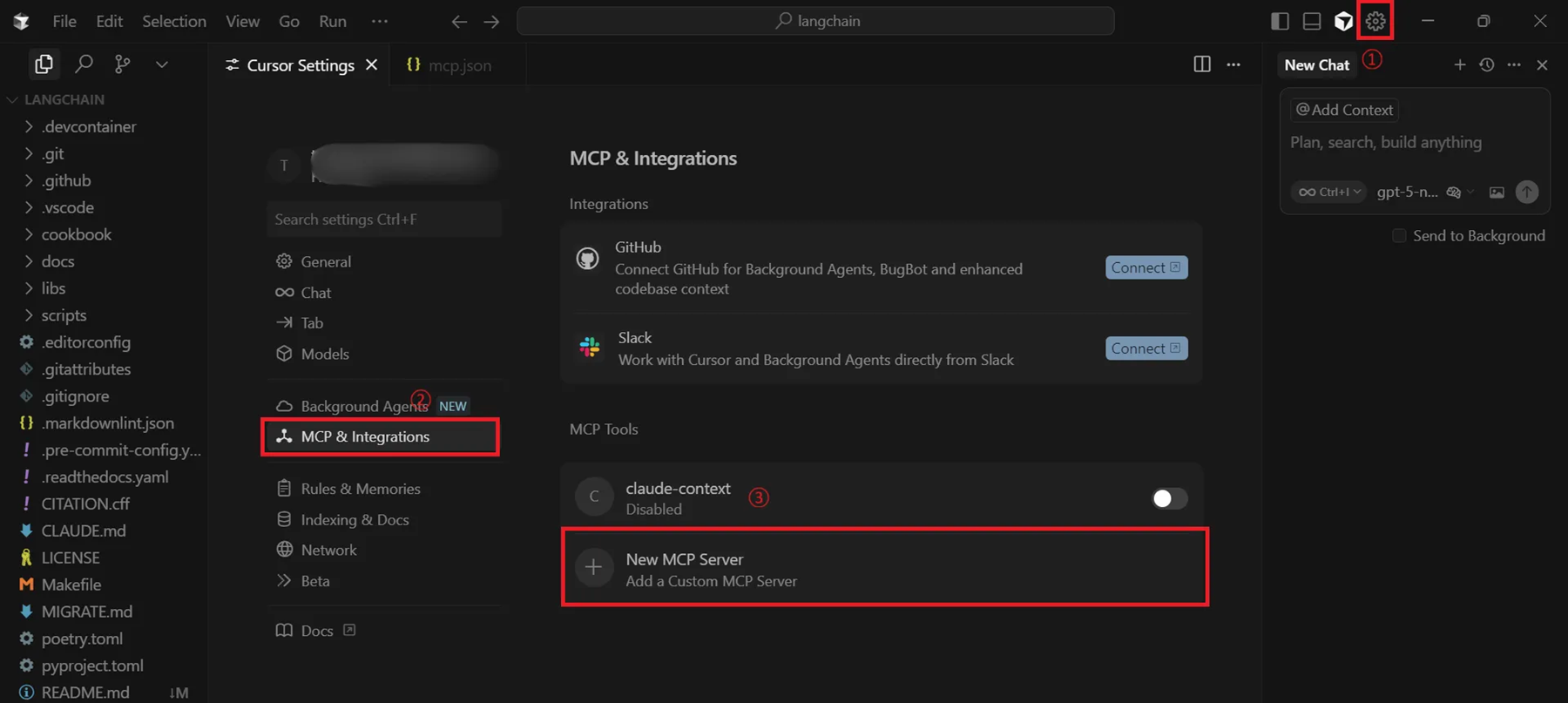
Cursorを起動し、右上の⚙ボタン「Settings」を選択し、「MCP&Integrations」の中にある「New MCP Server」を選択します。
-
「mcp.json」に以下の内容を追加します。
json{ "mcpServers": { "claude-context": { "command": "npx", "args": ["-y", "@zilliz/claude-context-mcp@latest"], "env": { "OPENAI_API_KEY": "your-openai-api-key", "MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint", "MILVUS_TOKEN": "your-zilliz-cloud-api-key" } } }
}
| **項目(キー)** | **入力内容(値)** |
| --- | --- |
| `OPENAI_API_KEY` | 先ほど控えておいたOpenAI APIキー |
| `MILVUS_ADDRESS` | Zilliz Cloudのクラスター画面から取得する「**Public Endpoint**」 |
| `MILVUS_TOKEN` | Zilliz Cloudのクラスター画面から取得する「**Token**」 |
Zilliz Cloudのクラスター画面

以下のように、「**claude-context**」MCPサーバが存在し「**4 tools enabled**」となっていたらセットアップ完了です。

# 実際にClaude Context MCPを試してみる
それでは実際にCursorで「**Claude Context MCP**」を使ってみます。
MCPの有無による性能の比較をしやすくするため、ある程度規模が大きく多数のLLMツールが存在する「**LangChain**」を使用します。
https://github.com/langchain-ai/langchain
:::message
**LangChain**
大規模言語モデル(LLM)を使ったアプリケーションを開発するためのオープンソースフレームワーク。複雑なAIアプリケーションを迅速に構築できるため世界中の開発者に利用されています。
:::
今回は以下のプロンプトをチャット欄に入力します。
:::message
langchain の典型的な RAG パイプライン(Retriever → Reranker(あるなら)→ Prompt/LLM)の呼び出し経路を、Python 実装で追ってください。
:::
プロンプトをMCPありとなしの状態で実行することで、実行時間とトークン数(料金比較)、出力内容について比較していきます。
:::message
今回の操作を実行する際には、Cursorのエージェントがデフォルトの**Agentモード**であることを確かめてください。
エージェントのモードについては下記をご確認ください。
https://docs.cursor.com/ja/agent/modes
:::
## MCPサーバの実行準備(初回のみ)
Claude Context MCP の検索ツールを使うためには、まずリポジトリをインデックス化してベクトルDBを作成する必要があります。以下のプロンプトを実行してインデックスを生成します。
:::message
langchainをインデックス化して
:::
以下のように「**index_codebase**」が呼び出されていれば成功です。インデックス化にかかる時間はリポジトリの規模に依存し、今回のLangChainでは約20分を要しました。進捗は、「進捗確認」や「get_indexing_status」といったプロンプトでいつでも確認できます。

## 実行結果の比較
実際に先ほどのプロンプトを**MCPサーバあり/なし**の場合でそれぞれ試し、以下の観点から比較します。今回はOpenAIの「**gpt-4.1**」モデルを使用します。
- **実行時間・出力内容**
- **プロンプト実行にかかった料金・トークン数**
結論としては、**Cursor標準機能と比較して出力結果は変わらなかったが、トークン数・料金は大きく減少**しました。
### 実行時間・出力内容
実行時間については、**両者に大きな違いは見られませんでした**。これは、Cursorに標準で搭載されている「**Codebase Indexing**」機能が影響していると考えられます。
:::message
**Codebase Indexing**
コードを単なるテキストではなく、構造や関係性で理解し、瞬時に検索・分析できるようにする技術
:::
この機能によって、AIエージェントは迅速にコード探索や構造理解を行うことができるため、MCPサーバの有無にかかわらず実行時間があまり変化していませんでした。また、出力内容に大きな違いは見られませんでした。
### プロンプト実行にかかった料金・トークン数
一方で、プロンプト実行にかかった**トークン数と料金**には明確な差が見られました。以下の比較が示す通り、**MCPを使用した方が、いずれも少ない**結果となりました。
**(上: MCP未使用、下: MCP使用)**

この差が生まれた原因は、**AIエージェントの思考プロセスの違い**にあります。
- **MCPなしの場合**
AIエージェントは、まず「どのようにコードを探索するか」という計画を立て、その計画に沿ってCursorの「Codebase Indexing」機能を使用します。このプロセスはエージェントの思考に大きく依存するため、探索効率が不安定になりやすく、試行錯誤によって余分なトークンを消費する傾向がありました。
- **MCPありの場合**
AIエージェントは、あらかじめインデックス化されたリポジトリ全体の構造情報を活用し、MCPツールを通じて**直接的かつ効率的なコード検索**を行います。思考プロセスがシンプルになるため、無駄なやり取りが減り、トークン消費量を抑えることができました。
# おわりに
今回の検証を通じて、Cursorに「Claude Context MCP」を導入すれば、コード探索の効率を向上させ、特に**トークン消費量(コスト)の削減**に大きな効果があることを確認できました。
実行時間や出力内容に大きな差が見られなかったのは、Cursor自体のインデックス機能が優秀であるためと考えられます。しかし、より大規模で複雑なタスクを依頼する際には、思考プロセスの効率化が実行時間や出力の質にも良い影響を与える可能性は十分に考えられます。
ただし、このMCPを導入するには**外部のベクトルDBを準備しなければならないことに注意が必要**です。むしろ、ベクトルDBの運用やコードのエンベディングにかかるコストがかさむ恐れがあります。Zilliz Cloudの無料プランを使うとしても、大規模もしくは複数のリポジトリを扱う場合には上限に達してしまうことが想定されます。
現時点ではCursor(特にProプラン)に「Claude Context MCP」を導入してもコストが減少するとは断言できません。しかし、タスクの規模や性質に応じてこのMCPを導入することで開発体験やコスト効率を向上できる可能性があります。今後もこのサービスには注目したいです。
# 参考
https://github.com/zilliztech/code-context?tab=readme-ov-file
