
関連記事
- LangGraphとは
はじめに
この記事は、「Slackで社内文書検索 3/4回(Slackからのコマンドとメッセージの受信編)」の続きです。
開発の流れは以下の通りです。
- Slack APIアプリの作成と設定
- Vertex AI Searchのアプリの作成とデータストアの自動更新
- Slackからのコマンドとメッセージの受信
- 任意のLLMによる回答生成
今回は任意のLLMによる回答生成について説明していきます。
Cloud Functionsのファンクションの作成やコードだけが見たい方はこちら
概要
今回は以下の処理のうち、Pub/Subからイベントを受け取って、ユーザに返答するまでの処理の説明をします。

任意のLLMによる回答生成
今回の見出しが任意のLLMとなっているのは、コマンドによってLLMを指定して回答を生成するようにしているからです。コマンドは「Slackで社内文書検索 1/4回(Slack APIアプリの作成と設定編)」の記事で示しましたが、再度示しておきます。
| コマンド | 説明 | 備考 |
| /palm2 | 回答生成に使うLLMモデルを「PaLM2」にする。 | コマンドに続けて質問文を送る。 |
| /gpt-3 | 回答生成に使うLLMモデルを「GPT-3.5」にする。 | コマンドに続けて質問文を送る。 |
| /gpt-4 | 回答生成に使うLLMモデルを「GPT-4」にする。 | コマンドに続けて質問文を送る。 |
回答生成では、Vertex AI Searchのアプリを用いて、メッセージ(質問)に対する関連資料を検索し、任意のLLMモデルを使ってその資料の内容を参考に質問に関連する回答を生成します。
回答生成の処理の概要を以下に示します。

1. イベントを受け取る
Pub/Subからイベントを受け取る部分は、Cloud Functionsでファンクションを作成する際にトリガーとしてPub/Subを指定することで実現にします。
設定方法はこちらで説明しています。
受け取ったイベントからメッセージとコマンドを取り出すには以下のように関数を定義します。
@functions_framework.cloud_event
def send_slack_message(cloud_event):
# Decode the Pub/Sub message data
pubsub_message = base64.b64decode(cloud_event.data["message"]["data"]).decode("utf-8")
pubsub_message_data = json.loads(pubsub_message)
message = pubsub_message_data["data"]["message"]
message = message.strip("<>")
command = pubsub_message_data["data"]["command"]2. 資料を検索する
ここではVertex AI Searchのアプリを使って、質問に関連のある資料を検索します。
今回はLangChainのRetrieversのGoogleVertexAISearchRetrieverを用いてVertex AI Searchの検索機能を実装しました。
GoogleVertexAISearchRetrieverを呼び出す際にたくさん引数を渡しますが、今回はmax_documentsに注目して説明します。その他の引数の説明についてはこちらをご覧ください。
max_documentsは検索結果として表示する資料の数を指定するものになります。今回は1にしていますが、データストアが大規模になるにつれ、関連資料が増えてくると考えられるので、将来的には複数の資料を引用して回答生成することも視野に入れています。
from langchain.retrievers import GoogleVertexAISearchRetriever
retriever = GoogleVertexAISearchRetriever(
project_id=PROJECT_ID,
location_id=LOCATION_ID,
data_store_id=DATA_STORE_ID,
max_documents=1,
engine_data_type=0,
max_extractive_answer_count=1,
get_extractive_answers=False,
query_expansion_condition=2,
)
result = retriever.get_relevant_documents(query)
url = result[0].metadata["source"]
document = result[0].metadata["source"][result[0].metadata["source"].rfind("/") + 1:]上記のresultには参考資料のURLやその資料の要約などが含まれていますが、要約の精度があまり良くなかったので、今回はURLのみを利用します。
また、documentではURLから資料の名前(例:○○.pdf)を取り出しています。
3. 資料をロードする
ここでは、検索してきた資料の内容をロードします。
今回は、LangChainのDocument loadersのGCSFileLoaderを用いて、ファイルをロードします。
関数の中で、資料検索とファイルのロードをしています。
from langchain.document_loaders import PyPDFLoader, GCSFileLoader
def load_pdf(file_path):
return PyPDFLoader(file_path)
def load_text(message):
url, document = search(message)
loader = GCSFileLoader(project_name=PROJECT_ID, bucket=BUCKET_ID, blob=document, loader_func=load_pdf)
text = loader.load()
return text, url4. 回答生成
ここでは、PaLM2とGPT-3.5、GPT-4の3つのLLMで回答を生成します。
今回は、LangChainのChainsを用いて回答を生成します。回答生成の処理は以下のようになります。PaLM2ではStuff、GPT-3.5、GPT-4ではMap Reduceという方法をとります。
回答生成の処理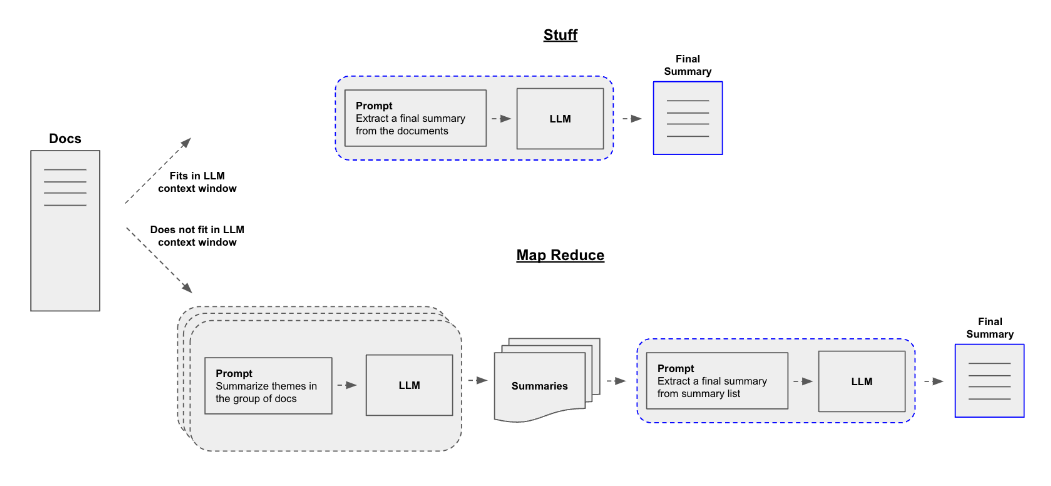

-
PaLM2
PaLM2は試作段階であり、GPT-3.5やGPT-4に比べ、出力の大きさが小さい上に、クオリティも低い。(2023/10/30現在)
そのため、PaLM2はStuffDocumentsChainを用いて、テキストを参考に回答生成する簡単な処理になっています。
StuffDocumentsChainを用いた理由としては、StuffDocumentsChainはドキュメントを複数プロンプトに埋め込めるという特徴を持っているので、将来的に回答生成に利用する資料の容量が増えたときに対応が楽になるからです。
The stuff documents chain ("stuff" as in "to stuff" or "to fill") is the most straightforward of the document chains. It takes a list of documents, inserts them all into a prompt and passes that prompt to an LLM.
This chain is well-suited for applications where documents are small and only a few are passed in for most calls.
以下にコードを示します。
from langchain.chains.llm import LLMChain from langchain.prompts import PromptTemplate from langchain.chat_models import ChatVertexAI from langchain.chains.combine_documents.stuff import StuffDocumentsChain def summarize_palm2(message, docs, url): prompt_template = """\nUse the following text to answer the question. If there is no information relevant to your question, please say "No information".:\n# Question\n""" + message + """\n# text\n{text}""" PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"]) llm = ChatVertexAI(model="chat-bison@001", temperature=0) llm_chain = LLMChain(llm=llm, prompt=PROMPT) stuff_chain = StuffDocumentsChain( llm_chain=llm_chain, document_variable_name="text", ) return stuff_chain.run(docs)今回ChatVertexAIのモデルはchat-bisonを用いましたが、目的に応じてモデルも変更できます。モデルの一覧は以下のサイトをご覧ください。
-
GPT-3.5とGPT-4
GPT-3.5、GPT-4では回答生成に、load_summarize_chainを用います。
load_summarize_chainを用いることで、Map Reduceを簡単に実装できます。
処理の流れを簡単に説明します。まず、参考資料を分割して、それぞれの資料から回答生成に必要そうな情報を抽出します(下のコードのPROMPT)。次に、分割された資料から抽出した情報から回答生成を行います(下のコードのCOMBINE_PROMPT)。
以下にコードを示します。
from langchain.prompts import PromptTemplate from langchain.chains.summarize import load_summarize_chain from langchain.chat_models import ChatOpenAI def summarize_gpt(message, docs, url, model): prompt_template = """ You are a professional editor. Please extract sentences related to the following questions. However, the following constraints must be followed: # Constraints - Do not omit any important keywords. - Extract without compromising the original intent of the text. - Avoid using fictional expressions or terms. - Do not modify any numbers within the text. - Ensure that the extracted sentences contain detailed information. # Question\n""" + message + """\n# Input Text\n{text}""" # ただし、以下のテキストに以下の質問に関連する情報がない場合は「出力フォーマット1」に従い、以下のテキストに以下の質問に関連する情報がある場合は「出力フォーマット2」に従ってください。 combine_prompt = """ あなたはプロの編集者です。以下のテキストを使って、以下の質問に以下の出力のフォーマットに従って「回答」と「参考」を答えてください。: # 質問\n""" + message + """\n# テキスト\n{text}""" + """ ### 出力フォーマット 回答:(質問に対する回答を示す) 参考:(質問に関連する情報がない場合は無し、質問に関連する情報がある場合は右のurlをそのまま出力してください)""" + url PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"]) COMBINE_PROMPT = PromptTemplate(template=combine_prompt, input_variables=["text"]) llm = ChatOpenAI(model=model, temperature=0) chain = load_summarize_chain( llm, chain_type="map_reduce", verbose=True, map_prompt=PROMPT, combine_prompt=COMBINE_PROMPT ) response = chain( { "input_documents": docs, "token_max": 7000, }, return_only_outputs=True, ) return response["output_text"]
回答生成と返信をするファンクション
以上の説明を踏まえてファンクションを作成します。
今回作成するファンクションの作成方法は前々回の記事と変わらないので、こちらを参照してください。ただし、前回の記事と異なる部分があります。その部分は以下に従ってください。
-
トリガー
-
HTTPS
- 未認証の呼び出しを許可を選択
-
トリガーの追加
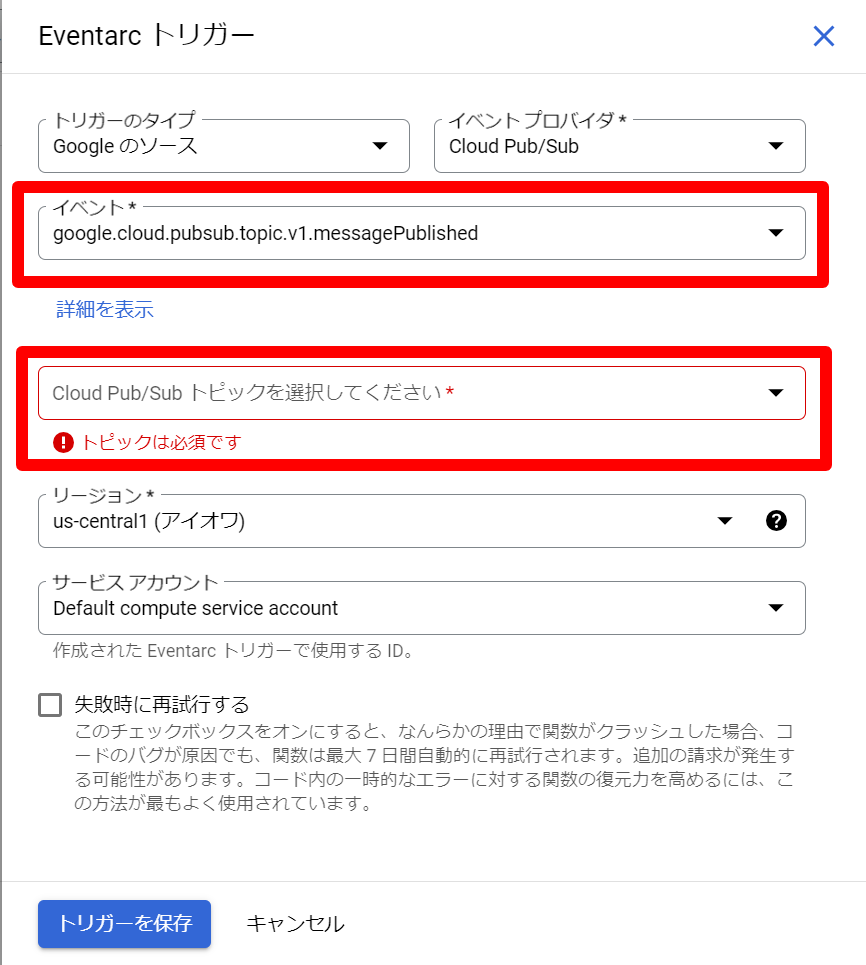
説明
- トリガーを追加を選択します。
- Pub/Subトリガーを選択します。
- イベントで「google.cloud.pubsub.topic.v1.messagePublished」を選択します。
- Cloud Pub/Sub トピックを選択してくださいで前回の記事で作成したトピックを選択します。
- トリガーを保存を選択します。
-
HTTPS
-
ランタイム環境変数
-
以下の4つを追加
名前 値 PROJECT_ID Google Cloud のプロジェクトID BUCKET_ID GCSのバケット名 (gs:// は不要) DATA_STORE_ID Vertex AI SearchのアプリのデータストアのID OPENAI_API_KEY OPENAIのAPIキー SLACK_BOT_TOKEN アプリの認証に用いるトークン SLACK_SIGNNG_SECRET リクエストの認証に用いるサイン WEBHOOK_URL Slackのワークスペースのチャンネルに返信するのに用いる SLACK_BOT_TOKEN
- Slack APIのページに移動
- 作成したアプリを選択
- サイドバーのOAuth & Permissonsを選択
- OAuth Tokens for Your WorkspaceのBot User OAuth Tokenをコピー
SLACK_SIGNNG_SECRET
- Slack APIのページに移動
- 作成したアプリを選択
- サイドバーのBasic Informationを選択
- App CredentialsのSigning SecretのShowを押す
WEBHOOK_URL
- Slack APIのページに移動
- 作成したアプリを選択
- サイドバーのIncoming Webhooksを選択
- Webhook URLs for Your WorkspaceのWebhook URLから今回のSlack APIアプリのインストール先のチャンネルに対応したWebhook URLをコピーします。
-
以下の4つを追加
-
main.py
code
import base64 import json import mimetypes import os import tempfile import functions_framework import urllib3 from langchain.retrievers import GoogleVertexAISearchRetriever from langchain.callbacks import get_openai_callback from langchain.chains.summarize import load_summarize_chain from langchain.chat_models import ChatOpenAI, ChatVertexAI from langchain.document_loaders import PyPDFLoader, GCSFileLoader from langchain.prompts import PromptTemplate from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chains.combine_documents.stuff import StuffDocumentsChain from langchain.chains import LLMChain PROJECT_ID = os.environ.get("PROJECT_ID") DATA_STORE_ID = os.environ.get("DATA_STORE_ID") BUCKET_ID = os.environ.get("BUCKET_ID") http = urllib3.PoolManager() SLACK_BOT_TOKEN = os.environ.get("SLACK_BOT_TOKEN") WEBHOOK_URL = os.environ.get("WEBHOOK_URL") def search(query): retriever = GoogleVertexAISearchRetriever( project_id=PROJECT_ID, location_id=global, data_store_id=DATA_STORE_ID, max_documents=1, engine_data_type=0, max_extractive_answer_count=1, get_extractive_answers=False, query_expansion_condition=2, ) result = retriever.get_relevant_documents(query) if query == "": slack_message = {"text": "質問文を書いてください。"} encoded_msg = json.dumps(slack_message, default=str).encode("utf-8") http.request("POST", WEBHOOK_URL, body=encoded_msg) elif len(result) == 0: slack_message = {"text": "検索でエラーが発生しました。少ししてからやり直してください。"} encoded_msg = json.dumps(slack_message, default=str).encode("utf-8") http.request("POST", WEBHOOK_URL, body=encoded_msg) url = result[0].metadata["source"] document = result[0].metadata["source"][result[0].metadata["source"].rfind("/") + 1:] # print(document) return url, document def load_pdf(file_path): return PyPDFLoader(file_path) def load_text(message): url, document = search(message) loader = GCSFileLoader(project_name=PROJECT_ID, bucket=BUCKET_ID, blob=document, loader_func=load_pdf) text = loader.load() return text, url def summarize_palm2(message, docs, url): prompt_template = """\nUse the following text to answer the question. If there is no information relevant to your question, please say "No information".:\n# Question\n""" + message + """\n# text\n{text}""" PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"]) llm = ChatVertexAI(model="chat-bison@001", temperature=0) llm_chain = LLMChain(llm=llm, prompt=PROMPT) stuff_chain = StuffDocumentsChain( llm_chain=llm_chain, document_variable_name="text", ) return stuff_chain.run(docs) def summarize_gpt(message, docs, url, model): prompt_template = """ You are a professional editor. Please extract sentences related to the following questions. However, the following constraints must be followed: # Constraints - Do not omit any important keywords. - Extract without compromising the original intent of the text. - Avoid using fictional expressions or terms. - Do not modify any numbers within the text. - Ensure that the extracted sentences contain detailed information. # Question\n""" + message + """\n# Input Text\n{text}""" # ただし、以下のテキストに以下の質問に関連する情報がない場合は「出力フォーマット1」に従い、以下のテキストに以下の質問に関連する情報がある場合は「出力フォーマット2」に従ってください。 combine_prompt = """ あなたはプロの編集者です。以下のテキストを使って、以下の質問に以下の出力のフォーマットに従って「回答」と「参考」を答えてください。: # 質問\n""" + message + """\n# テキスト\n{text}""" + """ ### 出力フォーマット 回答:(質問に対する回答を示す) 参考:(質問に関連する情報がない場合は無し、質問に関連する情報がある場合は右のurlをそのまま出力してください)""" + url PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"]) COMBINE_PROMPT = PromptTemplate(template=combine_prompt, input_variables=["text"]) llm = ChatOpenAI(model=model, temperature=0) chain = load_summarize_chain( llm, chain_type="map_reduce", verbose=True, map_prompt=PROMPT, combine_prompt=COMBINE_PROMPT ) response = chain( { "input_documents": docs, "token_max": 7000, }, return_only_outputs=True, ) return response["output_text"] # Triggered from a message on a Cloud Pub/Sub topic. @functions_framework.cloud_event def send_slack_message(cloud_event): # Decode the Pub/Sub message data pubsub_message = base64.b64decode(cloud_event.data["message"]["data"]).decode("utf-8") pubsub_message_data = json.loads(pubsub_message) message = pubsub_message_data["data"]["message"] message = message.strip("<>") command = pubsub_message_data["data"]["command"] doc, url = load_text(message) if command == "/palm2": response = summarize_palm2(message, doc, url) slack_message = {"text": "モデル:PaLM2\n質問:" + message + "\n回答:" + response + "\n参考:" + url} elif command == "/gpt-3": response = summarize_gpt(message, doc, url, model="gpt-3.5-turbo") slack_message = {"text": "モデル:GPT-3.5\n質問:" + message + "\n" + response} elif command == "/gpt-4": response = summarize_gpt(message, doc, url, model="gpt-4") slack_message = {"text": "モデル:GPT-4\n質問:" + message + "\n" + response} else: slack_message = {"text": "コマンドがありません。"} try: encoded_msg = json.dumps(slack_message, default=str).encode("utf-8") http.request("POST", WEBHOOK_URL, body=encoded_msg) return "Message sent to Slack" except Exception as e: print(e) encoded_msg = json.dumps(e, default=str).encode("utf-8") http.request("POST", WEBHOOK_URL, body=encoded_msg) return "Message sent to Slack" -
requirements.txt
code
functions-framework==3.* azure-core==1.26.4 langchain==0.0.312 openai==0.27.7 pypdf==3.13.0 slack-bolt==1.18.0 slack-sdk==3.21.3 requests==2.29.0 urllib3==1.26.15 tiktoken==0.4.0 google-cloud-discoveryengine==0.11.2 google-cloud-storage==2.10.0 google-cloud-aiplatform>=1.33.0 -
エントリポイント
- send_slack_messageに変更
以上でファンクションの作成は終了です!
回答のクオリティについては、PaLM2はVertex AI Searchのアプリのデータストアの中の資料にない内容を質問するとハルシネーションが起きてしまいました。
また、PaLM2は出力の大きさが比較的小さいため、GPT-3.5やGPT-4に比べ、ざっくりとした回答になりました。
GPT-3.5、GPT-4に関しては、申し分ないクオリティの回答を生成する上に、私が行った実験の中ではハルシネーションは起こしませんでした。
最後に
今回は任意のLLMによる回答生成の説明をしました。これで、Slackで社内文書検索システムシリーズは終了になります。今後の展望としては、参考資料を増やして回答生成を行ったり、PaLM2を活用できるプロンプトやパイプラインを探していきたいです。