関連記事
はじめに
LangChainを知らない方、わからないかたは、まず「LangChainとは?」をご覧ください。
LangChainの機能の一つであるChainには様々な機能が提供されています。この記事ではChain機能の一つであるConversationalRetrievalChainについて説明します。
このConversationalRetrievalChainクラスは廃止予定であり、代わりに create_retrieval_chain を使用することが推奨されています。本記事では、 create_retrieval_chain を使用して解説します。
実行環境
- python==3.10.2
- langchain==0.2.11
- langchain-community==0.2.10
- langchain-openai==0.1.17
ConversationalRetrievalChainとは
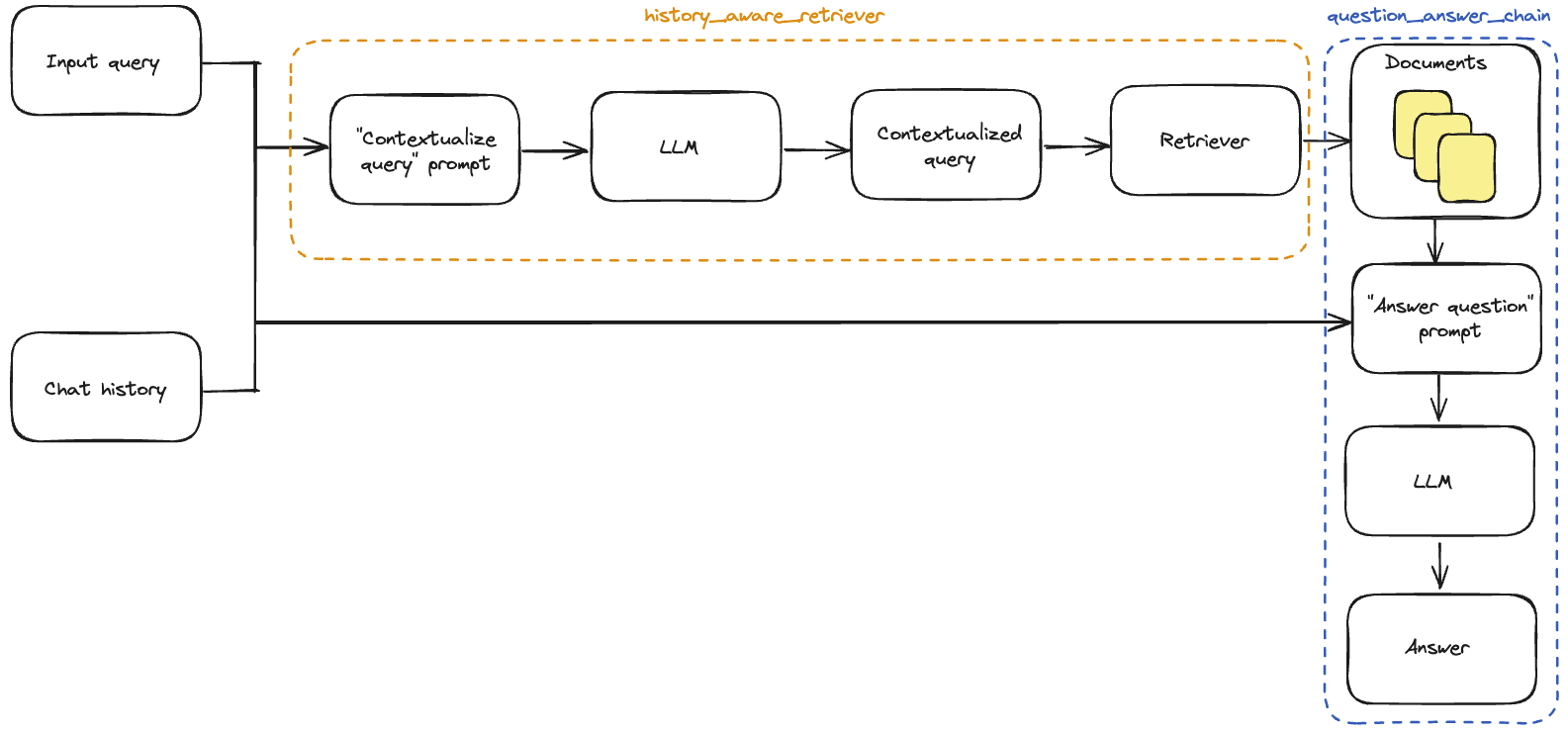
ConversationalRetrievalChainは、会話の履歴を保持しつつ、取得したドキュメントに基づいて会話を行うためのチェーンです。このチェーンはチャット履歴(メッセージのリスト)と新しい質問を受け取り、その質問への答えを返します。アルゴリズムは以下の3つの部分で構成されています。
- 単独の質問の作成:
- チャット履歴と新しい質問を使用して、「単独の質問」を作成します。この質問をリトリーバーに渡して関連するドキュメントを取得します。新しい質問だけを渡すと、関連するコンテキストが不足する可能性があります。一方、全体の会話を渡すと、不要な情報が混ざり込む可能性があります。
- リトリーバーへの質問の送信:
- 新しい質問をリトリーバーに渡し、関連するドキュメントを返します。
- LLMへのドキュメントと質問の送信:
- 取得したドキュメントを、新しい質問(デフォルトの動作)または元の質問とチャット履歴とともにLLMに渡して最終的な応答を生成します。
 https://python.langchain.com/v0.1/docs/use_cases/question_answering/chat_history/
https://python.langchain.com/v0.1/docs/use_cases/question_answering/chat_history/
実際にやってみる
今回はエルカミーの簡単な会社情報のファイル (about_elcamy.txt) を読み込ませ、問い合わせていきます。 about_elcamy.txtの内容は以下の通りです。
エルカミーについて
エルカミーは、データ分析やAI開発を通じてお客様と並走して価値共創する企業です。
ミッション
データの可能性を形にする!
データで、あらゆる問題の本質を知りたい。
データで、意思決定して問題を解決したい。
データで、新しい価値を創造したい。
ビジョン
コラボイノベートカンパニー
ユーザと並走してデータ活用を内製化する。
エルカミーに関わる人々と創発する。
バリュー
スピード アンド クオリティ
期待を超えるプロフェッショナル
学び続ける個人と組織
課題発見と価値創造
自責、謙虚、パッションコード全体
コード全体を載せておきました。概要を知りたい方はご確認ください。
コード例
import os
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
loader = TextLoader("about_elcamy.txt", encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever()
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
contextualize_q_system_prompt = (
"チャット履歴と最新のユーザー質問を考慮して、"
"チャット履歴なしでも理解できる単独の質問を形成してください。"
"質問に答えないでください。必要に応じて再構築し、そのまま返してください。"
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
qa_system_prompt = (
"あなたは質問応答タスクのアシスタントです。取得した以下のコンテキストを使用して質問に答えてください。"
"答えがわからない場合は、わからないと答えてください。"
"\n\n"
"{context}"
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
chat_history = []
question = "エルカミーについて要約してください"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])
print(ai_msg_1["answer"])
print("-----------")
second_question = "英語にしてください"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])
コードの説明
コードの説明に入ります。
ステップ
- 必要なライブラリのインポート
- OpenAI APIキーの設定
- ドキュメントの読み込みとベクトルストアの作成
- LLMの設定
- 質問の文脈化の設定
- ConversationalRetrievalChainの設定
- 回答生成
1. 必要なライブラリのインポート
まずは必要なライブラリをインポートします。
import os
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings2. OpenAI APIキーの設定
次にOpenAIのAPIを設定します。"YOUR_OPENAI_API_KEY”の部分に自分のAPIキーを入力します。
os.environ["OPENAI_API_KEY"]="YOUR_OPENAI_API_KEY"3. ドキュメントの読み込みとベクトルストアの作成
about_elcamy.txtの内容をを読み込み、それをベクトルストアに保存します。 以下が具体的なコードです。
-
テキストファイルの読み込み
pythonloader = TextLoader("about_elcamy.txt", encoding="utf-8") documents = loader.load() -
テキストの分割 大きなテキストをチャンクに分割します。ここでは、チャンクサイズを1000文字、オーバーラップを0に設定しています。
pythontext_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) documents = text_splitter.split_documents(documents) -
ベクトルストアの作成 テキストのチャンクをベクトル化し、Chromaベクトルストアに保存します。
pythonembeddings = OpenAIEmbeddings() vectorstore = Chroma.from_documents(documents, embeddings) -
リトリーバーの作成 ベクトルストアからリトリーバーを作成します。
pythonretriever = vectorstore.as_retriever()
4. LLMの設定
OpenAIのChatモデルを使用して、LLMを設定します。
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)5. 質問の文脈化の設定
ユーザーの最新の質問をチャット履歴を考慮して単独の質問に再構築するプロンプトを設定します。
-
システムプロンプトの設定:
pythoncontextualize_q_system_prompt = ( "チャット履歴と最新のユーザー質問を考慮して、" "チャット履歴なしでも理解できる単独の質問を形成してください。" "質問に答えないでください。必要に応じて再構築し、そのまま返してください。" ) -
プロンプトテンプレートの作成:
pythoncontextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) -
履歴を考慮したリトリーバーの作成:
pythonhistory_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt )
6. ConversationalRetrievalChainの設定
リトリーバーから取得したコンテキストを使用して質問に答えるプロンプトを設定します。そして、ConversationalRetrievalChainをcreate_retrieval_chain を使用して作成していきます。
-
システムプロンプトの設定
pythonqa_system_prompt = ( "あなたは質問応答タスクのアシスタントです。取得した以下のコンテキストを使用して質問に答えてください。" "答えがわからない場合は、わからないと答えてください。" "\n\n" "{context}" ) -
プロンプトテンプレートの作成
pythonqa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) -
質問応答チェーンの作成
pythonquestion_answer_chain = create_stuff_documents_chain(llm, qa_prompt) -
ConversationalRetrievalChainを
create_retrieval_chainを使用して作成pythonrag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain) -
初期チャット履歴の設定:
pythonchat_history = []
7. 回答生成
このコードは、チャット履歴を考慮した質問応答システムの基本的な実装例です。各ステップを順番に実行することで、ユーザーの質問に対して適切に文脈を考慮した回答を生成することができます。 では、実際に質問してみましょう。
question = "エルカミーについて要約してください"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg_1["answer"]])
print(ai_msg_1["answer"])query = "エルカミーについて要約してください"
result = qa({"question": query})
print(result["answer"])会話の内容が保持できているか確認していきます。
second_question = "英語にしてください"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])Elchemy is a company that collaborates with customers through data analysis and AI development to co-create value. Its mission is to shape the potential of data, understand the essence of problems, make decisions, and create new value using data. The vision is to be a collaborative innovation company that internalizes data utilization with users and emerges with them. The values include speed and quality, exceeding expectations as professionals, continuous learning for individuals and organizations, discovering challenges and creating value, self-responsibility, humility, and passion.
前文の要約文を保持できており、その内容を英訳してくれました!
まとめ
今回は、ConversationalRetrievalChainについて紹介していきました! 前文の内容を元に答えてほしい場合や、連続で同じ内容について質問する際は、会話の履歴を保持しておく必要があります。ConversationalRetrievalChainを使って、会話の内容を保持することができるので、ぜひ使ってみてください。
参考
https://python.langchain.com/v0.1/docs/use_cases/question_answering/chat_history/
