はじめに
Visual Blocks for MLは、Googleから提供されており、ノーコードで機械学習パイプラインを作成することができます。 今回はVisual Blocksについてまとめ、実際に使ってみたいと思います。
Visual Blocks for MLとは
Visual Blocksは、機械学習ベースのプロトタイプをノーコードで、簡単に開発することができるプラットフォームです。以下の画像はプロトタイプを開発するエディタ部分です。
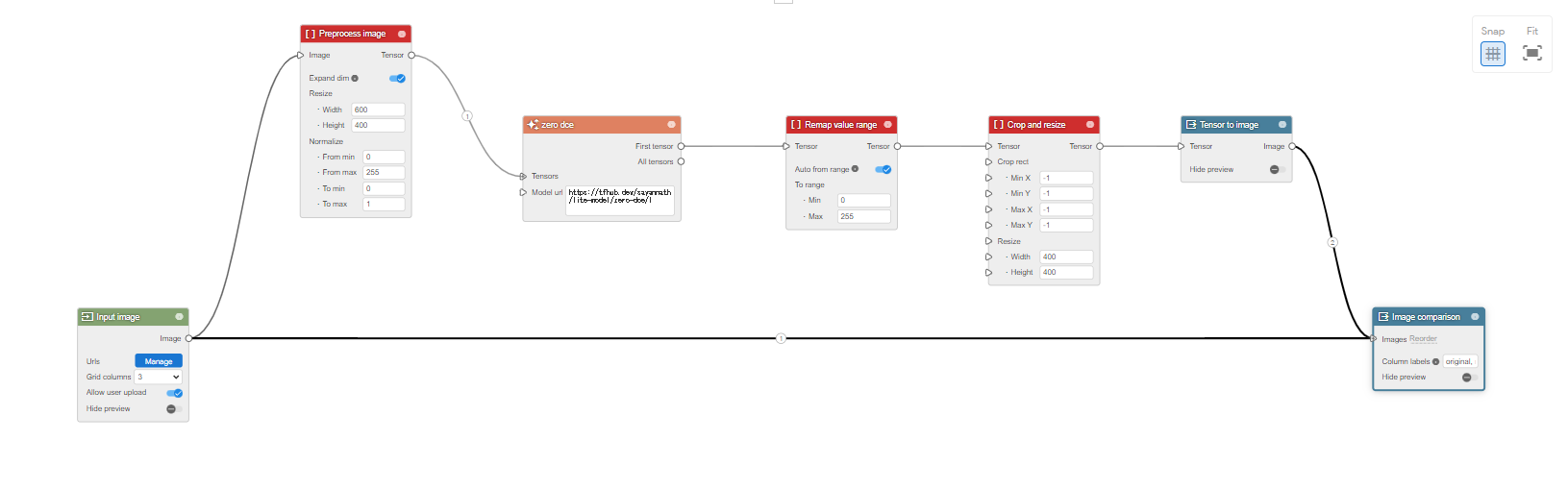
このエディタを通して、ノード同士を繋ぐだけで、簡単にMLパイプラインを構築することができます。また、どのような操作を行っているか可視化することができます。例えば、暗い画像を明るい画像に変更するシステムを組んだ場合を考えます。以下のように、画像を可視化し、変更の前後で比較することができます。
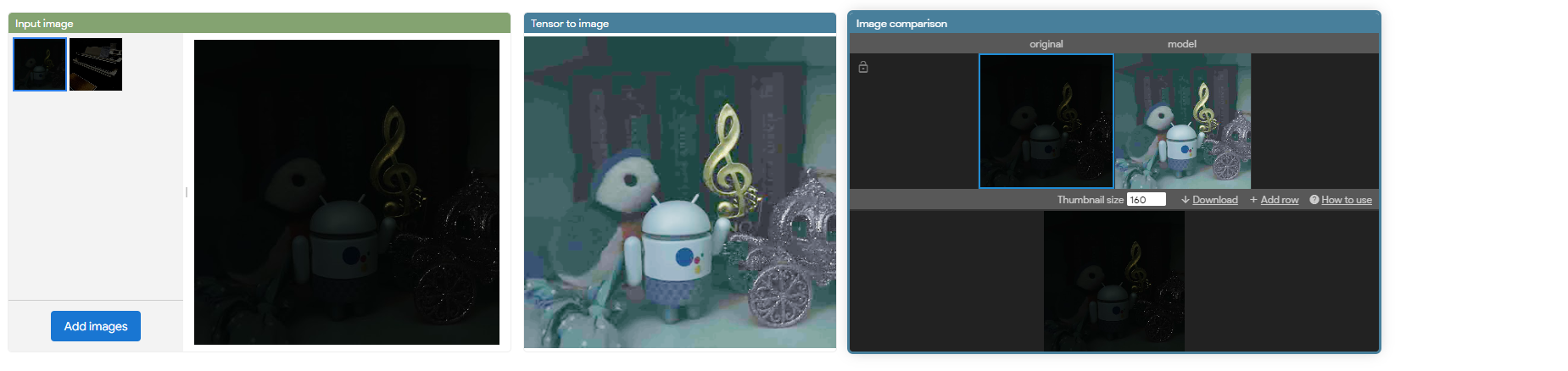
MLベースのプロントタイプを開発することは簡単ではありません。しかし、Visual Blocksを使うことで、コーディングや技術的な側面を気にすることなく、開発することができます。 開発したシステムはjsonファイルとして保存することができたり、他の人が開発したシステムがjsonファイルとして保存されていれば、読み込むこともできます。
ノードの種類
Visual Blocksで提供されているノードは以下の6種類になります。
- Input
- Effect
- Model
- Output
- Tensor
- Miscellaneous これらのノードを繋ぐことで、MLベースのプロトタイプを開発することができます。
Input nodes
Input nodesでは、入力に使用するデータの種類を選ぶことができます。提供されているデータの種類は画像、テキスト、ライブカメラです。

Effect nodes
Effect nodesでは、入力に対して、データ拡張やシェーダーを適用することができます。例えば、以下のように、画像を回転させることや、ノイズを加えることができます。
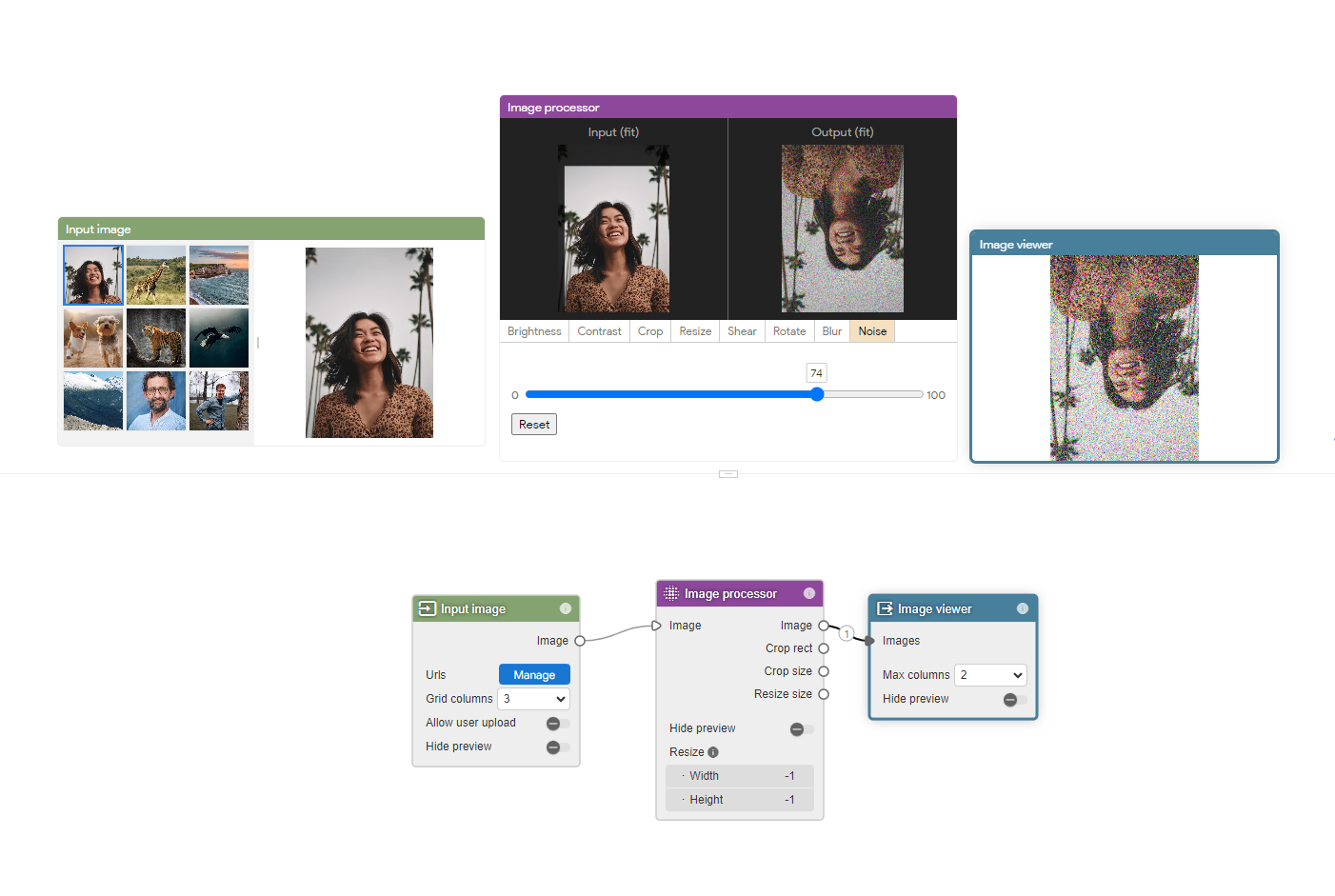 他にも、画像をミックスすることや、リサイズ、クロッピングなど様々な処理をすることができます。
他にも、画像をミックスすることや、リサイズ、クロッピングなど様々な処理をすることができます。
Model nodes
Model nodesでは、最先端の事前学習済みモデルを使用することができ、画像やテキストでの幅広いタスクをカバーしています。body segmentation、face detection、有害なテキストの検知などのタスクを実行することができます。また、Tensorflow.jsやTensorflow Liteからモデルを読み込むことも可能です。
Output nodes
Output nodesでは、モデルからのアウトプットを視覚化することができます。任意のノードに接続し、出力を確認することができるため、中間結果のデバックが簡単にできます。
Tensor nodes
Tensor nodesでは、テンソルから画像へ変換することや、生のテンソル出力に正規化を適用することなど、様々な機能が提供されています。
Miscellaneous nodes
Miscellaneous nodesでは、Webページを埋め込むことや、入力画像のサイズを取得することなど様々な機能が提供されています。
実際に使ってみた
実践する内容
今回は、以下のことを実践していきたいと思います。
- 人の画像から、人の身体領域だけを抽出する
- 顔を検知する
- 背景を変更する
実践
以下のようにノードを接続し、上記の内容を実践してみました。
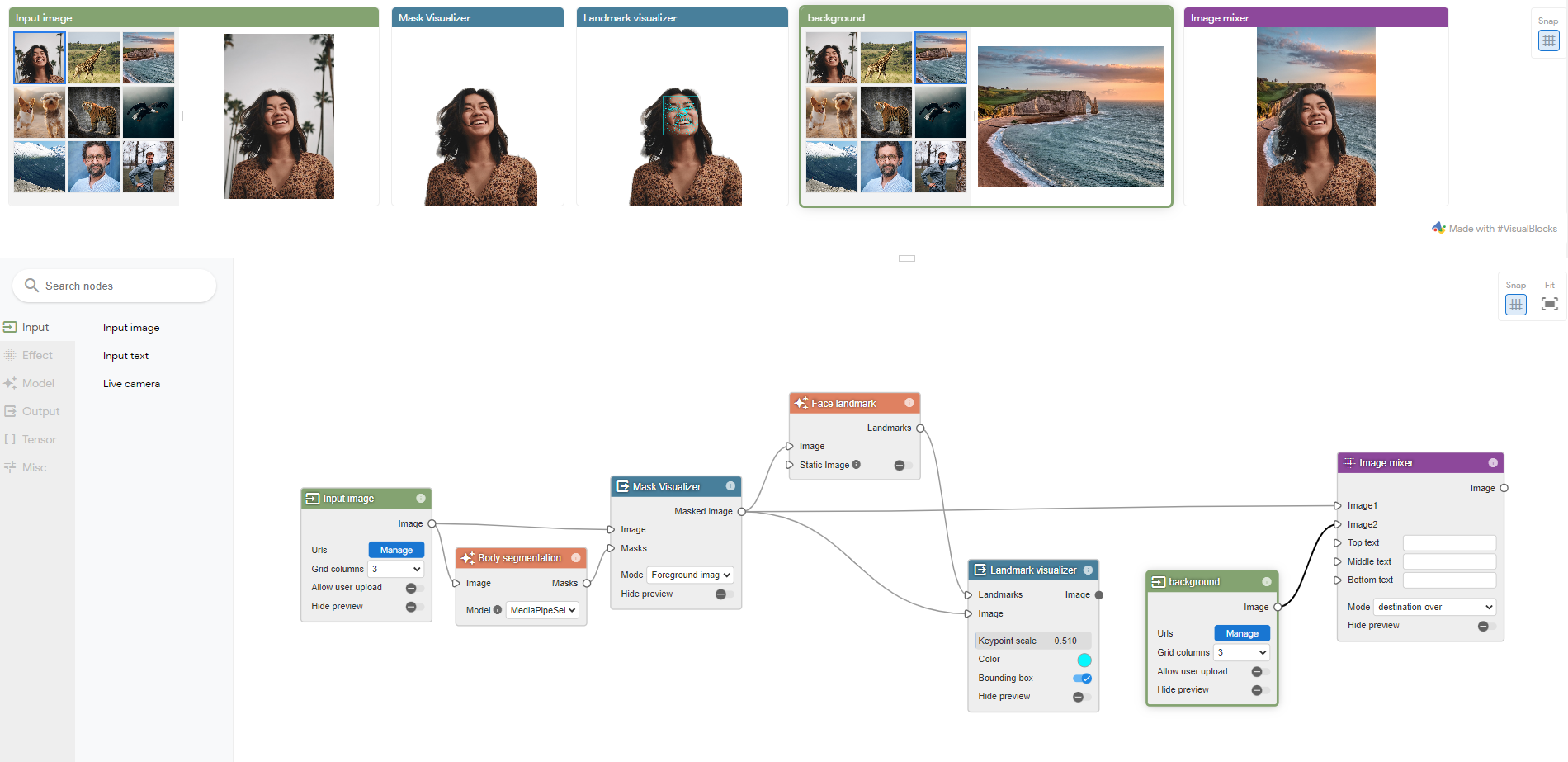
人の身体領域だけを抽出する
この機能を実現するために、以下のノードを使用します。
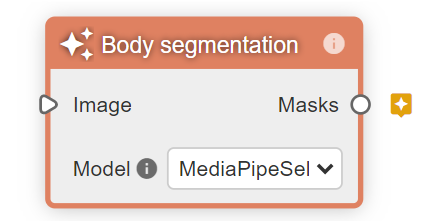
- Model nodesのbody segmentation
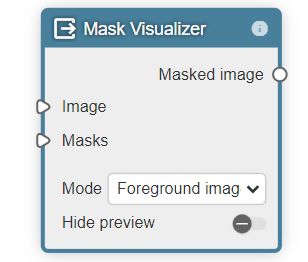
- Output nodesのMask Visualizer
 body segmentationでは、人の身体領域以外をマスクすることによって、人の身体領域を抽出します。body segmentationに画像を通すと、マスクが得られます。
得られたマスクと画像をMask Visualizerに入力することで、人の身体領域だけを抽出した画像を可視化することができます。
body segmentationでは、人の身体領域以外をマスクすることによって、人の身体領域を抽出します。body segmentationに画像を通すと、マスクが得られます。
得られたマスクと画像をMask Visualizerに入力することで、人の身体領域だけを抽出した画像を可視化することができます。


顔を検知する
この機能を実現するために、以下のノードを使用します。
- model nodesのFace landmark
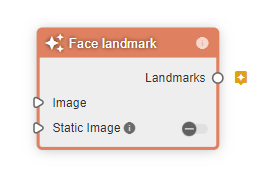
- Output nodesのLandmark visualizer
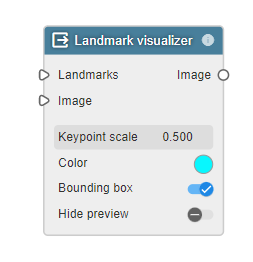 Face landmarkでは、入力画像から顔を検知することができます。目、鼻、口などの位置を特定し、顔のランドマークが得られます。
得られたランドマークと画像を入力することで、顔を検知した画像を可視化できます。
Face landmarkでは、入力画像から顔を検知することができます。目、鼻、口などの位置を特定し、顔のランドマークが得られます。
得られたランドマークと画像を入力することで、顔を検知した画像を可視化できます。


背景を変更する
この機能を実現するために、以下のノードを使用します。
- Effect nodesのImage mixer
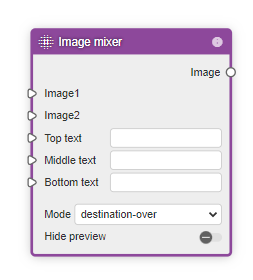 Image mixerでは、二つの入力画像をModeに従ってミックスすることができます。人の身体領域だけを抽出した画像はもうすでに得られているので、その画像に背景の画像をミックスすれば、背景を変えることができます。
注意する点は、image1に抽出した画像、image2に背景の画像、Modeはdestination-overを選ぶことです。
Image mixerでは、二つの入力画像をModeに従ってミックスすることができます。人の身体領域だけを抽出した画像はもうすでに得られているので、その画像に背景の画像をミックスすれば、背景を変えることができます。
注意する点は、image1に抽出した画像、image2に背景の画像、Modeはdestination-overを選ぶことです。


まとめ
今回はGoogleから提供されているVisual Blocks for MLについて説明しました。説明しきれていない機能がほかにもたくさんあるので触ってみてください。また、nodeを自作することもできるので、より複雑システムも開発できると思います。
参考
https://visualblocks.withgoogle.com/#/
https://ai.googleblog.com/2023/04/visual-blocks-for-ml-accelerating.html
