
はじめに
LlamaIndexは簡単な実装で、インデックスを作成し、OpenAIのモデルを使って問い合わせることができます。そこで、今回は、Webページの内容をLlamaIndexを使って読み込ませ、ChatGPTを使って問い合わせられるようにしました。
読み込んでいくWebページはLlamaIndexライブラリに関するWebページです。ライブラリに関するWebページは英語で、多くの項目に分かれているので、見づらいことがあったり、理解しずらいので、こちらを使って試していきます。
また、Webページの内容をLlamaIndexで読み込む内容は存在するのですが、最新のLlamaIndexに対応していないものがほとんどだったので、最新バージョンに対応させたものを作成していきます。
実際にやってみる
今回の流れは以下のようになります。
- WebページのURLを用意する
- LlamaIndexを使ってWebページの内容を読み込み、インデックスを作成する
- LlamaIndexを使って、インデックスに問い合わせる
WebページのURLを用意する
Webページを用意する流れを紹介します。
- Webページに存在するURLを全て取得する
- 取得したURLをアクセスできる形に変える
- URLを取得出来たら、ファイルとして保存する
①Webページに存在するURLを全て取得する
今回LlamaIndexに読み込ませるWebページはLlamaIndexのドキュメントページです。

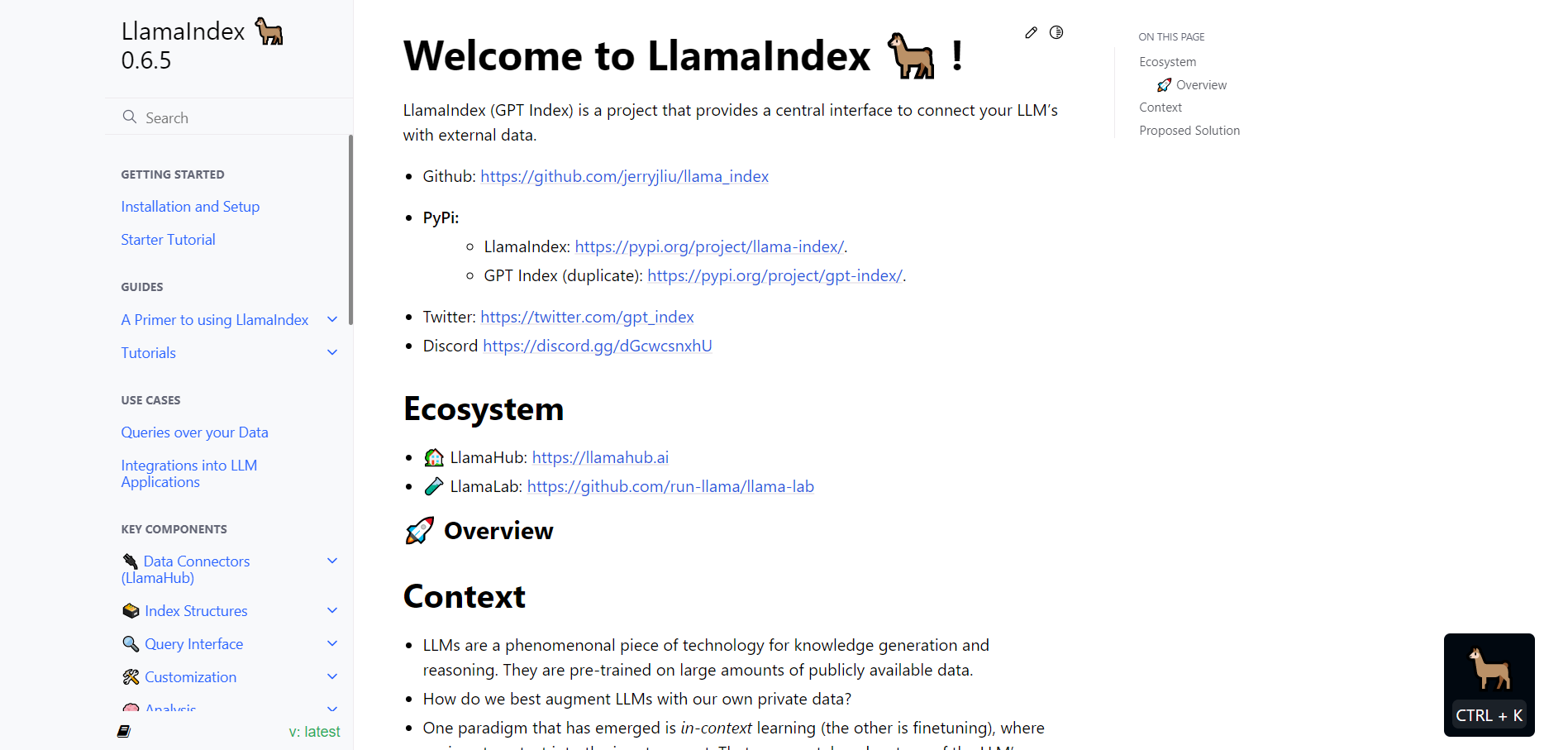
実際に見てみると、多くの項目に分かれていて、それぞれのURLを取ってくるのは大変です。そこで、以下のサイトを使いました。

このサイトにLlamaIndexのURLを入力すると、そのWebページに存在するすべてのURLを取ってくることができます!
実際にやってみると下の画像のようになります。

②取得したURLをアクセスできる形に変える
画像を見てみると、取得したURLは相対パスになってしまっいるので、Excelを使って、アクセス可能なURLに直していきます。まずはコピー&ペーストします。
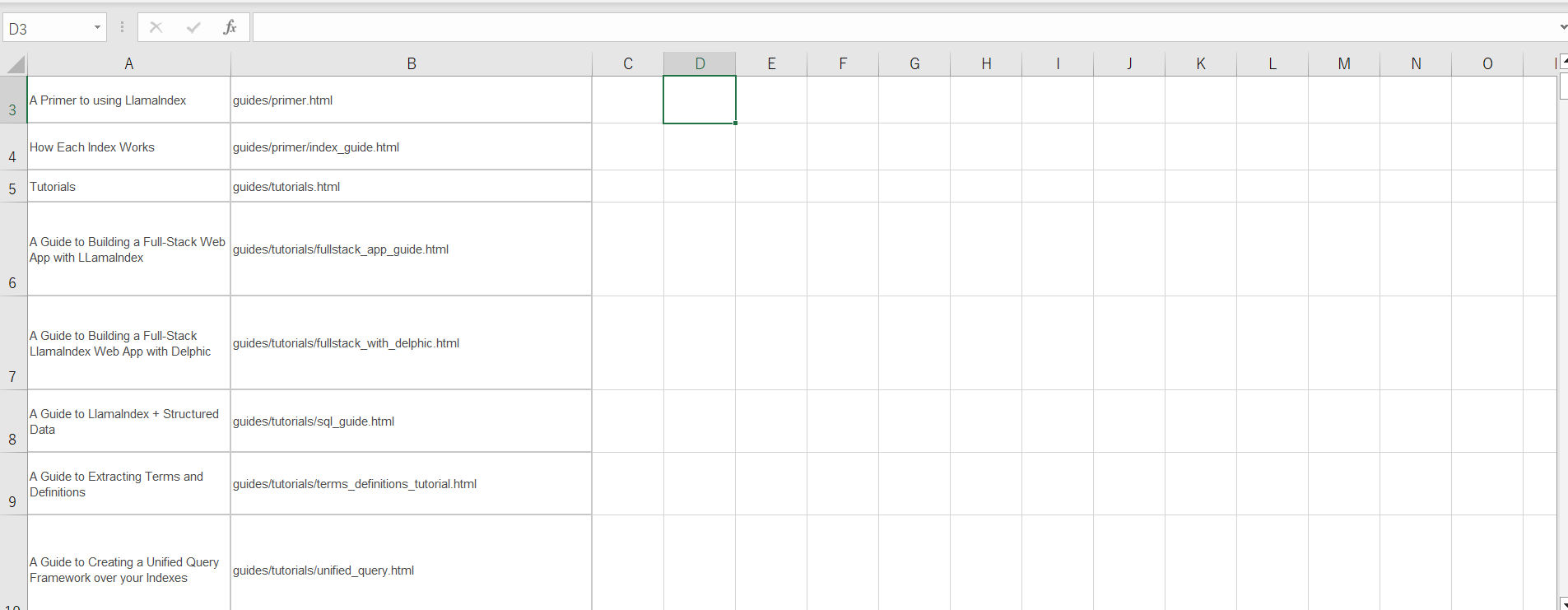
次にURLの部分をドメイン + 相対パスのようにしていきます。
= "https://gpt-index.readthedocs.io/en/latest/" & B1上記の数式を入力して、簡単に作ることができます。
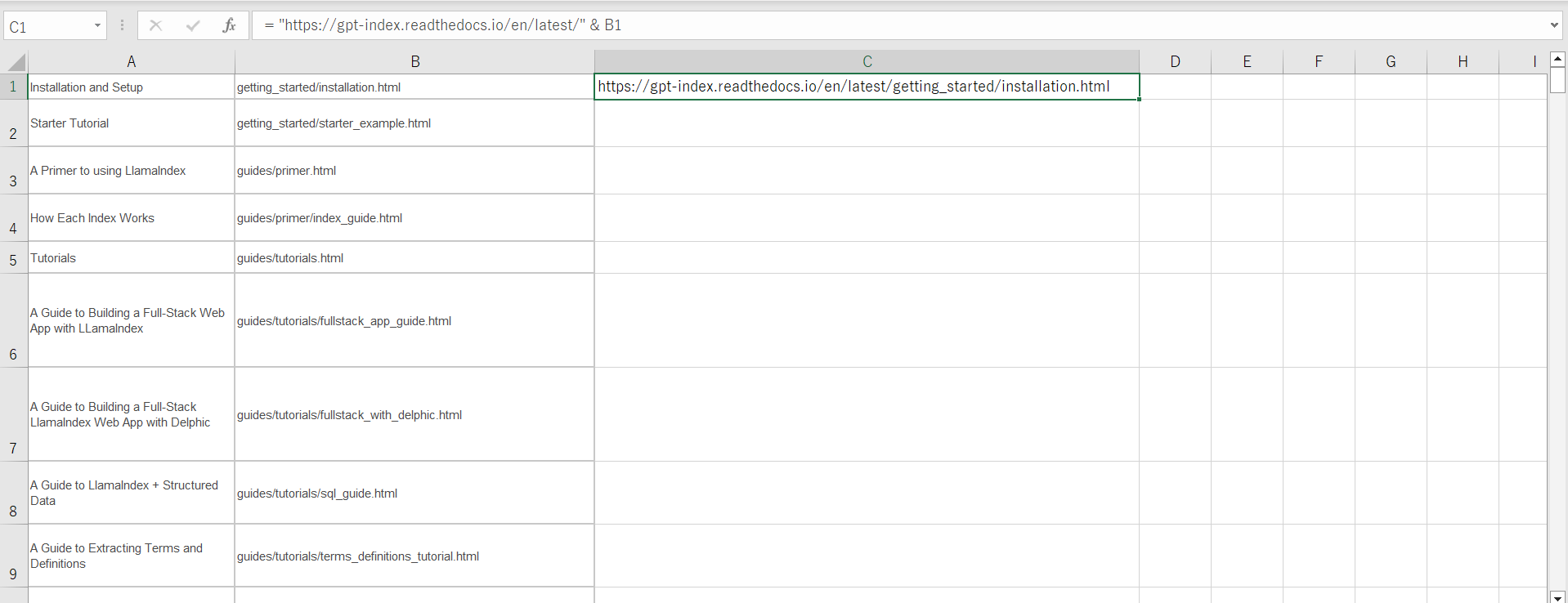
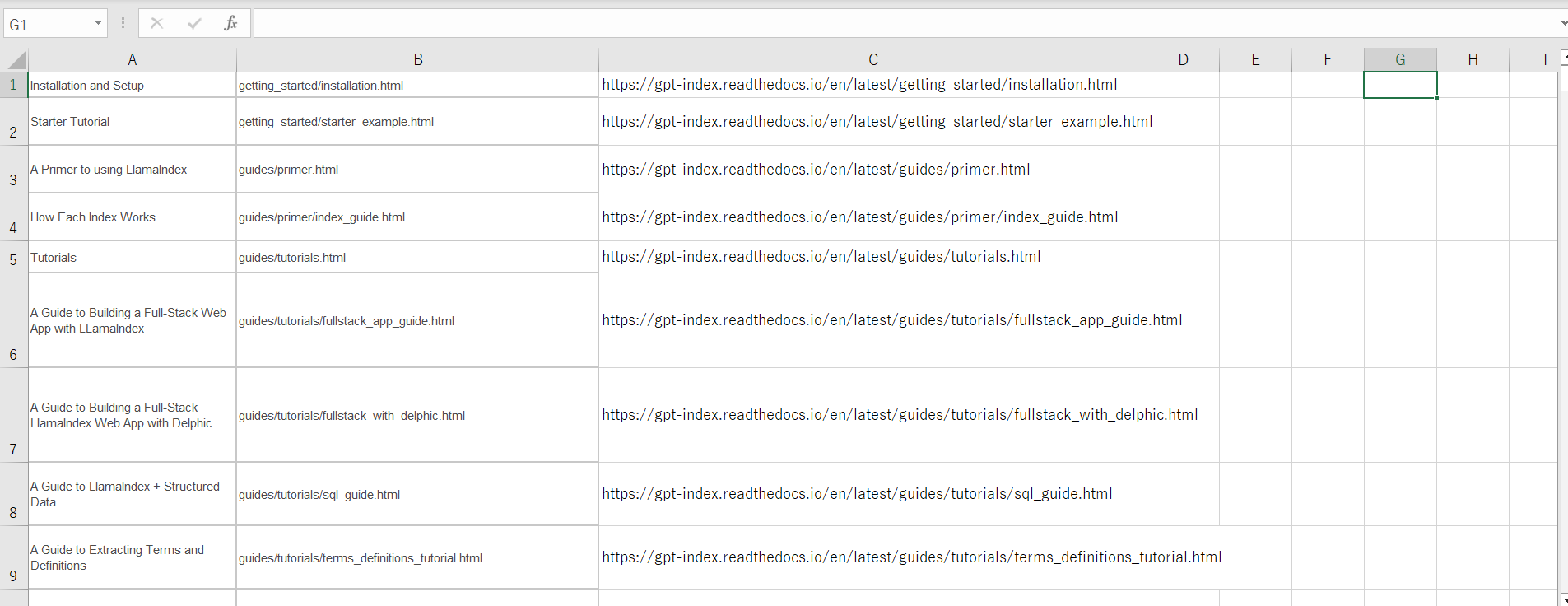
これで完成です。もとからアクセスできる形でURLが載っている場合もあるので、その部分は注意が必要です!
今回はURLの部分だけを取ってきて、textファイル(llamaindex_url.txt)として保存しました。
LlamaIndexを使ってWebページの内容を読み込み、インデックスを作成する
インデックスを作成するコードは以下のようになります。
import csv
import os
from llama_index import SimpleWebPageReader, LLMPredictor, GPTVectorStoreIndex, ServiceContext
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"]="OPENAI_API_KEY"
urls = []
with open('llamaindex_url.txt') as f:
reader = csv.reader(f)
for row in reader:
urls.append(row[0])
documents = SimpleWebPageReader(html_to_text=True).load_data(urls)
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
index.set_index_id("vector_index")
index.storage_context.persist('storage')LlamaIndexを使って、インデックスに問い合わせる
インデックスに問い合わせ、回答を生成するコードは以下のようになります。
import sys
import os
from llama_index import LLMPredictor, load_index_from_storage, StorageContext, PromptHelper, ServiceContext
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
os.environ["OPENAI_API_KEY"]="OPENAI_API_KEY"
template = """
与えられた質問に対して日本語で回答してください。
また、以下のフォーマットで答えてください。
```
質問: {question}
解答:
```
"""
prompt = PromptTemplate(
input_variables=["question"],
template = template,
)
max_input_size = 4096
num_output = 2048
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=2048))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
storage_context = StorageContext.from_defaults(persist_dir='storage')
index = load_index_from_storage(storage_context, index_id="vector_index")
query_engine = index.as_query_engine(service_context=service_context)
args = sys.argv
question = args[1]
output = query_engine.query(prompt.format(question=question))
print(output)実際に回答を生成する
うまく解答を生成できた例
$ python query.py "SimpleWebPageReaderのパラメータを教えてください"
質問: SimpleWebPageReaderのパラメータを教えてください
解答: html_to_text=Trueというパラメータがあります。これは、WebページのHTMLをテキス
トに変換するためにhtml2textがインストールされている必要があることを意味します。実際にLlamaIndexのWebページで確認してみると
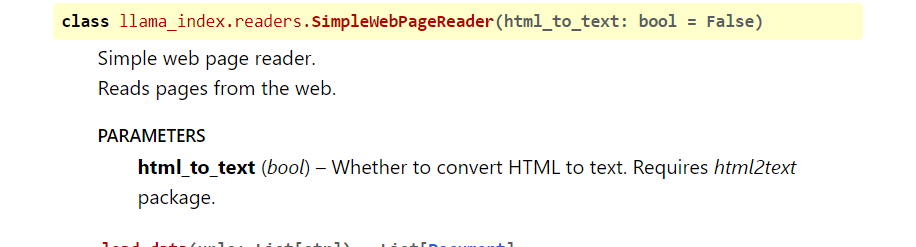
あっていました!
$ python query.py "BeautifulSoupWebReaderでは何ができますか?"
質問: BeautifulSoupWebReaderでは何ができますか?
解答: コンテンツを含むWebページを読み込み、BeautifulSoupを使用してHTMLからテキストを抽出することができます。実際にLlamaIndexのWebページで確認してみると
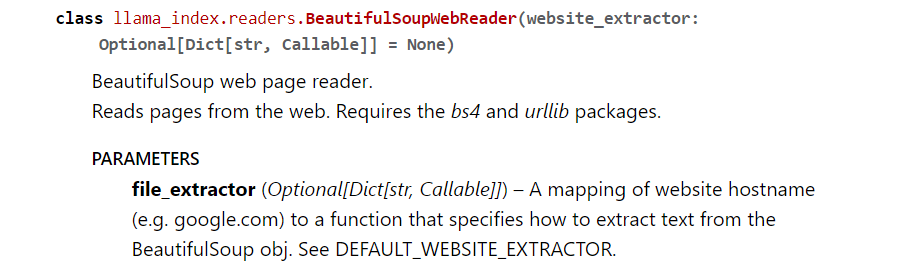
大体同じようなことが書いていました。
$ python query.py "LlamaIndexを使って、ドキュメントを読み込み、GPTVectorStoreIndex
を作成するコードを教えてください"
質問: LlamaIndexを使って、ドキュメントを読み込み、GPTVectorStoreIndexを作成するコー
ドを教えてください
解答:
```
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
```
ただし、ログを表示するためのコードが追加されました。下記の内容を見ると、正しく生成できています。
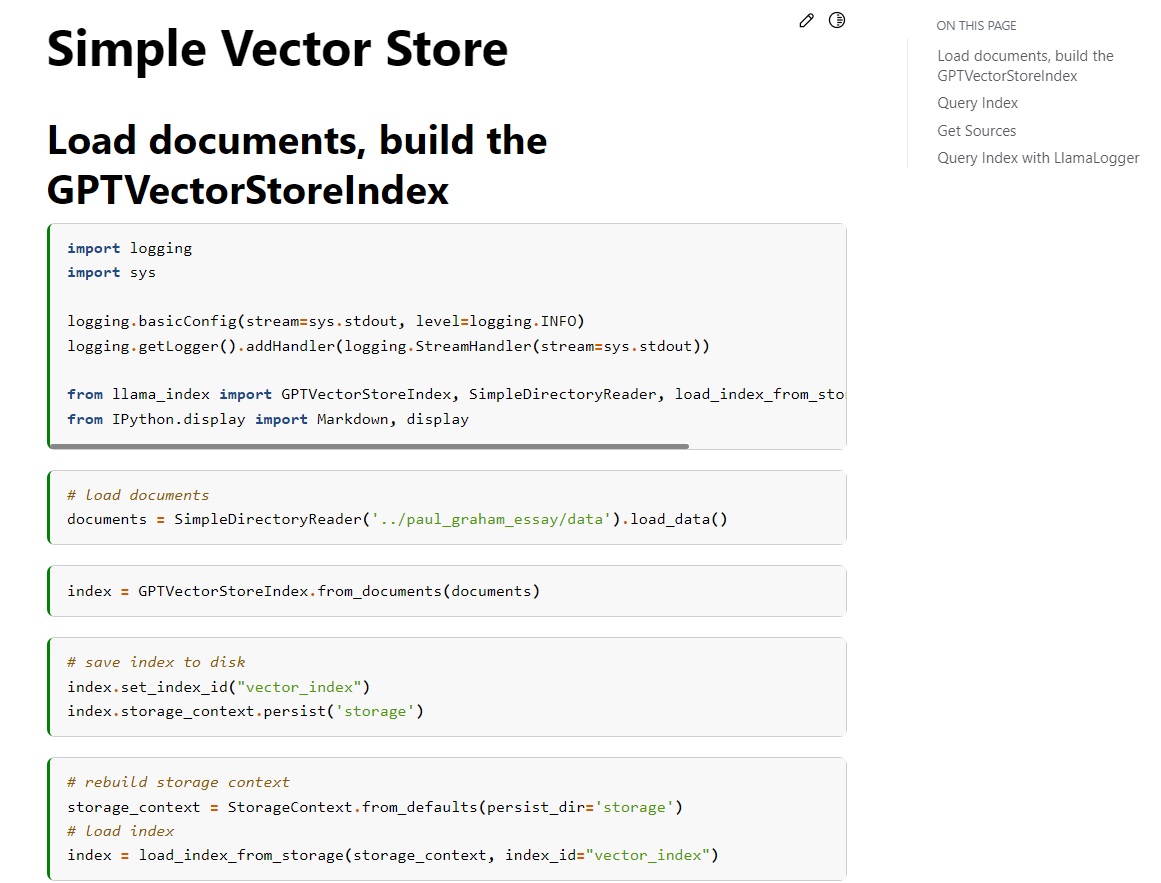
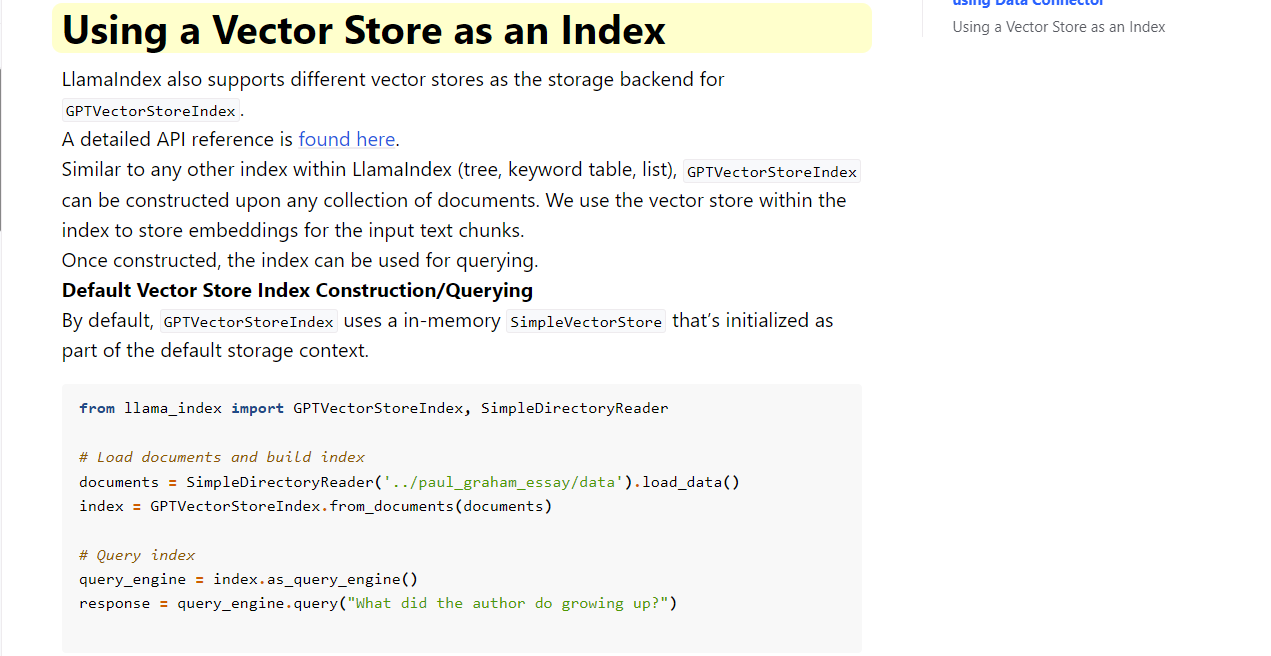
うまく生成できなかった例
$ python query.py "GPTVectorStoreIndexを作成するコードを教えてください"
質問: GPTVectorStoreIndexを作成するコードを教えてください
解答:
与えられた文脈情報からは、GPTVectorStoreIndexを作成するコードについての情報は得られ
ませんでした。文脈情報をもう少し詳しく提供していただければ、回答できるかもしれませ
ん。うまく生成できませんでした。
問い合わせる際は、詳しくプロンプトを書かなければならないようです。
$ python query.py "BeautifulSoupWebReaderのパラメータを教えてください"
質問: BeautifulSoupWebReaderのパラメータを教えてください
解答: コンテキスト情報には、BeautifulSoupWebReaderの使用例が含まれておらず、パラメ
ータに関する情報も提供されていません。したがって、この質問には回答できません。$ python query.py "LlamaIndexのData connectorsであるBeautifulSoupWebReaderのパラメータを教えてください"
質問: LlamaIndexのData connectorsであるBeautifulSoupWebReaderのパラメータを教えてください
解答:
BeautifulSoupWebReaderは記載されておらず、代わりにSimpleDirectoryReader、NotionPageReader、GoogleDocsReader、SlackReader、DiscordReader、ApifyActorなどのデータコネク
タが記載されています。BeautifulSoupWebReaderに関する情報は提供されていません。なぜか生成できませんでした。プロンプトを詳しく書き換えてもうまく生成できませんでした。
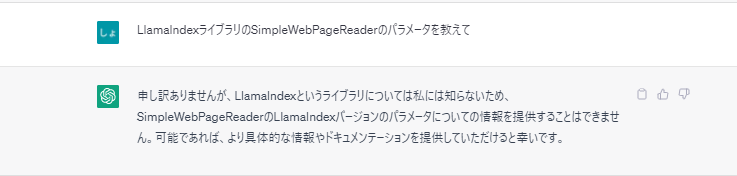
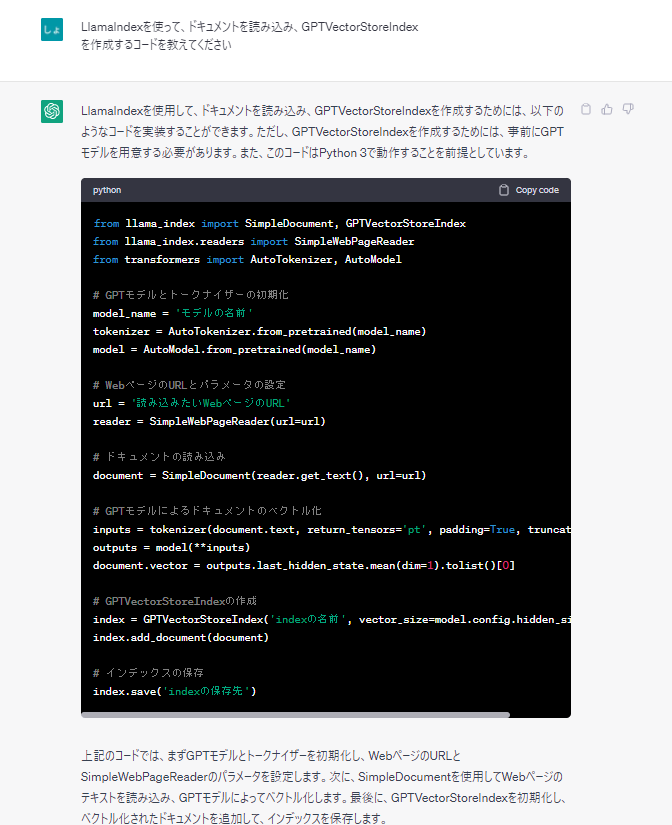
最新情報に対応していなかったり、コード自体が間違っていました。
from llama_index import SimpleDocument
from llama_index.readers import SimpleWebPageReaderllama_index にSimpleDocumentは存在していませんでした。また、SimpleWebPageReaderはllama_index.readersには存在しません。
まとめ
うまく生成できない場合がありますが、詳しくプロンプトを記載することで、欲しい解答を得られる確率が高いです。
また、ChatGPTを使って聞いても、最新情報に対応していないため、答えられない場合や、噓の解答をしてしまいます。ですので、最新の情報については、Webページを読み込んで、回答を生成することも1つの手段だと思います!
より、正確な回答を得るために、LangChainを使ってGoogle検索をツールとして持たせてみるとより良くなるかもしれません!
今回のコードはLlamaIndexの最新バージョンに対応しているので是非参考にしてください!
参考


