はじめに
Notion API+LlamaIndexでNotionページの内容に対して質問をし、回答を生成できるようにしました。 Notion APIとLlamaIndexを使ってNotionのページを読み込み、文書に対して問い合わせすることができます。Llamaindexを使うことで、簡単にNotionのページをインデックス化できるので、実践していきます。
Notion API
LlamaIndexを使ってNotionのページを読み込むには、NotionのAPIを取得する必要があります。Notion APIの取得方法とNotion APIを使える状態にする手順を説明します。
手順は以下のようになります
- インテグレーションを作成する
- コネクトを追加する
インテグレーションを作成する
以下のページから作成することができます。
https://www.notion.so/my-integrations インテグレーションを作成すると最後にトークンが付与されます。こちらのトークンがNotion APIとなりますのでメモしておきましょう。
コネクトを追加する
インテグレーションを作成し、Notion APIを取得しただけでは使うことができません。作成したインテグレーションからNotionのページやデータベースにアクセスできる状態にする必要があります。そのため、アクセスしたいページにコネクトを追加します。 アクセスしたいページを開き、コネクトの追加を開きます。
 そして、先ほど作成したインテグレーションを選択しましょう。
これで準備完了です。
そして、先ほど作成したインテグレーションを選択しましょう。
これで準備完了です。
実際にやってみる
では、実際にNotion APIとLlamaIndexを使ってNotionのページを読みこみ、問い合わせできるようにしていきます。
以下の2種類のファイルを作成していきます。
- Notionのページを読み込み、インデックスを作成する
- インデックスに問いあわせる
インデックスを作成する前に、読み込ませたいページやデータベースのIDが必要となります。 まずはIDを取得していきます。 読み込ませたいページやデータベースのURLからIDを取得することができます。
IDの取得の仕方
ページID 読み込ませたいページのURLは以下のような構成になっています。
:::message
https://www.notion.so/{ドメイン名}/{ページ名}-{ページID(32桁)}?pvs=4
32桁のページIDの部分を取得します。
データベースID 読み込ませたいデータベースのURLは以下のような構成になっています。
32桁のデータベースIDの部分を取得します。
:::
インデックスを作成
今回は、例としてNotionのページを読み込ませてみたいと思います。 読み込ませるページは以下のページになります。LangChainの概要について記載されています。
では、Notionのページを読み込ませていきます!
コード全体
コード全体を先にのせておきます。先に概要が知りたい方はご覧ください。
コード例
import os
import faiss
from llama_index import NotionPageReader
from llama_index import GPTVectorStoreIndex, StorageContext
from llama_index.vector_stores.faiss import FaissVectorStore
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
os.environ["NOTION_INTEGRATION_TOKEN"] = "NOTION_INTEGRATION_TOKEN"
integration_token = os.getenv("NOTION_INTEGRATION_TOKEN")
d = 1536
faiss_index = faiss.IndexFlatL2(d)
page_ids = ["page_ids"]
documents = NotionPageReader(integration_token=integration_token).load_data(page_ids=page_ids)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = GPTVectorStoreIndex.from_documents(documents, storage_context=storage_context)
index.set_index_id('vector_index')
index.storage_context.persist('storage')コードの説明
コードの説明に入ります。 まずは必要なライブラリをインポートしていきます。
import os
import faiss
from llama_index import NotionPageReader
from llama_index import GPTVectorStoreIndex, StorageContext
from llama_index.vector_stores.faiss import FaissVectorStore次に、OpenAIのAPIとNotionのAPIをそれぞれ設定していきます。
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
os.environ["NOTION_INTEGRATION_TOKEN"] = "NOTION_INTEGRATION_TOKEN"
integration_token = os.getenv("NOTION_INTEGRATION_TOKEN")今回はFAISSというライブラリを使ってインデックスを作成していきます。dはベクトルを埋め込むときの次元数を表しています。その次元をもとにインデックスの構造を決定しています。
d = 1536
faiss_index = faiss.IndexFlatL2(d)インデックスの構造を決めたので、Notionのページを読み込み、実際にインデックスを作成していきます。"page_ids"には先ほど取得したIDを入れます。
page_ids = ["page_ids"]
documents = NotionPageReader(integration_token=integration_token).load_data(page_ids=page_ids)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = GPTVectorStoreIndex.from_documents(documents, storage_context=storage_context)最後にインデックスを保存します。インデックスの内容を保存するディレクトリを指定します。今回はstrageに保存します。勝手にディレクトリが作られるので、用意する必要はありません。
index.storage_context.persist('storage')インデックスに問い合わせる
インデックスを作成したので、作成したインデックスをロードし、質問してみましょう。
コード全体
コード全体を先にのせておきます。先に概要が知りたい方はご覧ください。
コード例
import os
from llama_index import load_index_from_storage,StorageContext
from llama_index.vector_stores.faiss import FaissVectorStore
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
vector_store = FaissVectorStore.from_persist_dir(persist_dir='storage')
storage_context = StorageContext.from_defaults(vector_store=vector_store, persist_dir='storage')
index = load_index_from_storage(storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("質問したい内容")
print(response)コードの説明
コードの説明に入ります。 まず、必要なライブラリをインポートし、OpenAIのAPIを設定していきます。
import os
from llama_index import load_index_from_storage,StorageContext
from llama_index.vector_stores.faiss import FaissVectorStore
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"次に、先ほど作成したインデックスをロードしていきます。persist_dir に先ほど保存したディレクトリのパスを指定すればよいです。今回はstrageに保存したので、そこからロードします。
vector_store = FaissVectorStore.from_persist_dir(persist_dir='storage')
storage_context = StorageContext.from_defaults(vector_store=vector_store, persist_dir='storage')
index = load_index_from_storage(storage_context=storage_context)最後にクエリを発行し、質問していきます。"質問したい内容”の部分に質問したい内容を入れてあげればよいです。
query_engine = index.as_query_engine()
response = query_engine.query("質問したい内容")
print(response)実際に問い合わせてみる
実際に問いあわせた結果を見ていきます。
(1) LangChainとは何か聞いてみた
response = query_engine.query("LangChainとは何ですか")
print(response)LangChainは、ChatGPTなどの大規模言語モデル(LLM)を利用して、サービスの開発を行えるPythonライブラリです。LLM単独ではできないことを、外部リソースと組み合わせることで可能にすることができます。LangChainには、Models, Prompts, Chains, Indexes, Memory, Agentsの6つの機能が提供されています。 元の文書に基づいて正確な回答が得られました!
(2) コードを生成できるか試してみる
Agent機能
元ページには、agent機能を使ったコード例が記載されているので、生成出来るか試してみます。
response = query_engine.query("LangChainのAgent機能を使用して、Google検索をツールとするコード例を教えて")
print(response)LangChainのAgent機能を使用して、Google検索をツールとするコード例は以下の通りです。
os.environ["OPENAI_API_KEY"]="OpenAI_api_key"
os.environ["GOOGLE_API_KEY"] = "GOOGLE_API_KEY"
os.environ["GOOGLE_CSE_ID"] = "GOOGLE_CSE_ID"
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
tools = load_tools(["google-search"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("2023年のWBCの優勝国は?")ページに乗っているコード例を生成してくれました!
Memory機能
memory機能でも試してみます。
response = query_engine.query("LangChainのMemory機能を使用したコード例を教えて")
print(response)LangChainのMemory機能を使用したコード例を以下に示します。
import os
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
os.environ["OPENAI_API_KEY"]="OpenAI_api_key"
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="AIとは何ですか?")
print(conversation.predict(input="その内容を簡潔に要約してください。"))ページに乗っているコード例を生成してくれました!
Chain機能
最後にChain機能で試してみます。元のページで、Chain機能を使用したコード例を記載しています。その内容が取得できる事を期待しています。以下の画像がその内容になります。

response = query_engine.query("LangChainのChain機能を使用したコード例を教えて")
print(response)LangChainのChain機能を使用したコード例を教えてください。
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
os.environ["OPENAI_API_KEY"]="OpenAI_api_key"
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True)
# 会話を開始する
conversation.start()
# 会話を進める
while True:
# ユーザーからの入力を受け取る
user_input = input("User: ")
# 会話を進める
response = conversation.predict(input=user_input)
# ユーザーに出力する
print("Bot: ", response)正しくないコードを生成してしまいました。ConversationChainにはstartというメソッドは提供されていません。
原因 このような結果になった原因として、Notionのページ内でChainという単語が複数登場しているためだと考えられます。インデックスから、ベクトルの類似度を見て情報を取ってきます。そのため、同じ単語が複数あると、類似度が高い情報も多くなってしまいます。その結果、どの部分を取ってくればよいかわからないため、正確なコードを生成できなかったと考えられます。
このような状況を避けるためには、複数登場している単語を避けて、質問するとよいです。 例えば以下のように質問するとよいです。
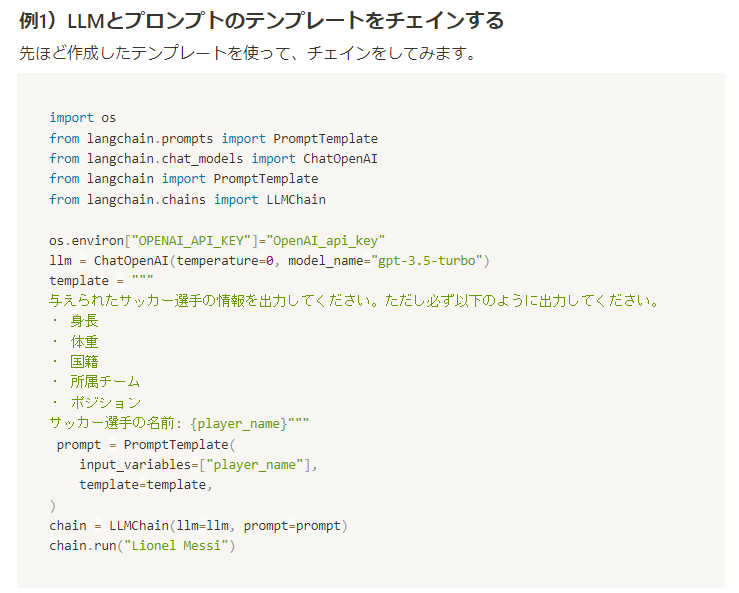
response = query_engine.query("LLMとテンプレートをチェインするコード例")
print(response)import os
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
from langchain.chains import LLMChain
os.environ["OPENAI_API_KEY"]="OpenAI_api_key"
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
template = """
与えられたサッカー選手の情報を出力してください。ただし必ず以下のように出力してください。
・ 身長
・ 体重
・ 国籍
・ 所属チーム
・ ポジション
サッカー選手の名前: {player_name}"""
prompt = PromptTemplate(
input_variables=["player_name"],
template=template,
)
chain = LLMChain(llトークン数が足りず、回答が途中で止まってしまいましたが、欲しい内容は取ってこれました。
まとめ
今回は、Notion APIとLlamaIndexを使ってNotionのページを読みこみ、問い合わせできるようにしてみました。おおむね、欲しい内容を取ってこれますが、複数回登場する単語には注意が必要だとわかりました。質問する際は、そのような単語を避けて質問したり、より具体的な質問をするようにすると、狙った回答が得られると思います。
参考
https://gpt-index.readthedocs.io/en/latest/index.html
https://dev.classmethod.jp/articles/llamaindex_with_notion-loader/
