はじめに
皆さん、こんにちは。株式会社Elcamyのデータサイエンティスト・AIエンジニアの近江俊樹です。 最近、AI、特にLLM(大規模言語モデル)開発の盛り上がりは目を見張るものがありますね。 LLMは大量のデータから学習し、その能力を高めていきます。高品質なデータをどれだけ多く学習させられるかが、LLMの性能を左右すると言っても過言ではありません。 しかし、LLM開発のためのデータ収集は容易ではありません。時間と労力を要する地道な作業が求められます。 そこで今回は、そんな「データ収集の苦労」を解決してくれる、強力なツール Firecrawl をご紹介します。 Firecrawlは、ウェブサイトの情報を効率的に収集し、LLMが学習しやすい形に整形してくれる、まさに「AIエンジニアのためのクローリングツール」という位置付けになっているそうです。 しかし、このFirecrawl、LLM開発に特化しているというだけで、LLM開発以外のデータ収集にも十分に使えると思いました。私が使ってみた感想ですが、非エンジニアにとても優しいツールだなと思いました。
この記事を読まれる方全員に持っていて欲しい前提知識ですが、クローリング・スクレイピングには多くの注意事項があります。特に重要なのが違法になってしまうパターンですので、スクレイピング違法パターンの解説については、弊社のブログをご参考ください。
この記事の対象者
- 非エンジニアだが、クローリング・スクレイピングが必要な方
- LLMの開発に関わっている人
- AIエンジニア(AI開発者)
- データサイエンティスト
参考
Firecrawl公式ドキュメント:https://docs.firecrawl.dev/introduction
Firecrawlの特徴
Firecrawlを一言で表すと、「ウェブサイトの情報を効率的にクローリングし、LLM向けのデータ準備に最適化されたツール」です。もちろんそれ以外の使い方もできます。
従来のウェブスクレイピングツールでは、
- 処理速度が遅く、大量のデータを扱うのが難しい
- 抽出したデータの整形に手間がかかる
- プログラミングの知識が必要で、初心者にはハードルが高い
といった課題がありました。 Firecrawlはこれらの課題を解決し、誰もが簡単に、そして効率的にウェブデータを取得し、LLM開発に活用できるよう設計されています。 開発元のMendable.aiは、AIとデータ分析の分野で豊富な経験を持つ企業です。Firecrawlは、そんな彼らのノウハウが詰まった、まさに「痒い所に手が届く」ツールと言えるでしょう。
Firecrawlは、任意のWebサイトをクリーンなMarkdown形式に変換することができます。 LLMで読みやすいMarkdown形式に変換してくれるので、LLM(大規模言語モデル)向けのデータ準備をしているエンジニアにはありがたい話ですね。 また、自社ブログや階層があるようなドキュメントを一括で、json形式にもまとめることができます。つまりこのjsonファイルを例えばDifyやCozeなどのKnowledgeに使うこともできるのです。
集めたデータで、自社専用のAIチャットを作ってみませんか? 「Firecrawlで集めたデータを使ってDifyに読み込ませたい」「うまく回答してくれる社内AI(RAG)を構築したい」という場合は、ぜひお気軽に弊社へご相談ください。 プロが最適な設計とデータ連携をサポートするDifyワークフロー構築や、導入から伴走するDify総合ソリューションで、本当に実用的なAIアプリづくりをお手伝いします。まずは「こんなデータ使えないかな?」とカジュアルにお話ししてみませんか?
さらに別視点から見ると、「膨大な自社コンテンツを整理したい」となったときに、自社内で効果的な整理ができていない場合、Firecrawlを使ったデータ収集は非エンジニアにとって有効な手段になりそうです。
このように高度なWebクロールと データ変換機能を備えており、サイトマップなしでもWebデータの収集、クリーニング、フォーマットを自動化でき、URLを入力するだけで、全プロセスを処理してくれるので、AIエンジニア・データサイエンティスト・非エンジニアにとって理想的なツールです。 FireCrawlはMendable.aiとFireCrawlコミュニティによって開発されており、Difyとの連携も可能で、最大300個の無料クレジットが利用できます。
Firecrawlの特徴をまとめると以下となります。
| 機能 | 説明 |
|---|---|
| 機能 | 説明 |
| Webクローリング | 指定されたURLからウェブサイト全体をクローリングし、情報をくまなく収集。サイトマップなしでも、Webサイトの情報を効率的に収集 |
| データ抽出&変換 | ウェブサイトから必要なデータを抽出し、Markdownやjson形式に変換 |
| シンプルなAPI | 数行のコードでFirecrawlの機能を利用可能。Python、Node.jsなどに対応 |
| オープンソース | セキュアな環境で使用可能 |
| Difyとの連携 | Difyと連携して、Webページをナレッジベースとして活用可能 |
ちなみに、似たような機能を持つ「Jina Reader API」というのがあるのですが、Jina Reader APIと違ってFireCrawlは、アクセス可能なすべてのサブページをクロールしてくれるので、ドキュメント全体の複数のページのクロールが可能です。
これらの機能により、ウェブサイトからLLMの学習データを作成する一連の作業を、Firecrawl一つで完結できます。
Firecrawlを使うメリット
Firecrawlを使うメリットは、以下の3つに集約されます。
- **圧倒的な使いやすさ **直感的なインターフェースとシンプルなAPIで、初心者でも簡単に操作できます。
- **高精度なデータ抽出 **高度な解析アルゴリズムにより、必要なデータをピンポイントで抽出。ノイズに悩まされることは少ないです。
- **Markdown形式での出力 **抽出したデータは、LLMで扱いやすいMarkdown形式で出力されます。すぐにLLMの学習に利用できるため、時間と手間を大幅に削減できます。
Firecrawlの活用事例
Firecrawlは、その汎用性の高さから、様々な分野で活用されています。
| 分野 | 例 |
|---|---|
| 分野 | 例 |
| マーケットリサーチ | 競合他社の価格や商品情報を収集し、市場動向を分析する。 |
| コンテンツアグリゲーション | 複数のニュースサイトから記事を収集し、自社サイトで配信する。 |
| AIモデルのトレーニング | 大規模なテキストデータを収集し、LLMの学習データとして利用する。 |
Firecrawlの料金プラン
Firecrawlは、ユーザーに合わせて、複数の料金プランを提供しています。 無料プランから、大企業向けのエンタープライズプランまで、幅広いニーズに対応できる料金プランが用意されています。 自分に合ったプランを選ぶことで、Firecrawlをより効率的に活用することができます。
以下は年契約の場合のプラン表です。
| プラン名 | 月額料金 | ページ数 | スクレイピング/分 | クローリング/分 | 備考 |
|---|---|---|---|---|---|
| プラン名 | 月額料金 | ページ数 | スクレイピング/分 | クローリング/分 | 備考 |
| Free Plan | 無料 | 500 | 5 | 1 | 初心者に最適 |
| Hobby | $16 | 3,000 | 10 | 3 | 小規模プロジェクトに最適 |
| Standard | $83 | 100,000 | 50 | 10 | 中規模プロジェクトにおすすめ |
| Growth | $333 | 500,000 | 500 | 50 | 大規模プロジェクトに最適 |
| Enterprise | 要相談 | 無制限 | カスタム | カスタム | 大企業向け |
※上記料金は、2024年7月31日時点の情報です。最新情報はFirecrawlの公式ウェブサイトをご確認ください。
Firecrawl APIを使う前に
使ってみる前にプレイグラウンドでAPIの挙動を試すことができます。 Firecrawlにログインすらせずに試すことが可能です。 クロールの制限は5ページです。アカウントを作成すれば5ページ以上を設定できます。
以下は弊社HPをクローリングしている様子です。 コーディングは一切不要で、URLを貼り付けてRunするだけです。 私はこの機能自体に驚きました。非エンジニアにとって非常に便利だと思いました。 目的によっては、APIを使わずこれだけで完結できるかもしれません。
@tweet 【Firecrawlを上手に使うコツ】 上記の動画内の[Options]で、スクレイピングデータにHeaderとかFooterが不要だと思われる場合は、Extract only main content (no headers, navs, footers, etc.)にチェックをしてください。 また下記のAPIを使う場合もonlyMainContentというオプションをつければ、中身だけ取得できます。
さあ、Firecrawl APIを使ってみよう!
Firecrawlは、誰でも簡単に導入することができます。
Step 0. 準備
今回は、Google Colaboratoryを使います。 以下がColaboratory(Colab)の説明ですが、なぜColabを使うかというと環境構築が不要だからです。エンジニアを目指した多くの方々がこの環境構築の際に発生する数々のエラーに面食らったことでしょう。 環境構築は今記事の本質ではないため、Colabを使ってFirecrawlを使っていきます。
Colab(正式名称「Colaboratory」)では、ブラウザ上で Python を記述、実行できます。以下の機能を使用できます。
- 環境構築が不要
- GPU に料金なしでアクセス
- 簡単に共有
引用:GoogleのColaboratory公式ページ
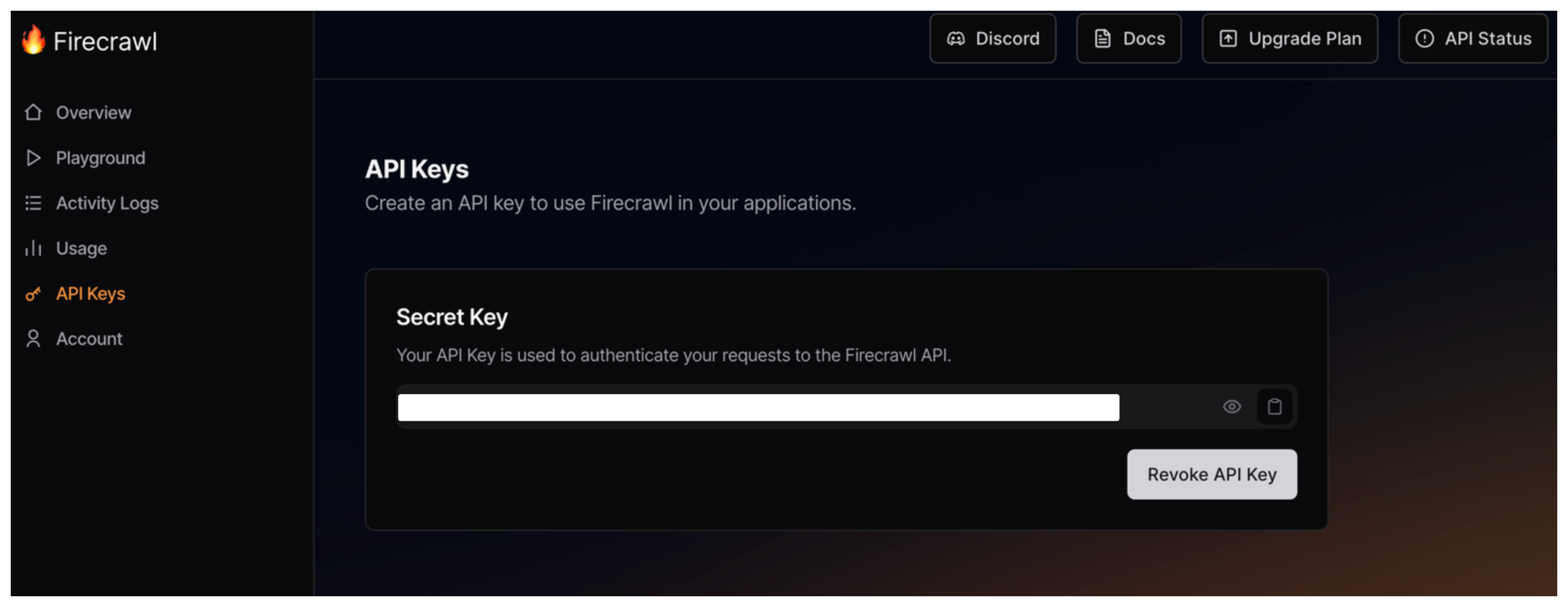
Step 1. アカウント作成&APIキーの取得
Firecrawlの公式ウェブサイトでアカウントを作成すると、既にAPIキーが用意されています。後で使うのでここにあることを覚えておきましょう。このキーは絶対に公開しないようにしてください。
Step 2. インストール
以下を実行してください。
!pip install firecrawl-py
下画面のようになるかと思います。
 もし、ここで詰まってしまった場合はFirecrawlではなくColab関連が原因だと思われますので、申し訳ございませんがColab関連を調べて自ら解決してください。以降、上記のような画面の画像は省略させていただきます。
もし、ここで詰まってしまった場合はFirecrawlではなくColab関連が原因だと思われますので、申し訳ございませんがColab関連を調べて自ら解決してください。以降、上記のような画面の画像は省略させていただきます。
Step 3. コーディング&実行
APIキーを使ってFirecrawl APIを呼び出し、ウェブクローリングとデータ抽出を実行します。 以下はPythonでのサンプルコードです。
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="YOUR_API_KEY")
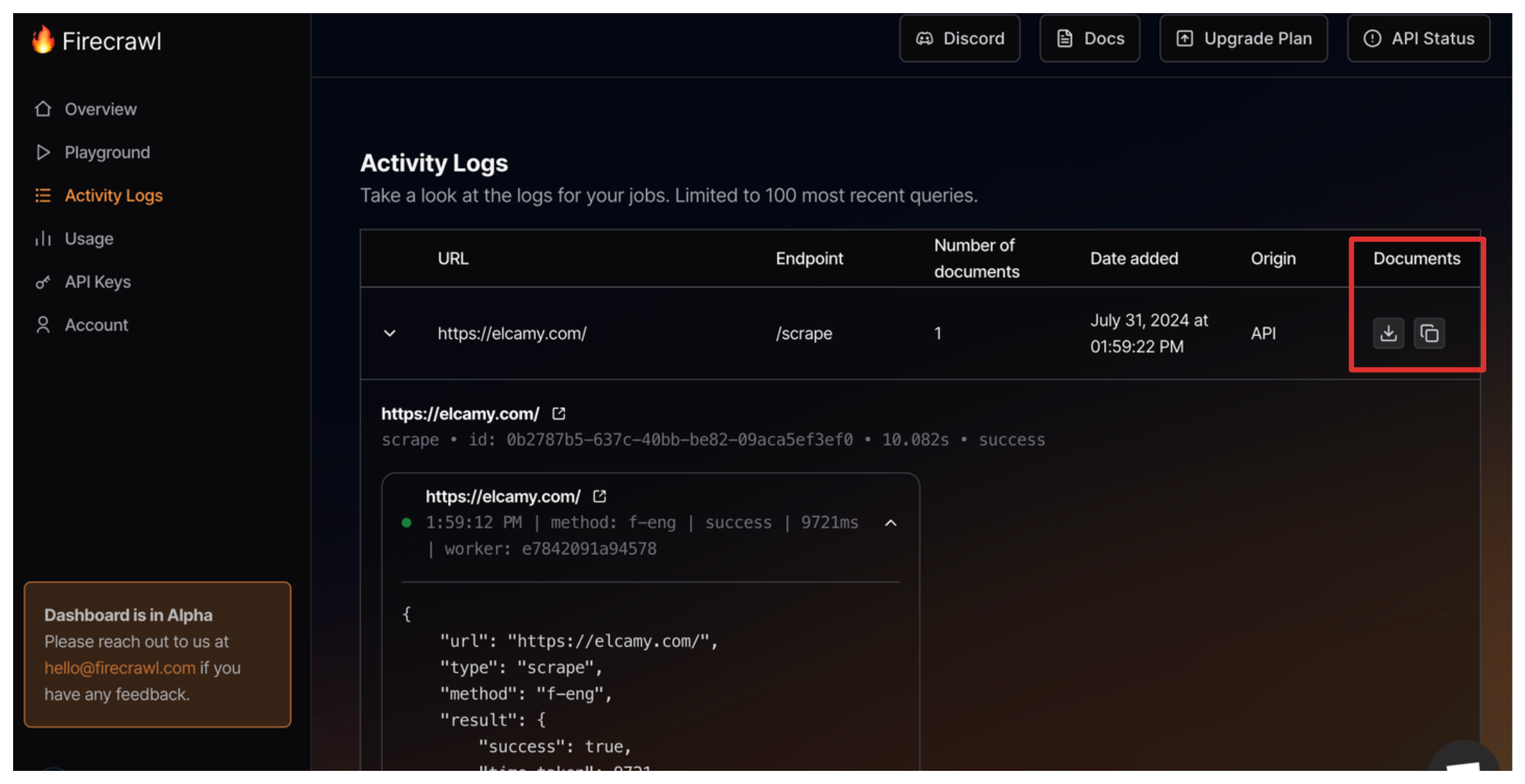
content = app.scrape_url("スクレイピングしたいサイトのURL")**”YOUR_API_KEY”**のYOUR_API_KEYの部分にStep 1のAPIキーをコピペして貼り付けてください。本当はコードに直接キーを貼り付けるのは良くないので、Colabの場合はシークレット機能を使うか、使い終わったらAPIキーの部分を消すようにすることをお勧めします。 "スクレイピングしたいサイトのURL"には、” ”の中にhttps://で始まるようなスクレイピングしたサイトのURLを入れてください。 あとは実行するだけです。 たったこれだけで、Firecrawlを使ったスクレイピングが開始できます!簡単ですね! 上記を実行した後のスクレイピングデータはFirecrawlダッシュボードのDocuments(赤枠)からダウンロードできます。
もっと実用的にFirecrawl APIを使おう!
とても簡単にスクレイピングができてしまったので、次は実用的かつコードが簡単な例を紹介します。
どんなことをやるかというと、自社HPのブログページのクローリング・スクレイピングです。 ブログコンテンツをちゃんと整理していなかったとき、いきなり上司から「ブログリスト提出して」と無茶を言われたときに役立ちそうです。 もちろん自社ブログコンテンツの分析のためのデータとしても活用できますね。
以下が具体的なフローです。
- 自社HPのブログコンテンツ(リンクに「blog/」が含まれているページ)が対象
- 対象をクローリング・スクレイピング
- マークダウン形式で、データを抽出
- 抽出したデータをテキストファイルで出力
- 出力するファイル名にスクレイピング日時を含める(管理しやすくするため)
カスタマイズすればいくらでも幅は広げることができますが、以下がそのコードです。
import datetime
import pytz
from firecrawl import FirecrawlApp
# 日本時間の設定
JST = pytz.timezone('Asia/Tokyo')
# 出力ファイル名(タイムスタンプ付きで重複防止)
output_filename = f"crawl_results_{datetime.datetime.now(JST).strftime('%Y-%m-%d-%H-%M-%S')}.txt"
# Firecrawlの初期化とクロール実行
app = FirecrawlApp(api_key="YOUR_API_KEY")
crawl_result = app.crawl_url('DOMAIN_NAME', {'crawlerOptions': {'includes': ['blog/*']}})
# 結果をテキストファイルに出力
with open(output_filename, 'w', encoding='utf-8') as f:
for result in crawl_result:
f.write(result['markdown'] + '\n')
print(f"クロール結果を {output_filename} に出力しました。")
- YOUR_API_KEYは前述した通りです。
- DOMAIN_NAMEはWebサイトのドメインを入れてください。ドメインとは、URLが「https://elcamy.com」の場合は、「elcamy.com」の部分のことを指します。
- **「blog/*」**というのは例えば弊社の場合、「https://elcamy.com/blog/」以下にブログページをまとめていますので、「blog/*」とすることで「https://elcamy.com/blog/」以下全てのページを指定しています。「blog/*」の箇所はご自身のページ構造に合わせて修正してください。
- クローリング・スクレイピングするときは必ずサーバーに負荷をかけているという認識を常に持ってください。違法になってしまうパターンはこちらの記事で解説しています。十分な知識を持った上で行なってください。
(例)出力したファイルの中身
ちなみにFirecrawlの公式ドキュメントを見ると、様々なオプションが記載されていますので、目的に合わせ、コード内のcrawlerOptionsの箇所をカスタマイズしてみても良いですね。
おわりに
Firecrawlは、ウェブクローリングとデータ抽出を効率化し、LLM開発を加速させる強力なツールです。高速な処理、高精度なデータ抽出、そして使いやすさ、どれをとっても従来のツールとは一線を画しています。 LLM開発に携わる皆さん、ぜひFirecrawlを試してみてください。もちろんLLM開発以外にも使えると思います。 ツールで取得できない場合やその他注意事項も多くあり、管理が大変だと思います。その場合は業者に依頼するのも良いかもしれません。 僕自身、今後Firecrawlを積極的に活用し、より高度なLLM開発にチャレンジしていきたいと考えています。 最後までお読みいただきありがとうございました。
データ収集からAI活用まで、まるごとサポートします! クローリングやスクレイピングは、サイトの仕様変更によるエラー対応など、運用に手間がかかることも多いです。「データ収集の自動化から、それを活用した社内AI(Dify)の構築までプロに任せたい」という方は、弊社のDify総合ソリューションをご活用ください。 非エンジニアの方でも安心して進められるよう、全力で伴走いたします。まずはお気軽にご相談ください。
